

Utilisez la fonction d'assistant d'importation de l'outil Navicat. Ce logiciel peut prendre en charge une variété de formats de fichiers, créer automatiquement des tableaux basés sur les champs de fichiers et insérer facilement des données, et il est également très rapide.
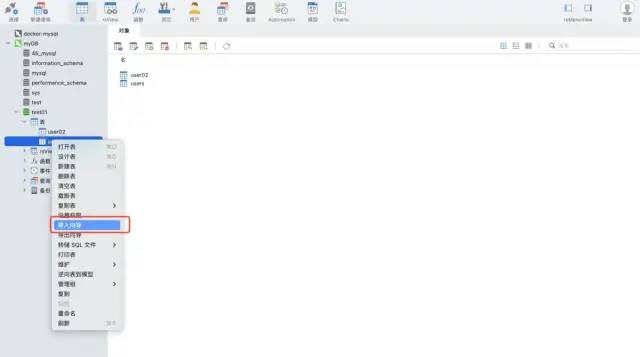
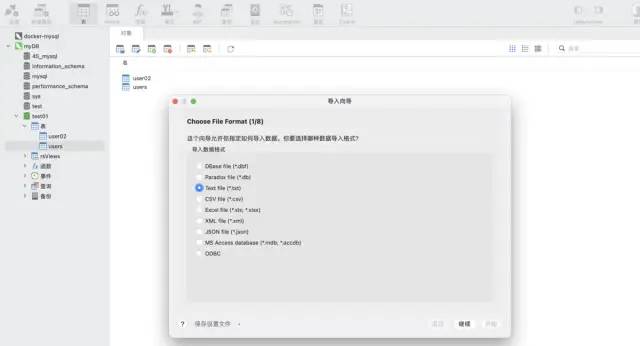
Données de test : format csv, environ 12 millions de lignes
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
Imprimer les résultats

bibliothèque python + pymysql
Installer la commande pymysql
pip install pymysql
Implémentation du code :
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')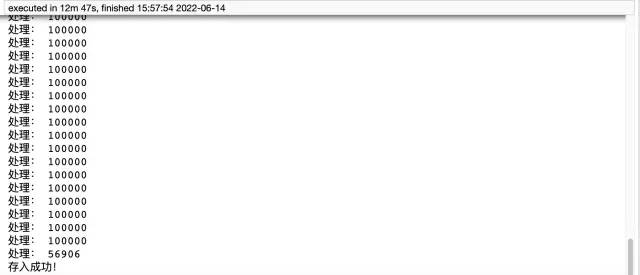
pandas + sqlalchemy : les pandas doivent introduire sqlalchemy pour prendre en charge SQL Avec le support de sqlalchemy, il peut implémenter tous les éléments courants. requête de types de base de données, mise à jour et autres opérations.
Implémentation du code :
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01') data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.to_sql('user02',engine,chunksize=100000,index=None) print('存入成功!')

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



