

Montrer la puissance de la programmation neurosymbolique
Au cours des dernières années, nous avons assisté à l'essor des modèles basés sur Transformer et obtenu des résultats dans de nombreux domaines tels que le traitement du langage naturel ou la vision par ordinateur. . candidature réussie. Dans cet article, nous explorerons une manière concise, interprétable et évolutive d'exprimer les modèles d'apprentissage profond, en particulier Transformer, sous la forme d'une architecture hybride, c'est-à-dire en combinant l'apprentissage profond avec l'intelligence artificielle symbolique. Par conséquent, nous implémenterons le modèle dans un framework neurosymbolique Python appelé PyNeuraLogic.
En combinant les représentations symboliques avec l'apprentissage profond, nous comblons les lacunes des modèles d'apprentissage profond actuels, telles que l'interprétabilité prête à l'emploi et les techniques d'inférence manquantes. Peut-être qu’augmenter le nombre de paramètres n’est pas le moyen le plus raisonnable d’obtenir les résultats souhaités, tout comme augmenter le nombre de mégapixels dans un appareil photo ne produit pas nécessairement de meilleures photos.
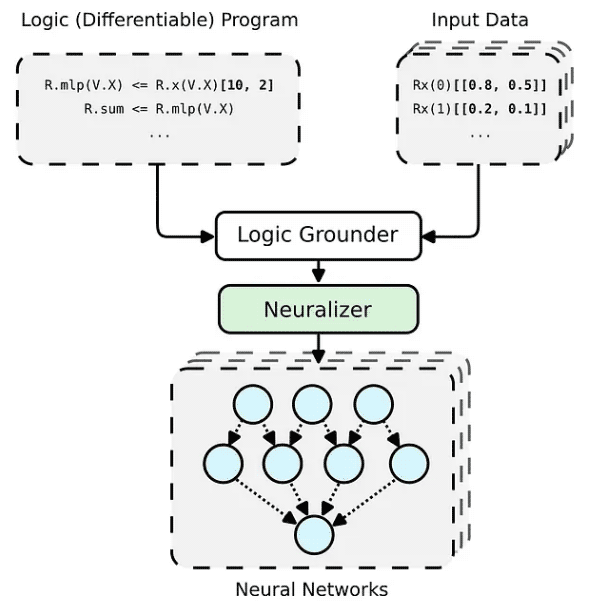
Le framework PyNeuraLogic est basé sur la programmation logique - les programmes logiques contiennent des paramètres différentiables. Le cadre est bien adapté aux données structurées plus petites (par exemple, molécules) et aux modèles complexes (par exemple, transformateurs et réseaux de neurones graphiques). PyNeuraLogic n'est pas le meilleur choix pour les données tensorielles non relationnelles et volumineuses.
L'élément clé du cadre est un programme logique différentiable, que nous appelons un modèle. Un modèle se compose de règles logiques qui définissent la structure d'un réseau neuronal de manière abstraite. Nous pouvons considérer un modèle comme un modèle pour l'architecture du modèle. Le modèle est ensuite appliqué à chaque instance de données d'entrée pour générer (via la base et la neurolisation) un réseau neuronal unique à l'échantillon d'entrée. Complètement différent des autres architectures prédéfinies, ce processus ne peut pas s'adapter à différents échantillons d'entrée.
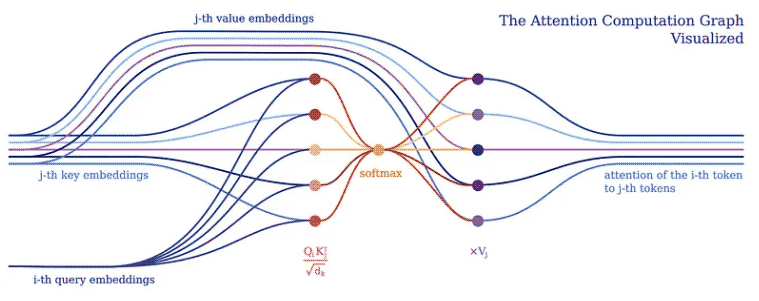
Habituellement, nous implémenterons le modèle d'apprentissage en profondeur pour effectuer des opérations tensorielles sur des lots de jetons d'entrée dans un grand tenseur. Cela est logique car les frameworks et le matériel d'apprentissage profond (tels que les GPU) sont généralement optimisés pour traiter des tenseurs plus grands plutôt que plusieurs tenseurs de formes et de tailles différentes. Les transformateurs ne font pas exception, regroupant généralement une représentation vectorielle de jeton unique dans une grande matrice et représentant le modèle sous forme d'opérations sur une telle matrice. Cependant, une telle implémentation cache les relations entre les jetons d’entrée individuels, comme en témoigne le mécanisme d’attention du Transformer.
Le mécanisme d'attention constitue le cœur de tous les modèles Transformer. Plus précisément, sa version classique utilise ce qu'on appelle l'attention du produit ponctuel à mise à l'échelle multi-têtes. Utilisons un en-tête (pour plus de clarté) pour décomposer l'attention du produit scalaire mis à l'échelle en un programme logique simple.
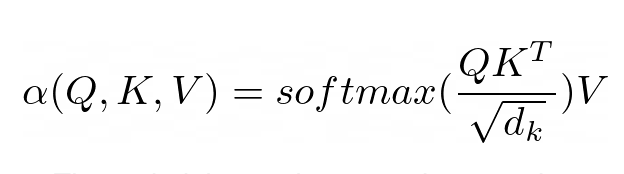
Le but de l'attention est de décider sur quelles parties de l'entrée le réseau doit se concentrer. Lors de la mise en œuvre, il convient de prêter attention à la valeur calculée pondérée V. Le poids représente la compatibilité de la clé d'entrée K et de la requête Q. Dans cette version particulière, les poids sont calculés par la fonction softmax du produit scalaire de la requête Q et de la clé de requête K, divisé par la racine carrée de la dimension vectorielle de la fonctionnalité d'entrée d_k.
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product]
Dans PyNeuraLogic, nous pouvons pleinement capturer le mécanisme d'attention grâce aux règles logiques ci-dessus. La première règle représente le calcul du poids : elle calcule le produit de la racine carrée inverse de la dimension et du j-ème vecteur clé et du i-ème vecteur de requête transposés. Ensuite, nous utilisons la fonction softmax pour agréger les résultats de i avec tous les j possibles.
La deuxième règle calcule ensuite le produit entre ce vecteur de poids et le j-ème vecteur de valeur correspondant et additionne les résultats pour différents j pour chaque i-ème jeton.
Pendant la formation et l'évaluation, nous limitons souvent ce à quoi le jeton d'entrée peut participer. Par exemple, nous souhaitons limiter les marqueurs pour anticiper et nous concentrer sur les mots à venir. Les frameworks populaires, tels que PyTorch, y parviennent en masquant, c'est-à-dire en définissant un sous-ensemble d'éléments du résultat du produit scalaire mis à l'échelle sur un nombre négatif très faible. Ces nombres précisent que la fonction softmax est forcée de mettre à zéro le poids de la paire de balises correspondante.
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.J, V.I)
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],Nous pouvons facilement y parvenir en ajoutant des contraintes de relation corporelle à nos symboles. Nous contraignons le i-ème indicateur à être supérieur ou égal au j-ème indicateur pour calculer le poids. Contrairement aux masques, nous calculons uniquement le produit scalaire mis à l’échelle requis.
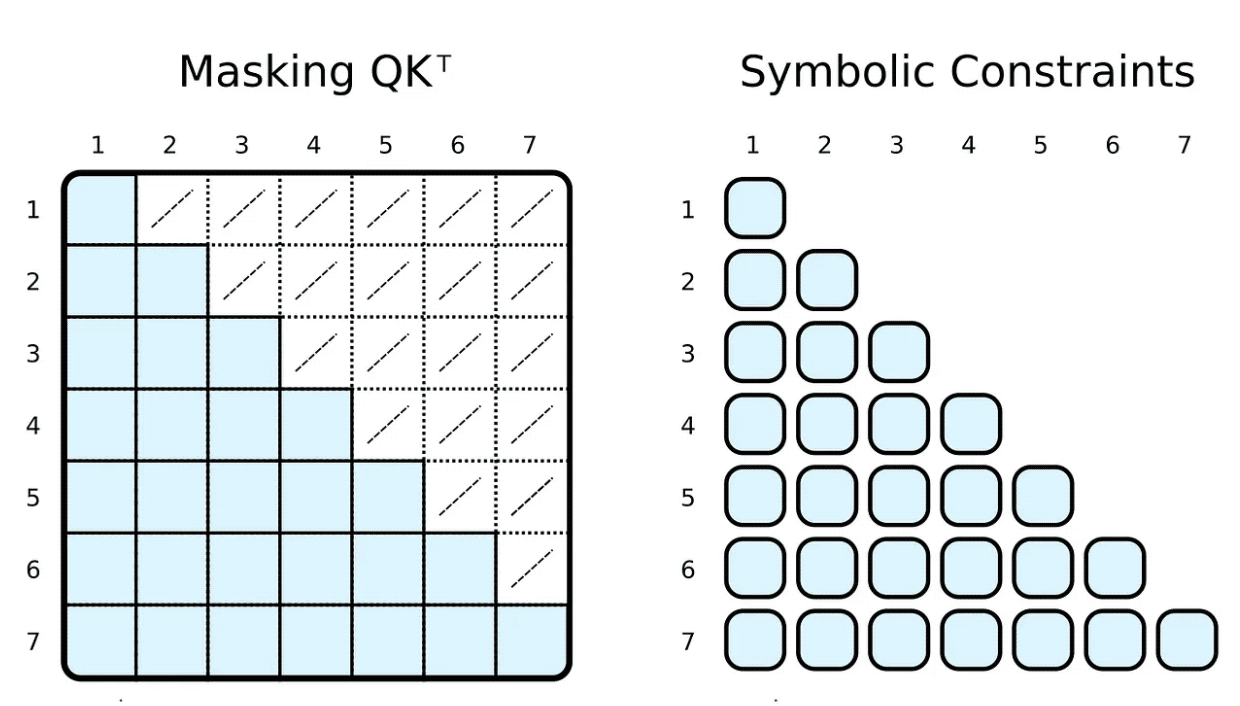
Bien entendu, le "masquage" symbolique peut être complètement arbitraire. La plupart des gens ont entendu parler du GPT-3⁴ basé sur un transformateur clairsemé ou de ses applications telles que ChatGPT. ⁵ Attention (version stride) du transformateur clairsemé a deux types de têtes d'attention :
一个只关注前 n 个标记 (0 ≤ i − j ≤ n)
一个只关注每第 n 个前一个标记 ((i − j) % n = 0)
两种类型的头的实现都只需要微小的改变(例如,对于 n = 5)。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.leq(V.D, 5), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.mod(V.D, 5, 0), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],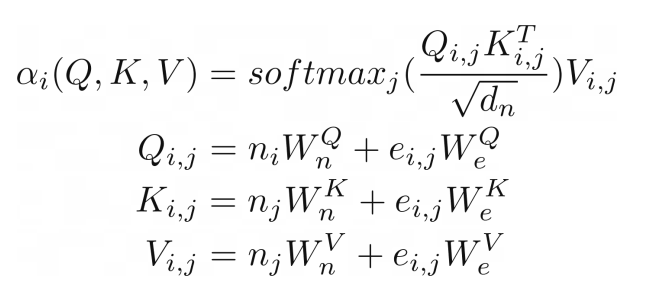
我们可以进一步推进,将类似图形输入的注意力概括到关系注意力的程度。⁶ 这种类型的注意力在图形上运行,其中节点只关注它们的邻居(由边连接的节点)。结果是节点向量嵌入和边嵌入的键 K、查询 Q 和值 V 相加。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.I, V.J).T, R.q(V.I, V.J))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.I, V.J)) | [F.product], R.q(V.I, V.J) <= (R.n(V.I)[W_qn], R.e(V.I, V.J)[W_qe]), R.k(V.I, V.J) <= (R.n(V.J)[W_kn], R.e(V.I, V.J)[W_ke]), R.v(V.I, V.J) <= (R.n(V.J)[W_vn], R.e(V.I, V.J)[W_ve]),
在我们的示例中,这种类型的注意力与之前展示的点积缩放注意力几乎相同。唯一的区别是添加了额外的术语来捕获边缘。将图作为注意力机制的输入似乎很自然,这并不奇怪,因为 Transformer 是一种图神经网络,作用于完全连接的图(未应用掩码时)。在传统的张量表示中,这并不是那么明显。
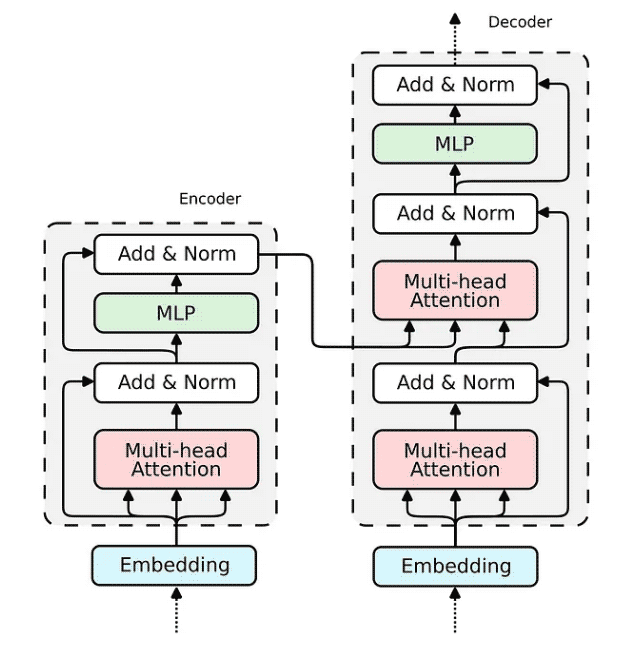
现在,当我们展示 Attention 机制的实现时,构建整个 transformer 编码器块的缺失部分相对简单。
如何在 Relational Attention 中实现嵌入已经为我们所展现。对于传统的 Transformer,嵌入将非常相似。我们将输入向量投影到三个嵌入向量中——键、查询和值。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v],
查询嵌入通过跳过连接与注意力的输出相加。然后将生成的向量归一化并传递到多层感知器 (MLP)。
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
对于 MLP,我们将实现一个具有两个隐藏层的全连接神经网络,它可以优雅地表达为一个逻辑规则。
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
最后一个带有规范化的跳过连接与前一个相同。
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
所有构建 Transformer 编码器所需的组件都已经被构建完成。解码器使用相同的组件;因此,其实施将是类似的。让我们将所有块组合成一个可微分逻辑程序,该程序可以嵌入到 Python 脚本中并使用 PyNeuraLogic 编译到神经网络中。
R.q(V.I) <= R.input(V.I)[W_q], R.k(V.I) <= R.input(V.I)[W_k], R.v(V.I) <= R.input(V.I)[W_v], R.d_k[1 / math.sqrt(embed_dim)], (R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])], (R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product], (R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm], (R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu], (R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



