

Comment Redis accélère Spark

Apache Spark devient de plus en plus un modèle pour les outils de traitement du Big Data de nouvelle génération. En empruntant à des algorithmes open source et en répartissant les tâches de traitement entre des clusters de nœuds de calcul, les frameworks de génération Spark et Hadoop surpassent facilement à la fois en termes de types d'analyse de données qu'ils peuvent effectuer sur une seule plateforme et en termes de rapidité avec laquelle ils peuvent effectuer ces tâches. cadres traditionnels. Spark utilise la mémoire pour traiter les données, ce qui le rend beaucoup plus rapide (jusqu'à 100 fois plus rapide) que Hadoop sur disque.
Mais avec un peu d'aide, Spark peut courir encore plus vite. Si vous combinez Spark avec Redis (une technologie populaire de stockage de structures de données en mémoire), vous pouvez encore une fois améliorer considérablement les performances des tâches d'analyse de traitement. Cela est dû à la structure de données optimisée de Redis et à sa capacité à minimiser la complexité et les frais généraux lors de l'exécution des opérations. L'utilisation de connecteurs pour se connecter aux structures de données et aux API Redis peut accélérer davantage Spark.
Quelle est l'ampleur de l'accélération ? Si Redis et Spark sont utilisés ensemble, il s'avère que le traitement des données (afin d'analyser les données de séries chronologiques décrites ci-dessous) est 45 fois plus rapide que Spark en utilisant uniquement la mémoire de processus ou le cache hors tas pour stocker des données - Pas 45 % plus rapide, mais 45 fois plus rapide !
L'importance de la vitesse des transactions analytiques augmente de jour en jour, car de nombreuses entreprises doivent permettre des analyses aussi rapides que les transactions commerciales. À mesure que de plus en plus de décisions sont automatisées, les analyses nécessaires pour prendre ces décisions devraient être effectuées en temps réel. Apache Spark est un excellent framework de traitement de données à usage général ; même s'il n'est pas entièrement en temps réel, il constitue un grand pas en avant vers une utilisation plus rapide des données.
Spark utilise des ensembles de données distribués résilients (RDD), qui peuvent être stockés dans une mémoire volatile ou dans un système de stockage persistant comme HDFS. Tous les RDD répartis sur les nœuds du cluster Spark restent inchangés, mais d'autres RDD peuvent être créés via des opérations de transformation.
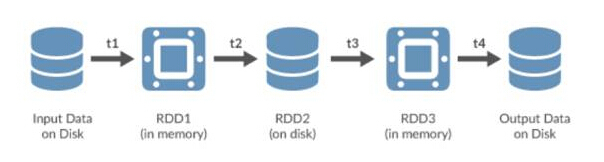
Spark RDD
RDD est un objet abstrait important dans Spark. Ils représentent un moyen tolérant aux pannes de présenter efficacement des données à un processus itératif. L'utilisation du traitement en mémoire signifie que le temps de traitement sera réduit de plusieurs ordres de grandeur par rapport à l'utilisation de HDFS et MapReduce.
Redis est spécialement conçu pour des performances élevées. La latence inférieure à la milliseconde est le résultat de structures de données optimisées qui améliorent l'efficacité en permettant d'effectuer des opérations à proximité de l'endroit où les données sont stockées. Cette structure de données utilise non seulement efficacement la mémoire et réduit la complexité des applications, mais réduit également la surcharge du réseau, la consommation de bande passante et le temps de traitement. Redis prend en charge plusieurs structures de données, notamment des chaînes, des ensembles, des ensembles triés, des hachages, des bitmaps, des hyperloglogs et des index géospatiaux. Les structures de données Redis sont comme des briques Lego, offrant aux développeurs des canaux simples pour implémenter des fonctions complexes.
Pour montrer visuellement comment cette structure de données peut simplifier le temps de traitement et la complexité des applications, autant prendre la structure de données Sorted Set (Sorted Set) comme exemple. Un ensemble ordonné est essentiellement un ensemble de membres classés par score.

Redis Sorted Collection
Vous pouvez stocker de nombreux types de données ici et elles sont automatiquement triées par scores. Les types de données courants stockés dans les collections ordonnées incluent : les données de séries chronologiques telles que les articles (par prix), les noms de produits (par quantité), les cours des actions et les relevés de capteurs tels que les horodatages.
Le charme des ensembles ordonnés réside dans les opérations intégrées de Redis, qui permettent aux requêtes de plage, à l'intersection de plusieurs ensembles ordonnés, à la récupération par niveau de membre et par score, et à davantage de transactions d'être exécutées simplement, avec une vitesse extrême et sur un mettre en œuvre à grande échelle. Non seulement les opérations intégrées enregistrent le code qui doit être écrit, mais l'exécution d'opérations en mémoire réduit la latence du réseau et économise la bande passante, permettant un débit élevé avec des latences inférieures à la milliseconde. Si des ensembles triés sont utilisés pour analyser les données de séries chronologiques, des améliorations de performances peuvent souvent être obtenues par ordres de grandeur par rapport à d'autres systèmes de stockage clé/valeur en mémoire ou à des bases de données sur disque.
Le connecteur Spark-Redis est développé par l'équipe Redis pour améliorer les capacités d'analyse de Spark. Ce package permet à Spark d'utiliser Redis comme l'une de ses sources de données. Grâce à ce connecteur, Spark peut accéder directement à la structure des données de Redis, améliorant ainsi considérablement les performances de différents types d'analyse.

Spark Redis Connector
Afin de démontrer les avantages apportés à Spark, l'équipe Redis a décidé d'effectuer des requêtes de tranche de temps (plage) dans plusieurs scénarios différents pour comparer horizontalement l'analyse des séries chronologiques dans Spark. Ces scénarios incluent : Spark stocke toutes les données dans la mémoire interne, Spark utilise Tachyon comme cache hors tas, Spark utilise HDFS et une combinaison de Spark et Redis.
L'équipe Redis a utilisé le package de séries chronologiques Spark de Cloudera pour créer un package de séries chronologiques Spark-Redis qui utilise les collections ordonnées Redis pour accélérer l'analyse des séries chronologiques. En plus de fournir toutes les structures de données qui permettent à Spark d'accéder à Redis, ce package effectue également deux tâches supplémentaires
Garantit automatiquement que les nœuds Redis sont cohérents avec le cluster Spark, garantissant que chaque nœud Spark utilise les données Redis locales, optimisant ainsi la latence.
Intégrez les API de dataframe et de source de données Spark pour convertir automatiquement les requêtes Spark SQL en le mécanisme de récupération de données le plus efficace dans Redis.
En termes simples, cela signifie que les utilisateurs n'ont pas à se soucier de la cohérence opérationnelle entre Spark et Redis et peuvent continuer à utiliser Spark SQL pour l'analyse, tout en améliorant considérablement les performances des requêtes.
Les données de séries chronologiques utilisées dans cette comparaison côte à côte comprennent : des données financières générées aléatoirement et 1 024 actions par jour pendant 32 ans. Chaque action est représentée par son propre ensemble ordonné, le score est la date et les données membres incluent le cours d'ouverture, le dernier cours, le dernier cours, le cours de clôture, le volume des transactions et le cours de clôture ajusté. L'image suivante représente la représentation des données dans un ensemble trié Redis utilisé pour l'analyse Spark :
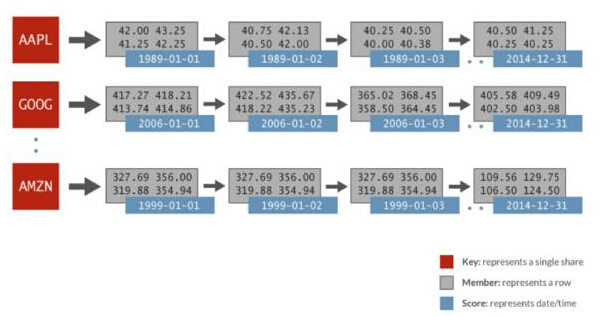
Série temporelle Spark Redis
Dans l'exemple ci-dessus, en termes d'ensemble trié AAPL, il y a une représentation de chaque jour ( 1989-01-01), et plusieurs valeurs tout au long de la journée représentées sous la forme d'une seule ligne associée. Utilisez simplement une simple commande ZRANGEBYSCORE dans Redis pour ce faire : obtenez toutes les valeurs pour une certaine tranche de temps, et donc obtenez tous les cours des actions dans la plage de dates spécifiée. Redis peut effectuer ces types de requêtes plus rapidement que les autres systèmes de stockage clé/valeur, jusqu'à 100 fois plus rapide.
Cette comparaison horizontale confirme l'amélioration des performances. Il a été constaté que Spark utilisant Redis peut effectuer des requêtes de tranche de temps 135 fois plus rapides que Spark utilisant HDFS et 45 fois plus rapides que Spark utilisant la mémoire sur tas (de processus) ou Spark utilisant Tachyon comme cache hors tas. La figure ci-dessous montre le temps d'exécution moyen comparé pour différents scénarios :
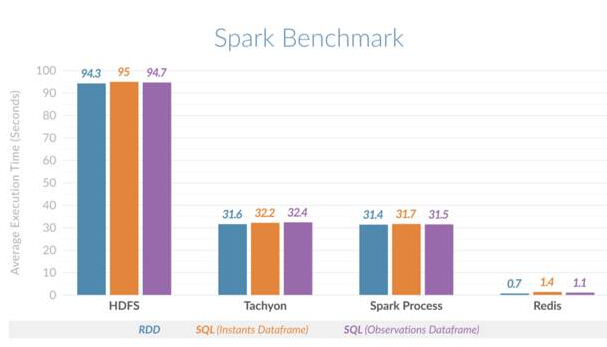
Comparaison horizontale Spark Redis
Ce guide vous guidera étape par étape pour installer le cluster Spark standard et la suite Spark-Redis. À travers un exemple simple de comptage de mots, il montre comment intégrer l'utilisation de Spark et Redis. Après avoir essayé Spark et le package Spark-Redis, vous pouvez explorer davantage de scénarios utilisant d'autres structures de données Redis.
Bien que les ensembles ordonnés soient bien adaptés aux données de séries chronologiques, d'autres structures de données de Redis, telles que les ensembles, les listes et les index géospatiaux, peuvent enrichir davantage les analyses Spark. Imaginez ceci : un processus Spark tente de déterminer quelles zones sont adaptées au lancement d'un nouveau produit, en tenant compte de facteurs tels que les préférences de la foule et la distance par rapport au centre-ville, afin d'optimiser l'effet de lancement. Imaginez comment des structures de données telles que des index géospatiaux et des collections dotées de capacités d'analyse intégrées pourraient accélérer considérablement ce processus. La combinaison Spark-Redis offre de grandes perspectives d'application.
Spark offre un large éventail de capacités d'analyse, notamment SQL, l'apprentissage automatique, le calcul graphique et Spark Streaming. L’utilisation des capacités de traitement en mémoire de Spark ne vous amène qu’à une certaine échelle. Cependant, avec Redis, vous pouvez aller plus loin : non seulement vous pouvez améliorer les performances en utilisant la structure de données de Redis, mais vous pouvez également étendre Spark plus facilement, c'est-à-dire en utilisant pleinement le mécanisme de stockage de données en mémoire distribuée partagée fourni par Redis pour traiter des centaines de milliers d'enregistrements, voire des milliards d'enregistrements.
Cet exemple de série chronologique n'est que le début. L’utilisation des structures de données Redis pour l’apprentissage automatique et l’analyse graphique devrait également apporter des avantages significatifs en termes de temps d’exécution à ces charges de travail.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
