
 base de données
Redis
Quel est le principe de l'algorithme commun de limitation de courant de Redis et comment le mettre en œuvre
base de données
Redis
Quel est le principe de l'algorithme commun de limitation de courant de Redis et comment le mettre en œuvre
Quel est le principe de l'algorithme commun de limitation de courant de Redis et comment le mettre en œuvre

Introduction
La limite de taux fait référence au fait d'autoriser uniquement les événements spécifiés à entrer dans le système. L'excédent se verra refuser le service, sera mis en file d'attente ou attendu, déclassé, etc.
Les schémas courants de limitation de taux sont les suivants :
. Fenêtre de temps fixe
La fenêtre de temps fixe est l'un des algorithmes de limitation de courant les plus courants. La notion de fenêtre correspond à l'unité de temps limite actuelle dans le scénario limite courant.
Principe
La chronologie est divisée en plusieurs fenêtres indépendantes et de taille fixe
La requête tombant dans chaque fenêtre temporelle augmentera le compteur de 1
Si le compteur dépasse le seuil limite actuel ; , Les demandes ultérieures tombant dans cette fenêtre seront rejetées. Mais lorsque le temps atteint la fenêtre horaire suivante, le compteur sera réinitialisé à 0.
Exemple de description
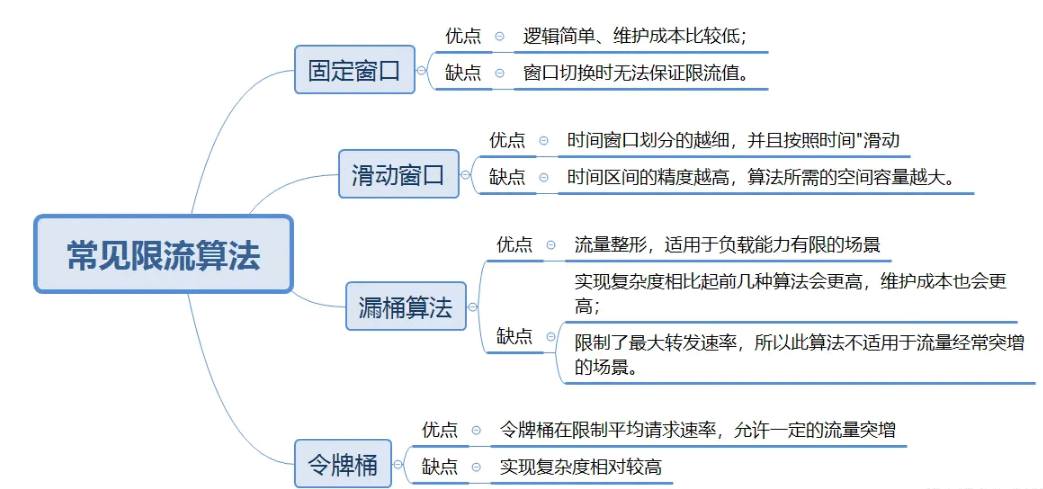
Instructions : Le scénario comme indiqué ci-dessus consiste à limiter le débit à 10 fois par seconde, la taille de la fenêtre est de 1 seconde, chaque carré représente une demande, le carré vert représente une demande normale , et le rouge La méthode représente les requêtes limitées en courant. Dans le scénario de 10 fois par seconde, en regardant de gauche à droite, après la saisie de 10 requêtes, toutes les requêtes suivantes seront limitées en courant.
Avantages et inconvénients
Avantages :
Logique simple et coût de maintenance relativement faible
Inconvénients :
La valeur limite actuelle ne peut pas être garantie lors du changement de fenêtre ;
Implémentation associée
L'implémentation spécifique de la fenêtre de temps fixe peut être implémentée en utilisant Redis pour appeler le script de limitation de courant Lua.
Script de limitation de débit
local key = KEYS[1]
local count = tonumber(ARGV[1])
local time = tonumber(ARGV[2])
local current = redis.call('get', key)
if current and tonumber(current) > count then
return tonumber(current)
end
current = redis.call('incr', key)
if tonumber(current) == 1 then
redis.call('expire', key, time)
end
return tonumber(current)Implémentation spécifique
public Long ratelimiter(String key ,int time,int count) throws IOException
{
Resource resource = new ClassPathResource("ratelimiter.lua");
String redisScript = IOUtils.toString(resource.getInputStream(), StandardCharsets.UTF_8);
List<String> keys = Collections.singletonList(key);
List<String> args = new ArrayList<>();
args.add(Integer.toString(count));
args.add(Integer.toString(time));
long result = redisTemplate.execute(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
Object nativeConnection = connection.getNativeConnection();
if (nativeConnection instanceof Jedis)
{
return (Long) ((Jedis) nativeConnection).eval(redisScript, keys, args);
}
return -1l;
}
});
return result;
}Test
@RequestMapping(value = "/RateLimiter", method = RequestMethod.GET)
public String RateLimiter() throws IOException
{
int time=3;
int count=1;
String key="redis:ratelimiter";
Long number=redisLockUtil.ratelimiter(key, time, count);
logger.info("count:{}",number);
Map<String, Object> map =new HashMap<>();
if(number==null || number.intValue()>count)
{
map.put("code", "-1");
map.put("msg", "访问过于频繁,请稍候再试");
}else{
map.put("code", "200");
map.put("msg", "访问成功");
}
return JSON.toJSONString(map);
}Instructions :Le test est accessible une fois toutes les 3 secondes. Si le nombre dépasse la limite, une erreur sera affichée.
Fenêtre temporelle glissante
L'algorithme de fenêtre temporelle glissante est une amélioration de l'algorithme de fenêtre temporelle fixe. Dans l'algorithme de fenêtre glissante, il est également nécessaire d'interroger dynamiquement la fenêtre pour la requête en cours. Mais chaque élément de la fenêtre est une fenêtre enfant. Le concept de sous-fenêtre est similaire à la fenêtre fixe de la solution 1, et la taille de la sous-fenêtre peut être ajustée dynamiquement.
Principe de mise en œuvre
Divisez le temps unitaire en plusieurs intervalles, généralement divisés de manière égale en plusieurs petites périodes de temps
Il y a un compteur dans chaque intervalle, et une demande tombe dans cet intervalle, le compteur dans celui-ci ; l'intervalle sera incrémenté de un ;
Chaque période de temps passe, la fenêtre temporelle glissera d'un espace vers la droite, supprimant l'intervalle le plus ancien et incorporant le nouveau
-
Lors du calcul du nombre total de demandes dans l'intervalle ; toute la fenêtre de temps, les compteurs de tous les segments de temps seront accumulés. Si le nombre total dépasse la limite, toutes les demandes de cette fenêtre seront rejetées.
Exemple de description
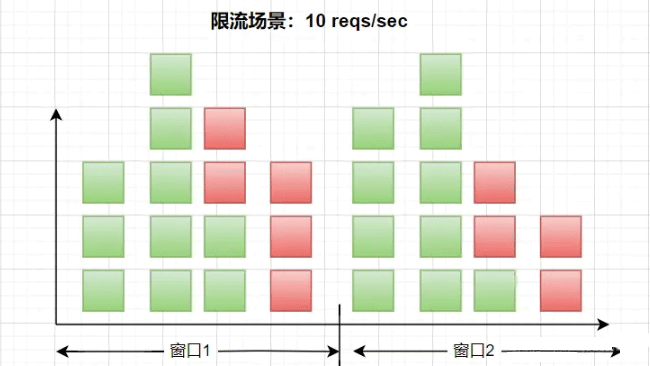
Instructions : Par exemple, la scène dans l'image ci-dessus est limitée à 100 fois par minute. La dimension temporelle de chaque sous-fenêtre est définie sur 1 seconde, donc une fenêtre d'une minute comporte 60 sous-fenêtres. De cette façon, chaque fois qu'une requête arrive, lorsque nous calculons dynamiquement cette fenêtre, nous devons la retrouver jusqu'à 60 fois. La complexité temporelle est passée d'un niveau linéaire à un niveau constant, et la complexité temporelle sera relativement inférieure.
Implémentation spécifique
Concernant l'implémentation de la fenêtre temporelle glissante, vous pouvez utiliser sentinel L'utilisation de sentinel sera expliquée en détail plus tard.
Algorithme de seau qui fuit
L'algorithme d'entonnoir consiste à remplir d'abord l'entonnoir avec de l'eau, puis à l'écouler à un débit fixe. Lorsque la quantité d'eau entrante dépasse l'eau sortante, l'excès d'eau sera éliminé. Lorsque le volume des requêtes dépasse le seuil limite actuel, la file d'attente du serveur agit comme un compartiment qui fuit. Par conséquent, les demandes supplémentaires se verront refuser le service. L'algorithme de compartiment à fuites est implémenté à l'aide de files d'attente, qui peuvent contrôler la vitesse d'accès du trafic à un débit fixe et obtenir un lissage du trafic.
Principe
Explication :
Placez chaque demande dans une file d'attente de taille fixe en cours
La file d'attente évacuera les demandes à un rythme fixe et cessera de s'écouler si la file d'attente est vide.
Si la file d'attente est pleine, les demandes redondantes seront rejetées directement
Implémentation spécifique
long timeStamp = System.currentTimeMillis(); //当前时间
long capacity = 1000;// 桶的容量
long rate = 1;//水漏出的速度
long water = 100;//当前水量
public boolean leakyBucket()
{
//先执行漏水,因为rate是固定的,所以可以认为“时间间隔*rate”即为漏出的水量
long now = System.currentTimeMillis();
water = Math.max(0, water -(now-timeStamp) * rate);
timeStamp = now;
// 水还未满,加水
if (water < capacity)
{
water=water+100;
return true;
}
//水满,拒绝加水
else
{
return false;
}
}
@RequestMapping(value="/leakyBucketLimit",method = RequestMethod.GET)
public void leakyBucketLimit()
{
for(int i=0;i<20;i++) {
fixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
if(leakyBucket())
{
logger.info("thread name:"+Thread.currentThread().getName()+" "+sdf.format(new Date()));
}
else
{
logger.error("请求频繁");
}
}
});
}
}Token Bucket Algorithm
L'algorithme Token Bucket est une version améliorée basée sur le bucket qui fuit dans le bucket, le jeton. représente la limite supérieure des requêtes autorisées par le système actuel, et le jeton sera mis dans le compartiment à un rythme constant. Lorsque le seau est plein, de nouveaux jetons seront supprimés
Principe
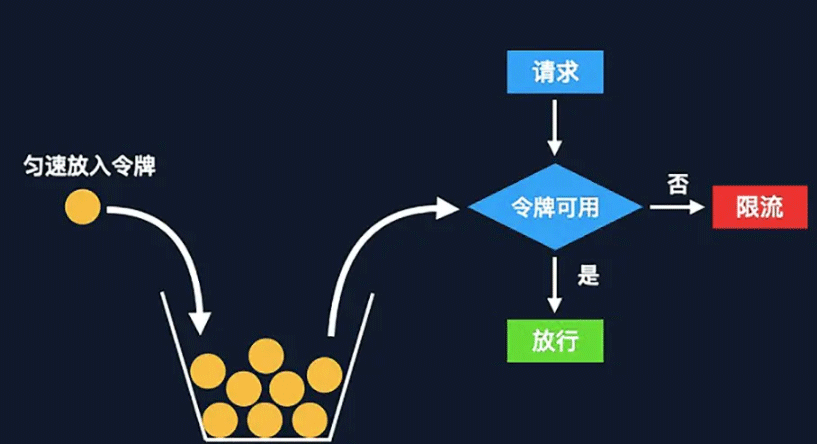
Les jetons sont générés à un taux fixe et placés dans le seau à jetons ;
如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
如果桶空了,则拒绝该请求。
具体实现
@RequestMapping(value="/ratelimit",method = RequestMethod.GET)
public void ratelimit()
{
//每1s产生0.5个令牌,也就是说接口2s只允许调用1次
RateLimiter rateLimiter=RateLimiter.create(0.5,1,TimeUnit.SECONDS);
for(int i=0;i<10;i++) {
fixedThreadPool.execute(new Runnable()
{
@Override
public void run()
{
//获取令牌最大等待10秒
if(rateLimiter.tryAcquire(1,10,TimeUnit.SECONDS))
{
logger.info("thread name:"+Thread.currentThread().getName()+" "+sdf.format(new Date()));
}
else
{
logger.error("请求频繁");
}
}
});
}
}执行结果:
-[pool-1-thread-3] ERROR 请求频繁
[pool-1-thread-2] ERROR 请求频繁
[pool-1-thread-1] INFO thread name:pool-1-thread-1 2022-08-07 15:44:00
[pool-1-thread-8] ERROR [] - 请求频繁
[pool-1-thread-9] ERROR [] - 请求频繁
[pool-1-thread-10] ERROR [] - 请求频繁
[pool-1-thread-7] INFO [] - thread name:pool-1-thread-7 2022-08-07 15:44:03
[pool-1-thread-6] INFO [] - thread name:pool-1-thread-6 2022-08-07 15:44:05
[pool-1-thread-5] INFO [] - thread name:pool-1-thread-5 2022-08-07 15:44:07
[pool-1-thread-4] INFO [] - thread name:pool-1-thread-4 2022-08-07 15:44:09
说明:接口限制为每2秒请求一次,10个线程需要20s才能处理完,但是rateLimiter.tryAcquire限制了10s内没有获取到令牌就抛出异常,所以结果中会有5个是请求频繁的。
小结
固定窗口:实现简单,适用于流量相对均匀分布,对限流准确度要求不严格的场景。
滑动窗口:适用于对准确性和性能有一定的要求场景,可以调整子窗口数量来权衡性能和准确度
漏桶:适用于流量绝对平滑的场景
令牌桶:适用于流量整体平滑的情况下,同时也可以满足一定的突发流程场景
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment afficher le numéro de version de redis
Apr 10, 2025 pm 05:57 PM
Comment afficher le numéro de version de redis
Apr 10, 2025 pm 05:57 PM
Pour afficher le numéro de version redis, vous pouvez utiliser les trois méthodes suivantes: (1) Entrez la commande Info, (2) Démarrez le serveur avec l'option - Version et (3) afficher le fichier de configuration.
 Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Étapes pour résoudre le problème que Redis-Server ne peut pas trouver: Vérifiez l'installation pour vous assurer que Redis est installé correctement; Définissez les variables d'environnement redis_host et redis_port; Démarrer le serveur Redis Redis-Server; Vérifiez si le serveur exécute Redis-Cli Ping.
 Comment la clé est-elle unique pour Redis Query
Apr 10, 2025 pm 07:03 PM
Comment la clé est-elle unique pour Redis Query
Apr 10, 2025 pm 07:03 PM
Redis utilise cinq stratégies pour assurer le caractère unique des clés: 1. Séparation des espaces de noms; 2. Structure de données de hachage; 3. Définir la structure des données; 4. Caractères spéciaux des touches de chaîne; 5. Vérification du script LUA. Le choix de stratégies spécifiques dépend de l'organisation des données, des performances et des exigences d'évolutivité.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment utiliser redis zset
Apr 10, 2025 pm 07:27 PM
Comment utiliser redis zset
Apr 10, 2025 pm 07:27 PM
Les ensembles commandés par Redis (ZSETS) sont utilisés pour stocker des éléments commandés et trier par des scores associés. Les étapes à utiliser ZSET incluent: 1. Créer un ZSET; 2. Ajouter un membre; 3. Obtenez un score de membre; 4. Obtenez un classement; 5. Obtenez un membre dans la gamme de classement; 6. Supprimer un membre; 7. Obtenez le nombre d'éléments; 8. Obtenez le nombre de membres dans la plage de score.
 Comment le cluster redis est-il implémenté
Apr 10, 2025 pm 05:27 PM
Comment le cluster redis est-il implémenté
Apr 10, 2025 pm 05:27 PM
Le cluster Redis est un modèle de déploiement distribué qui permet une expansion horizontale des instances Redis, et est implémentée via la communication inter-nœuds, l'espace clé de la division des emplacements de hachage, l'élection du nœud, la réplication maître-esclave et la redirection de commande: communication inter-nœuds: la communication du réseau virtuel est réalisée via le bus de cluster. Slot de hachage: divise l'espace clé en emplacements de hachage pour déterminer le nœud responsable de la clé. Élection du nœud: au moins trois nœuds maîtres sont nécessaires et un seul nœud maître actif est assuré par le mécanisme électoral. Réplication maître-esclave: le nœud maître est responsable de la rédaction de demandes, et le nœud esclave est responsable des demandes de lecture et de la réplication des données. Redirection de commande: le client se connecte au nœud responsable de la clé et le nœud redirige les demandes incorrectes. Dépannage: détection des défauts, marquer la ligne et re
