
show variables like '%join_buffer%'

Comment optimiser l'instruction de jointure dans MySQL

Jointure simple en boucle imbriquée
Jetons un coup d'œil au fonctionnement de MySQL lors de l'exécution d'une opération de jointure. Quelles sont les méthodes de jointure courantes ?
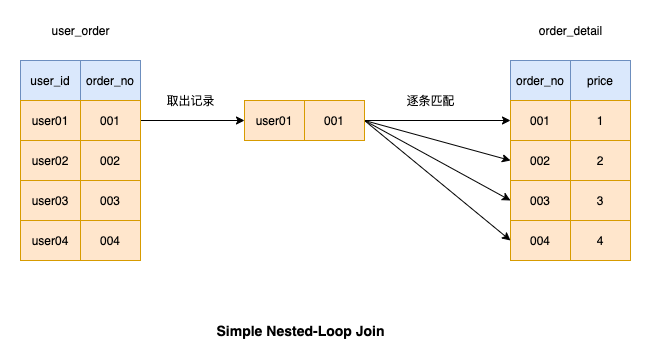
Comme le montre l'image, lorsque nous effectuons l'opération de connexion, la table de gauche est Driven table , et la table de droite est # 🎜🎜#driven table
Simple Nested-Loop Join Cette opération de jointure consiste à prendre un enregistrement de la table pilote, puis à faire correspondre les enregistrements de la table pilotée tableau un par un. Si les conditions correspondent, le résultat sera renvoyé. Ensuite, continuez à faire correspondre l'enregistrement suivant dans la table des pilotes jusqu'à ce que toutes les données de la table des pilotes aient été mises en correspondanceParce qu'il faut du temps pour récupérer les données de la table des pilotes à chaque fois , MySQL n'utilise pas Cet algorithme est utilisé pour effectuer des opérations de connexion Afin d'éviter de démarrer à partir du pilote à chaque fois, la récupération des données de la table prend du temps. Nous pouvons récupérer un lot de données de la table du pilote en une seule fois et effectuer des opérations de correspondance en mémoire. Une fois ce lot de données mis en correspondance, un lot de données est extrait de la table des pilotes et placé dans la mémoire jusqu'à ce que toutes les données de la table des pilotes correspondent.La récupération de données par lots peut réduire considérablement les E/S. opérations, donc l'efficacité d'exécution est relativement élevée, cette opération de connexion est également utilisée par MySQL
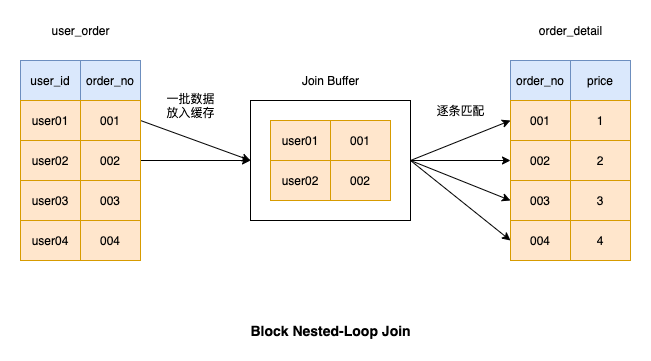
D'ailleurs, cette mémoire a un nom propre dans MySQL, appelé join buffer Nous pouvons exécuter l'instruction suivante pour. afficher la taille du tampon de jointure#🎜🎜 #show variables like '%join_buffer%'
Copier après la connexion
show variables like '%join_buffer%'
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
Le temps d'exécution est de 0,035s
 Le plan d'exécution est le suivant
Le plan d'exécution est le suivant
# 🎜🎜# J'ai vu Using join buffer dans la colonne Extra, indiquant que l'opération de connexion est basée sur
Block Nested-Loop Joinalgorithme
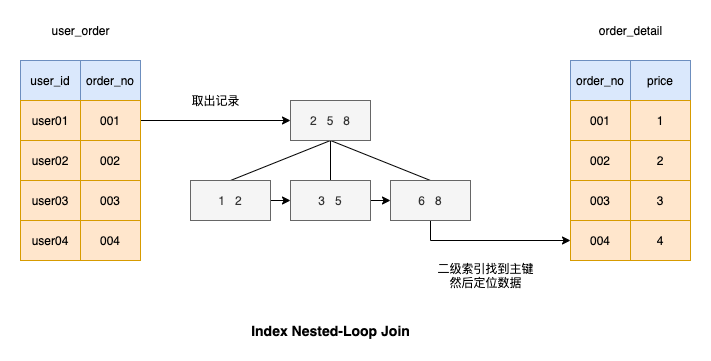
Index Nested-Loop Join # 🎜🎜#Après avoir compris l'algorithme
# 🎜🎜#Après avoir compris l'algorithme
, vous pouvez voir que chaque enregistrement dans la table pilote fera correspondre tous les enregistrements de la table pilotée. Cela prend-il beaucoup de temps. Peut-il être amélioré. Qu'en est-il de l'efficacité de la correspondance des tables pilotées ?
Je suppose que vous avez aussi pensé à cet algorithme, qui consiste à ajouter des index aux colonnes connectées par la table pilotée, afin que le processus de correspondance soit très rapide, comme le montre l'image 
Voyons à quelle vitesse il est nécessaire d'effectuer des requêtes basées sur des jointures basées sur des colonnes d'index ?
select * from t1 straight_join t2 on (t1.id = t2.id)
# 🎜🎜# Le plan d'exécution est le suivant
 Toutes les colonnes des enregistrements de la table pilote ne seront pas placées dans le tampon de jointure, seulement les colonnes dans la liste de requêtes et le filtrage Seules les colonnes de la condition seront placées dans le tampon de jointure, nous n'utilisons donc pas * comme liste de requêtes, nous avons seulement besoin de mettre les colonnes qui nous intéressent dans la liste de requêtes, donc que plus d'enregistrements peuvent être placés dans le tampon de jointure#🎜🎜 #
Toutes les colonnes des enregistrements de la table pilote ne seront pas placées dans le tampon de jointure, seulement les colonnes dans la liste de requêtes et le filtrage Seules les colonnes de la condition seront placées dans le tampon de jointure, nous n'utilisons donc pas * comme liste de requêtes, nous avons seulement besoin de mettre les colonnes qui nous intéressent dans la liste de requêtes, donc que plus d'enregistrements peuvent être placés dans le tampon de jointure#🎜🎜 #
Comment choisir la table des pilotes ?
Maintenant que nous connaissons l'implémentation spécifique de join, parlons d'une question courante, à savoir, comment choisir la table des pilotes ?
 S'il s'agit de l'algorithme Block Nested-Loop Join :
S'il s'agit de l'algorithme Block Nested-Loop Join :
 Lorsque le tampon de jointure est suffisamment grand, qui le fait ? La table pilote n'a aucun impact
Lorsque le tampon de jointure est suffisamment grand, qui le fait ? La table pilote n'a aucun impact
Lorsque le tampon de jointure n'est pas assez grand, vous devez choisir une petite table comme table pilote (la petite table a moins de données et le nombre de fois où elles sont placées dans le tampon de jointure est petit, ce qui réduit le nombre d'analyses de la table)
Si c'est le cas un algorithme de jointure à boucle imbriquée d'indexOn suppose que les lignes de la table de pilotage Le nombre est M, donc M lignes de la table de pilotage doivent être numérisées
# 🎜🎜#Chaque fois qu'une ligne de données est obtenue à partir de la table pilotée, l'index a doit d'abord être recherché, puis l'index de clé primaire est recherché. Le nombre de lignes dans la table pilotée est N. La complexité approximative de la recherche d'un arbre à chaque fois est le logarithme de base 2 N, donc la complexité temporelle de la recherche d'une ligne sur la table pilotée est de 2 ∗ #Chaque ligne de données de la table pilotée doit être recherchée une fois dans la table pilotée. La complexité approximative de l'ensemble du processus d'exécution est M + M ∗ 2∗log2NÉvidemment, M a un plus grand impact sur le nombre de lignes numérisées, donc une petite table doit être utilisée comme table de conduite. Bien entendu, la prémisse de cette conclusion est que l'index de la table pilotée peut être utilisé
Lors de l'exécution de l'opération de jointure, la table pilotée peut être utilisé Index
Utiliser une petite table comme table pilote
Augmenter la taille du tampon de jointure
Ne pas utiliser * comme liste de requêtes, renvoyer uniquement les colonnes requises
En bref, nous pouvons laisser la petite table être la table pilote
Lorsque l'instruction de jointure est exécutée lentement, nous pouvons l'optimiser grâce aux méthodes suivantes
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1666
1666
 14
1425
52
1327
25
1273
29
1253
24
14
1425
52
1327
25
1273
29
1253
24

 Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Laravel est un cadre PHP pour la création facile des applications Web. Il fournit une gamme de fonctionnalités puissantes, notamment: Installation: Installez le Laravel CLI globalement avec Composer et créez des applications dans le répertoire du projet. Routage: définissez la relation entre l'URL et le gestionnaire dans Routes / web.php. Voir: Créez une vue dans les ressources / vues pour rendre l'interface de l'application. Intégration de la base de données: fournit une intégration prête à l'emploi avec des bases de données telles que MySQL et utilise la migration pour créer et modifier des tables. Modèle et contrôleur: le modèle représente l'entité de la base de données et le contrôleur traite les demandes HTTP.
 Mysql et phpmyadmin: fonctionnalités et fonctions de base
Apr 22, 2025 am 12:12 AM
Mysql et phpmyadmin: fonctionnalités et fonctions de base
Apr 22, 2025 am 12:12 AM
MySQL et PHPMyAdmin sont de puissants outils de gestion de la base de données. 1) MySQL est utilisé pour créer des bases de données et des tables et pour exécuter des requêtes DML et SQL. 2) PHPMYADMIN fournit une interface intuitive pour la gestion des bases de données, la gestion de la structure de la table, les opérations de données et la gestion de l'autorisation des utilisateurs.
 MySQL vs d'autres langages de programmation: une comparaison
Apr 19, 2025 am 12:22 AM
MySQL vs d'autres langages de programmation: une comparaison
Apr 19, 2025 am 12:22 AM
Par rapport à d'autres langages de programmation, MySQL est principalement utilisé pour stocker et gérer les données, tandis que d'autres langages tels que Python, Java et C sont utilisés pour le traitement logique et le développement d'applications. MySQL est connu pour ses performances élevées, son évolutivité et son support multiplateforme, adapté aux besoins de gestion des données, tandis que d'autres langues présentent des avantages dans leurs domaines respectifs tels que l'analyse des données, les applications d'entreprise et la programmation système.
 Résolvez le problème de la connexion de la base de données: un cas pratique d'utilisation de la bibliothèque Minii / DB
Apr 18, 2025 am 07:09 AM
Résolvez le problème de la connexion de la base de données: un cas pratique d'utilisation de la bibliothèque Minii / DB
Apr 18, 2025 am 07:09 AM
J'ai rencontré un problème délicat lors du développement d'une petite application: la nécessité d'intégrer rapidement une bibliothèque d'opération de base de données légère. Après avoir essayé plusieurs bibliothèques, j'ai constaté qu'ils avaient trop de fonctionnalités ou ne sont pas très compatibles. Finalement, j'ai trouvé Minii / DB, une version simplifiée basée sur YII2 qui a parfaitement résolu mon problème.
 Méthode d'installation de Laravel Framework
Apr 18, 2025 pm 12:54 PM
Méthode d'installation de Laravel Framework
Apr 18, 2025 pm 12:54 PM
Résumé de l'article: Cet article fournit des instructions détaillées étape par étape pour guider les lecteurs sur la façon d'installer facilement le cadre Laravel. Laravel est un puissant cadre PHP qui accélère le processus de développement des applications Web. Ce didacticiel couvre le processus d'installation des exigences du système à la configuration des bases de données et à la configuration du routage. En suivant ces étapes, les lecteurs peuvent jeter rapidement et efficacement une base solide pour leur projet Laravel.
 Résoudre MySQL Mode Problem: L'expérience de l'utilisation du module TheliamysQlModeschecker
Apr 18, 2025 am 08:42 AM
Résoudre MySQL Mode Problem: L'expérience de l'utilisation du module TheliamysQlModeschecker
Apr 18, 2025 am 08:42 AM
Lors du développement d'un site Web de commerce électronique à l'aide de Thelia, j'ai rencontré un problème délicat: le mode MySQL n'est pas réglé correctement, ce qui fait que certaines fonctionnalités ne fonctionnent pas correctement. Après une certaine exploration, j'ai trouvé un module appelé TheliamysqlModeschecker, qui est capable de réparer automatiquement le motif MySQL requis par Thelia, résolvant complètement mes problèmes.
 MySQL: données structurées et bases de données relationnelles
Apr 18, 2025 am 12:22 AM
MySQL: données structurées et bases de données relationnelles
Apr 18, 2025 am 12:22 AM
MySQL gère efficacement les données structurées par la structure de la table et la requête SQL, et met en œuvre des relations inter-tableaux à travers des clés étrangères. 1. Définissez le format de données et tapez lors de la création d'une table. 2. Utilisez des clés étrangères pour établir des relations entre les tables. 3. Améliorer les performances par l'indexation et l'optimisation des requêtes. 4. Bases de données régulièrement sauvegarde et surveillent régulièrement la sécurité des données et l'optimisation des performances.
 MySQL: fonctionnalités et capacités clés expliqués
Apr 18, 2025 am 12:17 AM
MySQL: fonctionnalités et capacités clés expliqués
Apr 18, 2025 am 12:17 AM
MySQL est un système de gestion de base de données relationnel open source qui est largement utilisé dans le développement Web. Ses caractéristiques clés incluent: 1. Prend en charge plusieurs moteurs de stockage, tels que InNODB et Myisam, adaptés à différents scénarios; 2. Fournit des fonctions de réplication à esclave maître pour faciliter l'équilibrage de la charge et la sauvegarde des données; 3. Améliorez l'efficacité de la requête grâce à l'optimisation des requêtes et à l'utilisation d'index.
