
 base de données
tutoriel mysql
Quelle est la différence entre l'index B-tree et l'index B+-tree dans MySQL ?
base de données
tutoriel mysql
Quelle est la différence entre l'index B-tree et l'index B+-tree dans MySQL ?
Quelle est la différence entre l'index B-tree et l'index B+-tree dans MySQL ?

Si vous utilisez un arbre comme structure de données d'index, chaque fois que vous recherchez des données, un nœud de l'arborescence sera lu à partir du disque, qui est une page. Cependant, chaque nœud de l'arbre binaire ne stocke qu'une seule donnée. , qui ne peut pas remplir une page d’espace de stockage, l’espace de stockage supplémentaire ne serait-il pas gaspillé ? Afin de résoudre cette lacune de l'arbre de recherche binaire équilibré, nous devrions rechercher une structure de données capable de stocker plus de données dans un seul nœud, c'est-à-dire un arbre de recherche multidirectionnel.
1. Arbre de recherche multidirectionnel
1. Hauteur complète de l'arbre binaire : O(log2N), où 2 est le logarithme, le nombre de nœuds à chaque niveau de l'arbre ; .Arbre de recherche M-way complet La hauteur : O(logmN), où M est le logarithme, le nombre de nœuds dans chaque couche de l'arbre ; O(log2N),其中2为对数,树每层的节点数;
2、完全M路搜索树的高度:O(logmN),其中M为对数,树每层的节点数;
M路搜索树适用于存储数据量过大无法一次性加载到内存的场景。通过增加每层节点的个数和在每个节点存放更多的数据来在一层中存放更多的数据,从而降低树的高度,在数据查找时减少磁盘访问次数。
因此,如果每个节点包含的关键字数量和每层的节点数量增加,则树的高度将减少。尽管每个节点的数据确定会更加耗时,但B树的关注点在于解决磁盘性能瓶颈,因此单个节点搜索数据的成本可以被忽略。
2. B树-多路平衡搜索树
B树是一种M路搜索树,B树主要用于解决M路搜索树的不平衡导致树的高度变高,跟二叉树退化为链表导致性能问题一样。B树通过对每层的节点进行控制、调整,如节点分离,节点合并,一层满时向上分裂父节点来增加新的层等操作来来保证该M路搜索树的平衡。
在B树中,每个节点都是一个磁盘块(页),而阶数或者说路数M则规定了节点中最多的子节点数量。每个非叶子节点存放了关键字和指向儿子树的指针,具体数量为:M阶的B树,每个非叶子节点存放了M-1个关键字和M个指向子树的指针。如图为5阶B树结构的示意图:

3. B树索引
首先创建一张user表:
create table user( id int, name varchar, primary key(id) ) ROW_FORMAT=COMPACT;
假如我们使用B树对表中的用户记录建立索引:
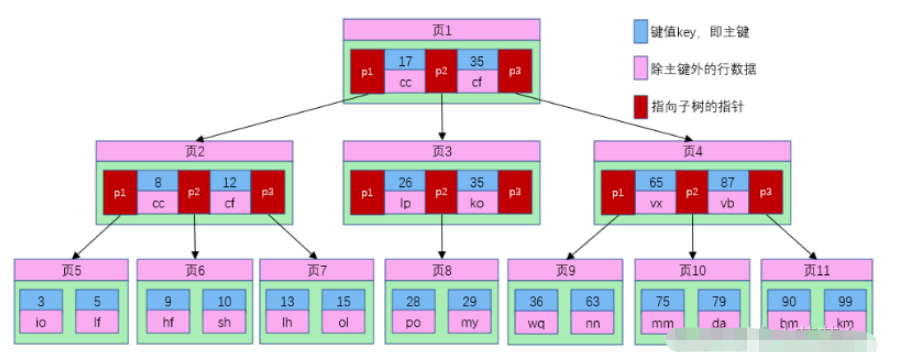
B树的每个节点占用一个磁盘块,磁盘块也就是页,从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的主键key和数据data,并且每个节点拥有了更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会降低。假如我们要查找id=28的用户信息,那么查找流程如下:
1、根据根节点找到页1,读入内存。【磁盘I/O操作第1次】
2、比较键值28在区间(17,35),找到页1的指针p2;
3、根据p2指针找到页3,读入内存。【磁盘I/O操作第2次】
4、比较键值28在区间(26,35),找到页3的指针p2。
5、根据p2指针找到页8,读入内存。【磁盘I/O操作第3次】
6、在页8中的键值列表中找到键值28,键值对应的用户信息为(28,po);
B-Tree相对于AVLTree
3. Index B-tree
Créez d'abord une table utilisateur :
rrreeeSi nous utilisons B-tree pour indexer les enregistrements utilisateur dans le tableau :
Chaque nœud du B-tree occupe un bloc de disque, et le bloc de disque est également une page. Comme le montre la figure ci-dessus, comparé à l'arbre binaire équilibré, chaque nœud du L'arbre B stocke plus de clés primaires et de données, et chaque nœud a plus de nœuds enfants, le nombre de nœuds enfants est généralement appelé l'ordre. L'arbre B dans la figure ci-dessus est un arbre B à 3 niveaux et la hauteur. sera également réduite. Si nous voulons trouver les informations utilisateur de id=28, alors le processus de recherche est le suivant : 1 Trouvez la page 1 en fonction du nœud racine et lisez-la dans la mémoire. [Opération d'E/S disque 1ère fois] 🎜🎜2. Comparez la valeur de clé 28 dans l'intervalle (17,35), recherchez le pointeur p2 de la page 1 🎜🎜3. dans la mémoire. [Opération d'E/S disque 2ème fois] 🎜🎜4. Comparez la valeur clé 28 dans l'intervalle (26,35) et trouvez le pointeur p2 de la page 3. 🎜🎜5. Trouvez la page 8 selon le pointeur p2 et lisez-la dans la mémoire. [Opération d'E/S disque 3ème fois] 🎜🎜6. Recherchez la valeur de clé 28 dans la liste des valeurs de clé à la page 8. Les informations utilisateur correspondant à la valeur de clé sont (28,po) ; Par rapport à AVLTree, le nombre de nœuds est réduit, de sorte que les données sont extraites de la mémoire à chaque fois que les E/S du disque sont utilisées, améliorant ainsi l'efficacité des requêtes. 🎜🎜4. B+Tree Index🎜🎜B+Tree est une optimisation basée sur B-Tree, ce qui le rend plus adapté à la mise en œuvre de structures d'index de stockage externes : 🎜🎜1. nœuds Identique au nombre de mots-clés ; 🎜🎜2. Ajoutez un pointeur de lien vers tous les nœuds feuilles ; 🎜🎜3. Tous les mots-clés apparaissent dans les nœuds feuilles, et les mots-clés dans la liste chaînée sont dans l'ordre ; Non Le nœud feuille est équivalent à l'index du nœud feuille, et le nœud feuille est équivalent à la couche de données qui stocke les données (mot-clé) 🎜🎜Le moteur de stockage InnoDB utilise B+Tree pour implémenter sa structure d'index ; 🎜🎜Dans le diagramme de structure B-tree, on peut voir que chaque nœud contient également des valeurs de données en plus de la valeur clé des données. L'espace de stockage de chaque page est limité. Si les données sont volumineuses, le nombre de clés pouvant être stockées dans chaque nœud (c'est-à-dire une page) sera très faible. Lorsque la quantité de données stockées est importante, cela entraînera également. à B- La profondeur de l'arborescence est plus grande, ce qui augmente le nombre d'E/S disque pendant la requête, affectant ainsi l'efficacité de la requête. Dans B+Tree, tous les nœuds d'enregistrement de données sont stockés sur les nœuds feuilles dans la même couche par ordre de valeur clé. Seules les informations sur les valeurs clés sont stockées sur les nœuds non feuilles. Cela peut augmenter considérablement le nombre de valeurs clés stockées dans chacun. node. , réduisez la hauteur de B+Tree. 🎜🎜🎜B+Tree présente plusieurs différences par rapport à B-Tree : 🎜🎜🎜1. Les nœuds non-feuilles stockent uniquement les informations sur les valeurs clés et les pointeurs vers les numéros de page des nœuds enfants. 🎜🎜2. Il existe un lien entre toutes les chaînes de nœuds-feuilles. pointeur ; 🎜🎜3. Les enregistrements de données sont stockés dans les nœuds feuilles ;
D'après la figure ci-dessus, jetons un coup d'œil à la différence entre l'arbre B+ et l'arbre B :
(2) Dans l'arbre B+, les nœuds non-feuilles ne stockent que les valeurs clés, tandis que les nœuds de l'arbre B stockent les deux. valeurs clés et données du magasin.
La taille de la page est fixe et la taille de page par défaut dans InnoDB est de 16 Ko. Si les données ne sont pas stockées, davantage de valeurs clés seront stockées, l'ordre de l'arborescence correspondante sera plus grand et l'arborescence sera plus courte et plus grosse. En conséquence, le nombre de fois d'E/S disque dont nous avons besoin pour rechercher des données. sera à nouveau réduite. L’efficacité des requêtes de données sera également plus rapide.
De plus, si un nœud de notre arbre B+ peut stocker 1 000 valeurs clés, alors l'arbre B+ à 3 couches peut stocker 1 000×1000×1000=1 milliard de données. Généralement, le nœud racine réside en mémoire (il n'est pas nécessaire de lire le disque lors de la première récupération du nœud racine), donc généralement nous n'avons besoin que de 2 E/S disque pour rechercher 1 milliard de données.
(2) Toutes les données de l'index de l'arbre B+ sont stockées dans des nœuds feuilles et les données sont organisées dans l'ordre.
B+ Les pages de l'arborescence sont connectées via une liste chaînée bidirectionnelle, et les données dans les nœuds feuilles sont connectées via une liste chaînée unidirectionnelle De cette façon, toutes les données du tableau peuvent être trouvées. Les arbres B+ rendent les requêtes par plage, les requêtes de tri, les requêtes de groupe et les requêtes de déduplication extrêmement simples. Dans B-tree, les données étant dispersées dans différents nœuds, il n’est pas facile d’y parvenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
