
 base de données
tutoriel mysql
Quelle est la raison pour laquelle les tables temporaires MySQL peuvent avoir des noms en double ?
base de données
tutoriel mysql
Quelle est la raison pour laquelle les tables temporaires MySQL peuvent avoir des noms en double ?
Quelle est la raison pour laquelle les tables temporaires MySQL peuvent avoir des noms en double ?

Aujourd'hui, nous commencerons par cette question : Quelles sont les caractéristiques des tables temporaires et à quels scénarios conviennent-elles ?
Ici, je dois d'abord vous aider à clarifier un problème facilement mal compris : certaines personnes peuvent penser que les tables temporaires sont des tables mémoire. Or, ces deux notions sont complètement différentes.
Memory table fait référence à une table utilisant le moteur Memory. La syntaxe de création de table est create table …engine=memory. **Les données de ce type de table sont stockées dans la mémoire et seront effacées au redémarrage du système, mais la structure de la table demeure. **À l'exception de ces deux fonctionnalités qui semblent "étranges", par rapport aux autres fonctionnalités, il s'agit d'une table normale.
Tableau temporaire, différents types de moteurs peuvent être utilisés. Si vous utilisez la table temporaire du moteur InnoDB ou du moteur MyISAM, les données sont écrites sur le disque lors de l'écriture. Bien entendu, les tables temporaires peuvent également utiliser le moteur Memory.
Après avoir clarifié la différence entre les tables mémoire et les tables temporaires, examinons les caractéristiques des tables temporaires.
Caractéristiques des tables temporaires
Pour faciliter la compréhension, jetons un œil à la séquence d'opérations suivante :

Comme vous pouvez le constater, les tables temporaires ont les caractéristiques d'utilisation suivantes :
La syntaxe de création une table, c'est créer une table temporaire ….
Les autres threads ne peuvent pas accéder à la table temporaire créée par une session, elle n'est visible que par cette session. Par conséquent, la table temporaire t créée par la session A dans la figure est invisible pour la session B.
Une table temporaire peut avoir le même nom qu'une table normale.
Lorsqu'il y a des tables temporaires et des tables ordinaires portant le même nom dans la session A, l'instruction showcreate et les instructions add, delete, modifier et query accèdent à la table temporaire. La commande
showtables n'affiche pas les tables temporaires.
Étant donné que la table temporaire n'est accessible que par la session qui l'a créée, la table temporaire sera automatiquement supprimée à la fin de la session.
Le scénario d'optimisation des jointures de l'article précédent est particulièrement adapté à l'utilisation de tables temporaires car les tables temporaires disposent de cette fonctionnalité. Pourquoi? Les raisons incluent principalement les deux aspects suivants :
Les tables temporaires de différentes sessions peuvent être renommées Si plusieurs sessions effectuent l'optimisation des jointures en même temps, il n'y a pas lieu de s'inquiéter de l'échec de la création de table dû. aux noms de tables répétés.
Pas besoin de vous soucier de la suppression des données. Si une table normale est utilisée, si le client est déconnecté anormalement lors de l'exécution du processus, ou si la base de données est redémarrée anormalement, les tables de données générées lors du processus intermédiaire doivent être spécifiquement nettoyées. Puisque la table temporaire sera automatiquement recyclée, cette opération supplémentaire n'est pas requise.
Application des tables temporaires
Comme il n'y a pas lieu de s'inquiéter des conflits de noms en double entre les threads, les tables temporaires sont souvent utilisées dans le processus d'optimisation des requêtes complexes. Parmi eux, la requête inter-bases de données du système de sous-base de données et de sous-tables est un scénario d'utilisation typique.
Généralement, le scénario de partitionnement de base de données et de table consiste à distribuer une table logiquement grande à différentes instances de base de données. Par exemple. Pour un champ f donné, divisez la grande table ht en 1024 sous-tables et distribuez ces sous-tables à 32 instances de base de données. Comme le montre la figure ci-dessous :
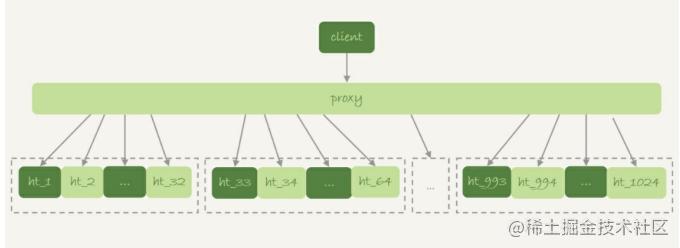
Généralement, ce type de système de sous-base de données et de sous-tables a un proxy de couche intermédiaire. Cependant, il existe également des solutions qui permettent au client de se connecter directement à la base de données, c'est-à-dire qu'il n'y a pas de couche proxy.
Dans cette architecture, la sélection des clés de partition est basée sur le principe de « réduire les opérations croisées entre bases de données et tables croisées ». Si la plupart des instructions contiennent la condition équivalente à f, alors f doit être utilisé comme clé de partition. Le proxy qui a analysé l'instruction SQL décidera vers quelle table l'acheminer pour la requête.
Par exemple, la déclaration suivante :
select v from ht where f=N;
À ce stade, nous pouvons utiliser les règles de sous-table (par exemple, N%1024) pour confirmer sur quelle sous-table les données requises sont placées. Ce type d'instruction n'a besoin d'accéder qu'à une seule sous-table et constitue la forme d'instruction la plus populaire dans le schéma de sous-base de données et de sous-table.
Cependant, s'il y a un autre index k sur cette table et que l'instruction de requête ressemble à ceci :
select v from ht where k >= M order by t_modified desc limit 100;
À ce stade, puisque le champ de partition f n'est pas utilisé dans les conditions de requête, nous ne pouvons trouver que toutes les partitions qui répondent les conditions Toutes les lignes, puis effectuez l'ordre par opération de manière uniforme. Dans ce cas, deux idées sont couramment utilisées.
La première idée est d'implémenter le tri dans le code de processus de la couche proxy. L'avantage de cette méthode est que la vitesse de traitement est rapide. Après avoir récupéré les données de la sous-base de données, elle peut directement participer au calcul en mémoire. Cependant, les inconvénients de cette solution sont également évidents :
- nécessite un travail de développement relativement important. L'énoncé que nous avons donné en exemple est relativement simple. S'il s'agit d'opérations complexes, comme regrouper ou même rejoindre, les capacités de développement de la couche intermédiaire seront relativement élevées ;
对proxy端的压力比较大,尤其是很容易出现内存不够用和CPU瓶颈的问题。
另一种思路就是,把各个分库拿到的数据,汇总到一个MySQL实例的一个表中,然后在这个汇总实例上做逻辑操作。
比如上面这条语句,执行流程可以类似这样:
在汇总库上创建一个临时表temp_ht,表里包含三个字段v、k、t_modified;
在各个分库上执行
select v,k,t_modified from ht_x where k >= M order by t_modified desc limit 100;把分库执行的结果插入到temp_ht表中;
执行
select v from temp_ht order by t_modified desc limit 100;
得到结果。 这个过程对应的流程图如下所示:
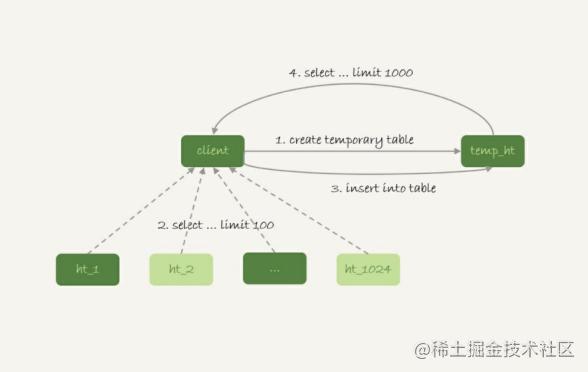
在实践中,我们往往会发现每个分库的计算量都不饱和,所以会直接把临时表temp_ht放到32个分库中的某一个上。
为什么临时表可以重名?
你可能会问,不同线程可以创建同名的临时表,这是怎么做到的呢?
我们在执行
create temporary table temp_t(id int primary key)engine=innodb;
这个语句的时候,MySQL要给这个InnoDB表创建一个frm文件保存表结构定义,还要有地方保存表数据。
这个frm文件放在临时文件目录下,文件名的后缀是.frm,前缀是“#sql{进程id}_ {线程id}_ 序列号”。
从文件名的前缀规则,我们可以看到,其实创建一个叫作t1的InnoDB临时表,MySQL在存储上认为我们创建的表名跟普通表t1是不同的,因此同一个库下面已经有普通表t1的情况下,还是可以再创建一个临时表t1的。
先来举一个例子。

进程号为1234的进程,它的线程id分别为4和5,分别属于会话A和会话B。因此,可以看出,session A和session B创建的临时表在磁盘上的文件名不会冲突。
MySQL维护数据表,除了物理上要有文件外,内存里面也有一套机制区别不同的表,每个表都对应一个table_def_key。
一个普通表的table_def_key的值是由“库名+表名”得到的,所以如果你要在同一个库下创建两个同名的普通表,创建第二个表的过程中就会发现table_def_key已经存在了。
而对于临时表,table_def_key在“库名+表名”基础上,又加入了“server_id+thread_id”。
也就是说,session A和session B创建的两个临时表t1,它们的table_def_key不同,磁盘文件名也不同,因此可以并存。
在实现上,每个线程都维护了自己的临时表链表。这样每次session内操作表的时候,先遍历链表,检查是否有这个名字的临时表,如果有就优先操作临时表,如果没有再操作普通表;在session结束的时候,对链表里的每个临时表,执行 “DROPTEMPORARY TABLE +表名”操作。
你会注意到,在binlog中也有DROP TEMPORARY TABLE命令的记录。你一定会觉得奇怪,临时表只在线程内自己可以访问,为什么需要写到binlog里面?这,就需要说到主备复制了。
临时表和主备复制
既然写binlog,就意味着备库需要。 你可以设想一下,在主库上执行下面这个语句序列:
create table t_normal(id int primary key, c int)engine=innodb;/*Q1*/ create temporary table temp_t like t_normal;/*Q2*/ insert into temp_t values(1,1);/*Q3*/ insert into t_normal select * from temp_t;/*Q4*/
如果关于临时表的操作都不记录,那么在备库就只有create table t_normal表和insert intot_normal select * fromtemp_t这两个语句的binlog日志,备库在执行到insert into t_normal的时候,就会报错“表temp_t不存在”。
你可能会说,如果把binlog设置为row格式就好了吧?因为binlog是row格式时,在记录insert intot_normal的binlog时,记录的是这个操作的数据,即:write_rowevent里面记录的逻辑是“插入一行数据(1,1)”。
确实是这样。如果当前的binlog_format=row,那么跟临时表有关的语句,就不会记录到binlog里。也就是说,只在binlog_format=statment/mixed的时候,binlog中才会记录临时表的操作。
在这种情况下,执行创建临时表语句的操作会被传递到备用数据库进行处理,从而触发备用数据库的同步线程创建相应的临时表。主库在线程退出的时候,会自动删除临时表,但是备库同步线程是持续在运行的。因此,我们需要在主数据库中再运行一个DROP TEMPORARY TABLE命令以便备用数据库执行。
Peu importe si différents threads de la base de données principale créent des tables temporaires portant le même nom, mais comment gérer le transfert vers la base de données de secours pour l'exécution ?
Maintenant, laissez-moi vous donner un exemple dans la séquence suivante, l'instance S est la base de données de secours de M.

Deux sessions sur la base de données principale M ont créé une table temporaire t1 du même nom. Ces deux instructions de création de table temporaire t1 seront transmises à la base de données de secours S.
Cependant, le thread du journal d'application de la base de données de secours est partagé, ce qui signifie que l'instruction create doit être exécutée deux fois dans le thread d'application. Malgré la réplication multithread, il est toujours possible d'être affecté au même travailleur dans la bibliothèque esclave pour exécution. Alors, cela amènera-t-il le thread de synchronisation à signaler une erreur ?
Évidemment non, sinon la table temporaire serait un bug. En d’autres termes, le thread de sauvegarde doit traiter les deux tables t1 comme des tables temporaires indépendantes à traiter pendant l’exécution. Comment y parvient-on ? Lorsque MySQL enregistre le binlog, il écrira l'ID de thread de la bibliothèque principale pour exécuter cette instruction dans le binlog. De cette façon, le thread d'application dans la base de données de secours peut connaître l'ID du thread de la base de données principale qui exécute chaque instruction, et utiliser cet ID de thread pour construire la table_def_key de la table temporaire :
La table temporaire t1 de la session A, la table_def_key dans la base de données de secours est : nom de la bibliothèque + t1 + "ID de serveur de M" + "id_thread_id de la session A" ;
table temporaire t1 de la session B, la clé_def_key dans la base de données de secours est : nom de la bibliothèque + t1 + "ID de serveur de M" + "thread_id de la session B".
Étant donné que table_def_key est différent, ces deux tables ne seront pas en conflit dans le thread d'application de la base de données de secours.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Comment copier des tables dans MySQL
Apr 08, 2025 pm 07:24 PM
Comment copier des tables dans MySQL
Apr 08, 2025 pm 07:24 PM
La copie d'une table dans MySQL nécessite la création de nouvelles tables, l'insertion de données, la définition de clés étrangères, la copie des index, les déclencheurs, les procédures stockées et les fonctions. Les étapes spécifiques incluent: la création d'une nouvelle table avec la même structure. Insérez les données de la table d'origine dans une nouvelle table. Définissez la même contrainte de clé étrangère (si le tableau d'origine en a un). Créer le même index. Créez le même déclencheur (si le tableau d'origine en a un). Créez la même procédure ou fonction stockée (si la table d'origine est utilisée).
 Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Comment voir Mysql
Apr 08, 2025 pm 07:21 PM
Affichez la base de données MySQL avec la commande suivante: Connectez-vous au serveur: MySQL -U Username -P mot de passe Exécuter les bases de données Afficher les bases de données; Commande pour obtenir toutes les bases de données existantes Sélectionnez la base de données: utilisez le nom de la base de données; Tableau de vue: afficher des tables; Afficher la structure de la table: décrire le nom du tableau; Afficher les données: sélectionnez * dans le nom du tableau;
 Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
NAVICAT pour MARIADB ne peut pas afficher directement le mot de passe de la base de données car le mot de passe est stocké sous forme cryptée. Pour garantir la sécurité de la base de données, il existe trois façons de réinitialiser votre mot de passe: réinitialisez votre mot de passe via Navicat et définissez un mot de passe complexe. Affichez le fichier de configuration (non recommandé, haut risque). Utilisez des outils de ligne de commande système (non recommandés, vous devez être compétent dans les outils de ligne de commande).
 Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Copier et coller dans MySQL incluent les étapes suivantes: Sélectionnez les données, copiez avec Ctrl C (Windows) ou CMD C (Mac); Cliquez avec le bouton droit à l'emplacement cible, sélectionnez Coller ou utilisez Ctrl V (Windows) ou CMD V (Mac); Les données copiées sont insérées dans l'emplacement cible ou remplacer les données existantes (selon que les données existent déjà à l'emplacement cible).
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
