

ChatGPT a été critiqué pour ses capacités mathématiques depuis sa sortie.
Même le « génie mathématique » Terence Tao a dit un jour que GPT-4 n'ajoutait pas beaucoup de valeur dans son domaine d'expertise mathématique.
Que dois-je faire, laisser ChatGPT devenir un « retardé mathématique » ?
OpenAI travaille dur - Afin d'améliorer les capacités de raisonnement mathématique de GPT-4, l'équipe OpenAI utilise la « Supervision des processus » (PRM) pour entraîner le modèle.
Vérifions étape par étape !

Adresse papier : https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
Dans le document, les chercheurs ont formé le modèle en récompensant chacun bonne réponse Les étapes de raisonnement, c'est-à-dire la « supervision du processus », plutôt que de simplement récompenser le résultat final correct (supervision des résultats), permettent d'atteindre le dernier SOTA en matière de résolution de problèmes mathématiques.
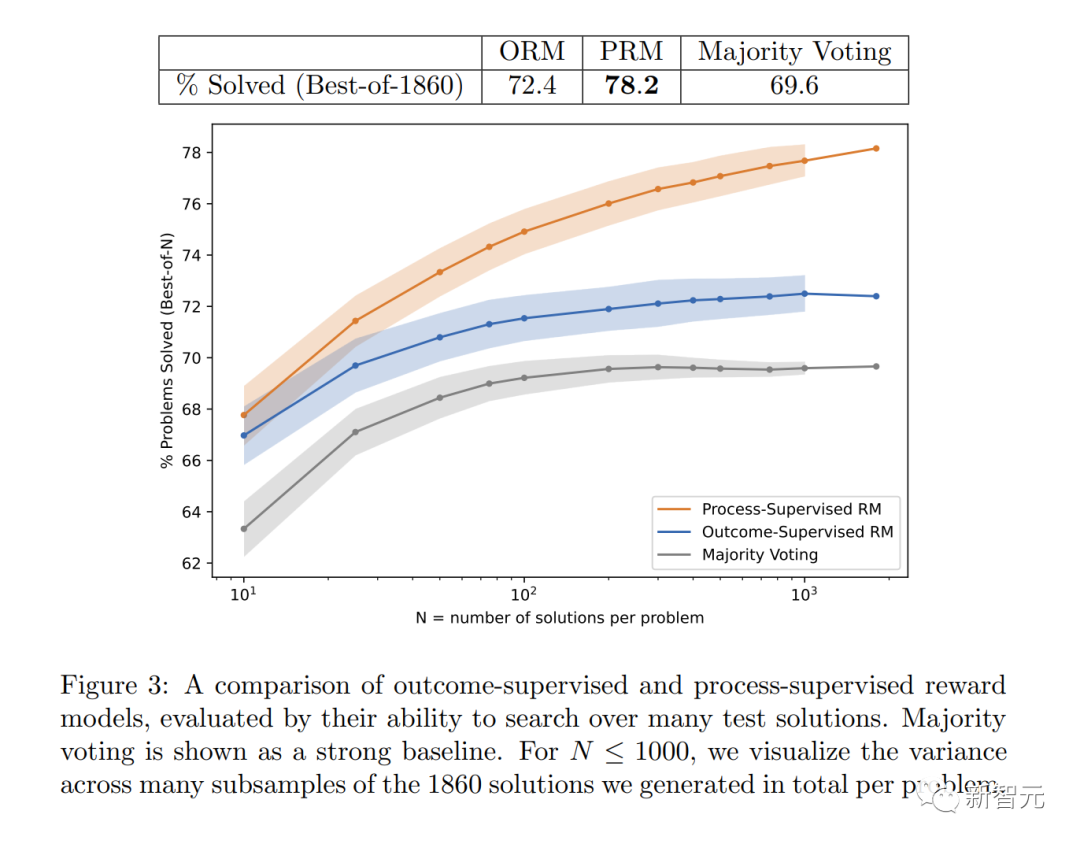
Plus précisément, PRM résout 78,2 % des problèmes dans un sous-ensemble représentatif de l'ensemble de tests MATH.

De plus, OpenAI a découvert que la « supervision des processus » est d'une grande valeur dans l'alignement - entraîner le modèle à produire une chaîne de pensées reconnue par les humains.
Les dernières recherches sont bien sûr indispensables pour transmettre par Sam Altman, "Notre équipe Mathgen a obtenu des résultats très intéressants en matière de supervision des processus, ce qui est un signe positif d'alignement." » est extrêmement coûteux pour les grands modèles et diverses tâches car cela nécessite un retour manuel. Par conséquent, ce travail est d’une grande importance et peut être considéré comme déterminant l’orientation future de la recherche d’OpenAI.
Résoudre des problèmes mathématiques
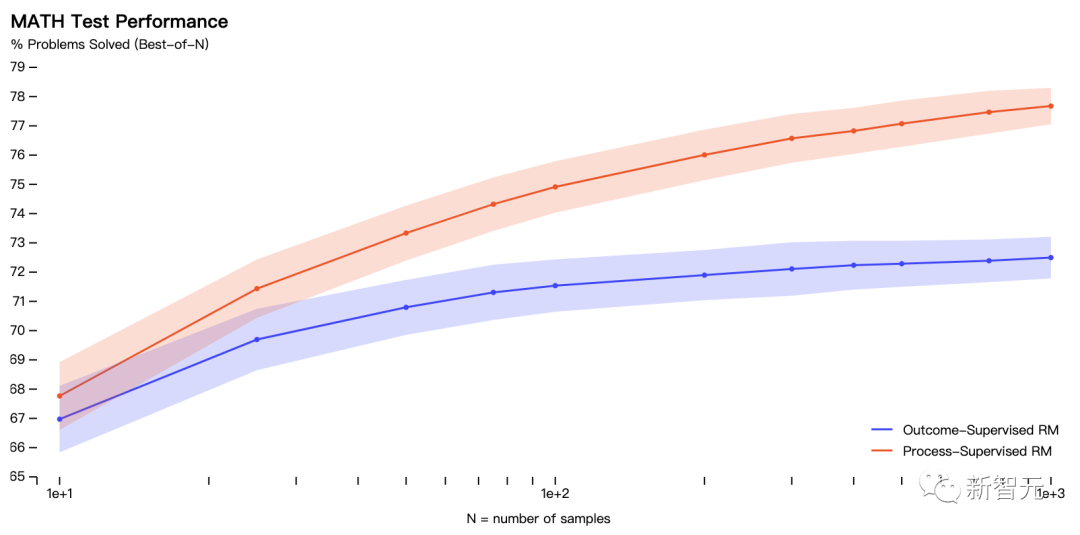
 Dans l'expérience, les chercheurs ont utilisé des problèmes dans l'ensemble de données MATH pour évaluer les modèles de récompense de « supervision des processus » et de « supervision des résultats ».
Dans l'expérience, les chercheurs ont utilisé des problèmes dans l'ensemble de données MATH pour évaluer les modèles de récompense de « supervision des processus » et de « supervision des résultats ».
Le graphique montre le pourcentage de solutions sélectionnées qui ont abouti à une réponse finale correcte en fonction du nombre de solutions considérées.
Le modèle de récompense « supervision des processus » non seulement fonctionne mieux dans l'ensemble, mais l'écart de performance se creuse à mesure que davantage de solutions sont envisagées pour chaque problème.
 Cela montre que le modèle de récompense « supervision des processus » est plus fiable.
Cela montre que le modèle de récompense « supervision des processus » est plus fiable.
Ci-dessous, OpenAI présente 10 problèmes mathématiques et solutions pour le modèle, ainsi que des commentaires sur les avantages et les inconvénients du modèle de récompense.
Le modèle a été évalué à partir des trois types d'indicateurs suivants : vrai (TP), vrai négatif (TN) et faux positif (FP).
Vrai (TP)
Tout d'abord, simplifions la formule de la fonction trigonométrique.
 Ce problème complexe de fonction trigonométrique nécessite l'application de plusieurs identités dans un ordre non évident.
Ce problème complexe de fonction trigonométrique nécessite l'application de plusieurs identités dans un ordre non évident.

Ici, GPT-4 effectue avec succès une série de factorisations polynomiales complexes.
Utiliser l'identité Sophie-Germain à l'étape 5 est une étape importante. On voit que cette étape est très instructive.

Dans les étapes 7 et 8, GPT-4 commence à effectuer des suppositions et des vérifications.
C'est un lieu courant où le modèle peut « halluciner » et prétendre qu'une supposition particulière a été réussie. Dans ce cas, le modèle de récompense valide chaque étape et détermine que la chaîne de pensée est correcte.

Le modèle applique avec succès plusieurs identités trigonométriques pour simplifier l'expression.

À l'étape 7, GPT-4 tente de simplifier une expression, mais la tentative échoue. Le modèle de récompense a détecté ce bug.

À l'étape 11, GPT-4 a commis une simple erreur de calcul. Également découvert par le modèle de récompense.

GPT-4 a essayé d'utiliser la formule de la différence au carré à l'étape 12, mais cette expression n'est pas réellement la différence au carré.

La logique de l'étape 8 est bizarre, mais le modèle bonus la fait passer. Cependant, à l’étape 9, le modèle prend en compte l’expression de manière incorrecte.
Le modèle de récompense corrige cette erreur.

À l'étape 4, GPT-4 prétend à tort que "la séquence se répète tous les 12 éléments", mais en fait elle se répète tous les 10 éléments. Cette erreur de comptage trompe parfois le modèle de récompense.

À l'étape 13, GPT-4 tente de simplifier l'équation en combinant des termes similaires. Il déplace et combine correctement les termes linéaires vers la gauche, mais laisse incorrectement le côté droit inchangé. Le modèle de récompense est trompé par cette erreur.

GPT-4 essaie de faire une division longue, mais à l'étape 16, il oublie d'inclure le zéro non significatif dans la partie répétitive de la décimale. Le modèle de récompense est trompé par cette erreur.

GPT-4 a commis une subtile erreur de comptage à l'étape 9.
En apparence, l'affirmation selon laquelle il existe 5 façons d'échanger des boules de la même couleur (puisqu'il y a 5 couleurs) semble raisonnable.
Cependant, ce décompte est sous-estimé d'un facteur 2 car Bob a 2 choix, c'est-à-dire décider quelle balle donner à Alice. Le modèle de récompense est trompé par cette erreur.

Bien que les grands modèles de langage se soient considérablement améliorés en termes de capacités de raisonnement complexes, même les modèles les plus avancés produisent toujours des erreurs logiques, ou des absurdités, comme on dit souvent « Hallucination ».
Dans l'engouement pour l'intelligence artificielle générative, l'illusion des grands modèles de langage a toujours troublé les gens.
Musc a déclaré que ce dont nous avons besoin, c'est de TruthGPT
Par exemple, récemment, un avocat américain a cité un cas fabriqué de toutes pièces de ChatGPT dans un dossier déposé devant un tribunal fédéral de New York et pourrait faire face à des sanctions.
Les chercheurs d'OpenAI mentionnent dans le rapport : "Ces illusions sont particulièrement problématiques dans les domaines qui nécessitent un raisonnement en plusieurs étapes, car une simple erreur logique peut causer de graves dommages à l'ensemble de la solution."
De plus, atténuer les hallucinations est également la clé de la construction. AGI cohérent.
Comment réduire l'illusion des grands modèles ? Il existe généralement deux méthodes : la supervision des processus et la supervision des résultats.
La « supervision des résultats », comme son nom l'indique, consiste à donner un feedback au grand modèle en fonction des résultats finaux, tandis que la « supervision du processus » peut fournir un feedback pour chaque étape de la chaîne de réflexion.

Dans la supervision des processus, les grands modèles sont récompensés pour leurs étapes de raisonnement correctes, et pas seulement pour leurs conclusions finales correctes. Ce processus encouragera le modèle à suivre des chaînes de méthodes de pensée plus humaines, le rendant ainsi plus susceptible de créer une IA mieux explicable.
Les chercheurs d'OpenAI ont déclaré que même si la supervision des processus n'a pas été inventée par OpenAI, OpenAI travaille dur pour la faire avancer.
Dans les dernières recherches, OpenAI a essayé à la fois les méthodes de « supervision des résultats » ou de « supervision des processus ». Et en utilisant l'ensemble de données MATH comme plate-forme de test, une comparaison détaillée des deux méthodes est effectuée.
Les résultats ont révélé que la « supervision des processus » peut améliorer considérablement les performances du modèle.
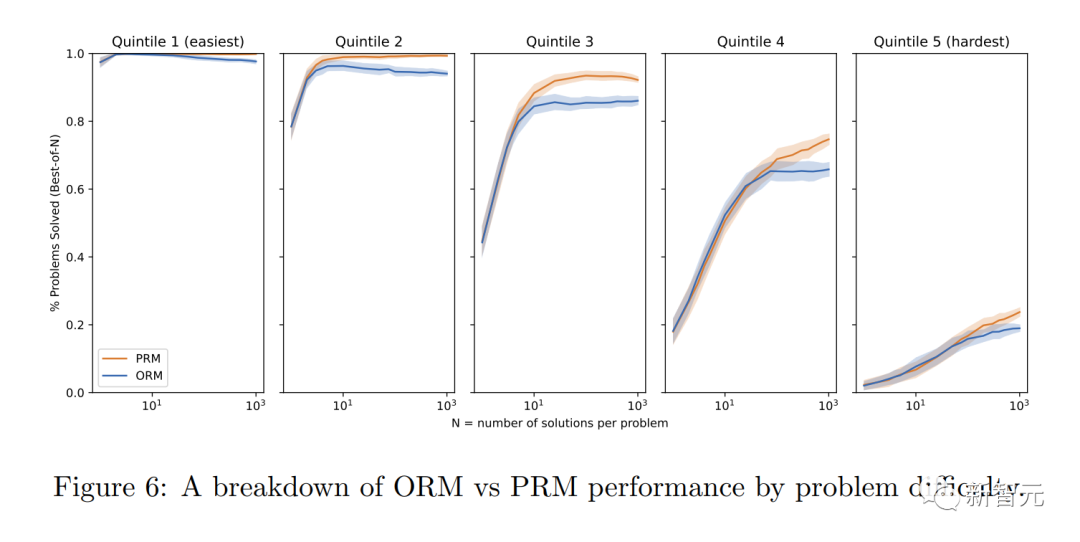
Pour les tâches mathématiques, la « supervision des processus » a produit des résultats nettement meilleurs pour les grands et les petits modèles, ce qui signifie que les modèles étaient généralement corrects et présentaient également des processus de pensée plus humains.
De cette façon, les illusions ou erreurs logiques difficiles à éviter même dans les modèles les plus puissants peuvent être réduites.
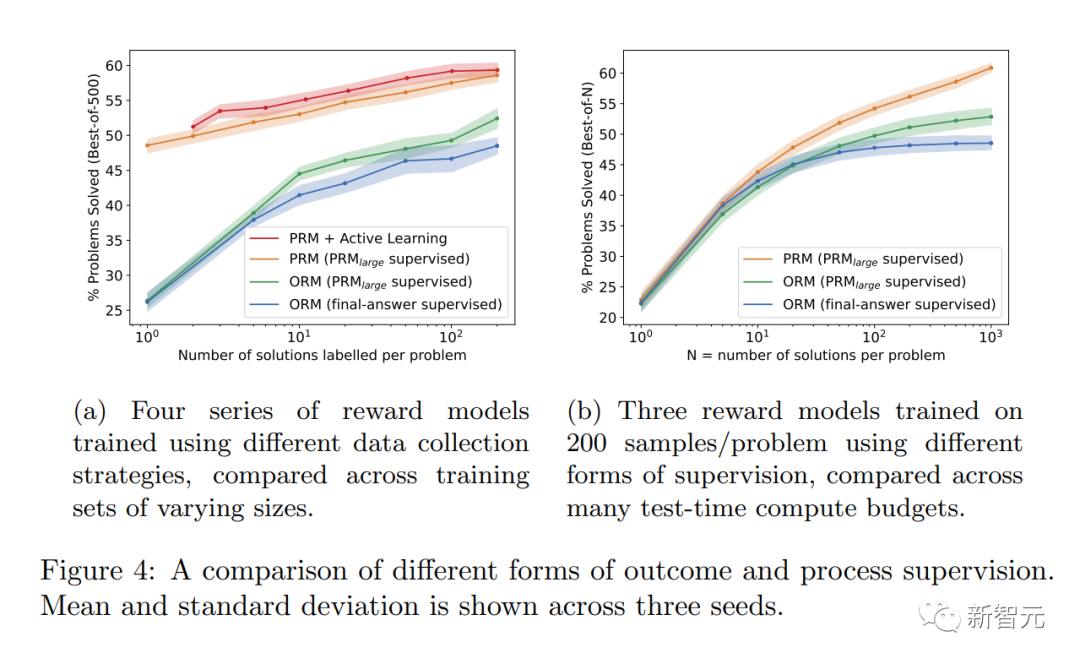
Les chercheurs ont découvert que la « supervision des processus » présente plusieurs avantages d'alignement par rapport à la « supervision des résultats » :
· Les récompenses directes suivent un modèle de chaîne de pensée cohérent car chaque étape du processus Tous sont soumis à un encadrement précis.
· Plus susceptible de produire un raisonnement explicable, car la « supervision des processus » encourage les modèles à suivre des processus approuvés par l'homme. En revanche, le suivi des résultats peut récompenser un processus incohérent et est souvent plus difficile à examiner.
Il convient également de mentionner que dans certains cas, les méthodes visant à rendre les systèmes d'IA plus sûrs peuvent entraîner une dégradation des performances. Ce coût est appelé « taxe d’alignement ».
De manière générale, tout coût de « taxe d'alignement » peut entraver l'adoption de méthodes d'alignement afin de déployer les modèles les plus performants.
Cependant, les résultats suivants des chercheurs montrent que la « supervision des processus » produit en réalité une « taxe d'alignement négative » lors des tests dans le domaine des mathématiques.
On peut dire qu'il n'y a pas de perte de performances majeure due à l'alignement.
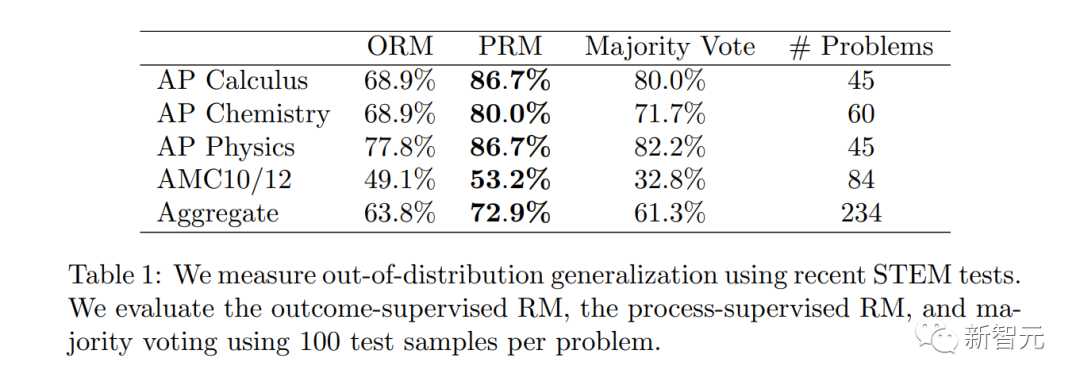
Il convient de noter que PRM nécessite davantage d'annotations humaines et est toujours profondément indissociable du RLHF.
Dans quelle mesure la supervision des processus est-elle applicable dans des domaines autres que les mathématiques ? Ce processus nécessite une exploration plus approfondie.
Les chercheurs d'OpenAI ont ouvert cet ensemble de données de commentaires humains PRM, qui contient 800 000 annotations correctes au niveau des étapes : 75 000 solutions générées à partir de 12 000 problèmes mathématiques

Ce qui suit est un exemple d'annotation. OpenAI publie les annotations brutes, ainsi que les instructions aux annotateurs au cours des phases 1 et 2 du projet.
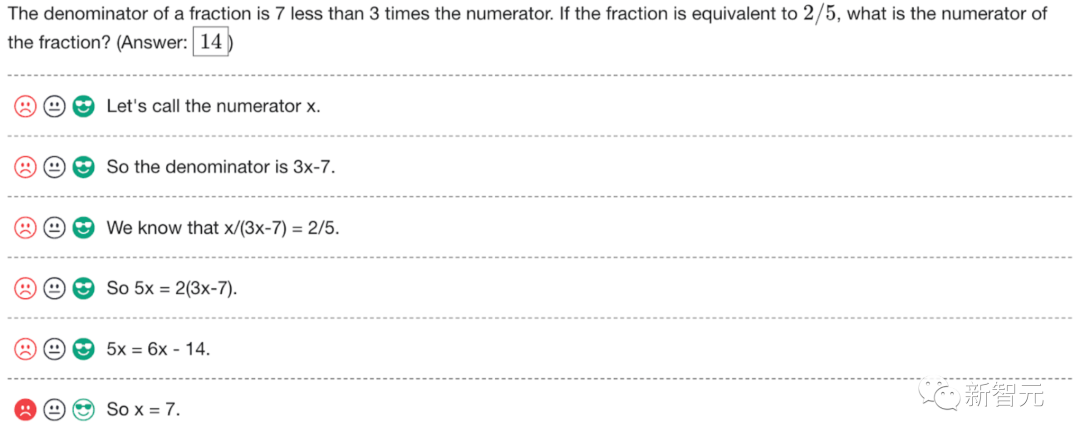
Le scientifique de NVIDIA Jim Fan a fait un résumé des dernières recherches d'OpenAI :
Pour les problèmes complexes, étape par étape, donnez des récompenses à chaque étape au lieu de donner une seule réponse à la fin. prix. Fondamentalement, signal de récompense dense > signal de récompense clairsemé. Le modèle de récompense de processus (PRM) peut mieux sélectionner des solutions pour des tests MATH difficiles que le modèle de récompense de résultat (ORM). La prochaine étape évidente consiste à affiner GPT-4 avec PRM, ce que cet article n'a pas encore fait. Il convient de noter que PRM nécessite davantage d’annotations humaines. OpenAI a publié un ensemble de données de commentaires humains : 800 000 annotations par étapes sur 75 000 solutions à 12 000 problèmes mathématiques.
C'est comme un vieux dicton à l'école, apprends à penser.

Entraîner le modèle à réfléchir, et pas seulement à produire la bonne réponse, changera la donne dans la résolution de problèmes complexes.
ChatGPT est super faible en mathématiques. Aujourd'hui, j'ai essayé de résoudre un problème de mathématiques tiré d'un livre de mathématiques de 4e année. ChatGPT a donné la mauvaise réponse. J'ai vérifié mes réponses avec les réponses de ChatGPT, les réponses de Perplexity AI, Google et mon professeur de quatrième année. On peut confirmer partout que la réponse de chatgpt est fausse.

Référence : https://www.php.cn/link/daf642455364613e2120c636b5a1f9c7
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Où regarder les rediffusions en direct de Douyin
Où regarder les rediffusions en direct de Douyin
 Quelle est la différence entre WeChat et WeChat ?
Quelle est la différence entre WeChat et WeChat ?
 COMMENT INSTALLER LINUX
COMMENT INSTALLER LINUX
 logiciel erp gratuit
logiciel erp gratuit
 Comment résoudre le code tronqué de securecrt
Comment résoudre le code tronqué de securecrt
 Pourquoi ne puis-je pas supprimer la dernière page vierge de Word ?
Pourquoi ne puis-je pas supprimer la dernière page vierge de Word ?
 Dernières tendances des prix du Bitcoin
Dernières tendances des prix du Bitcoin
 Quelles sont les technologies de base nécessaires au développement Java ?
Quelles sont les technologies de base nécessaires au développement Java ?
 Sur quelle plateforme puis-je acheter des pièces Ripple ?
Sur quelle plateforme puis-je acheter des pièces Ripple ?










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



