
 développement back-end
Tutoriel Python
Quelles sont les méthodes de traitement des caractéristiques catégorielles dans l'apprentissage automatique Python ?
développement back-end
Tutoriel Python
Quelles sont les méthodes de traitement des caractéristiques catégorielles dans l'apprentissage automatique Python ?
Quelles sont les méthodes de traitement des caractéristiques catégorielles dans l'apprentissage automatique Python ?

Les caractéristiques catégorielles font référence à des caractéristiques dont les valeurs appartiennent à un ensemble fini de catégories, telles que la profession et le groupe sanguin. Son entrée d'origine se présente généralement sous la forme d'une chaîne. La plupart des modèles d'algorithme n'acceptent pas l'entrée de caractéristiques numériques. Les caractéristiques de catégorie numérique seront traitées comme des caractéristiques numériques, ce qui entraînera des erreurs dans le modèle entraîné.
Codage d'étiquettes
Label Encoding utilise un dictionnaire pour associer chaque étiquette de catégorie à un entier croissant, c'est-à-dire générer un index dans un tableau d'instances nommé class_.
Le LabelEncoder dans Scikit-learn est utilisé pour encoder des valeurs de caractéristiques catégorielles, c'est-à-dire pour encoder des valeurs discontinues ou du texte. Il comprend les méthodes courantes suivantes :
fit(y) : fit peut être considéré comme un dictionnaire vide, et y peut être considéré comme un mot fortifié dans le dictionnaire.
fit_transform(y) : cela équivaut à effectuer d'abord un ajustement puis une transformation, c'est-à-dire à insérer y dans le dictionnaire puis à transformer pour obtenir la valeur d'index.
inverse_transform(y) : récupère les données originales en fonction de la valeur d'index y.
transform(y) : Convertissez y en une valeur d'index.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
Méthode d'encodage de données multi-colonnes :
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
d = {}
le = LabelEncoder()
cols_to_encode = ['pets', 'owner', 'location']
for col in cols_to_encode:
df_train[col] = le.fit_transform(df_train[col])
d[col] = le.classes_Factorize() de Pandas peut mapper les données nominales de la série sur un ensemble de nombres, et le même type nominal est mappé sur le même nombre. La fonction factorize renvoie un tuple contenant deux éléments. Le premier élément est un tableau dont les éléments sont des nombres auxquels les éléments nominaux sont mappés ; le deuxième élément est un type Index, où les éléments sont tous des éléments nominaux sans duplication.
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
Label Encoding convertit uniquement le texte en valeurs numériques et ne résout pas le problème des caractéristiques du texte : toutes les étiquettes deviennent des nombres, et le modèle d'algorithme considérera directement les nombres similaires en fonction de leur distance, quelle que soit la signification spécifique de l'étiquette. . Les données traitées par cette méthode peuvent être appliquées à des modèles d'algorithmes prenant en charge les attributs catégoriels, tels que LightGBM.
Ordinal Encoding
Ordinal Encoding est l'idée la plus simple pour une fonctionnalité avec m catégories, nous la mappons sur un entier de [0,m-1] en conséquence. Bien entendu, le codage ordinal est plus adapté aux fonctionnalités ordinales, c'est-à-dire que chaque fonctionnalité a un ordre inhérent. Par exemple, pour une catégorie comme « Éducation », « Bachelor », « Master » et « Ph.D. » peuvent être naturellement codés comme [0,2], car ils contiennent intrinsèquement un tel ordre logique. Mais pour une catégorie comme « couleur », il n'est pas raisonnable de coder respectivement « bleu », « vert » et « rouge » dans [0,2], car nous n'avons aucune raison de penser que « bleu » et « vert » L'écart entre « bleu » et « rouge » a des effets différents sur les fonctionnalités.
ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
df['GenerationLabel'] = df['Generation'].map(gord_map)One-Hot Encoding
Dans les tâches réelles des applications d'apprentissage automatique, les caractéristiques ne sont parfois pas toujours des valeurs continues, mais peuvent être des valeurs catégorielles. Par exemple, le sexe peut être divisé en homme et femme. Dans les tâches d'apprentissage automatique, pour de telles fonctionnalités, nous devons généralement les numériser. Par exemple, il existe les trois attributs de fonctionnalité suivants :
Gender : ["masculin", "female"]
Région : [ ". Europe", "US", "Asia"]
Navigateur : ["Firefox", "Chrome", "Safari", "Internet Explorer"]
Pour un certain échantillon, tel que ["masculin" ", "US", "Internet Explorer"], nous devons numériser les caractéristiques de cette valeur de classification. La méthode la plus directe, nous pouvons utiliser la sérialisation : [0,1,3]. Bien que les données soient converties sous forme numérique, notre classificateur ne peut pas utiliser directement les données ci-dessus. Parce que les classificateurs utilisent souvent par défaut des données continues et ordonnées. Selon la représentation ci-dessus, les nombres ne sont pas ordonnés, mais attribués au hasard. Un tel traitement de fonctionnalités ne peut pas être directement intégré aux algorithmes d’apprentissage automatique.
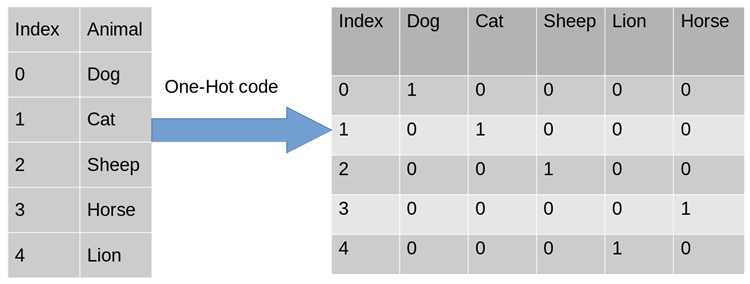
Afin de résoudre le problème ci-dessus, l'utilisation de One-Hot Encoding est l'une des solutions possibles. Encodage à chaud, également appelé encodage efficace sur un bit. La méthode consiste à utiliser un registre d'état à N bits pour coder N états. Chaque état possède son propre bit de registre indépendant, et à tout moment, un seul d'entre eux est valide. Le codage à chaud convertit chaque fonctionnalité en m fonctionnalités binaires, où m est le nombre de valeurs possibles pour la fonctionnalité. De plus, ces fonctionnalités s’excluent mutuellement et une seule est active à la fois. Les données deviennent donc rares.
Pour le problème ci-dessus, l'attribut de genre est bidimensionnel. De même, la région est tridimensionnelle et le navigateur est quadridimensionnel. De cette façon, nous pouvons utiliser l'encodage One-Hot pour encoder l'échantillon ci-dessus [" male", "US", "Internet Explorer"], male correspond à [1, 0], de même US correspond à [0, 1, 0] et Internet Explorer correspond à [0, 0, 0, 1]. Le résultat complet de la numérisation des fonctionnalités est : [1,0,0,1,0,0,0,0,1].
Pourquoi puis-je utiliser One-Hot Encoding ?
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
使用One-Hot编码对离散型特征进行处理可以使得特征之间的距离计算更加准确。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。在实际应用中,One-Hot Encoding与PCA结合的方法也非常实用。
One-Hot Encoding的使用场景
独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
树结构方法,如随机森林、Bagging和Boosting等,在特征处理方面不需要进行标准化操作。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
基于Scikit-learn 的one hot encoding
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
可以处理数值型和类别型数据
输入必须为1D数组
可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
OneHotEncoder只能对数值型数据进行处理,需要先将文本转化为数值(Label encoding)后才能使用,只接受2D数组:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def LabelOneHotEncoder(data, categorical_features):
d_num = np.array([])
for f in data.columns:
if f in categorical_features:
le, ohe = LabelEncoder(), OneHotEncoder()
data[f] = le.fit_transform(data[f])
if len(d_num) == 0:
d_num = np.array(ohe.fit_transform(data[[f]]))
else:
d_num = np.hstack((d_num, ohe.fit_transform(data[[f]]).A))
else:
if len(d_num) == 0:
d_num = np.array(data[[f]])
else:
d_num = np.hstack((d_num, data[[f]]))
return d_num
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_new = LabelOneHotEncoder(df, ['color', 'make', 'year'])基于Pandas的one hot encoding
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1])
print(df_processed)get_dummies的优势在于:
本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
不管你列是数值型还是字符串型,都可以进行二值化编码
能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
频数编码(Frequency Encoding/Count Encoding)
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
import pandas as pd
data_count = data.groupby('城市')['城市'].agg({'频数':'size'}).reset_index()
data = pd.merge(data, data_count, on = '城市', how = 'left')目标编码(Target Encoding/Mean Encoding)
目标编码(target encoding),亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
一般情况下,针对定性特征,我们只需要使用sklearn的OneHotEncoder或LabelEncoder进行编码。
LabelEncoder peut recevoir des colonnes de caractéristiques irrégulières et les convertir en valeurs entières de 0 à n-1 (en supposant qu'il y ait n catégories différentes au total) OneHotEncoder peut créer un m*n clairsemé via une matrice de codage factice (en supposant qu'il y ait m lignes) ; de données au total, le fait que le format de matrice de sortie spécifique soit clairsemé peut être contrôlé par le paramètre sparse).
La « cardinalité » d'une caractéristique qualitative fait référence au nombre total de valeurs possibles distinctes que peut prendre la caractéristique. Face à des caractéristiques qualitatives de cardinalité élevée, ces méthodes de prétraitement des données ne parviennent souvent pas à obtenir des résultats satisfaisants.
Exemples de caractéristiques qualitatives à haute cardinalité : adresse IP, nom de domaine email, nom de ville, adresse du domicile, rue, numéro de produit.
Raison principale :
LabelEncoder code des caractéristiques qualitatives à haute cardinalité Bien qu'une seule colonne soit requise, chaque nombre naturel a une signification différente et est linéairement inséparable pour y. L'utilisation d'un modèle simple est sujette au sous-ajustement et ne peut pas pleinement saisir les différences entre les différentes catégories ; l'utilisation d'un modèle complexe est sujette au surajustement dans d'autres endroits.
OneHotEncoder code des caractéristiques qualitatives de haute cardinalité, qui produiront inévitablement des matrices clairsemées avec des dizaines de milliers de colonnes, ce qui consomme facilement beaucoup de mémoire et de temps de formation, à moins que l'algorithme lui-même ne soit optimisé (par exemple : SVM).
Si la cardinalité d'une certaine caractéristique catégorielle est relativement faible (caractéristiques de faible cardinalité), c'est-à-dire que le nombre d'éléments dans l'ensemble formé en dédupliquant toutes les valeurs de la caractéristique est relativement faible, le One- La méthode de codage à chaud est généralement utilisée pour convertir les caractéristiques en types de valeurs numériques. Le codage à chaud peut être effectué pendant le prétraitement des données ou pendant la formation du modèle, du point de vue du temps de formation, CatBoost utilise également cette dernière méthode pour les fonctionnalités catégorielles à faible cardinalité.
Évidemment, parmi les fonctionnalités à cardinalité élevée, telles que l'ID utilisateur, cette méthode d'encodage générera un grand nombre de nouvelles fonctionnalités, provoquant un désastre de dimensionnalité. Une méthode de compromis consiste à regrouper les catégories en un nombre limité de groupes, puis à effectuer un codage One-hot. Une méthode couramment utilisée consiste à regrouper en fonction des statistiques de variable cible (Statistiques cibles, ci-après dénommées TS), qui sont utilisées pour estimer la valeur attendue de la variable cible pour chaque catégorie. Certaines personnes utilisent même directement TS comme nouvelle variable numérique pour remplacer la variable catégorielle d'origine. Il est important de noter qu'en définissant le seuil des caractéristiques numériques TS, basé sur la perte logarithmique, le coefficient de Gini ou l'erreur quadratique moyenne, nous pouvons obtenir la division optimale parmi toutes les divisions possibles qui divisent la catégorie en deux pour l'ensemble d'apprentissage. Dans LightGBM, les caractéristiques catégorielles sont représentées par des statistiques de gradient (GS) à chaque étape de l'augmentation du gradient. Bien qu'elle fournisse des informations importantes pour la construction d'arborescences, cette méthode présente les deux inconvénients suivants :
Augmente le temps de calcul, car GS doit être calculé pour chaque fonctionnalité de catégorie et à chaque étape de l'itération
Besoins de stockage accrus . Pour une variable catégorielle, il est nécessaire de stocker la catégorie de chaque nœud à chaque fois
Afin de pallier ces défauts, LightGBM classe toutes les catégories de longue traîne en une seule catégorie au prix de la perte de certaines informations. On prétend que cette méthode est bien meilleure que le codage One-hot lorsqu’il s’agit de fonctionnalités de type à cardinalité élevée. Grâce aux fonctionnalités TS, un seul numéro par catégorie est calculé et stocké. Par conséquent, l’utilisation de TS comme nouvelle fonctionnalité numérique pour le traitement des caractéristiques catégorielles est la plus efficace et peut minimiser la perte d’informations. TS est également largement utilisé dans les tâches de prédiction de clics. Les fonctionnalités de catégorie dans ce scénario incluent les utilisateurs, les régions, les annonces, les éditeurs d'annonces, etc. Dans la discussion suivante, nous nous concentrerons sur TS et laisserons de côté l’encodage One-hot et GS pour l’instant.
Voici la formule de calcul :
où n représente le nombre de valeurs pour une certaine caractéristique,
représente le nombre d'étiquettes positives pour une certaine valeur de caractéristique, mdl est un seuil minimum et le nombre d'échantillons est inférieur à La catégorie de caractéristiques de cette valeur sera ignorée et la priorité est la moyenne de l'étiquette. Notez que si vous êtes confronté à un problème de régression, il peut être traité en moyenne/max de la valeur de l'étiquette sous la fonctionnalité correspondante. Pour k problèmes de classification, les caractéristiques k-1 correspondantes seront générées.
Cette méthode est également sujette au surapprentissage. Les méthodes suivantes sont utilisées pour éviter le surapprentissage :
Augmenter la taille du terme régulier a
Ajouter du bruit à cette colonne de l'ensemble d'entraînement
Utiliser le crossover Vérifiez que
le codage cible est une méthode de codage supervisé s'il est utilisé correctement, il peut améliorer efficacement la précision du modèle de prédiction (Pargent, Bischl et Thomas 2019) et la clé pour cela est de l'introduire dans. le processus de codage Régularisation pour éviter les problèmes de surajustement.
Par exemple, la catégorie A correspond à 200 tags 1, 300 tags 2 et 500 tags 3. Elle peut être codée comme : 2/10, 3/10, 3/6. La chose la plus importante au milieu est de savoir comment éviter le surajustement (l'encodage cible d'origine encode directement toutes les données et étiquettes de l'ensemble d'entraînement, ce qui rendra les résultats d'encodage obtenus trop dépendants de l'ensemble d'apprentissage. Une solution courante consiste à utiliser 2). Les niveaux de validation croisée trouvent la moyenne cible. L'idée est la suivante :
把train data划分为20-folds (举例:infold: fold #2-20, out of fold: fold #1)
计算 10-folds的 inner out of folds值 (举例:使用inner_infold #2-10 的target的均值,来作为inner_oof #1的预测值)
对10个inner out of folds 值取平均,得到 inner_oof_mean
将每一个 infold (fold #2-20) 再次划分为10-folds (举例:inner_infold: fold #2-10, Inner_oof: fold #1)
计算oof_mean (举例:使用 infold #2-20的inner_oof_mean 来预测 out of fold #1的oof_mean
将train data 的 oof_mean 映射到test data完成编码
比如划分为10折,每次对9折进行标签编码然后用得到的标签编码模型预测第10折的特征得到结果,其实就是常说的均值编码。
目标编码尝试对分类特征中每个级别的目标总体平均值进行测量。当数据量较少时,每个级别的数据量减少意味着估计的均值与真实均值之间的差距增加,方差也会更大。
from category_encoders import TargetEncoder import pandas as pd from sklearn.datasets import load_boston # prepare some data bunch = load_boston() y_train = bunch.target[0:250] y_test = bunch.target[250:506] X_train = pd.DataFrame(bunch.data[0:250], columns=bunch.feature_names) X_test = pd.DataFrame(bunch.data[250:506], columns=bunch.feature_names) # use target encoding to encode two categorical features enc = TargetEncoder(cols=['CHAS', 'RAD']) # transform the datasets training_numeric_dataset = enc.fit_transform(X_train, y_train) testing_numeric_dataset = enc.transform(X_test)
Beta Target Encoding
Kaggle竞赛Avito Demand Prediction Challenge 第14名的solution分享:14th Place Solution: The Almost Golden Defenders。和target encoding 一样,beta target encoding 也采用 target mean value (among each category) 来给categorical feature做编码。不同之处在于,为了进一步减少target variable leak,beta target encoding发生在在5-fold CV内部,而不是在5-fold CV之前:
把train data划分为5-folds (5-fold cross validation)
target encoding based on infold data
train model
get out of fold prediction
同时beta target encoding 加入了smoothing term,用 bayesian mean 来代替mean。Bayesian mean (Bayesian average) 的思路:某一个category如果数据量较少( 另外,对于target encoding和beta target encoding,不一定要用target mean (or bayesian mean),也可以用其他的统计值包括 medium, frqequency, mode, variance, skewness, and kurtosis — 或任何与target有correlation的统计值。 M-Estimate Encoding 相当于 一个简化版的Target Encoding: 其中????+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同样的在处理连续值时????+可以换成label的求和,????+换成所有label的求和。 一种基于目标的算法是 James-Stein 编码。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得: 其中B由以下公式估计: 但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。在实际操作中,可以使用网格搜索方法来选择一个较优的B值。 Weight Of Evidence 同样是基于target的方法。 使用WOE作为变量,第i类的WOE等于: WOE特别合适逻辑回归,因为Logit=log(odds)。WOE编码的变量被编码为统一的维度(是一个被标准化过的值),变量之间直接比较系数即可。 这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式: 使用二进制编码对每一类进行编号,使用具有log2N维的向量对N类进行编码。以 (0,0) 为例,它表示第一类,而 (0,1) 表示第二类,(1,0) 表示第三类,(1,1) 则表示第四类 类似于One-hot encoding,但是通过hash函数映射到一个低维空间,并且使得两个类对应向量的空间距离基本保持一致。使用低维空间来降低了表示向量的维度。 特征哈希可能会导致要素之间发生冲突。一个哈希编码的好处是不需要指定或维护原变量与新变量之间的映射关系。因此,哈希编码器的大小及复杂程度不随数据类别的增多而增多。 和WOE相似,只是去掉了log,即: effectue un codage de somme sur une certaine caractéristique en comparant la différence entre la valeur moyenne de l'étiquette (ou d'autres variables associées) sous la valeur de la caractéristique et la valeur moyenne de l'étiquette globale. . pour encoder les fonctionnalités. Si les détails ne sont pas bien traités, cette méthode est très sujette au surajustement, elle doit donc être combinée avec la méthode Leave-One-Out ou la validation croisée quintuple pour coder les fonctionnalités. Il existe également des méthodes pour ajouter un terme de pénalité basé sur la variance afin d'éviter le surajustement. Le codage Helmert est couramment utilisé en économétrie. Après le codage Helmert (chaque valeur de la caractéristique catégorielle correspond à une ligne de la matrice Helmert), les coefficients de variable codés dans le modèle linéaire peuvent refléter la valeur moyenne de la variable dépendante étant donné une certaine valeur de catégorie de la variable de catégorie. les moyennes de la variable dépendante étant donné les valeurs des autres catégories de cette catégorie. L'encodage du casque est la méthode d'encodage la plus largement utilisée après One-Hot Encoding et Sum Encoder. Différent de Sum Encoder, il compare la valeur moyenne de l'étiquette correspondante (ou d'autres variables associées) sous une certaine valeur de caractéristique avec la différence entre les. moyen de ses caractéristiques précédentes, plutôt que la moyenne de toutes les caractéristiques. Cette fonctionnalité est également sujette au surapprentissage. Pour les variables catégorielles dont le nombre de valeurs possibles est supérieur au maximum one-hot, CatBoost utilise une méthode d'encodage très efficace, similaire à l'encodage moyen, mais peut réduire le surapprentissage. Sa méthode de mise en œuvre spécifique est la suivante : Triez aléatoirement l'ensemble d'échantillons d'entrée et générez plusieurs groupes d'arrangements aléatoires. Convertissez les balises à virgule flottante ou de valeur d'attribut en nombres entiers. Convertissez tous les résultats des valeurs des caractéristiques de classification en résultats numériques selon la formule suivante. où CountInClass représente le nombre d'échantillons ayant une valeur de 1 dans la valeur actuelle de la fonction de classification ; Prior est la valeur initiale de la molécule, déterminée en fonction des paramètres initiaux. TotalCount représente le nombre de tous les échantillons ayant la même valeur de caractéristique de classification que l'échantillon actuel, y compris l'échantillon actuel lui-même. Résumé du traitement CatBoost Caractéristiques catégorielles : Tout d'abord, ils calculeront les statistiques de certaines données. Calculez la fréquence d'occurrence d'une catégorie, ajoutez des hyperparamètres et générez de nouvelles fonctionnalités numériques. Cette stratégie nécessite que les données portant la même étiquette ne puissent pas être organisées ensemble (c'est-à-dire tous les 0 d'abord, puis tous les 1), et que l'ensemble de données doit être brouillé avant l'entraînement. Deuxièmement, utilisez différentes permutations des données (en fait 4). Avant de construire l'arbre à chaque tour, un tour de dés est lancé pour décider quel arrangement utiliser pour construire l'arbre. Le troisième point est d'envisager d'essayer différentes combinaisons de caractéristiques catégorielles. Par exemple, la combinaison de couleur et de type peut former une caractéristique similaire au chien bleu. Lorsque le nombre de caractéristiques catégorielles à combiner augmente, catboost ne prend en compte que certaines combinaisons. Lors de la sélection du premier nœud, une seule fonctionnalité, telle que A, est prise en compte. Lors de la génération du deuxième nœud, considérez la combinaison de A et de toute caractéristique catégorielle et choisissez la meilleure. De cette façon, un algorithme glouton est utilisé pour générer des combinaisons. Quatrièmement, à moins que la dimension soit très petite comme le sexe, il n'est pas recommandé de générer vous-même des vecteurs uniques. Il est préférable de laisser le soin à l'algorithme. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!# train -> training dataframe
# test -> test dataframe
# N_min -> smoothing term, minimum sample size, if sample size is less than N_min, add up to N_min
# target_col -> target column
# cat_cols -> categorical colums
# Step 1: fill NA in train and test dataframe
# Step 2: 5-fold CV (beta target encoding within each fold)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for i, (dev_index, val_index) in enumerate(kf.split(train.index.values)):
# split data into dev set and validation set
dev = train.loc[dev_index].reset_index(drop=True)
val = train.loc[val_index].reset_index(drop=True)
feature_cols = []
for var_name in cat_cols:
feature_name = f'{var_name}_mean'
feature_cols.append(feature_name)
prior_mean = np.mean(dev[target_col])
stats = dev[[target_col, var_name]].groupby(var_name).agg(['sum', 'count'])[target_col].reset_index()
### beta target encoding by Bayesian average for dev set
df_stats = pd.merge(dev[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
dev[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for val set
df_stats = pd.merge(val[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
val[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for test set
df_stats = pd.merge(test[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
test[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
# Bayesian mean is equivalent to adding N_prior data points of value prior_mean to the data set.
del df_stats, stats
# Step 3: train model (K-fold CV), get oof predictioM-Estimate Encoding
James-Stein Encoding
Weight of Evidence Encoder
Leave-one-out Encoder (LOO or LOOE)
Binary Encoding
Hashing Encoding
Probability Ratio Encoding
Sum Encoder (Deviation Encoder, Effect Encoder)
Helmert Encoding
CatBoost Encoding

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
VS Code est disponible sur Mac. Il a des extensions puissantes, l'intégration GIT, le terminal et le débogueur, et offre également une multitude d'options de configuration. Cependant, pour des projets particulièrement importants ou un développement hautement professionnel, le code vs peut avoir des performances ou des limitations fonctionnelles.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
