


Les transactions sont une fonctionnalité importante qui distingue MySQL de NoSQL et constituent une technologie clé pour garantir la cohérence des données dans les bases de données relationnelles. Une unité d'exécution de base composée d'une ou plusieurs instructions SQL peut être considérée comme une opération de transaction sur la base de données. Lorsque ces instructions sont exécutées, soit elles sont toutes exécutées, soit aucune n'est exécutée.
L'exécution d'une transaction comprend principalement deux opérations, le commit et le rollback.
Soumettre : valider, écrire les résultats de l'exécution de la transaction dans la base de données.
Rollback : restauration, restauration de toutes les instructions exécutées et renvoi des données avant modification.
Les transactions MySQL contiennent quatre caractéristiques, connues sous le nom de quatre rois ACID.
Atomicité : les instructions sont soit entièrement exécutées, soit pas exécutées du tout. C'est la caractéristique principale d'une transaction. La transaction elle-même est définie par l'atomicité ; la mise en œuvre est principalement basée sur le journal d'annulation.
Durabilité : garantit que les données ne seront pas perdues en raison d'un temps d'arrêt ou d'autres raisons après la soumission de la transaction ; la mise en œuvre est principalement basée sur le journal redo ;
Isolement : garantit que l'exécution de la transaction n'est pas autant que possible affectée par d'autres transactions ; par défaut Le niveau d'isolement est RR. La mise en œuvre de RR est principalement basée sur le mécanisme de verrouillage, les colonnes de données cachées, le journal d'annulation et le mécanisme de verrouillage de la clé suivante
Cohérence (Cohérence) : Le but ultime poursuivi par la transaction, la réalisation. La cohérence nécessite à la fois la base de données et la base de données. Les garanties au niveau de l'application nécessitent également des garanties au niveau de l'application.
L'atomicité d'une transaction est comme une opération atomique, ce qui signifie que la transaction ne peut pas être subdivisée. , et soit toutes les opérations, soit aucune des opérations sont effectuées ; si la transaction Si une instruction SQL ne s'exécute pas, l'instruction exécutée doit également être annulée et la base de données revient à l'état avant la transaction. Il n'y a que 0 et 1. , et il n'y a pas d'autres valeurs. L'atomicité de la transaction indique que la transaction est un tout. Lorsque la transaction ne réussit pas, toutes les instructions exécutées dans la transaction doivent être annulées, afin que la base de données revienne à l'état. là où la transaction n'a pas été démarrée.
L'atomicité de la transaction est obtenue via le journal d'annulation lorsque la transaction doit être annulée, le moteur InnoDB appellera le journal d'annulation pour annuler l'instruction SQL et implémenter l'annulation des données
.
PersistanceLa durabilité de la transaction est obtenue grâce au redo log dans le moteur de stockage InnoDB. L'idée d'implémentation spécifique voir ci-dessous
L'atomicité et la durabilité sont des propriétés. le niveau d'une seule transaction elle-même, tandis que l'isolement fait référence à la relation entre les transactions qui doivent être isolées les unes des autres. Les opérations ne doivent pas interférer avec d'autres transactionsIl existe de nombreux points de connaissance sur le mécanisme de verrouillage En raison du manque de. espace, je vais tous les expliquer. Voici une brève introduction aux verrous répartis selon la granularité.
Granularité : fait référence au niveau de raffinement ou d'exhaustivité des données stockées dans l'unité de données de l'entrepôt de données. Plus le degré de raffinement est élevé, plus le niveau de granularité est faible ; à l’inverse, plus le degré de raffinement est faible, plus le niveau de granularité est grand.MySQL peut être divisé en verrous de ligne, verrous de table et verrous de page en fonction de la granularité des verrous.Verrouillage de table : Le verrouillage avec la plus grande granularité, ce qui signifie que l'opération en cours verrouille toute la table ;Verrouillage de ligne : Le verrou avec la plus petite granularité, ce qui signifie que seule la ligne de l'opération en cours est verrouillée.
Verrouillage de page : Un verrou avec une granularité entre les verrous au niveau de la ligne et les verrous au niveau de la table, ce qui signifie verrouiller la page.
Ces trois types de verrous verrouillent les données à différents niveaux. En raison de différentes granularités, ils apportent différents avantages et inconvénients.Division granulaire de la base de données
Le verrouillage de la table verrouillera la table entière lors de l'exploitation des données, les performances de concurrence sont donc médiocres ;
Le verrouillage de ligne verrouille uniquement les données qui doivent être exploitées et les performances de concurrence sont bonnes. Cependant, étant donné que le verrouillage lui-même consomme des ressources (l'obtention de verrous, la vérification des verrous, la libération des verrous, etc. consomment tous des ressources), l'utilisation de verrous de table peut économiser beaucoup de ressources lorsqu'il y a beaucoup de données verrouillées.
Différents moteurs de stockage dans MySQL prennent en charge différents verrous. MyIsam ne prend en charge que les verrous de table, tandis qu'InnoDB prend en charge à la fois les verrous de table et les verrous de ligne. Pour des raisons de performances, les verrous de ligne sont utilisés dans la plupart des cas.
Problèmes de lecture et d'écriture simultanées
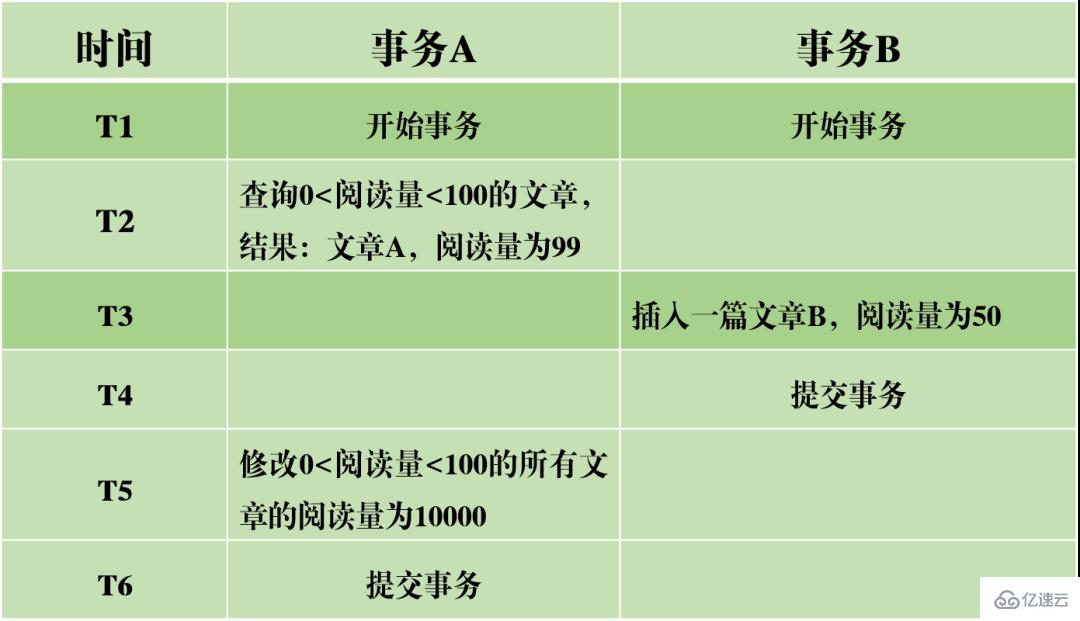
Dans une situation simultanée, la lecture et l'écriture simultanées de MySQL peuvent provoquer trois types de problèmes : les lectures sales, la non-répétabilité et les lectures fantômes.
(1) Lecture sale : la transaction en cours lit les données non validées d'autres transactions, qui sont des données sales.
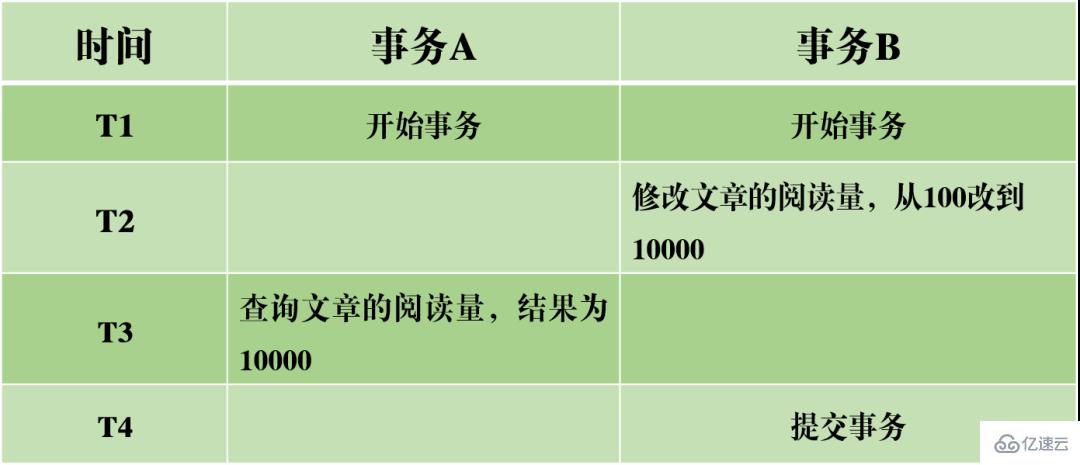
Dans l'exemple de scénario ci-dessus, lorsque la transaction A lit le volume de lecture de l'article, elle obtient les données que la transaction B n'a pas encore soumises. Si la transaction B n'est finalement pas soumise avec succès, entraînant l'annulation de la transaction, alors le montant lu n'est pas réellement modifié avec succès, mais la transaction A lit la valeur modifiée, ce qui est évidemment déraisonnable.
(2) Lecture non répétable : Les mêmes données sont lues deux fois dans la transaction A, mais les résultats des deux lectures sont différents. La différence entre une lecture sale et une lecture non répétable réside dans le fait que la première lit les données non validées par d'autres transactions, tandis que la seconde lit les données soumises par d'autres transactions.
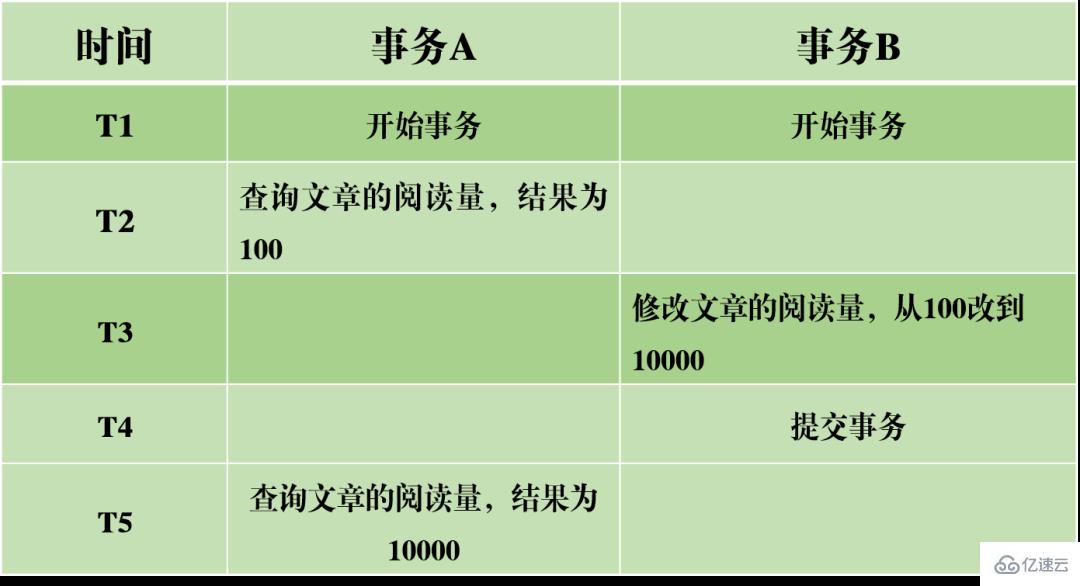
Par exemple, lorsque la transaction A lit les données du volume de lecture de l'article en séquence, elle obtient des résultats différents. Cela signifie que lors de l'exécution de la transaction A, la valeur du volume lu a été modifiée par d'autres transactions. Cela rend les résultats de la requête de données non fiables et irréalistes.
Après réécriture : dans la transaction A, lorsque deux requêtes de base de données sont effectuées selon une certaine condition, le nombre de lignes dans les résultats de la requête est différent, ce qui provoque une lecture fantôme. Les mots originaux peuvent être réécrits comme suit : Par rapport à la lecture fantôme, la lecture non répétable ressemble davantage à un changement dans les données, qui est un changement dans le nombre de lignes de données.
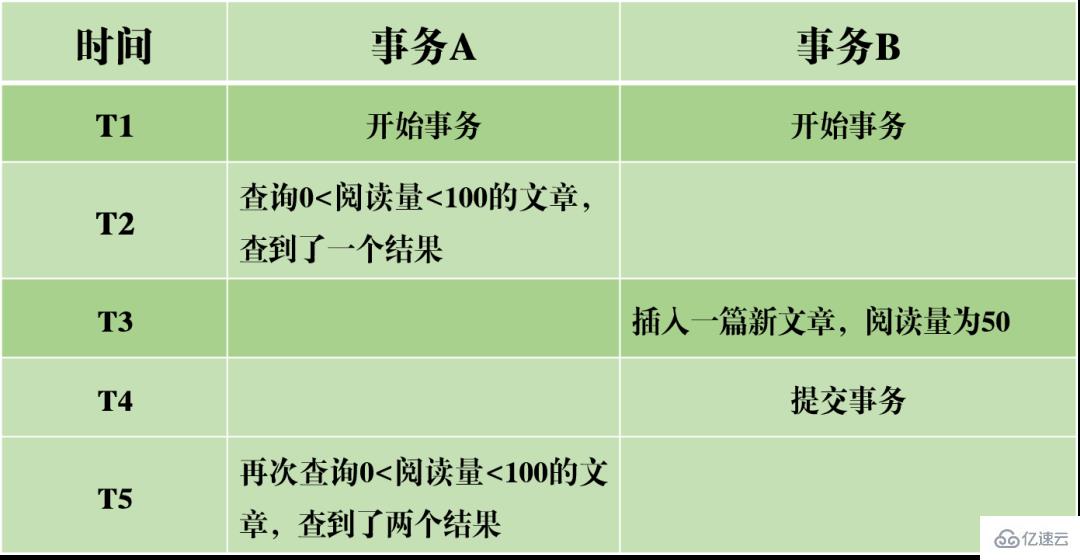
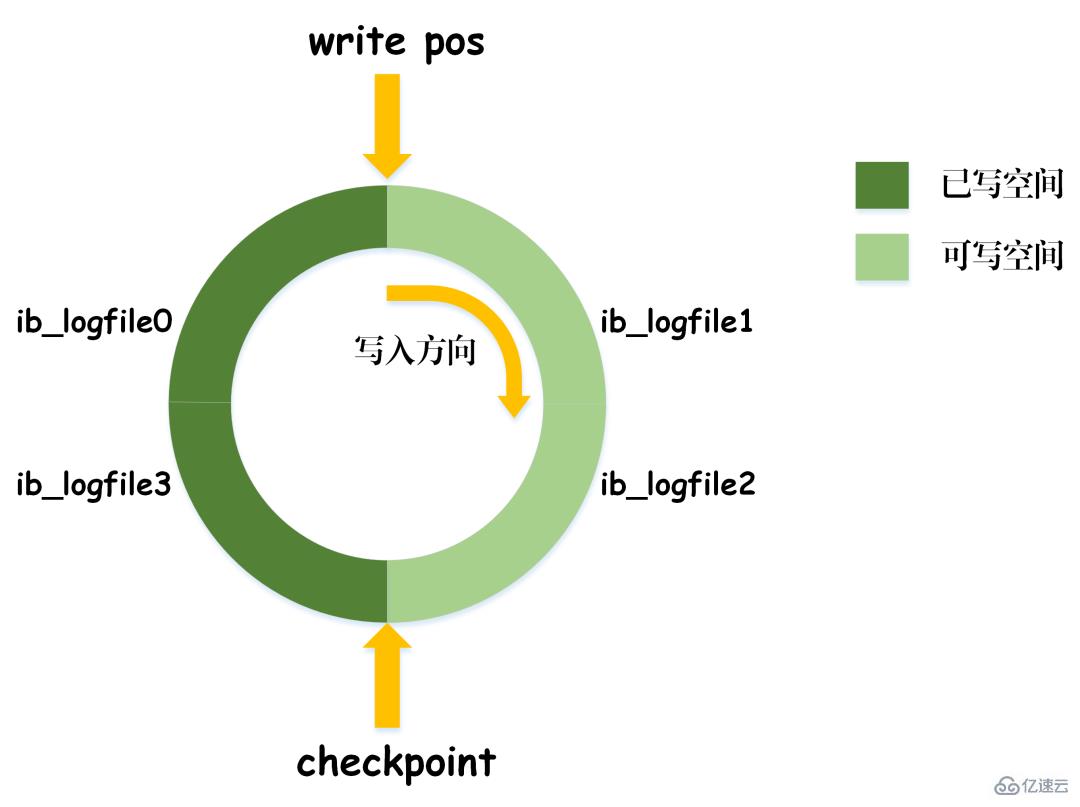
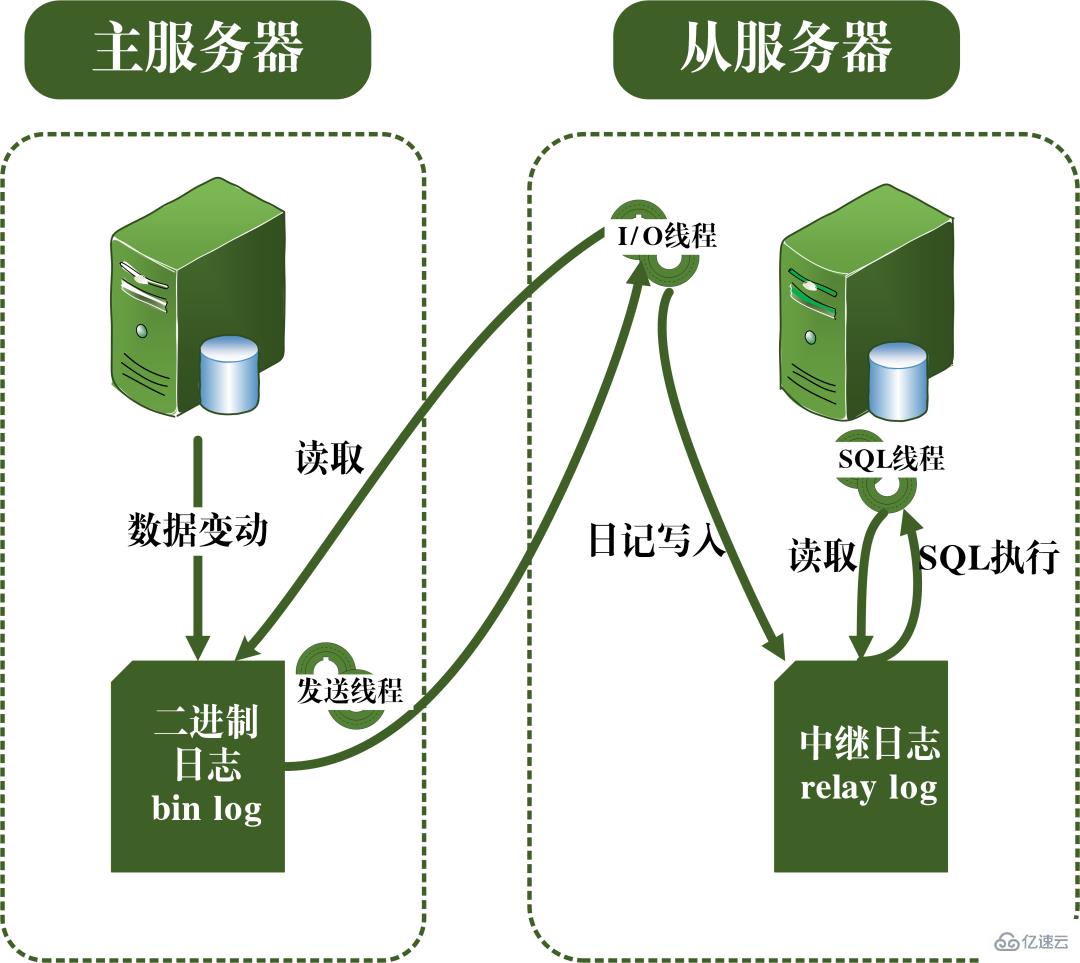
En prenant l'image ci-dessus comme exemple, lors de l'interrogation d'articles avec 0 Niveaux d'isolement Sur la base des trois problèmes ci-dessus, quatre niveaux d'isolement sont générés, indiquant différents degrés de propriétés d'isolement de la base de données. Dans la conception réelle d'une base de données, plus le niveau d'isolement est élevé, plus l'efficacité de la concurrence de la base de données sera faible ; et si le niveau d'isolement est trop faible, la base de données rencontrera divers problèmes compliqués pendant le processus de lecture et d'écriture. Ainsi, dans la plupart des systèmes de bases de données, le niveau d'isolement par défaut est en lecture validée (comme Oracle) ou en lecture répétable RR (moteur InnoDB de MySQL). MVCC Un autre gros morceau difficile à mâcher. MVCC est utilisé pour implémenter le troisième niveau d'isolement ci-dessus, qui peut lire RR à plusieurs reprises. Multi-Version Concurrency Control, également connu sous le nom de MVCC, est un protocole de contrôle de concurrence qui peut prendre en charge plusieurs versions de données. La caractéristique de MVCC est qu'en même temps, différentes transactions peuvent lire différentes versions de données, résolvant ainsi les problèmes de lectures sales et de lectures non répétables. MVCC réalise en fait la coexistence de plusieurs versions de données grâce à des colonnes de données cachées et des journaux de restauration (journal d'annulation). L'avantage est que lors de l'utilisation de MVCC pour lire des données, il n'est pas nécessaire de verrouiller, évitant ainsi les conflits de lecture et d'écriture simultanées. Lors de la mise en œuvre de MVCC, plusieurs colonnes masquées supplémentaires seront enregistrées dans chaque ligne de données, telles que le numéro de version et l'heure de suppression lors de la création de la ligne actuelle et le pointeur de restauration vers le journal d'annulation. Le numéro de version ici n'est pas la valeur temporelle réelle, mais le numéro de version du système. Chaque fois qu'une nouvelle transaction est démarrée, le numéro de version du système est automatiquement incrémenté. Au début d'une transaction, le numéro de version du système se verra attribuer le numéro de version de la transaction pour comparaison avec le numéro de version de chaque ligne d'enregistrements interrogés. Chaque transaction a son propre numéro de version. De cette manière, lorsque des opérations sur les données sont effectuées au sein de la transaction, l'objectif du contrôle de version des données est atteint grâce à la comparaison des numéros de version. De plus, le niveau d'isolement RR implémenté par InnoDB peut éviter le phénomène de lectures fantômes, qui est obtenu grâce au mécanisme de verrouillage de la clé suivante. Le verrouillage de la touche suivante est en fait un type de verrouillage de ligne, mais il verrouille non seulement l'enregistrement de ligne actuel lui-même, mais verrouille également une plage. Par exemple, dans l'exemple ci-dessus de lecture fantôme, lorsque vous commencez à interroger des articles avec 0 Verrouillage des espaces : bloquer les espaces dans les enregistrements d'index Bien qu'InnoDB utilise le verrouillage de la touche suivante pour éviter les problèmes de lecture fantôme, il ne s'agit pas d'une isolation véritablement sérialisable. Regardons un autre exemple. Tout d'abord, permettez-moi de poser une question : Au temps T6, après que la transaction A ait validé la transaction, devinez quel est le volume de lecture de l'article A et de l'article B ? La réponse est que le volume de lecture de l'article AB a été modifié à 10 000. Cela signifie que la soumission de la transaction B affecte en réalité l'exécution de la transaction A, ce qui indique en outre que les deux transactions ne sont pas complètement indépendantes. Bien qu'il puisse éviter le phénomène de lecture fantôme, il n'atteint pas le niveau de sérialisabilité. La condition nécessaire pour atteindre le niveau d'isolement sérialisable est d'éviter les lectures sales, les lectures non répétables et les lectures fantômes, mais cela n'est pas suffisant. La sérialisabilité peut éviter les lectures sales, les lectures non répétables et les lectures fantômes, mais éviter les lectures sales, les lectures non répétables et les lectures fantômes ne permet pas nécessairement d'obtenir la sérialisabilité. Cohérence La cohérence signifie qu'une fois la transaction exécutée, les contraintes d'intégrité de la base de données ne sont pas détruites et l'état des données est légal avant et après l'exécution de la transaction. La cohérence est le but ultime poursuivi par les transactions. L'atomicité, la durabilité et l'isolement existent réellement pour garantir la cohérence de l'état de la base de données. Plus rien à dire. Vous dégustez avec soin. Après avoir appris la structure de base de MySQL, j'ai maintenant une compréhension relativement précise du processus d'exécution de MySQL. Ensuite, je vais vous présenter le système de journalisation. Le système de journalisation MySQL est un composant important de la base de données et est utilisé pour enregistrer les mises à jour et les modifications de la base de données. Si la base de données échoue, les données originales de la base de données peuvent être restaurées via différents enregistrements de journal. Par conséquent, en fait, le système de journalisation détermine directement la robustesse et la robustesse du fonctionnement de MySQL. MySQL possède de nombreux types de journaux, tels que le journal binaire (binlog), le journal des erreurs, le journal des requêtes, le journal des requêtes lentes, etc. De plus, le moteur de stockage InnoDB fournit également deux types de journaux : le journal redo (redo log) et annuler le journal (retourner le journal). Ici, nous allons nous concentrer sur le moteur InnoDB et analyser les trois types de journaux redo, de journaux de restauration et de journaux binaires. Redo log (redo log) Le redo log (redo log) est le journal de la couche moteur InnoDB Il est utilisé pour enregistrer les changements de données provoqués par les opérations de transaction et enregistre la modification physique des pages de données. La fonction de refaire le journal est en fait facile à comprendre, permettez-moi d'utiliser une analogie. La modification des données dans la base de données est comme un article que vous avez écrit. Que se passe-t-il si l'article est perdu un jour ? Pour éviter ce malheureux événement, lors de la rédaction d'un article, nous pouvons tenir un petit carnet pour enregistrer chaque modification, et enregistrer quand et quel type de modifications ont été apportées à une certaine page. C'est le journal de rétablissement. Le moteur InnoDB met à jour les données en écrivant d'abord l'enregistrement de mise à jour dans le journal redo, puis en mettant à jour le contenu du journal sur le disque lorsque le système est inactif ou selon la stratégie de mise à jour définie. La technologie de journalisation dite à écriture anticipée (Write Ahead logging). Cette technologie peut réduire considérablement la fréquence des opérations d'E/S et améliorer l'efficacité de l'actualisation des données. Vinage des données sales Il convient de noter que la taille du journal de rétablissement est fixe Afin d'écrire en continu les enregistrements de mise à jour, deux positions d'indicateur sont définies dans le journal de rétablissement, checkpoint et write_pos, qui représentent respectivement la position où. l'effacement est enregistré et la position où l'écriture est enregistrée. Le diagramme d'écriture des données du journal redo est visible dans la figure ci-dessous. Lorsque le drapeau write_pos atteint la fin du journal, il passera de la fin à la tête du journal pour l'écriture de recirculation. Par conséquent, la structure logique du redo log n’est pas linéaire, mais peut être considérée comme un mouvement circulaire. L'espace entre write_pos et checkpoint peut être utilisé pour écrire de nouvelles données. L'écriture et l'effacement sont effectués en avant et en arrière dans un cycle. Lorsque write_pos rattrape le point de contrôle, cela signifie que le journal de rétablissement est plein. Pour le moment, vous ne pouvez pas continuer à exécuter de nouvelles instructions de mise à jour de base de données. Vous devez d'abord arrêter et supprimer certains enregistrements, puis exécuter des règles de point de contrôle pour libérer de l'espace inscriptible. Règles du point de contrôle : une fois le point de contrôle déclenché, les pages de données sales et les pages de journal sales dans le tampon seront vidées sur le disque. Données sales : font référence aux données de la mémoire qui n'ont pas été vidées sur le disque. Le concept le plus important du redo log est le pool de tampons. Il s'agit d'une zone allouée en mémoire, qui contient le mappage de certaines pages de données sur le disque et sert de tampon pour accéder à la base de données. Lorsqu'une demande de lecture de données est faite, elle déterminera d'abord s'il y a un hit dans le pool de tampons. Si elle manque, elle sera récupérée sur le disque et placée dans le pool de tampons. Une requête est faite pour écrire des données, elles seront écrites en premier Pool de tampons, les données modifiées dans le pool de tampons sont périodiquement vidées sur le disque. Ce processus est également appelé brossage. En plus du vidage des données sales mentionné ci-dessus, en fait, lorsque le journal redo est enregistré, afin d'assurer la persistance du fichier journal, il est également nécessaire d'écrire les enregistrements du journal de la mémoire au processus de disque. Le journal de redo peut être divisé en deux parties. L'une est le buff de journalisation du cache qui existe dans la mémoire volatile, et l'autre est le fichier de journalisation du fichier de journalisation enregistré sur le disque. Afin de garantir que chaque enregistrement peut être écrit dans le journal sur le disque, l'opération fsync du système d'exploitation sera appelée chaque fois que le journal dans le tampon de journalisation est écrit dans le fichier de journalisation. Le journal binaire binlog est un journal de couche de service et est également appelé journal d'archive. Binlog enregistre toutes les opérations de mise à jour dans la base de données, y compris les modifications de la base de données. Toutes les opérations impliquant des modifications de données doivent être enregistrées dans le journal binaire. Par conséquent, binlog peut facilement copier et sauvegarder des données, il est donc souvent utilisé pour la synchronisation des bibliothèques maître-esclave. Bien que le contenu de stockage du binlog et du redo log semble similaire, ils sont en réalité différents. Le redo log est un journal physique, qui enregistre les modifications réelles apportées à certaines données ; tandis que le binlog est un journal logique, qui enregistre la logique originale de l'instruction SQL, telle que "donner le champ de la ligne avec ID=2". Ajoutez 1". Le contenu du journal binlog est binaire. Selon les paramètres de format du journal, il peut être basé sur des instructions SQL, sur les données elles-mêmes ou sur un mélange des deux. Les enregistrements généralement utilisés sont des instructions SQL. Ma compréhension personnelle des concepts de physique et de logique ici est la suivante : De plus, il y a deux étapes de soumission lors de l'écriture du redo log. L'une est l'écriture de l'état de préparation avant l'écriture du binlog, et la seconde est l'écriture de l'état de validation après l'écriture du binlog. La raison d'organiser une telle soumission en deux étapes est naturellement logique. Nous pouvons maintenant supposer qu'au lieu d'utiliser la soumission en deux phases, nous adoptons la soumission « en une seule phase », c'est-à-dire soit écrire d'abord le journal de rétablissement, puis écrire le journal binaire, soit écrire d'abord le journal binaire, puis écrire le journal de rétablissement. La soumission de ces deux manières entraînera une incohérence entre l'état de la base de données d'origine et l'état de la base de données restaurée. Écrivez d'abord le journal de rétablissement, puis écrivez le journal binaire : Après avoir écrit le journal de rétablissement, les données ont une capacité de sécurité en cas de crash à ce moment-là, de sorte que le système tombe en panne et les données seront restaurées à l'état où elles étaient avant le début de la transaction. Si le système plante après l'écriture du journal redo mais avant l'écriture du binlog, alors... Pour le moment, binlog n'enregistre pas l'instruction de mise à jour ci-dessus, ce qui entraîne l'absence de l'instruction de mise à jour ci-dessus lorsque binlog est utilisé pour sauvegarder ou restaurer la base de données. Par conséquent, les données de la ligne id=2 ne sont pas mises à jour. Le problème de l'écriture du redo log d'abord, puis du binlog Écrivez d'abord le binlog, puis du redo log : Après l'écriture du binlog, toutes les instructions sont enregistrées, elles peuvent donc être copiées ou restaurées via binlog Les données dans la ligne id=2 dans la base de données sera mise à jour en a=1. Cependant, si le système tombe en panne avant l'écriture du journal redo, la transaction enregistrée dans le journal redo sera invalide, ce qui entraînera la non mise à jour des données de la ligne id=2 dans la base de données réelle. Le problème de l'écriture du binlog d'abord, puis du redo log On peut voir que la soumission en deux étapes vise à éviter les problèmes ci-dessus et à rendre cohérentes les informations enregistrées dans le binlog et le redo log. Journal de restauration (journal d'annulation) Le moteur InnoDB fournit un journal de restauration, qui est utilisé pour les opérations de restauration de données. Lorsqu'une transaction modifie la base de données, le moteur InnoDB enregistrera non seulement le journal de rétablissement, mais générera également le journal d'annulation correspondant ; si l'exécution de la transaction échoue ou si un rollback est appelé, provoquant l'annulation de la transaction, les informations contenues dans le journal d'annulation ; peut être utilisé pour restaurer les données jusqu'à ce qu'elles étaient avant la modification. Mais l'annulation du journal est différente du rétablissement du journal. Il s'agit d'un journal logique. Il enregistre les informations liées à l'exécution des instructions SQL. Lorsqu'une restauration se produit, le moteur InnoDB fera le contraire du travail précédent en fonction des enregistrements du journal d'annulation. Par exemple, pour chaque opération d'insertion de données (insertion), une opération de suppression de données (suppression) sera effectuée lors de la restauration ; pour chaque opération de suppression de données (suppression), une opération d'insertion de données (insertion) sera effectuée lors de la restauration ; Opération de mise à jour (mise à jour), lors de la restauration, une opération de mise à jour inversée des données (mise à jour) sera effectuée pour modifier les données. Le journal d'annulation a deux fonctions, l'une consiste à fournir une restauration et l'autre à implémenter MVCC. Le concept de réplication maître-esclave est très simple : copier une base de données identique à partir de la base de données d'origine est appelée la base de données maître, et la base de données copiée est appelée. la base de données esclave. La base de données esclave synchronisera les données avec la base de données maître pour maintenir la cohérence des données entre les deux. Le principe de la réplication maître-esclave est en fait implémenté via le journal bin. Le journal du journal bin stocke toutes les instructions SQL dans la base de données. En copiant les instructions SQL dans le journal du journal bin, puis en exécutant les instructions, la base de données esclave et la base de données principale peuvent être synchronisées. Le processus de réplication maître-esclave est visible dans la figure ci-dessous. Le processus de réplication maître-esclave est principalement effectué par trois threads. Un thread d'envoi s'exécute sur le serveur maître et est utilisé pour envoyer les journaux binlog au serveur esclave. Il existe deux threads d'E/S et threads SQL supplémentaires en cours d'exécution sur le serveur esclave. Le thread d'E/S est utilisé pour lire le contenu du journal binlog envoyé par le serveur principal et le copier dans le journal de relais local. Le thread SQL lit les instructions SQL contenant les mises à jour de données du journal de relais et effectue des opérations basées sur ces instructions pour garantir que les données de la base de données maître-esclave restent cohérentes. Principe de réplication maître-esclave La raison pour laquelle la réplication maître-esclave doit être mise en œuvre est en fait déterminée par le scénario d'application réel. Les avantages que la réplication maître-esclave peut apporter sont les suivants : 1. Réaliser une sauvegarde hors site des données via la réplication. Lorsque la base de données maître tombe en panne, la base de données esclave peut être commutée pour éviter la perte de données. 2. L'architecture peut être étendue. Lorsque le volume d'activité devient plus important et que la fréquence d'accès aux E/S est trop élevée, l'utilisation d'un stockage multi-bases de données peut réduire la fréquence d'accès aux E/S du disque et améliorer les E/S. des performances d'une seule machine. 3. Il peut réaliser la séparation de la lecture et de l'écriture, afin que la base de données puisse prendre en charge une plus grande concurrence. 4. Implémentez l'équilibrage de charge du serveur en divisant la charge des requêtes clients entre le serveur maître et le serveur esclave. 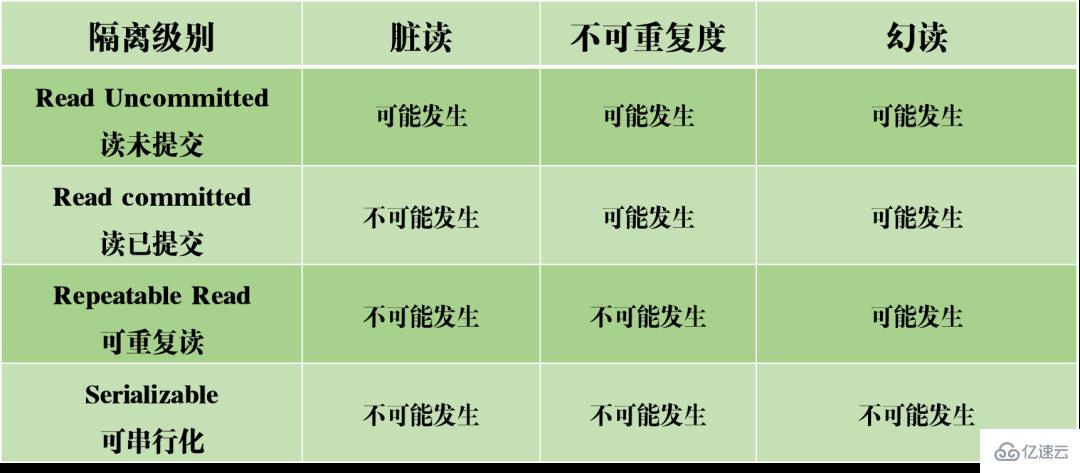
2. Système de journalisation MySQL
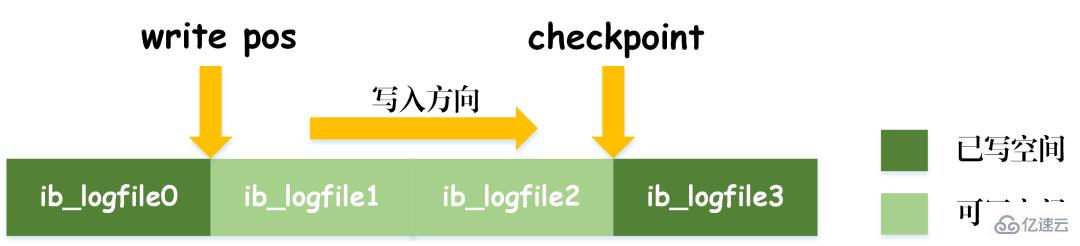
Par conséquent, lorsque les données sont modifiées, en plus de modifier les données dans le pool de tampons, l'opération sera également enregistrée dans le journal redo ; lorsque la transaction est soumise, les données seront vidées en fonction des enregistrements du journal redo ; . Si MySQL tombe en panne, les données du journal redo peuvent être lues lors du redémarrage et la base de données peut être restaurée, garantissant ainsi la durabilité des transactions et rendant la base de données sécurisée.
Vinage du journal sale
Lors de l'écriture, il faut également passer par le cache de l'espace noyau du système d'exploitation. Le processus d'écriture du journal redo est visible dans la figure ci-dessous.
processus de vidage du journal redo 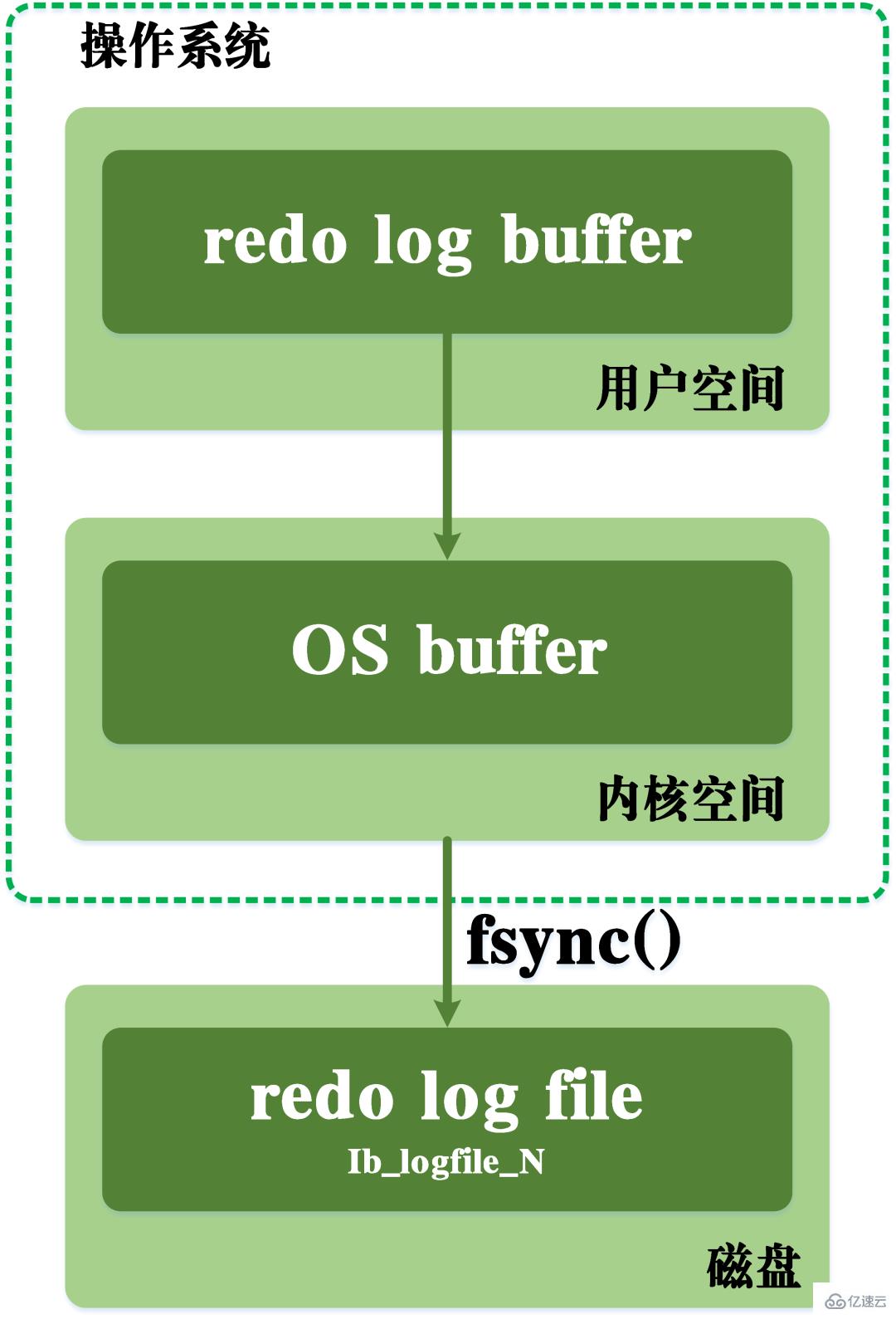
Dans le même temps, le journal redo est basé sur la récupération après crash pour garantir la récupération des données après un crash de MySQL ; tandis que le binlog est basé sur une récupération à un moment précis pour garantir que le serveur peut récupérer les données en fonction de points temporels ou sauvegarder les données. . En fait, MySQL n'avait pas de journal de rétablissement au début. Parce qu'au début MySQL n'avait pas de moteur InnoDB, le moteur intégré était MyISAM. Binlog est un journal de couche de service, il peut donc être utilisé par tous les moteurs. Cependant, les journaux binlog à eux seuls ne peuvent fournir que des fonctions d'archivage et ne peuvent pas fournir de fonctionnalités de sécurité en cas de crash. Par conséquent, le moteur InnoDB utilise une technologie apprise d'Oracle, à savoir le redo log, pour obtenir des fonctionnalités de sécurité en cas de crash. Ici, les caractéristiques du redo log et du binlog sont comparées respectivement :
Comparaison des caractéristiques du redo log et du binlog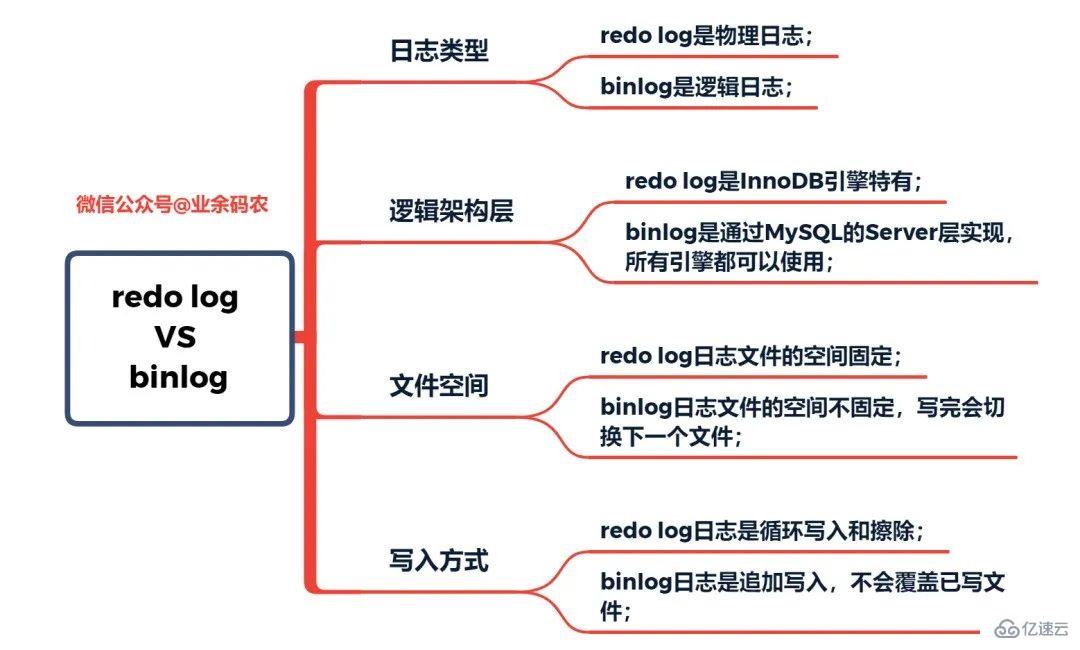 Lorsque MySQL exécute les instructions de mise à jour, la lecture et l'écriture du redo log et du binlog sont impliquées. Le processus d'exécution d'une instruction de mise à jour est le suivant :
Lorsque MySQL exécute les instructions de mise à jour, la lecture et l'écriture du redo log et du binlog sont impliquées. Le processus d'exécution d'une instruction de mise à jour est le suivant : 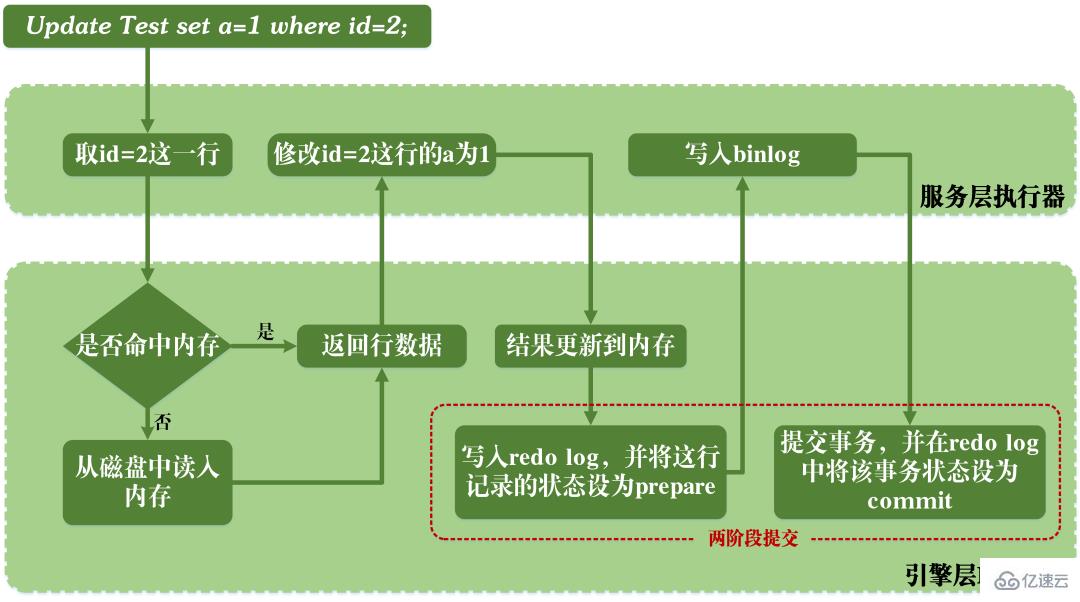 Comme le montre la figure ci-dessus, lorsque MySQL exécute l'instruction de mise à jour, il analyse et exécute l'instruction au niveau du service. couche et au niveau de la couche moteur Extraction et stockage des données en même temps, binlog est écrit dans la couche service et redo log est écrit dans InnoDB.
Comme le montre la figure ci-dessus, lorsque MySQL exécute l'instruction de mise à jour, il analyse et exécute l'instruction au niveau du service. couche et au niveau de la couche moteur Extraction et stockage des données en même temps, binlog est écrit dans la couche service et redo log est écrit dans InnoDB. 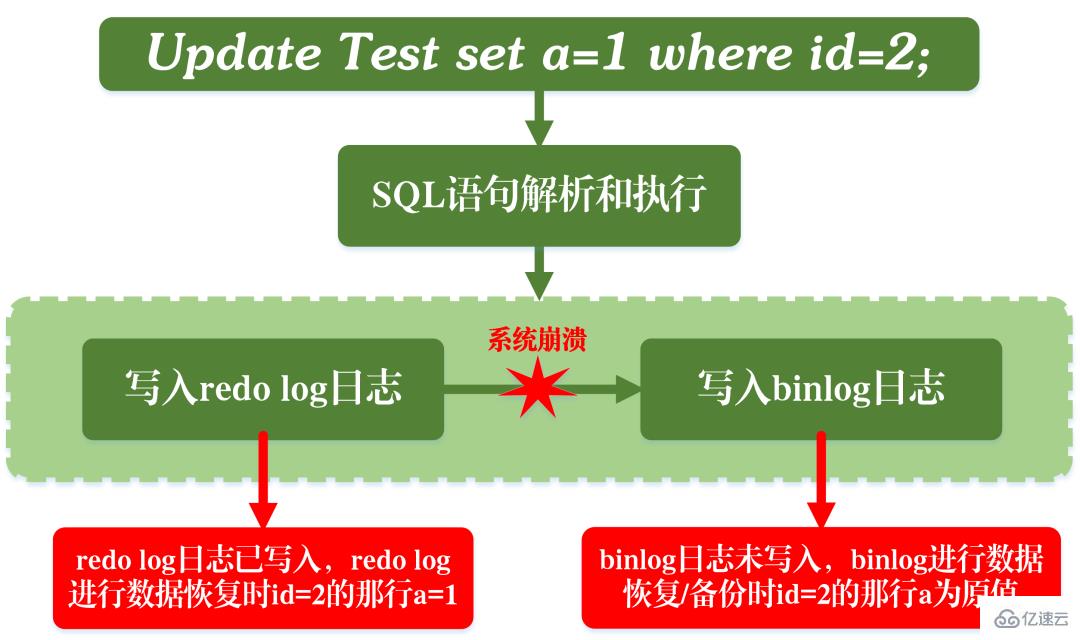
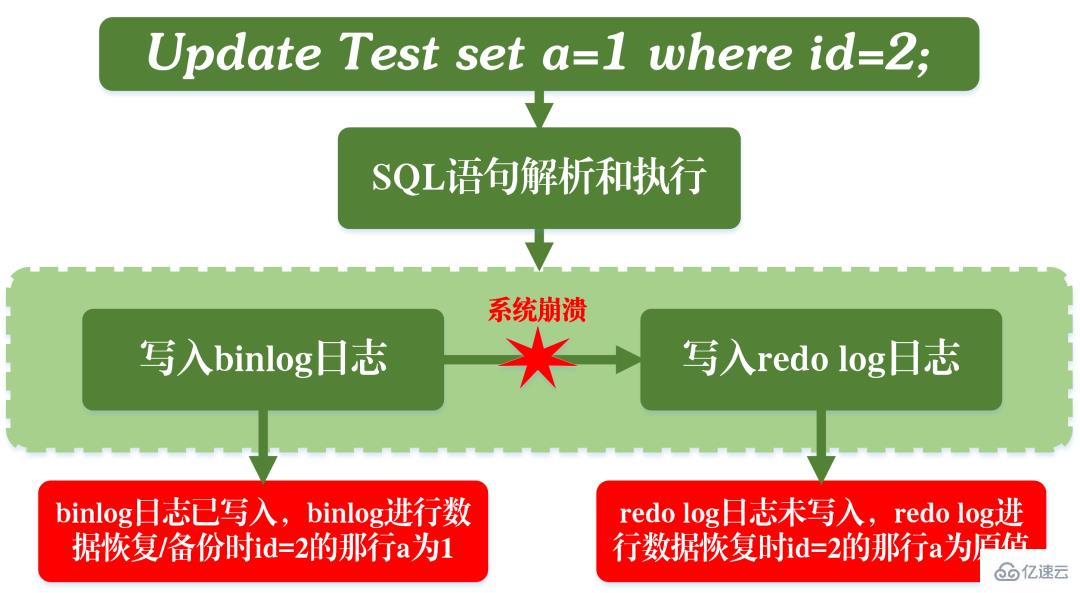
3. Réplication maître-esclave
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



