

Créez un index sur le champ de filtre après où (où après la sélection/mise à jour/suppression est applicable), utilisez l'index pour accélérer l'efficacité du filtrage, sans effectuer une analyse complète de la table
Dans le cas de exigences uniques Ajoutez un index unique au champ pour accélérer l'efficacité de la requête. Si vous le trouvez, vous pouvez directement renvoyer
Ajouter un index au champ après regrouper par ou trier par. index équivaut à déjà l'interroger Sorted (ici il faut faire attention à l'ordre des champs dans l'établissement de l'index commun, qui peut être étudié en conjonction avec le cas spécifique scénario 7)
Ajouter un index à le champ après DISTINCT (champ de déduplication). Puisque l'index est établi, alors les mêmes données sont côte à côte, vous pouvez donc effectuer rapidement des opérations de déduplication. Sinon, vous devrez peut-être rechercher les mêmes données et effectuer des opérations de déduplication
Sur les champs connectés lors de la jointure de plusieurs tables Créez un index (une petite table entraîne une grande table)
Prenez un certain préfixe de la chaîne pour créer un index (n'utilisez pas la chaîne entière comme index, sinon cela prendra trop d'espace)
Créer un index sur les colonnes fréquemment utilisées (Un index commun peut être établi, et les champs les plus fréquemment utilisés doivent être à l'extrême gauche de l'index commun, le principe le plus à gauche)
Créer un index sur une colonne avec haute distinction (la clé primaire a la plus haute distinction, car toutes les clés sont toutes uniques)
Scénario 1 : Créer un index sur le champ derrière le champ Where
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
Avant d'ajouter l'index, cela a pris 0,383 seconde, parcourant essentiellement la table entière

Après avoir ajouté l'index, cela prend 0,001 seconde et utilise un index (mais il faudra un certain temps pour créer l'index)
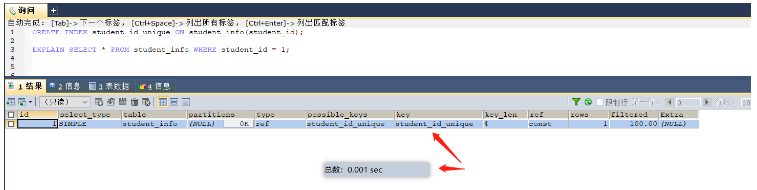
Dans le cas de requêtes fréquentes, vous pouvez créer un index sur les champs filtrés par où. S'il y a plusieurs champs filtrés par où, vous pouvez établir un index commun
Scénario 2 : Créer un index unique sur un champ avec. contraintes uniques (trouver la cible et revenir sans continuer à chercher)
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
Un index unique peut être établi sur un champ avec des contraintes uniques, bien qu'un index unique soit créé. Les index ont un certain impact sur les opérations d'insertion (vous devez déterminer si le les données nouvellement ajoutées sont déjà dans le tableau), mais l'établissement d'un index unique améliorera considérablement l'efficacité des requêtes. Par exemple, dans l'exemple ci-dessus, car un index unique est établi, une fois l'identifiant trouvé, une fois que les informations sur l'étudiant sont 1001, il n'est pas nécessaire de juger s'il y a un étudiant avec un identifiant égal à 1001 dans la base de données (il n'y a qu'une seule copie), et les informations peuvent être renvoyées directement si aucun index n'est établi, alors une analyse complète de la table est requise
.Scénario 3 : Les index sont souvent créés sur les champs de group by et order by (car l'index lui-même est trié, ce qui équivaut à trier avant d'interroger)
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引
Avant de construire l'index, cela prend 0,501 seconde, en utilisant toutes les données en mémoire Tri moyen
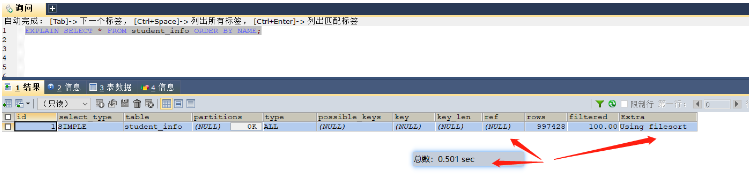
Après avoir établi l'index, cela prend 0,01 seconde
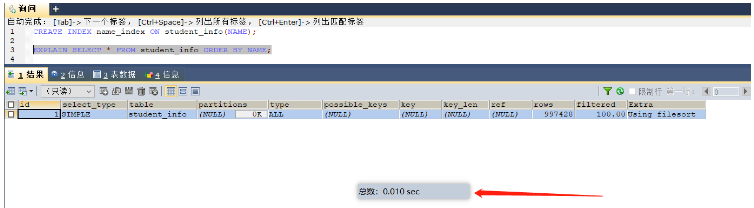
Scénario 4 : Ajouter un index au champ après DISTINCT (l'index a déjà trié les mêmes champs, ce qui rend la déduplication plus efficace)
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
Une fois l'index établi, la valeur par défaut est de trier par ordre croissant des champs d'index, et les champs avec la même valeur seront disposés ensemble, de sorte que la déduplication devient simple et efficace
Scénario 5 : Joindre plusieurs tables pour connecter de grandes tables Le champ de connexion a été indexé
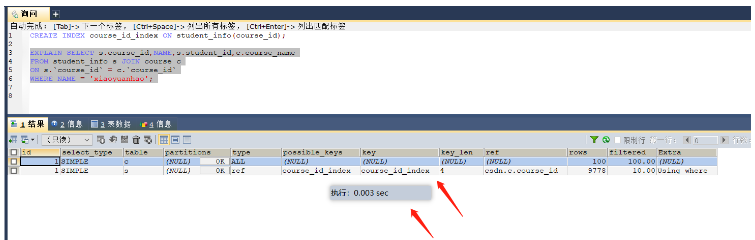
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
Avant la création de l'index, cela a pris 0,697 s
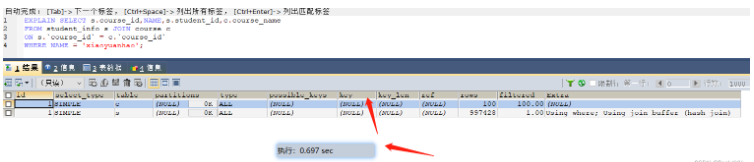
Après la création de l'index, l'index a été utilisé et cela a pris 0,003 s
Petite conduite de table. grande table :
En parcourant les petites tables une à une et en créant un index sur le champ de connexion dans la grande table, la requête peut être accélérée dans ce cas, à chaque fois le course_id dans la table cours et le cours_id de l'étudiant dans la table. La table des étudiants est supprimée pour l'opération de connexion, et le course_id de l'étudiant dans la table des étudiants est connecté. Course_id peut être indexé
Scénario 6 : utiliser le préfixe de la chaîne pour créer un index
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
La raison de l'indexation du préfixe. :
Comme certaines chaînes sont très longues, si la chaîne entière est indexée, l'index prendra beaucoup de temps Grand espace
Puisque la chaîne entière doit être stockée, les éléments de données seront très volumineux , la profondeur de l'arbre d'index sera approfondie et la vitesse de récupération diminuera
Bien que deux chaînes puissent sembler identiques dans l'index, Cependant, l'efficacité de l'opération de retour de table basée sur la clé primaire est toujours relativement élevé
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



