
ZRANGEBYLEX myindex "[bit" "[bit\xff"
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1

Comment utiliser Gaussian Redis pour implémenter un index secondaire

1. Contexte
En matière d'indexation, la première impression est le terme base de données, mais Gaussian Redis peut également implémenter une indexation secondaire ! ! ! Les index secondaires dans Gaussian Redis sont généralement implémentés à l'aide de zset. Gaussian Redis présente des avantages en termes de stabilité et de coût plus élevés que Redis open source. L'utilisation de Gaussian Redis zset pour implémenter des index secondaires commerciaux peut permettre d'obtenir une situation gagnant-gagnant en termes de performances et de coûts.
L'essence de l'indexation est d'utiliser des structures ordonnées pour accélérer les requêtes, de sorte que les index de type numérique et caractère puissent être facilement implémentés via la structure Zset Gaussian Redis.
• Index de type numérique (zset est trié par score) :
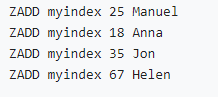

•
Passons en deux types de scénarios commerciaux classiques, voyons comment utiliser Gaussian Redis pour créer un système d'index secondaire stable et fiable. 2. Scénario 1 : Complétion du dictionnaire
2. Scénario 1 : Complétion du dictionnaire
Lors de la saisie d'une requête dans le navigateur, le navigateur recommande généralement des recherches avec le même préfixe en fonction de la vraisemblance. Ce scénario peut être réalisé à l'aide de la fonction d'index secondaire Gaussian Redis. 
2.1 Solution de base
Le moyen le plus simple est d'ajouter chaque requête de l'utilisateur à l'index. Si vous devez fournir des invites de complétion aux utilisateurs, vous pouvez utiliser ZRANGEBYLEX pour effectuer des requêtes de plage. Pour réduire le nombre de résultats, l'utilisation de l'option LIMIT est une méthode prise en charge par Gaussian Redis.
• Ajoutez une banane de recherche d'utilisateur à l'index : 
ZADD myindex 0 banana:1
ZRANGEBYLEX myindex "[bit" "[bit\xff"
Copier après la connexion
Autrement dit, utilisez ZRANGEBYLEX pour effectuer une requête de plage. La plage de requête est la chaîne saisie par l'utilisateur maintenant, et la même chaîne plus un octet de fin de 255 (xff). Nous pouvons utiliser cette méthode pour obtenir toutes les chaînes préfixées par la chaîne saisie par l'utilisateur. 2.2 Complétion de dictionnaire liée à la fréquence Dans les applications pratiques, les gens souhaitent généralement trier automatiquement les termes de complétion pour s'adapter à la fréquence d'occurrence et éliminer les termes qui ne sont plus populaires, tout en s'adaptant aux entrées futures. Nous pouvons toujours utiliser la structure ZSet de Gaussian Redis pour atteindre cet objectif, mais dans la structure d'index, non seulement les termes de recherche doivent être stockés, mais également les fréquences qui leur sont associées. • Ajouter la banane de recherche d'utilisateur à l'index • Déterminer si la banane existe ZRANGEBYLEX myindex "[bit" "[bit\xff"
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
Copier après la connexion
• Supposons que la banane n'existe pas, ajoutez la banane : 1, où 1 est la fréquence ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
ZADD myindex 0 banana:1
ZREM myindex 0 banana:1
ZADD myindex 0 banana:2
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
ZREM myindex 0 banaooo:1
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122
3.1 Codage des données
Si le point de données inséré est x = 75 et y = 200
1) Remplissez 0 (la donnée maximale est de 400, donc remplissez 3 chiffres)
2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
如果将数据表示为二进制,就可以获得更细的粒度,而在数字替换时,每次都将搜索范围扩大两倍。如果我们使用二进制表示法数字,每个变量最多需要9位(表示最多400个值),那么我们将得到:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
