

Comment implémenter l'extraction aléatoire dans MySQL

1. Introduction
Il est désormais nécessaire de sélectionner au hasard trois mots à la fois dans une liste de mots.
L'instruction de création de table de cette table est la suivante :
mysql> Create table 'words'(
'id' int(11) not null auto_increment;
'word' varchar(64) default null;
primary key ('id')
) ENGINE=InnoDB;Ensuite, nous y insérons 10 000 lignes de données. Voyons ensuite comment en sélectionner au hasard 3 mots.
2. Table temporaire mémoire
Tout d'abord, on pense généralement à utiliser order by rand() pour implémenter cette logique :
mysql> select word from words order by rand() limit 3;
Bien que cette phrase Les mots sont simples, mais le processus d'exécution est plus compliqué. Nous utilisons expliquer pour voir l'exécution de l'instruction :

Using Temporary dans le champ Extra indique qu'une table temporaire doit être utilisée, et Using filesort indique qu'un tri est requis. C'est-à-dire qu'une opération de tri est nécessaire.
Pour les tables InnoDB, effectuer un tri complet des champs peut réduire l'accès au disque, il sera donc préféré.
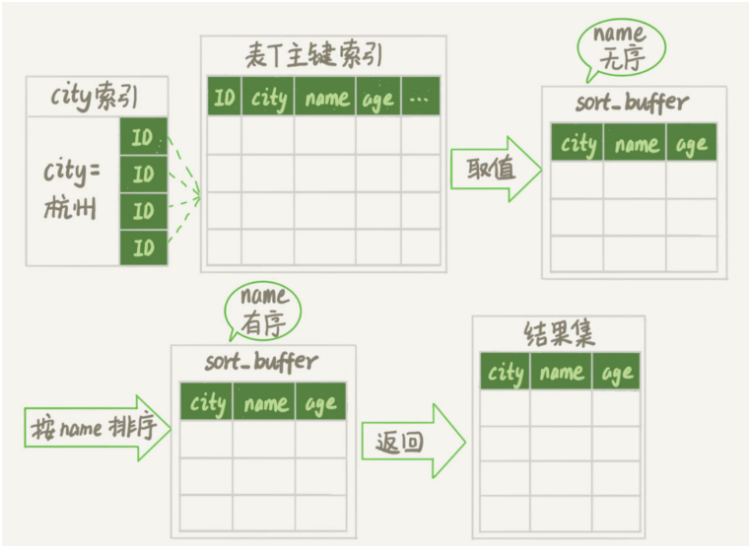
Pour les tables mémoire, le processus de retour de table accède simplement à la mémoire directement pour obtenir les données en fonction de l'emplacement des lignes de données. N'entraînera pas plusieurs accès au disque . Ainsi, à ce stade, MySQL donnera la priorité au tri des rowids.
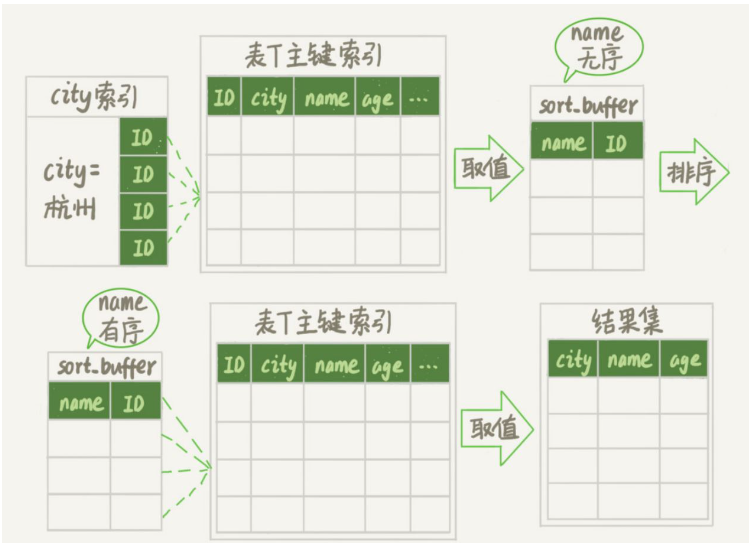
Voyons le processus d'exécution de cette instruction :
# 🎜🎜# Créez une table temporaire. Cette table utilise le moteur de mémoire Il y a deux champs dans la table. Le premier champ est de type double, enregistré sous la forme R, et le deuxième champ est de type varchar(64), enregistré sous la forme W. Et ce tableau n'a pas d'index.
- Dans le tableau des mots, supprimez tous les mots par ordre de clé primaire. Pour chaque mot, appelez la fonction rand() pour générer aléatoirement un nombre décimal aléatoire supérieur à 0 et inférieur à 1, et stockez le nombre décimal aléatoire et le mot dans les champs R et W de la table temporaire respectivement.
- La prochaine étape consiste à trier par champ R
- Initialiser sort_buffer. sort_buffer comprend un type double et un champ entier.
- Retirez la valeur R et les informations de position ligne par ligne de la table de mémoire temporaire et stockez-les respectivement dans les deux champs de sort_buffer.
- sort_buffer est trié en fonction de la valeur R
- Une fois le tri terminé, retirez l'emplacement informations des trois premiers résultats, récupérer le mot correspondant dans la table mémoire temporaire, et le renvoyer au client.
L'emplacement mentionné ci-dessus L'information est en fait l'emplacement de la ligne, qui est le rowid que nous avons mentionné précédemment.
Pour le moteur InnoDB, il existe deux manières de déterminer s'il existe une table de clé primaire :- Pour # 🎜 🎜#Table InnoDB avec clé primaire
, ce rowid est l'identifiant de la clé primaire
Pour - Table InnoDB sans clé primaire
Disons que ce rowid est généré par le système et est utilisé pour identifier différentes lignes.
Par conséquent,
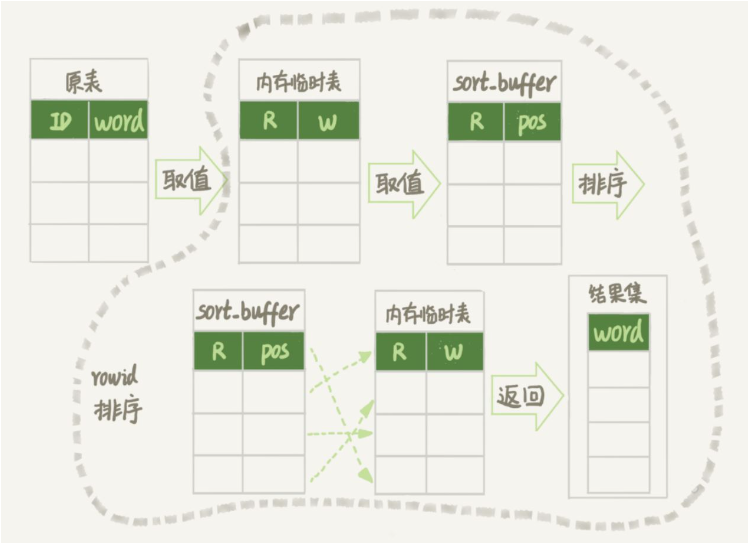
3. Table temporaire de disque
Toutes les tables temporaires ne sont pas des tables temporaires en mémoire
. La configuration tmp_table_size limite la taille de la table temporaire mémoire Si cette taille est dépassée, la table temporaire du disque sera utilisée.Le moteur InnoDB utilise par défaut des tables temporaires de disque . 4. Algorithme de tri de file d'attente prioritaire
Après MySQL5.6, l'algorithme de tri de file d'attente prioritaire #🎜🎜 a été introduit. Cet algorithme ne nécessite pas l'utilisation de fichiers temporaires#. 🎜🎜#. L'algorithme de tri par fusion d'origine nécessite l'utilisation de fichiers temporaires. Parce que lorsque vous utilisez l'algorithme de fusion, vous n'avez en fait besoin que d'obtenir le top 3, mais si vous manquez de tri par fusion, tout est déjà en ordre, provoquant un gaspillage de ressources.L'algorithme de tri de la file d'attente prioritaire ne peut obtenir que les trois premiers. Le processus d'exécution est le suivant :
Pour ces 10 000 (R , rowid ), prenez d'abord les trois premières lignes, construisez un tas et placez la plus grande valeur en haut du tas, comparez avec le plus grand R du tas actuel, si R’ du tas et remplacez-le par (R’, rowid’).- Répétez le processus ci-dessus.
- Le processus est le suivant :
Mais lorsque le nombre limite est relativement large , il est difficile de maintenir le tas, c'est pourquoi l'algorithme de tri par fusion sera utilisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
