
 développement back-end
Tutoriel Python
Quelle est la méthode de communication entre les processus Python ?
développement back-end
Tutoriel Python
Quelle est la méthode de communication entre les processus Python ?
Quelle est la méthode de communication entre les processus Python ?

Qu'est-ce que la communication de processus
Voici un exemple de mécanisme de communication : Nous connaissons tous le mot communication, par exemple, une personne veut appeler sa petite amie. Une fois l'appel établi, une file d'attente implicite (notez cette terminologie) est formée. À ce moment-là, cette personne continuera à donner des informations à sa petite amie par le biais du dialogue, et la petite amie de cette personne écoute également. Je pense que dans la plupart des cas, c'est probablement l'inverse.
Les deux peuvent être comparés à deux processus. Le processus de « cette personne » doit envoyer des informations au processus de « petite amie », il a donc besoin de l'aide d'une file d'attente. Étant donné que la petite amie a besoin de recevoir des informations dans la file d'attente à tout moment, elle peut faire autre chose en même temps, ce qui signifie que la communication entre les deux processus repose principalement sur la file d'attente.
Cette file d'attente peut prendre en charge l'envoi et la réception de messages. "Cette personne" est responsable de l'envoi des messages, tandis que "petite amie" est responsable de la réception des messages.
Puisque la file d'attente est au centre de nos préoccupations, voyons comment créer la file d'attente.
Création de file d'attente - multitraitement
utilise toujours le module multitraitement et appelle la fonction Queue de ce module pour créer la file d'attente.
| Nom de la fonction | Introduction | Paramètres | Valeur de retour |
|---|---|---|---|
| Queue | Création de file d'attente | mac_count | Objet Queue |
Introduction à la fonction Queue : appeler Queue peut créer une file d'attente ; Il a un paramètre mac_count qui représente le nombre maximum de messages pouvant être créés dans la file d'attente. S'il n'est pas transmis, la longueur par défaut est illimitée. Après avoir instancié un objet de file d'attente, vous devez utiliser l'objet de file d'attente pour insérer et supprimer des données.
Méthode de communication entre les processus
| Nom de la fonction | Introduction | Paramètres | Valeur de retour |
|---|---|---|---|
| put | Mettre le message dans la file d'attente | message | Non e |
| get | Recevoir un message de file d'attente | Aucun | str |
Introduction à la fonction Put : transmettre les données. Il comporte un message de paramètre, qui est un type de chaîne.
get introduction à la fonction : utilisée pour recevoir des données dans la file d'attente. (En fait, il s'agit d'un scénario JSON courant. Une grande partie de la transmission de données se fait sous forme de chaînes. L'insertion et la récupération de files d'attente utilisent des chaînes, donc json est très approprié pour ce scénario.)
Ensuite, pratiquons l'utilisation des files d'attente.
Communication inter-processus - Cas de démonstration de file d'attente
L'exemple de code est le suivant :
# coding:utf-8
import json
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send.start()
receive.start()Exception rencontrée lors de l'utilisation de la file d'attente pour établir une communication inter-processus
Mais une erreur apparaîtra ici, comme indiqué ci-dessous :
Un exemple La capture d'écran d'erreur est la suivante :
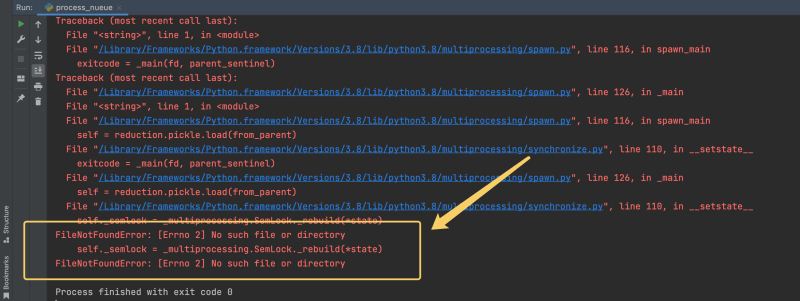
Le message d'erreur ici signifie que le fichier n'a pas été trouvé. En fait, lorsque nous utilisons la file d'attente pour faire put() et get(), un verrou invisible est ajouté, qui est le .SemLock dans le cercle de l'image ci-dessus. Nous n'avons pas besoin de nous soucier de la cause spécifique de cette erreur. La résolution de ce problème est en fait très simple.
FileNotFoundError : [Errno 2] Aucune solution d'exception de fichier ou de répertoire
Ce qui doit bloquer le processus n'est qu'un des sous-processus d'envoi ou de réception. Il s'agit simplement d'une situation théorique. Mais notre sous-processus de réception est une boucle while, qui s'exécutera toujours, il nous suffit donc d'ajouter une jointure au sous-processus d'envoi.
Le schéma de solution est le suivant :
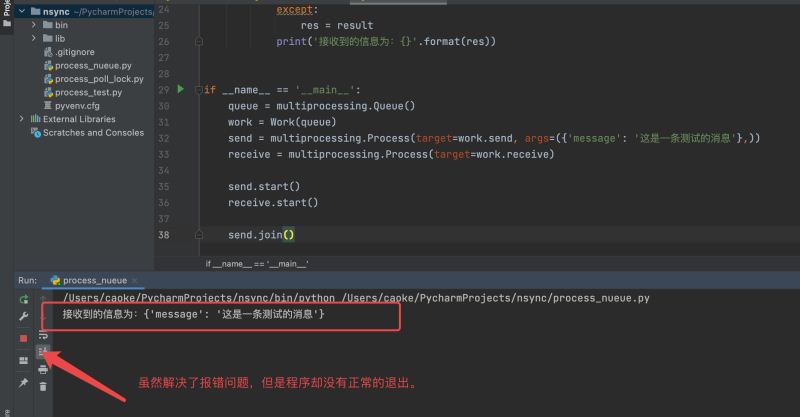
PS : Bien que le problème d'erreur ait été résolu, le programme ne s'est pas terminé normalement.
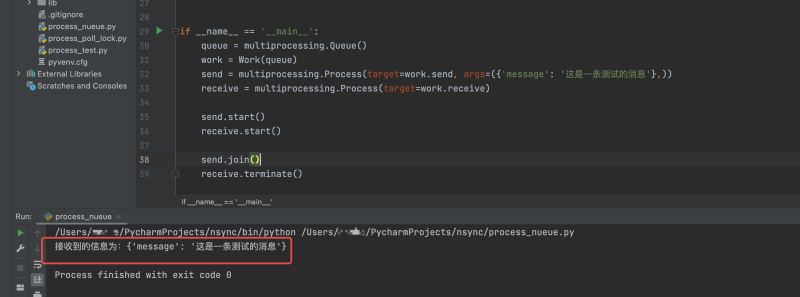
En fait, puisque notre processus de réception est une boucle while, nous ne savons pas quand il sera traité et il n'y a aucun moyen d'y mettre fin immédiatement. Nous devons donc utiliser la fonction terminate() dans le processus de réception pour terminer la réception.
Les résultats en cours d'exécution sont les suivants :
Ajouter des données à la fonction d'envoi par lots
Créez une nouvelle fonction et écrivez-la dans une boucle for pour simuler l'ajout de messages à envoyer par lots
Puis ajoutez un fil de discussion à cette fonction qui simule l'envoi de données par lots.
L'exemple de code est le suivant :
# coding:utf-8
import json
import time
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def send_all(self): # 定义一个 send_all(发送)函数,然后通过for循环模拟批量发送的 message
for i in range(20):
self.queue.put('第 {} 次循环,发送的消息为:{}'.format(i, i))
time.sleep(1)
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send_all = multiprocessing.Process(target=work.send_all,)
send_all.start() # 这里因为 send 只执行了1次,然后就结束了。而 send_all 却要循环20次,它的执行时间是最长的,信息也是发送的最多的
send.start()
receive.start()
# send.join() # 使用 send 的阻塞会造成 send_all 循环还未结束 ,receive.terminate() 函数接收端就会终结。
send_all.join() # 所以我们只需要阻塞最长使用率的进程就可以了
receive.terminate()Les résultats d'exécution sont les suivants :
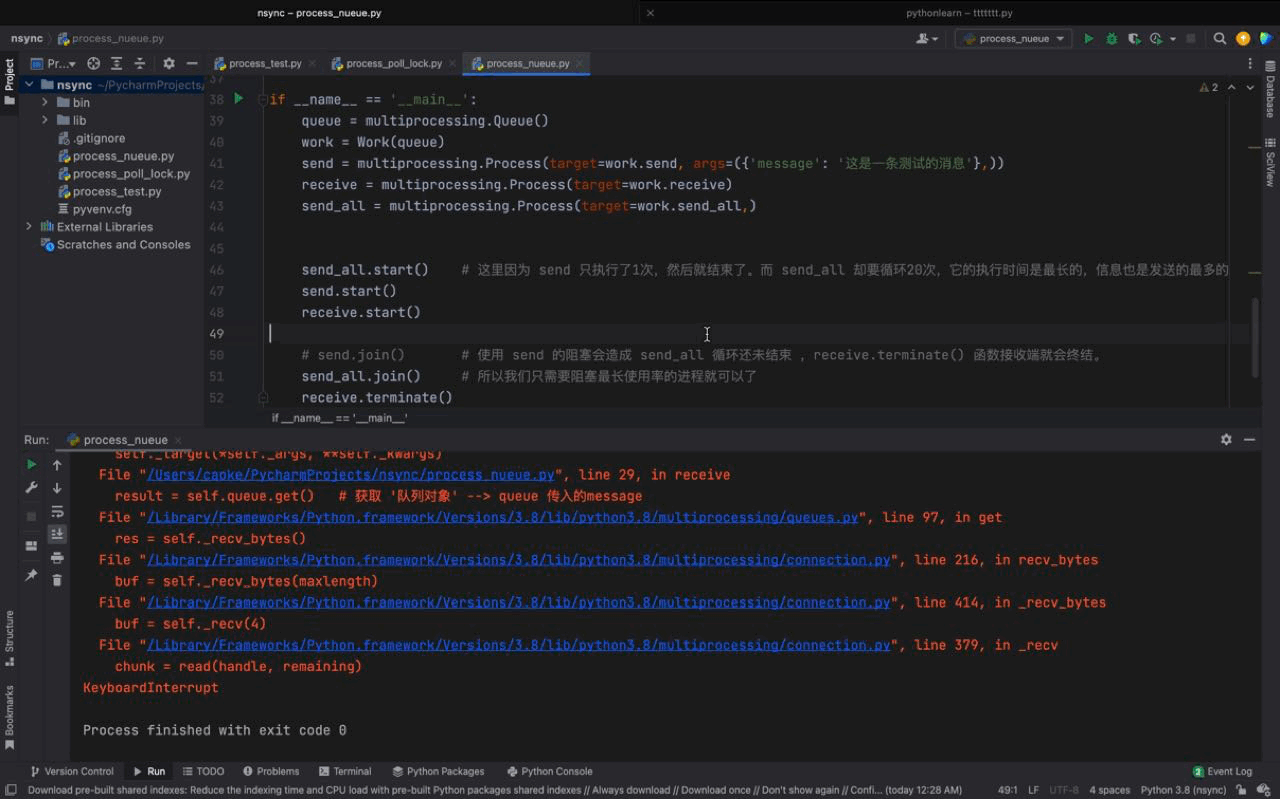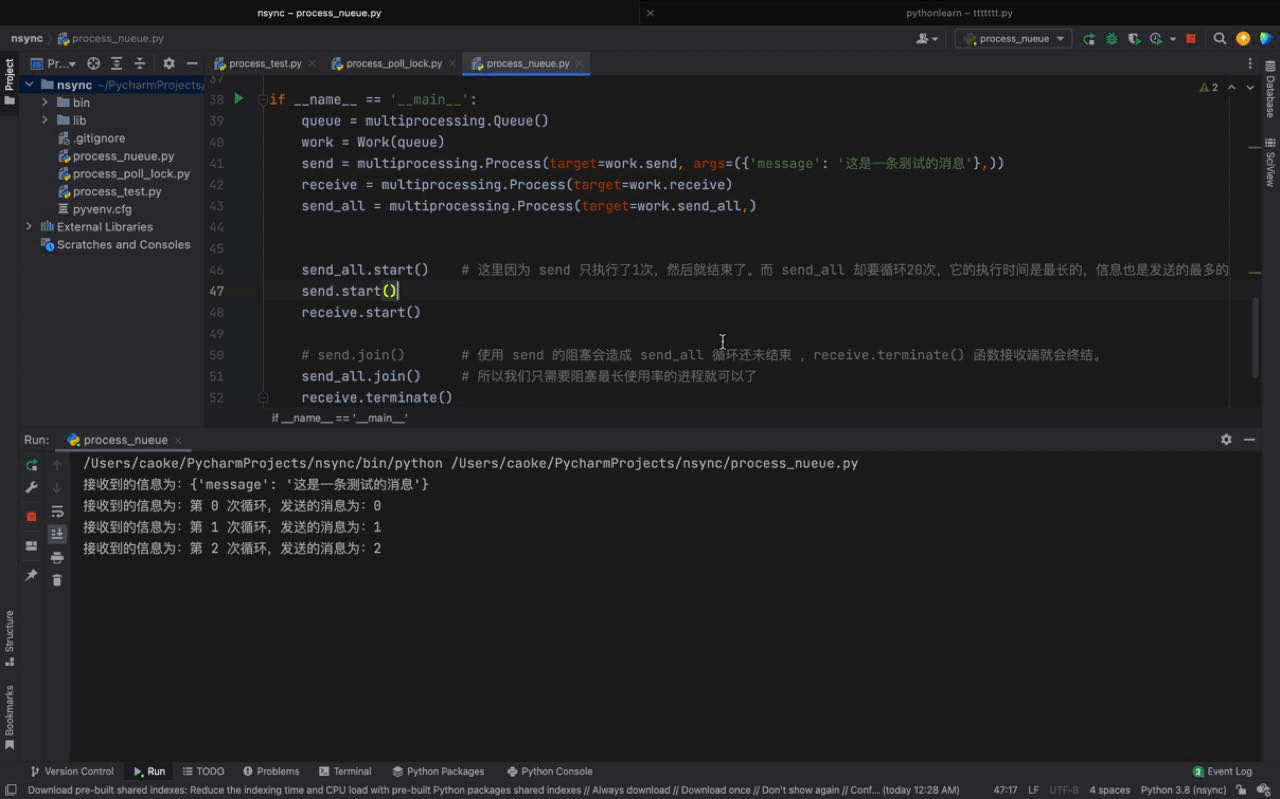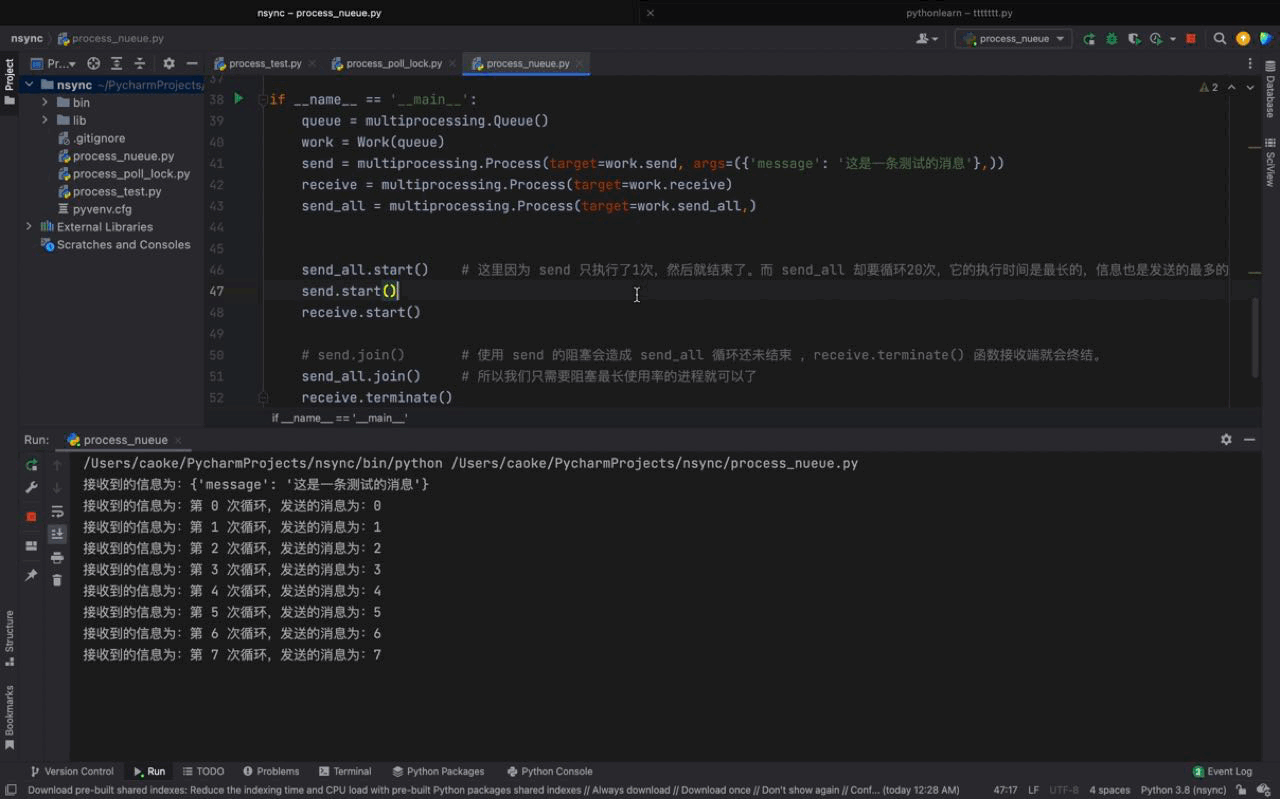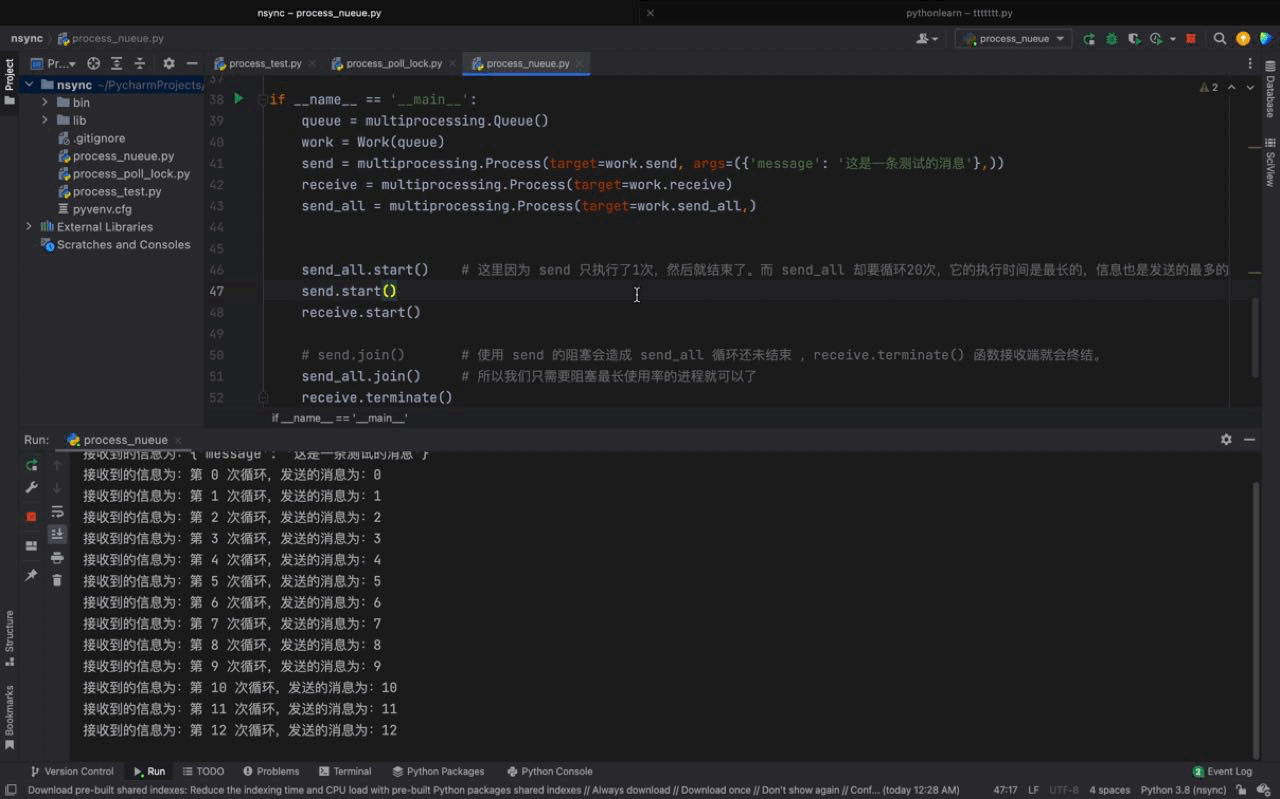
De la figure ci-dessus, nous pouvons voir que les processus send et send_all peuvent envoyer des messages via l'objet Queue instancié par file d'attente, et le même fonction de réception. Les messages transmis par les deux processus seront également imprimés.
Section
Dans ce chapitre, nous avons utilisé avec succès les files d'attente pour réaliser une communication inter-processus, et avons également maîtrisé les compétences opérationnelles des files d'attente. Dans une file d'attente, une extrémité (ici nous démontrons l'extrémité d'envoi) ajoute des informations pertinentes via la méthode put, et l'autre extrémité utilise la méthode get pour obtenir des informations pertinentes, les deux processus coopèrent l'un avec l'autre pour obtenir l'effet d'un seul processus ; communication.
En plus des files d'attente, les processus peuvent également communiquer à l'aide de canaux, de sémaphores et de mémoire partagée. Si vous êtes intéressé, vous pouvez en apprendre davantage sur ces méthodes. Vous pouvez l'étendre vous-même.
Autres moyens de communication inter-processus - Supplément
Python fournit une variété de moyens de communication de processus, notamment des signaux, des canaux, des files d'attente de messages, des sémaphores, de la mémoire partagée, des sockets, etc.
Les deux méthodes principales sont Queue et Pipe .Queue Utilisé pour implémenter la communication entre plusieurs processus, Pipe est la communication entre deux processus.
Tubes : divisés en tubes anonymes et tubes nommés
Tubes anonymes : demandent un tampon de taille fixe dans le noyau. Le programme a le droit d'écrire et de lire. Généralement, la fonction fock est utilisée pour réaliser la communication entre. Processus parent et enfant
Canal nommé : demande un tampon de taille fixe en mémoire. Le programme a le droit d'écrire et de lire. Les processus qui ne sont pas liés par le sang peuvent également communiquer entre les processus
Caractéristiques : Orienté vers les flux d'octets ; le cycle de vie suit le noyau ; est livré avec Mécanisme d'exclusion mutuelle synchrone ; communication unidirectionnelle semi-duplex, deux canaux réalisent une communication bidirectionnelle
Une façon de réécrire est d'établir une file d'attente dans le noyau du système d'exploitation, la file d'attente contient plusieurs éléments de datagramme et plusieurs processus peuvent accéder à la file d'attente via un handle spécifique. Les files d'attente de messages peuvent être utilisées pour envoyer des données d'un processus à un autre. Chaque bloc de données est considéré comme ayant un type, et les blocs de données reçus par le processus récepteur peuvent avoir des types différents. Les files d'attente de messages présentent également les mêmes inconvénients que les tubes, c'est-à-dire qu'il existe une limite supérieure sur la longueur maximale de chaque message, il existe une limite supérieure sur le nombre total d'octets dans chaque file d'attente de messages et il existe également une limite supérieure sur le nombre total de files d'attente de messages sur le système
Caractéristiques : File d'attente de messages Elle peut être considérée comme une liste chaînée globale. Le type et le contenu du datagramme sont stockés dans les nœuds de la liste chaînée, qui sont marqués de l'identifiant de la file d'attente de messages. ; la file d'attente de messages permet à un ou plusieurs processus d'écrire ou de lire des messages ; la durée de vie de la file d'attente de messages Le cycle suit le noyau, la file d'attente de messages peut réaliser une communication bidirectionnelle ;
3. Sémaphore : créez une collection de sémaphores (essentiellement un tableau) dans le noyau. Les éléments du tableau (sémaphores) sont tous 1. Utilisez l'opération P pour effectuer -1 et utilisez l'opération V pour +1
P. (sv) : Si la valeur de sv est supérieure à zéro, décrémentez-la de 1 ; si sa valeur est nulle, suspendez l'exécution du programme
V(sv) : Si d'autres processus sont suspendus en attente de sv, laissez-le reprendre opération. Si aucun processus ne se bloque en raison de l'attente de sv, ajoutez-y 1
L'opération PV est utilisée pour le même processus afin d'obtenir une exclusion mutuelle ; l'opération PV est utilisée pour différents processus afin d'obtenir la synchronisation
Fonction : Protéger les ressources critiques
4. Mémoire partagée : mappez le même morceau de mémoire physique dans l'espace d'adressage virtuel de différents processus pour parvenir au partage de la même ressource entre différents processus. En ce qui concerne les méthodes de communication inter-processus, la mémoire partagée peut être considérée comme la forme d'IPC la plus utile et la plus rapide.
Caractéristiques : Contrairement aux changements et copies fréquents de données du mode utilisateur au mode noyau, il suffit de les lire directement à partir de la mémoire. ; partage La mémoire est une ressource critique, les opérations doivent donc être atomiques. Vous pouvez utiliser un sémaphore ou un mutex.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Bien que distincts et distincts soient liés à la distinction, ils sont utilisés différemment: distinct (adjectif) décrit le caractère unique des choses elles-mêmes et est utilisée pour souligner les différences entre les choses; Distinct (verbe) représente le comportement ou la capacité de distinction, et est utilisé pour décrire le processus de discrimination. En programmation, distinct est souvent utilisé pour représenter l'unicité des éléments d'une collection, tels que les opérations de déduplication; Distinct se reflète dans la conception d'algorithmes ou de fonctions, tels que la distinction étrange et uniforme des nombres. Lors de l'optimisation, l'opération distincte doit sélectionner l'algorithme et la structure de données appropriés, tandis que l'opération distincte doit optimiser la distinction entre l'efficacité logique et faire attention à l'écriture de code clair et lisible.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
! x Compréhension! X est un non-opérateur logique dans le langage C. Il booléen la valeur de x, c'est-à-dire que les véritables modifications sont fausses et fausses modifient true. Mais sachez que la vérité et le mensonge en C sont représentés par des valeurs numériques plutôt que par les types booléens, le non-zéro est considéré comme vrai, et seul 0 est considéré comme faux. Par conséquent,! X traite des nombres négatifs de la même manière que des nombres positifs et est considéré comme vrai.
 Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Il n'y a pas de fonction de somme intégrée en C pour la somme, mais il peut être implémenté par: en utilisant une boucle pour accumuler des éléments un par un; Utilisation d'un pointeur pour accéder et accumuler des éléments un par un; Pour les volumes de données importants, envisagez des calculs parallèles.
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données dynamiques de la page de travail 58.com tout en rampant? Lorsque vous rampez une page de travail de 58.com en utilisant des outils de chenilles, vous pouvez rencontrer cela ...
 Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code n'est pas impossible, mais il doit être traité avec prudence. Des dépendances telles que l'environnement, les bibliothèques, les versions, etc. dans le code peuvent ne pas correspondre au projet actuel, entraînant des erreurs ou des résultats imprévisibles. Assurez-vous de vous assurer que le contexte est cohérent, y compris les chemins de fichier, les bibliothèques dépendantes et les versions Python. De plus, lors de la copie et de la collation du code pour une bibliothèque spécifique, vous devrez peut-être installer la bibliothèque et ses dépendances. Les erreurs courantes incluent les erreurs de chemin, les conflits de version et les styles de code incohérents. L'optimisation des performances doit être redessinée ou refactorisée en fonction de l'objectif d'origine et des contraintes du code. Il est crucial de comprendre et de déboguer le code copié, et de ne pas copier et coller aveuglément.
