

Index est une structure de données qui aide MySQL à effectuer des requêtes efficaces. Comme la table des matières d'un livre, elle peut accélérer la requête
L'index peut avoir un index B-Tree et un index Hash. L'index est implémenté dans le moteur de stockage
InnoDB / MyISAM ne prend en charge que l'index B-Tree
Memory/Heap prend en charge l'index B-Tree et l'index Hash
B-Tree
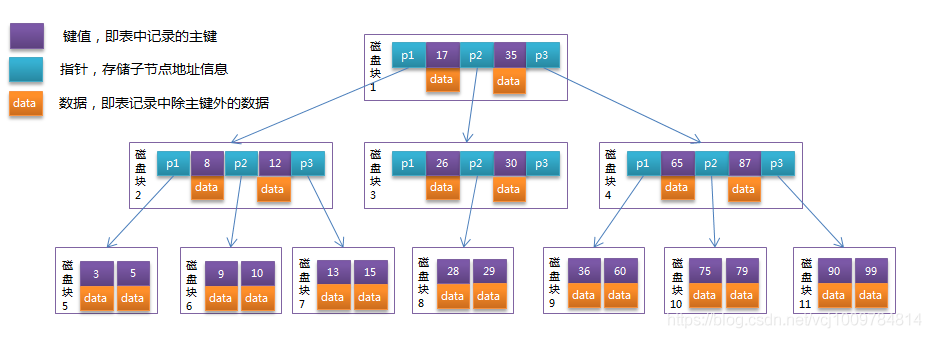
B-Tree est une structure de données très appropriée pour les opérations sur disque. Il s’agit d’un arbre de recherche équilibré à plusieurs voies. Sa hauteur est généralement de 2 à 4, et ses nœuds non-feuilles et ses nœuds feuilles stockeront les données. Tous ses nœuds feuilles sont sur la même couche. L'image ci-dessous est un B-Tree
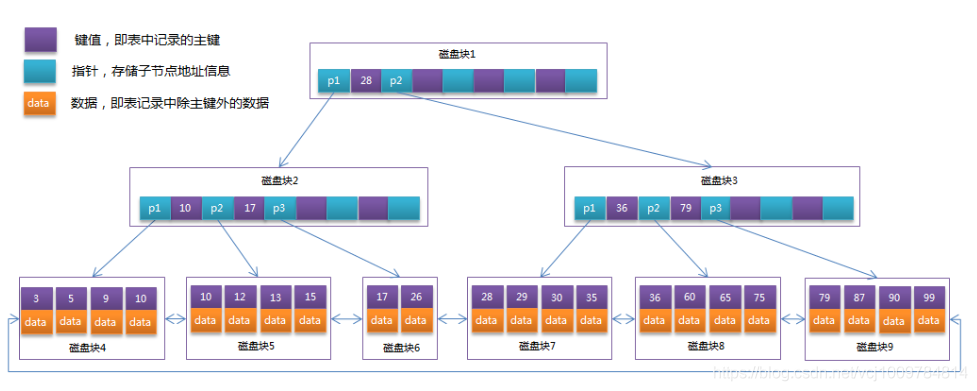
B+ Tree : L'arbre B+ est une optimisation basée sur B-Tree. La principale différence entre celui-ci et l'arbre B est que toutes les données de l'arbre B+ sont stockées dans les nœuds feuilles et que les nœuds feuilles sont reliés entre eux par une liste chaînée. L'image ci-dessous est un arbre B+
La taille d'une page dans InnoDB est de 16 Ko (une page est un nœud sur l'arborescence B+ si la clé primaire de la table est INT et la taille est de 4 octets). , alors ce nœud Il peut également stocker des valeurs clés 4K. En supposant que les pointeurs et les valeurs clés occupent la même taille, alors un arbre B+ d'une hauteur de 3 a 2048 nœuds dans la deuxième couche et le nombre de nœuds feuilles. dans la troisième couche est 2048*2048 = 4194304, un nœud fait 16 Ko, il peut accueillir un total de 67108864 Ko, soit 65 536 Mo, soit 64 Go de données.
Étant donné que les nœuds feuilles sont reliés entre eux par une liste chaînée, s'ils sont classés par colonne d'index, ils seront triés par défaut, l'efficacité sera donc très élevée.
Indice MyISAM
L'index et les données MyISAM sont stockés séparément. Dans l'index de clé primaire de MyISAM, l'adresse de l'enregistrement est stockée dans le nœud feuille de l'arbre B+. Par conséquent, MyISAM doit passer par 2 IO via la requête d'index
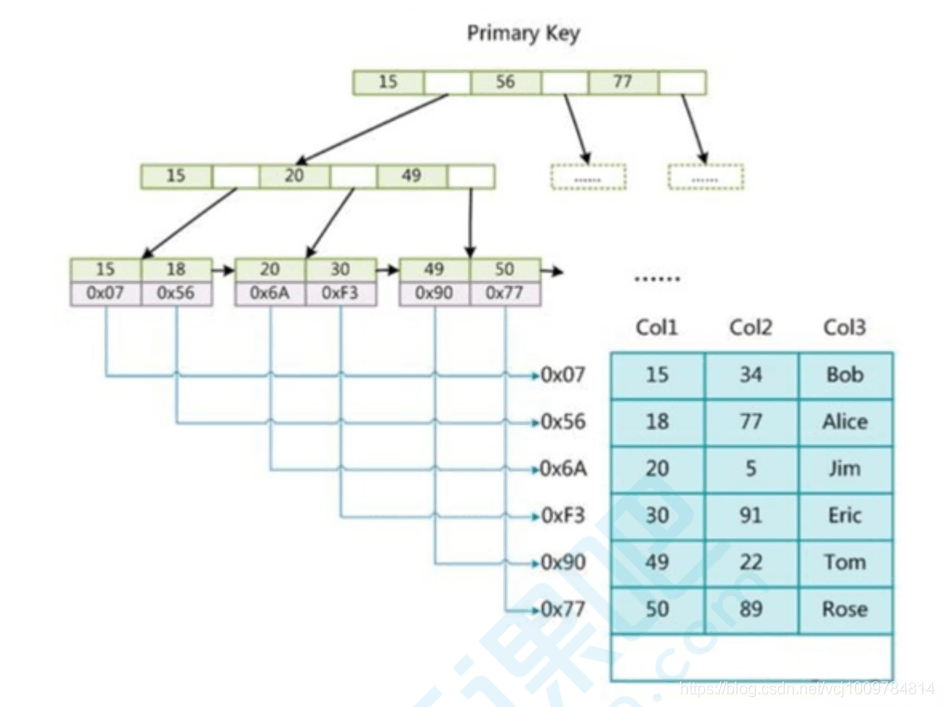
L'index auxiliaire de MyISAM est le même que celui de la requête d'index. index de clé primaire. La seule différence est Oui, la clé de l'index auxiliaire peut être répétée, mais la clé de l'index de clé primaire ne peut pas être répétée
Index InnoDB
Les données et l'index InnoDB sont stockés ensemble, également appelés clusterisés. indice. Les données sont indexées par la clé primaire et stockées sur les nœuds feuilles de l'arborescence B+ d'index de clé primaire.
Index de clé primaire InnoDB, les données sont déjà incluses dans les nœuds feuilles, c'est-à-dire que l'index et les données sont stockés ensemble, ce qui est un index clusterisé.
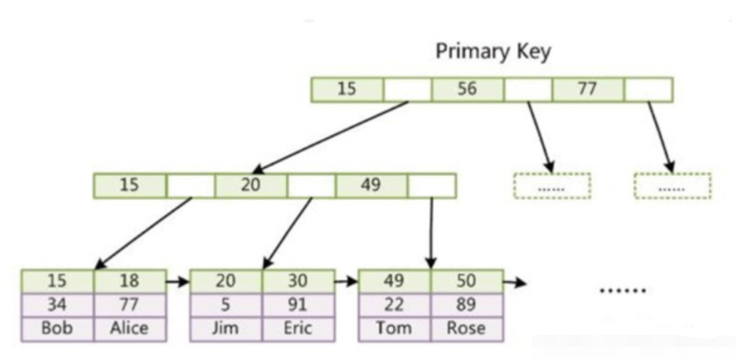
Index auxiliaire d'InnoDB, le nœud feuille stocke la valeur de la clé primaire au lieu de l'adresse. L'utilisation de l'index auxiliaire nécessite deux recherches.
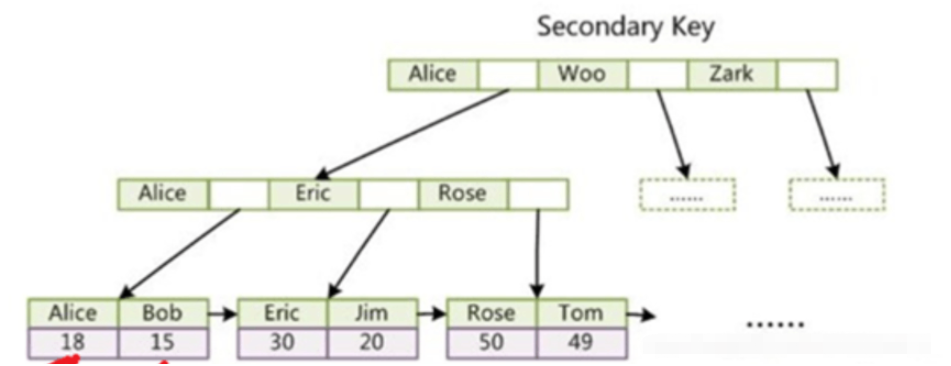
La différence entre les index InnoDB et MyISAM :
InnoDB utilise un index clusterisé et ses nœuds feuilles d'index de clé primaire stockent les données directement, tandis que les nœuds feuilles de son index auxiliaire stockent la valeur de la clé primaire
MyISAM Lors de l'utilisation d'un index non clusterisé, les données et l'index ne sont pas dans le même fichier. Le nœud feuille dans l'index de clé primaire stocke l'adresse de l'enregistrement de ligne, et le nœud feuille dans l'index auxiliaire stocke également l'adresse. adresse de l'enregistrement, seule l'adresse de l'index auxiliaire peut être répétée, mais la clé de l'index de clé primaire ne peut pas être répétée
Question:
Pourquoi InnoDB n'utilise-t-il pas un champ trop long comme clé primaire ?
Une clé primaire trop longue fera que l'index auxiliaire prendra beaucoup de place
Pourquoi est-il recommandé à InnoDB d'utiliser des clés primaires à incrémentation automatique ?
Si une clé primaire à augmentation automatique est utilisée, chaque fois qu'un nouvel enregistrement est inséré, le nouvel enregistrement sera ajouté séquentiellement à la position suivante du nœud d'index actuel. Lorsqu'une page est pleine, une nouvelle page sera ouverte, ainsi. créer la structure d'index Il est très compact et ne nécessite pas de déplacer les données existantes à chaque fois qu'elles sont insérées, ce qui est très efficace. Si vous n'utilisez pas de clé primaire à incrémentation automatique, vous devez choisir une position d'insertion à chaque fois que vous insérez un nouvel enregistrement, et vous devrez peut-être déplacer les données, ce qui rend l'efficacité inefficace et la structure d'index non compacte
Pourquoi utiliser un arbre B+ ? Sans B-tree
L'index lui-même est également relativement volumineux et est généralement stocké sur disque. L'index et les données peuvent être stockés séparément (index non clusterisé de MyISAM) ou ils peuvent être stockés ensemble (index clusterisé d'InnoDB)
Avantages
Réduire les coûts d'E/S et améliorer l'efficacité des requêtes de données
Réduire les coûts de tri (les colonnes indexées seront automatiquement triées et l'efficacité sera grandement améliorée en utilisant l'ordre par )
Inconvénients
Les index occuperont un espace de stockage supplémentaire
Les index réduiront l'efficacité de la mise à jour des données des tables. Lors de l'ajout, de la suppression ou de la modification d'opérations, vous devez non seulement sauvegarder les données, mais également mettre à jour l'index correspondant
index à une seule colonne
index de clé primaire
unique index
index ordinaire
Index combiné
Créer un index
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
Supprimer l'index
DROP INDEX index_name ON table_name;
Scénarios où l'indexation est requise
fréquemment utilisé comme conditions de requête Colonne, l'index doit être construit
Dans une association multi-tables, les champs associés doivent être indexés
Champs triés dans la requête, l'index doit être construit
Scénarios dans lesquels l'indexation n'est pas applicable
Écrire plusieurs lectures Peu de tables ne conviennent pas à la création d'index
Les champs fréquemment mis à jour ne conviennent pas à la création d'index
Il y a un utilisateur table dont l'index est le suivant

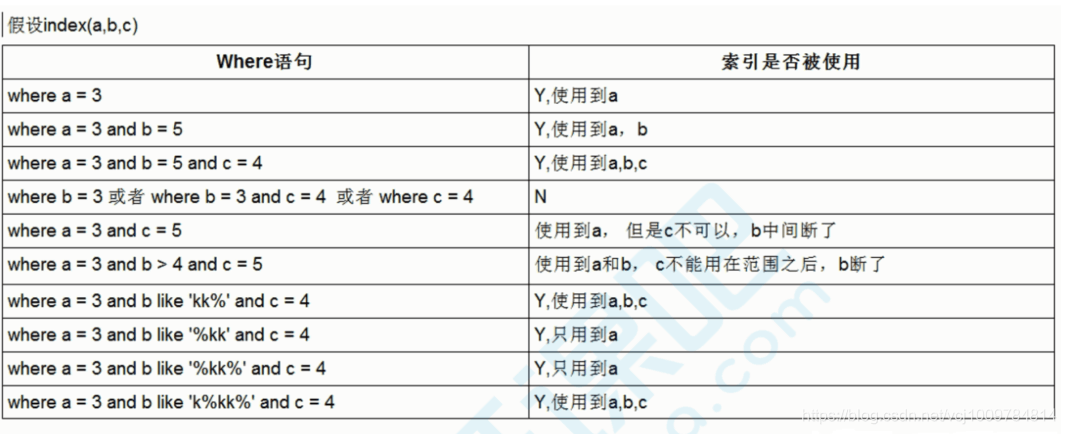
où nom, les trois champs âge, adresse sont utilisés comme un index combiné
Vous pouvez utiliser expliquer pour effectuer une analyse des performances sur une certaine instruction SQL
explain select * from user where name = 'am';

possible_keys
Index éventuellement utilisés
key
Index actuellement utilisés
key_len
La longueur de l'index utilisé pour la requête
ref
S'il s'agit d'une requête équivalente, ce sera const
rows
L'estimation nombre de lignes à analyser (pas une valeur exacte)
extra
Informations supplémentaires, telles que
utiliser où
signifie que les résultats renvoyés par le moteur de stockage doivent être filtrés au niveau de la couche SQL
utiliser index
signifie qu'il n'est pas nécessaire d'interroger la table. Généralement, cette valeur sera utilisée lorsqu'un index de couverture est utilisé. L'index de couverture signifie que les colonnes de la sélection sont toutes des colonnes d'index. La requête qui n'a pas besoin d'être renvoyée à la table signifie que vous pouvez obtenir la valeur de la colonne d'index directement en accédant à l'index auxiliaire, et il n'est pas nécessaire d'aller à l'index de clé primaire pour récupérer les enregistrements
en utilisant la condition d'index
MySQL prend en charge les fonctionnalités ICP après 5.6.x (Index Condition Pushdown), vous pouvez transmettre les conditions de vérification à la couche du moteur de stockage. Les enregistrements qui ne remplissent pas les conditions ne sont pas lus directement, au lieu d'être lus d'abord, puis ensuite. filtré au niveau de la couche SQL Layer comme auparavant, ce qui réduit le moteur de stockage. Le nombre de lignes analysées par la couche

en utilisant le tri de fichiers
L'index ne peut pas être utilisé lors du tri
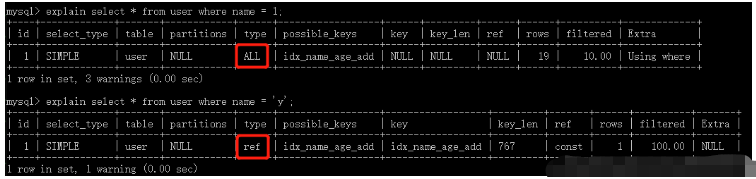
type
système : il n'y a qu'une seule ligne de données dans la table, ou la table est vide
const : utilisez un index unique ou un index de clé primaire, et interrogez avec où équivalent, l'enregistrement renvoyé est une ligne, également appelée analyse d'index unique

ref : Pour un index non unique, utilisez la condition Where équivalente ou une requête pour la règle de préfixe la plus à gauche.
Ce qui suit est la règle de préfixe la plus à gauche qui est satisfaite, c'est-à-dire que pour idx_name_age_add, le préfixe le plus à gauche est satisfait et le premier index est name

range : analyse de plage d'index, courante dans >, <, between, in, like et d'autres requêtes


Notez que lorsque j'aime, le caractère générique % ne peut pas être placé au début, sinon cela provoquera une analyse complète de la table

index : Il n'y a pas de correspondance exacte sur l'index, mais il n'est pas nécessaire d'interroger la table


all : Scannez la table complète, puis filtrez le enregistrements qui répondent aux exigences de la couche SQL Layer
全值匹配
在索引列上使用等值查询
explain select * from user where name = 'y' and age = 15;

2. 最左前缀
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age = 15;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
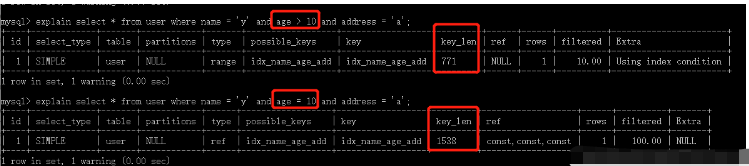
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 ),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
9. 索引字段不要用or

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



