
 base de données
tutoriel mysql
Quel est le principe d'indexation et la stratégie d'optimisation de la base de données MySQL ?
base de données
tutoriel mysql
Quel est le principe d'indexation et la stratégie d'optimisation de la base de données MySQL ?
Quel est le principe d'indexation et la stratégie d'optimisation de la base de données MySQL ?

1 Index
Concept d'index
Un index est un fichier spécial qui contient des pointeurs de référence vers tous les enregistrements de la table de données. Vous pouvez créer un index sur une ou plusieurs colonnes de la table et spécifier le type d'index. Chaque type d'index a sa propre implémentation de structure de données.
Le rôle de l'index
La relation entre les tables, les données et les index dans une base de données est similaire à la relation entre les livres, le contenu des livres et les catalogues de livres sur une étagère. L'index joue un rôle similaire à celui d'un catalogue de livres et peut. être utilisé pour localiser et récupérer rapidement des données. Les index peuvent grandement améliorer les performances des bases de données.
Scénarios d'utilisation d'index
Pour envisager de créer un index sur une ou plusieurs colonnes d'une table de base de données, vous devez prendre en compte les points suivants :
La quantité de données est importante et des requêtes conditionnelles sont souvent effectuées sur celles-ci. colonnes.
La fréquence des opérations d'insertion et de modification sur ces colonnes dans cette table de base de données est faible.
Les index occupent de l'espace disque supplémentaire.
2 Classification de l'index
Divisé de la structure de stockage de l'index : index BTree, index de hachage, index de texte intégral FULLTEXT, index RTree
-
Divisé du niveau d'application : index ordinaire, index unique, clé primaire index, index composé
Divisé du type de valeur de clé d'index, index de clé primaire, index auxiliaire (index secondaire)
Divisé de la relation logique entre le stockage des données et la valeur de la clé d'index : index clusterisé (index clusterisé) non -index clusterisé (index non clusterisé) Index)
Divisé du nombre de colonnes d'index : index à colonne unique, index composé
La différence entre l'index B-tree et l'index arbre B+

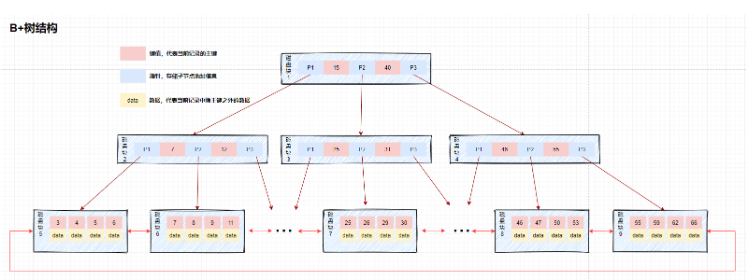
Différence :
L'emplacement de stockage des données est différent : stockage de l'arbre B+ Au niveau du nœud feuille, le B-tree est stocké dans tous les nœuds, ce qui reflète les avantages de l'arbre B+ : le nœud ne stocke pas de données, donc un le nœud peut stocker plus de clés. Cela peut rendre l'arborescence plus courte, ce qui réduit le nombre d'opérations d'E/S. Les performances des requêtes sont stables : chaque requête passe du nœud racine au nœud feuille, la longueur du chemin de la requête est la même, c'est-à-dire que chaque requête est également efficace et la complexité temporelle est fixée à O(log(n))
Pointage des nœuds feuilles : arbre B+ Les nœuds feuilles adjacents sont connectés via des pointeurs. L'arbre B n'a pas de
reflétant les avantages de l'arbre B+ : tous les nœuds feuilles forment une liste chaînée ordonnée, ce qui facilite la recherche de plage
3 Opération d'indexation
Créer un index de clé primaire
-- 在创建表的时候,直接在字段名后指定 primary key create table user1(id int primary key, name varchar(30)); -- 在创建表的最后,指定某列或某几列为主键索引 create table user2(id int, name varchar(30), primary key(id)); -- 创建表以后再添加主键 create table user3(id int, name varchar(30)); alter table user3 add primary key(id);
Caractéristiques de l'index de clé primaire :
- Il y a au plus un index de clé primaire dans une table. Bien sûr, cela peut rendre l'index de clé primaire très efficace (la clé primaire ne peut pas être répétée)
- . Créez la colonne de l'index de clé primaire, sa valeur ne peut pas être nulle et ne peut pas être répétée
- Les colonnes de l'index de clé primaire sont essentiellement int
- Création d'un index unique
-- 在表定义时,在某列后直接指定unique唯一属性。 create table user4(id int primary key, name varchar(30) unique); -- 创建表时,在表的后面指定某列或某几列为unique create table user5(id int primary key, name varchar(30), unique(name)); -- 创建表以后再添加unique create table user6(id int primary key, name varchar(30)); alter table user6 add unique(name);
Copier après la connexionCaractéristiques de l'index unique index :
Dans une table, il peut y avoir plusieurs index uniques
- Efficacité des requêtes Élevée
- Si vous créez un index unique sur une certaine colonne, vous devez vous assurer que cette colonne ne peut pas contenir de données en double
- index ordinaire
--在表的定义最后,指定某列为索引 create table user8(id int primary key, name varchar(20), email varchar(30), index(name) ); --创建完表以后指定某列为普通索引 create table user9(id int primary key, name varchar(20), email varchar(30)); alter table user9 add index(name); -- 创建一个索引名为 idx_name 的索引 create table user10(id int primary key, name varchar(20), email varchar(30)); create index idx_name on user10(name);
Copier après la connexionCaractéristiques des index ordinaires :
Il peut y avoir plusieurs index ordinaires dans une table . Les index ordinaires sont plus couramment utilisés dans le développement réel
- Si une colonne doit être indexée, mais que la colonne a des valeurs en double, alors nous devons utiliser des index ordinaires
- index de requête
- afficher les clés de la table. nom
- mysql> afficher les clés de marchandisesG
*********** 1. ligne **** *******
Table : marchandises <= Nom de la table Non_unique : 0 <= 0 signifie un index unique
Seq_in_index : 1Column_name : goods_id <= Où se trouve l'index Colonne
Collation : A
Cardinalité : 0
Sous_partie : NULL
Emballé : NULL
Null :
Index_type : BTREE <= Index sous forme d'arbre binaire
Commentaire :
1 ligne dans l'ensemble (0,00 sec)
afficher l'index du nom de la table ;
- desc nom de la table
- Supprimer l'index
- Supprimer l'index de clé primaire : modifier le nom de la table, supprimer la clé primaire ;
- Supprimer les autres index : modifier le nom de la table, supprimer le nom de l'index ; le nom de l'index est le champ Key_name dans afficher les clés du nom de la table
-
mysql> alter table user10 drop index idx_name;
Copier après la connexion déposer le nom de l'index sur le nom de la table
mysql> drop index name on user8
- Principe de création d'index
- Les champs qui sont plus fréquemment utilisés comme conditions de requête doivent être indexés
- Les champs peu uniques ne conviennent pas à la création d'un index seuls, même s'ils sont fréquemment utilisés comme conditions de requête
- Les champs mis à jour très fréquemment ne conviennent pas à la création d'un index
- Les champs qui n'apparaissent pas dans la clause Where ne doivent pas créer d'index
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
