
SELECT COUNT(DISTINCT id, a, IFNULL(b, '0')) as cnt FROM test_distinct;
 base de données
tutoriel mysql
Comment résoudre le problème du nombre de colonnes distinctes dans MySQL
base de données
tutoriel mysql
Comment résoudre le problème du nombre de colonnes distinctes dans MySQL
Comment résoudre le problème du nombre de colonnes distinctes dans MySQL

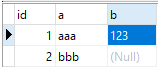
La base de données de test reproduite est la suivante :
CREATE TABLE `test_distinct` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` varchar(50) CHARACTER SET utf8 DEFAULT NULL, `b` varchar(50) CHARACTER SET utf8 DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
Les données de test dans le tableau sont les suivantes : Nous devons maintenant compter le nombre de colonnes après déduplication de ces trois colonnes.
Analyse du problème
Mon ami m'a donné quatre instructions de requête pour localiser le problème
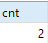
SELECT COUNT(*) AS cnt FROM test_distinct; SELECT COUNT(DISTINCT id, a, b) as cnt FROM test_distinct; SELECT id, a, b, COUNT(*) AS cnt FROM test_distinct GROUP BY id, a, b HAVING cnt > 1; SELECT l.id AS l_id, l.a AS l_a, l.b AS l_b, r.id AS r_id, r.a AS r_a, r.b AS r_b FROM test_distinct l LEFT JOIN test_distinct r ON l.id = r.id AND l.a = r.a AND l.b = r.b WHERE r.id is NULL or r.id = 'null';
 # 🎜🎜 #
# 🎜🎜 #
 Attention ! ! ! À partir des données de test, nous pouvons rapidement deviner où se situe le problème, mais il s'avère qu'il y a plus de 30 000 éléments de données dans le tableau et qu'il est impossible de visualiser les données à l'œil nu.
Attention ! ! ! À partir des données de test, nous pouvons rapidement deviner où se situe le problème, mais il s'avère qu'il y a plus de 30 000 éléments de données dans le tableau et qu'il est impossible de visualiser les données à l'œil nu.
Il y a deux points contre-intuitifs dans les résultats de la requête ci-dessus :
- La deuxième donnée est manquante après les statistiques de déduplication, mais la seconde Il manque une donnée. Les résultats des trois données montrent qu'elles n'ont pas les mêmes données.
- Lorsque vous utilisez la même table pour effectuer une jointure externe gauche, la table pilote contient des données, mais la table pilotée est vide.
- Regardons d'abord la deuxième question. Le document officiel a l'explication suivante :
- Lors de l'utilisation. Sous-clause ON, elle contient les mêmes expressions conditionnelles utilisées dans la clause WHERE. Une situation courante consiste à utiliser la clause ON pour spécifier les conditions de jointure de la table et à utiliser la clause WHERE pour limiter les lignes incluses dans le jeu de résultats.
- Si la table de droite n'a aucune ligne correspondante pour la condition dans la partie ON ou USING de LEFT JOIN, la table de droite utilise toutes les colonnes définies sur NULL.
- Vous ne pouvez pas utiliser d'opérateurs de comparaison arithmétique (tels que =, < ou <>) pour comparer NULL.
SELECT NULL = NULL; SELECT NULL IS NULL;
Copier après la connexion
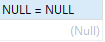
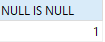 Donc le deuxième problème réside dans le résultat de NULL=NULL La valeur est toujours False, ce qui entraîne deux lignes de données initialement égales mais non égales.
Donc le deuxième problème réside dans le résultat de NULL=NULL La valeur est toujours False, ce qui entraîne deux lignes de données initialement égales mais non égales.
Mais cela ne résout pas le premier problème : pourquoi une donnée a disparu après la déduplication. Cependant, on peut deviner que les données manquantes sont probablement liées à la valeur NULL.
On sépare les deux opérations de comptage et de distinct :
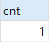
SELECT COUNT(*) as cnt FROM (SELECT DISTINCT id, a, b FROM test_distinct) as tmp;
Hein ? Le résultat est correct, ce qui signifie que le plan de requête généré par count(distinct expr) peut être différent de ce que nous avions imaginé. Il ne s'agit pas de supprimer d'abord les doublons puis de compter. Utilisez expliquer pour analyser la requête. plan des deux déclarations, comme indiqué ci-dessous :

count(distinct expr)生成的查询计划可能和我们想象的不一样,并不是先去重再统计,使用explain分析一下两条语句的查询计划,如下所示:

从表中可以看到,mysql执行引擎直接将count(distinct expr)作为一个查询,查看官方文档:
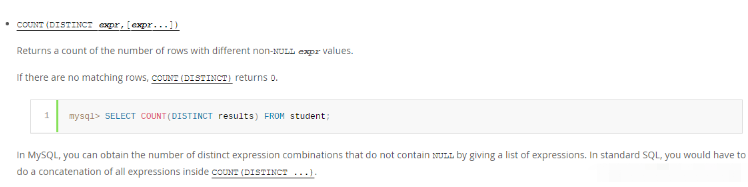
解决办法
至此问题才终于弄清楚了。解决这个问题的办法有两种,第一种就是上述的先去重后统计,第二种可以利用IFNULL()
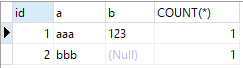 Comme vous pouvez le voir sur le tableau, le moteur d'exécution mysql utilise directement
Comme vous pouvez le voir sur le tableau, le moteur d'exécution mysql utilise directement count(distinct expr) sous forme de requête, consultez le document officiel : 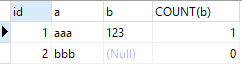
Solution
IFNULL() : SELECT COUNT(DISTINCT id, a, IFNULL(b, '0')) as cnt FROM test_distinct;
Copier après la connexion
. Un autre ajout, utilisez count() : SELECT COUNT(DISTINCT id, a, IFNULL(b, '0')) as cnt FROM test_distinct;
- knowledge point#🎜🎜##🎜🎜 ##🎜🎜##🎜🎜#Vous ne pouvez pas utiliser d'opérateurs de comparaison arithmétique (tels que =, ) pour comparer des valeurs nulles #🎜🎜##🎜🎜##🎜🎜##🎜🎜#count ; ( distinct expr) renvoie le nombre de lignes distinctes et non vides dans la colonne expr #🎜🎜# ;
-
COUNT() a deux utilisations distinctes : elle peut être utilisée pour compter le nombre de valeurs dans une colonne, ou elle peut être utilisée pour compter le nombre de lignes. Lors du comptage des valeurs de colonne, la valeur de la colonne doit être non vide (NULL n'est pas compté). Lorsqu'une colonne ou une expression est spécifiée entre parenthèses de la fonction COUNT(), la fonction compte le nombre de résultats qui ont une valeur dans l'expression. Une autre fonction de COUNT() consiste à compter le nombre de lignes dans le jeu de résultats. Lorsque MySQL confirme que la valeur de l'expression entre parenthèses ne peut pas être vide, il compte en fait le nombre de lignes. Le plus simple est lorsque nous utilisons COUNT(). Dans ce cas, le caractère générique ne s'étend pas à toutes les colonnes comme nous l'avions deviné. En fait, il ignorera toutes les colonnes et comptera directement toutes les lignes - "MySQL haute performance" ;
Dans InnoDB, SELECT COUNT(*) et SELECT COUNT(1) sont traités de la même manière et il n'y a aucune différence de performances.
SELECT id, a, b, COUNT(*) FROM test_distinct GROUP BY id, a, b; SELECT id, a, b, COUNT(b) FROM test_distinct GROUP BY id, a, b;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
