
 base de données
tutoriel mysql
Quelle est la différence entre sur, dans, comme et où dans MySQL ?
base de données
tutoriel mysql
Quelle est la différence entre sur, dans, comme et où dans MySQL ?
Quelle est la différence entre sur, dans, comme et où dans MySQL ?

La différence entre Mysql sur, dans, comme et où
Réponse : Où les conditions de requête, utilisez-les lors de la connexion interne et externe, comme alias, dans pour demander si une certaine valeur est dans une certaine condition
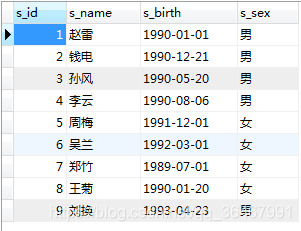
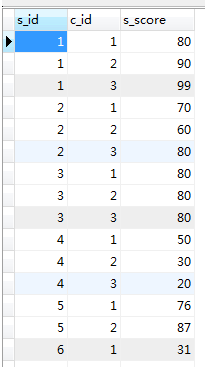
Créer 2 tableaux : étudiant, score
étudiant:
score:
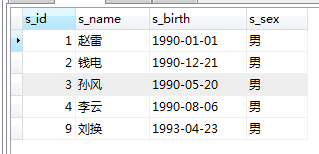
où
SELECT * FROM student WHERE s_sex='男'
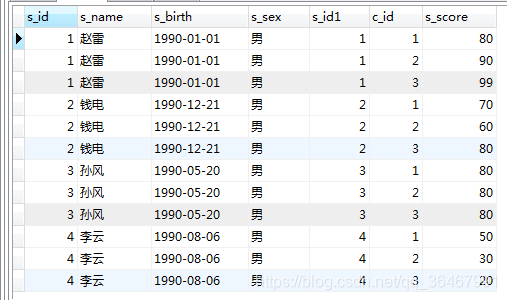
Exemple: sur
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;
sur et où combinaison :
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='赵雷'
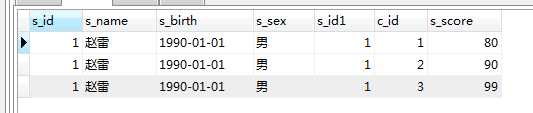
Par exemple : in
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='赵雷')
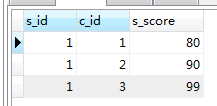
as
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='赵雷'
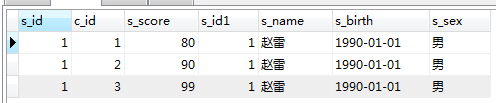
Problème de filtrage des données de jointure à gauche1.
Dans les conditions suivantes ne peut filtrez la table sur le côté droit de la jointure gauche, si la table de gauche ne peut pas correspondre aux données de la table de droite, null sera affiché à la position d'origine de la table de droite. Les données de la table sur le côté gauche de la jointure gauche ne sont pas contraintes après. en ajoutant la condition après là où, toutes les données seront filtrées.
2. Les mêmes données sont filtrées et utilisées à plusieurs reprises.
with <name> as()
Vous pouvez utiliser with as pour générer une table temporaire dans MySQL. Le temps d'exécution n'existera plus après l'exécution. article table, mais toutes les données du tableau ne sont pas ce dont nous avons besoin. Par conséquent, nous filtrons et créons d'abord un arc de table temporaire, et nous exploiterons l'arc.
S'il ne s'agit que d'une simple opération de l'exemple ci-dessus, il n'est pas nécessaire d'utiliser with...as, mais lorsque nous devons interroger conjointement ou même imbriquer la table article avec d'autres tables, le jugement de is_del = 0 sera doit être effectuée plusieurs fois. L'instruction SQL finale peut être très complexe et sujette aux erreurs, mais l'utilisation d'arc ne nécessite pas de filtrage répété des données.
Le sql dans with...as peut être plus compliqué. Par exemple, il y a name_id dans la table article, mais le plus souvent nous voulons utiliser name Nous pouvons le rechercher avec... comme à l'avance, et ensuite. utilisez une table temporaire pour le faire.
3. Trier par un certain champ pour obtenir les trois dernières données ou les trois premières données de chaque catégorie
C'est une question relativement classique. Je suis débutant et je ne connais qu'une seule façon de résoudre le problème, mais je vais essayer. de mon mieux pour l'expliquer d'une manière simple et populaire.
Exemple :
with arc as(
select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0
)
select * from arcDans l'exemple, cId est l'identifiant de la catégorie et updateTime est l'heure de mise à jour. La solution au problème consiste à sélectionner les trois dernières données pour chaque catégorie en arc, tout comme les besoins de la page d'accueil des actualités. pour sélectionner les dernières pour chaque catégorie. Pour trois actualités, selon les données de la base de données, on peut utiliser order by cId, updateTime desc pour trier les données par catégorie et heure de mise à jour. Cependant, il est impossible de récupérer des éléments spécifiques. de données pour chaque catégorie dans la base de données existante, nous pouvons donc ajouter un champ temporaire.
updateTimeSort Il représente le tri de chaque sous-élément de chaque catégorie de cette catégorie. Dans le problème actuel, ce champ temporaire devrait être lié au champ updateTime, qui trie chaque sous-élément de la catégorie en fonction de l'heure de mise à jour.
Comme le montre l'exemple de code, nous pouvons trouver les deux tables a1 et a2. Ce sont toutes deux des alias pour la table arc. Elles sont combinées sous forme de sous-requêtes, avec a2 comme table principale. pour trouver la catégorie qui est la même que les données actuelles de a2 et que l'heure de mise à jour est ultérieure au nombre de données dans les données actuelles de a2, vous pouvez voir count(*)+1, ce qui signifie que le nombre est augmenté. par un. Il est normal de ne pas en ajouter un, juste lorsqu'une donnée a la dernière heure de mise à jour dans la catégorie dans laquelle elle se trouve. La valeur de count(*) est 0. Si nous utilisons count(*)+1, nous pouvons trier les données à partir de 1.
En fin de compte, il nous suffit de sélectionner les données avec updateTimeSort <= 3. Si nous voulons filtrer les premières actualités publiées, il nous suffit de modifier la logique de filtrage de updateTimeSort dans l'exemple de code,
a1. updateTime > a2 .updateTime est remplacé par a1.updateTime < a2.updateTime
Vous pouvez voir qu'il y a une autre table a3 dans l'exemple de code, qui est en fait une table temporaire, nous avons appris plus tôt que with..as peut générer. une table temporaire, alors répétons cette fois. Comme le montre le code, les tables temporaires peuvent aussi exister sous une autre forme, avec... car nous ne l'utilisons que lorsque le sql est complexe. De manière générale, cette méthode peut nous aider à résoudre. beaucoup de problèmes maintenant, chacun a son propre. Les avantages et les inconvénients dépendent de la situation.
4、业务逻辑书写位置问题
接触sql多了会发现,sql其实能帮我们解决一定的业务问题,明显的有sql的存储过程和方法,对sql语句的批量处理其实在一定程度上帮我们解决一定的业务问题,但缺点也很明显,当新手接触这个项目时他很难搞清楚某个功能到底是如何实现的,不利于维护。
一般来说我们解决业务是在server层,有时会使用sql解决一些问题,但很少,在sever处理受制于计算机硬件,在数据库处理受制于数据库性能,相比之下,计算机硬件更易于扩展,因此还是不推荐大量使用sql解决问题的。
例如上个问题:根据某个字段排序取每个类别最后三条数据或前三条数据问题,虽然问题基本解决但让存在一些 ‘bug’,例如排序时会产生1、2、3、3、4这种排序,这是因为同个类别内有两条数据更新时间重复了,那我们直观想法(还是要看个人经验值)应该是,既然问题出在数据库,那应该在数据库查询的时候就解决这个问题,但事实上,让数据库去解决并不好解决,数据库的强项在于各种搜索算法,不在于逻辑处理,因此我们就要转移到server层处理,会有不少人陷于这个坑,花费大量时间去找办法让数据库去处理这类问题,但其实就算数据库处理得了,它也不一定有server层处理的效率高,当然如果是为了学习更多东西,这些时间也是值得花的,但是这种解题思路还是要改变下的。将1、2、3、3、4问题交给server处理也就是利用java等高级语言处理这种问题,相信熟用这些语言的开发者解决这些问题都是小case了。
5、查找另一表内和本表相关字段的数量
先复习下知识:用过count函数的人都清楚一旦使用count这类聚合函数,不做其他处理数据就会归为一行数据,但很多时候我们并不期望这样的结果,以此就要想些办法能用聚合函数,也能获取很多数据,我常用的是利用group by分组。
回归问题,现有(现不讨论表是否合理)文章表(id,title,content)有文章id,标题,文章内容三个字段,点赞收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),点赞字段(0未点赞,1点赞),现要查询文章表内每篇文章的点赞收藏数,sql语句:
select art.title,art.content, count(case afl.fav when 1 then 1 end) as collectNum, count(case afl.like when 1 then 1 end) as likeNum from article art left join article_favor_like afl on afl.arc_id = art.id group by afl.arc_id //这是关键
如果没有group by afl.arc_id 后果就是,查出来一行数据,数据还牛头不对马嘴,但通过对文章收藏表中的文章id进行分组就可以针对每个文章id查询数据,这样left join时右表就有每个文章id对相应的收藏数与点赞数,而不是表内所有点赞数和收藏数,最终数据也是我们所需的。
6、关于union的使用
例子:
select id,title,content,1 isArc from arc union select id,name,content,0 isArc from news
使用union进行的是上下整合
被联合的数据列数要求一致
列数相同,数据类型不同会自动进行数据类型转换
联合后的列的名字由联合中第一次出现的列名为依据,即使后续被联合数据有自己的列名也不会使用,在例子中最终列名为:id,title,content,name等列名不会使用,因此使用union一般配合别名使用统一结果。
有时候会区分数据是哪个表的,可以通过附加额外的字段来区别,就像例子中的isArc字段,news表中的isArc可以不写,原因也就是第4条,最终列名由第一次出现的列名决定,后续数据列名有没有都可以。
7、limit的巧用
limit一般用于分页,功能是获取指定区间内的数据,因此我们也可以用它来减少数据库的查询,例子:
select * from arc where id = 12 limit 1
数据库查询由索引还好,没有索引是要遍历数据库的,有些数据经由条件筛选在逻辑上应该是唯一的,使用limit 1可以使数据库查询到该数据时不再搜索,减少数据库搜索次数,但这种方法仅是一种技巧,想大幅度优化sql还要另想办法。
8、update ignore和insert ignore的使用
//标题是唯一索引,'新标题'存在则更新操作不执行 update ignore arc set title = '新标题' //标题是唯一索引,'标题1号'存在则插入操作不执行 insert ignore into arc values(null,'标题1号','文章内容')
有这种需求,数据存在时不执行任何操作,不存在则更新或插入,一个办法是使用ingore,它会忽略数据库报错,而数据库执行原子操作时报错是会回滚的,因此只要我们给数据加上主键或唯一索引,当被更新字段或插入字段与原有数据冲突时会报错,但因为ingore会忽视这种报错,后端也就不会报错,sql也未执行,达到了目的,有人会对报错敏感,其实也没什么,报错也是在检查数据是发现不合理之处给的一个提醒或警告,对数据库无害的。
9、mysql存在更新,不存在则插入
区别于上面那个需求,这个是当插入的数据存在时更新数据,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主键 insert into arc values(1,'标题1号','文章内容') on duplicate key update title='标题1号' //若要更新多个字段使用','隔开,例:title='标题1号',content='文章内容'
在例子中,当id为1的数据存在时,更新标题和内容,不存在则插入,如果执行更新操作,未设置新值的字段保持原来的值。
还有一个REPLACE INTO也可以达到这种效果,区别在于,REPLACE INTO更新时是先删除后插入会破坏原有索引,id为3的数据更新时会删除插入id为4的数据,未更新新值的字段设置为默认值或null。
无论是两个中的哪种方式判断数据是否存在的依据都是主键和唯一索引。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 PHPMYADMIN CONNEXION MYSQL
Apr 10, 2025 pm 10:57 PM
PHPMYADMIN CONNEXION MYSQL
Apr 10, 2025 pm 10:57 PM
Comment se connecter à MySQL à l'aide de PhpMyAdmin? L'URL pour accéder à phpmyadmin est généralement http: // localhost / phpmyadmin ou http: // [votre adresse IP de serveur] / phpmyadmin. Entrez votre nom d'utilisateur et votre mot de passe MySQL. Sélectionnez la base de données à laquelle vous souhaitez vous connecter. Cliquez sur le bouton "Connexion" pour établir une connexion.
