

Quels sont les huit problèmes classiques de Redis ?

1. Pourquoi utiliser Redis
Le blogueur estime que les principales considérations liées à l'utilisation de Redis dans les projets sont les performances et la concurrence. Bien sûr, redis a également d'autres fonctions telles que les verrous distribués, mais s'il s'agit uniquement d'autres fonctions telles que les verrous distribués, il existe d'autres middlewares (tels que zookpeer, etc.) à la place, et il n'est pas nécessaire d'utiliser redis. Par conséquent, cette question reçoit principalement une réponse sous deux angles : les performances et la concurrence.
Réponse : Comme indiqué ci-dessous, divisé en deux points
(1) Performance
Lorsque vous rencontrez du SQL qui nécessite un temps d'exécution long et que les résultats ne changent pas fréquemment, nous vous recommandons de stocker les résultats dans le cache. De cette manière, les requêtes ultérieures seront lues à partir du cache, afin de pouvoir répondre rapidement aux requêtes.
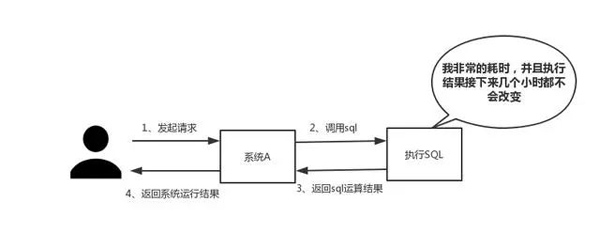
Hors sujet : J'ai soudain envie de parler de cette norme de réponse rapide. En fait, en fonction de l’effet d’interaction, il n’existe pas de norme fixe pour ce temps de réponse. Mais quelqu'un m'a dit un jour : « Dans un monde idéal, nos sauts de page doivent être résolus en un instant, et les opérations sur la page doivent être résolues en un instant. Afin d'offrir la meilleure expérience utilisateur, les opérations qui prennent plus de une seconde doit être fournie. Des invites de progression et permettent une suspension ou une annulation à tout moment. "
Alors, combien de temps cela prend-il en un instant, un instant ou un claquement de doigt ?
Selon les enregistrements "Maha Sangha Vinaya"
Un instant est une pensée, vingt pensées sont un instant, vingt instants sont un claquement de doigt et vingt claquements de doigts le doigt est un prélude Luo. , Vingt Luo est un instant, et un jour et une nuit sont trente instants.
Ainsi, après un calcul minutieux, un instant dure 0,36 seconde, un instant dure 0,018 seconde et un claquement de doigt dure 7,2 secondes.
(2) Concurrence
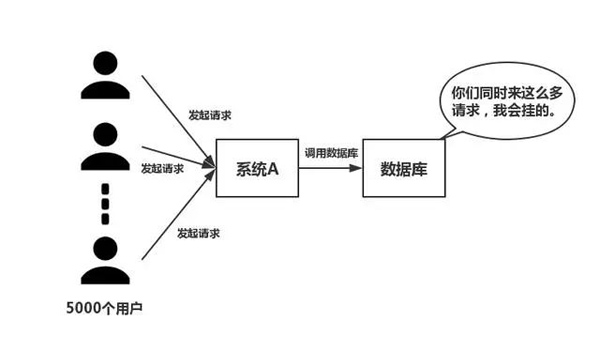
Comme le montre la figure ci-dessous, dans le cas d'une grande concurrence, toutes les requêtes accèdent directement à la base de données, et la base de données apparaîtra Anomalie de connexion. Dans ce cas, l'utilisation des opérations de mise en mémoire tampon Redis est nécessaire pour que la requête accède d'abord à Redis au lieu d'accéder directement à la base de données.
2. Quels sont les inconvénients de l'utilisation de Redis
Analyse : Tout le monde a été En utilisant Redis depuis si longtemps, ce problème doit être compris. Fondamentalement, vous rencontrerez certains problèmes lors de l'utilisation de Redis, et il n'y en a que quelques-uns courants.
Réponse : Principalement quatre questions
(1) Problèmes de cohérence en double écriture du cache et de la base de données
#🎜 🎜#(2) Problème d'avalanche de cache
(3) Problème de panne de cache
( 4) Cache problème de concurrence concurrente
Je pense personnellement que ces quatre problèmes sont relativement courants dans les projets. Les solutions spécifiques sont données plus tard. Vous pouvez vous référer à : « Avalanche de cache, pénétration du cache, préchauffage du cache, mise à jour du cache, dégradation du cache et autres problèmes ! 》3. Pourquoi Redis monothread est-il si rapide
Analyse : Cette question est en fait une enquête sur le mécanisme interne de Redis ? . D'après l'expérience d'entretien du blogueur, de nombreuses personnes ne comprennent pas le modèle de travail monothread de Redis. Cette question mérite donc encore d’être réexaminée.Réponse : Principalement les trois points suivants
(1) Opération de mémoire pure (2) Fil unique fonctionnement, en évitant les changements de contexte fréquents (3) Utiliser un mécanisme de multiplexage d'E/S non bloquant Digression : Parlons-en en détail maintenant Mécanisme de multiplexage d'E/S, parce que ce terme est si populaire que la plupart des gens ne comprennent pas ce qu'il signifie. Le blogueur a donné une analogie : Xiaoqu a ouvert un magasin express dans la ville S, responsable des services de livraison express dans la ville. En raison de fonds limités, Xiaoqu a d'abord embauché un groupe de coursiers, mais a découvert plus tard que les fonds étaient insuffisants et qu'il ne pouvait acheter qu'une voiture pour une livraison express.Méthode commerciale 1
Chaque fois qu'un client livre un coursier, Xiaoqu désignera un coursier pour le surveiller, puis le coursier Will Le coursier conduit la voiture pour livrer le colis. Lentement, Xiaoqu a découvert les problèmes suivants avec cette méthode commerciale- Des dizaines de coursiers ont essentiellement passé leur temps à voler des voitures, la plupart d'entre eux Les coursiers sont tous inactifs. livrer le coursier
- Avec l'augmentation de la livraison express, il y a de plus en plus de coursiers, Xiaoqu j'ai trouvé que le magasin de livraison express est de plus en plus encombré et il y a aucun moyen d'embaucher de nouveaux coursiers
- La coordination entre les coursiers prend du temps
Méthode commerciale deux
小quonly Embaucher un coursier. Xiaoqu marquera la livraison express envoyée par le client en fonction du lieu de livraison et la placera au même endroit. En fin de compte, le coursier récupérait les colis un par un, puis conduisait pour livrer le colis, puis revenait chercher le colis suivant après la livraison.Comparaison
En comparant les deux méthodes commerciales ci-dessus, pensez-vous que la seconde est plus efficace et meilleure ? Dans la métaphore ci-dessus :- Chaque coursier ------------------> 🎜🎜# Chaque livraison express-------------------->Chaque prise (flux E/S)#🎜 🎜##🎜 🎜#
- Lieu de livraison express--------------> Différents statuts de prise
Demande de livraison client-------------->Demande du client
- #🎜 🎜# Méthode commerciale de Xiaoqu-------------->Code exécuté sur le serveur
- Une voiture---- ---- ---------->Numéro de cœur du processeur
# 🎜🎜#1 . La première méthode commerciale est le modèle de concurrence traditionnel. Chaque flux d'E/S (express) est géré par un nouveau thread (courier).
2. La deuxième méthode de gestion est le multiplexage des E/S. Il n'existe qu'un seul thread (un coursier) qui gère plusieurs flux d'E/S en suivant l'état de chaque flux d'E/S (l'emplacement de livraison de chaque coursier).
Ce qui suit est une analogie avec le véritable modèle de thread Redis, comme le montre l'image
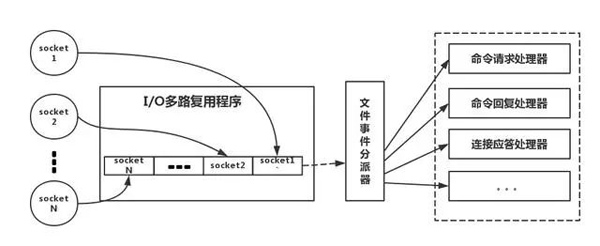 Reportez-vous à l'image ci-dessus , pour faire simple, c'est . Pendant le fonctionnement, notre client Redis créera des sockets avec différents types d'événements. Côté serveur, il existe un programme de multiplexage E/0 qui le met dans une file d'attente. Ensuite, le répartiteur d'événements de fichier le extrait tour à tour de la file d'attente et le transmet à différents processeurs d'événements.
Reportez-vous à l'image ci-dessus , pour faire simple, c'est . Pendant le fonctionnement, notre client Redis créera des sockets avec différents types d'événements. Côté serveur, il existe un programme de multiplexage E/0 qui le met dans une file d'attente. Ensuite, le répartiteur d'événements de fichier le extrait tour à tour de la file d'attente et le transmet à différents processeurs d'événements.
Il est à noter que pour ce mécanisme de multiplexage d'E/S, redis fournit également des bibliothèques de fonctions de multiplexage telles que select, epoll, evport, kqueue, etc. Vous pouvez vous renseigner par vous-même.
4. Types de données Redis et scénarios d'utilisation de chaque type de donnéesAnalyse : Pensez-vous que cette question est très basique ? , je le pense aussi. Cependant, d'après l'expérience des entretiens, au moins 80 % des personnes ne peuvent pas répondre à cette question. Il est recommandé qu'après l'avoir utilisé dans le projet, vous puissiez le mémoriser par analogie pour acquérir une expérience plus profonde au lieu de le mémoriser par cœur. Fondamentalement, un programmeur qualifié utilisera les cinq types.
Réponse : Il existe cinq types au total
(1) StringC'est en fait très courant et implique les opérations Get/set les plus élémentaires, la valeur peut être une chaîne ou un nombre. Généralement, certaines fonctions de comptage complexes sont mises en cache.
(2)hashLa valeur ici stocke des objets structurés, et il est plus pratique d'utiliser l'un des champs. Lorsque les blogueurs effectuent une authentification unique, ils utilisent cette structure de données pour stocker les informations utilisateur, utilisent cookieId comme clé et définissent 30 minutes comme délai d'expiration du cache, ce qui peut très bien simuler un effet de session.
(3)listEn utilisant la structure de données de List, vous pouvez exécuter des fonctions simples de file d'attente de messages. De plus, nous pouvons également utiliser la commande lrange pour implémenter la fonction de pagination basée sur Redis. Cette méthode offre d'excellentes performances et une excellente expérience utilisateur.
(4)setParce que l'ensemble est une collection de valeurs uniques. Par conséquent, la fonction de déduplication globale peut être mise en œuvre. Pourquoi ne pas utiliser le Set fourni avec la JVM pour la déduplication ? Étant donné que nos systèmes sont généralement déployés en clusters, il est difficile d'utiliser le Set fourni avec la JVM. Est-il trop compliqué de mettre en place un service public uniquement pour effectuer une déduplication globale ?
De plus, en utilisant des opérations telles que l'intersection, l'union et la différence, vous pouvez calculer les préférences communes, toutes les préférences, vos propres préférences uniques et d'autres fonctions.
(5) ensemble triél'ensemble trié a un score de paramètre de poids supplémentaire, et les éléments de l'ensemble peuvent être disposés en fonction du score . Vous pouvez créer une demande de classement et effectuer des opérations TOP N. De plus, dans un article intitulé « Analyse des schémas de tâches distribuées retardées », il est mentionné qu'un ensemble trié peut être utilisé pour implémenter des tâches retardées. La dernière application consiste à effectuer des recherches par plage.
5. Stratégie d'expiration de Redis et mécanisme d'élimination de la mémoireL'importance de ce problème va de soi, que vous utilisiez Redis ou non. . Par exemple, si vous ne pouvez stocker que 5 Go de données dans Redis, mais que vous écrivez 10 Go de données, 5 Go de données seront supprimés. Comment l'avez-vous supprimé ? Avez-vous réfléchi à ce problème ? De plus, vos données ont défini un délai d'expiration, mais une fois le délai écoulé, l'utilisation de la mémoire est encore relativement élevée. Avez-vous réfléchi à la raison ? redis adopté C'est une stratégie de suppression régulière + suppression paresseuse.
Pourquoi ne pas utiliser une stratégie de suppression planifiéeSuppression planifiée, utilisez une minuterie pour surveiller la clé et supprimez-la automatiquement lorsqu'elle expire ? . Bien que la mémoire soit libérée avec le temps, elle consomme beaucoup de ressources CPU. Étant donné qu'en cas de requêtes simultanées élevées, le CPU doit se concentrer sur le traitement des requêtes plutôt que sur les opérations de suppression de clé-valeur, nous avons renoncé à adopter cette stratégie
Comment fonctionnent la suppression régulière + la suppression paresseuse ?
Supprimer régulièrement. Par défaut, Redis vérifie toutes les 100 ms s'il y a des clés expirées, supprimez-les. Il convient de noter que Redis ne vérifie pas toutes les clés toutes les 100 ms, mais les sélectionne au hasard pour inspection (si toutes les clés sont vérifiées toutes les 100 ms, Redis ne serait-il pas bloqué) ? Si vous utilisez uniquement une stratégie de suppression périodique, de nombreuses clés ne seront pas supprimées après le délai d'expiration.
Donc, la suppression paresseuse est pratique. C'est-à-dire que lorsque vous obtenez une clé, Redis vérifiera si la clé a expiré si un délai d'expiration est défini ? S'il expire, il sera supprimé à ce moment-là. N'y a-t-il pas d'autres problèmes si on adopte la suppression régulière + la suppression paresseuse
?Non, si la clé n'est pas supprimée lors de la suppression régulière. Ensuite, vous n'avez pas demandé la clé immédiatement, ce qui signifie que la suppression différée n'a pas pris effet. De cette façon, la mémoire de Redis deviendra de plus en plus élevée. Ensuite, le mécanisme d'élimination de la mémoire doit être adopté.
Il y a une ligne de configuration dans redis.conf
# maxmemory-policy volatile-lru
Cette configuration est configurée avec la stratégie d'élimination de mémoire (quoi, vous ne l'avez pas configuré ? Réfléchissez à vous-même)
1) noeviction : quand la mémoire Lorsqu'il n'y a pas assez d'espace pour accueillir les données nouvellement écrites, la nouvelle opération d'écriture signalera une erreur. Personne ne devrait l'utiliser.
Lorsque l'espace mémoire est insuffisant pour stocker de nouvelles données, l'algorithme allkeys-lru supprimera la clé la moins récemment utilisée de l'espace clé. Recommandé, actuellement utilisé dans les projets.
3) allkeys-random : lorsque la mémoire n'est pas suffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé. Personne ne devrait l'utiliser. Si vous ne souhaitez pas le supprimer, utilisez au moins la clé et supprimez-la au hasard.
4) volatile-lru : lorsque la mémoire n'est pas suffisante pour accueillir les données nouvellement écrites, dans l'espace clé avec un délai d'expiration défini, supprimez la clé la moins récemment utilisée. Généralement, cette méthode n'est utilisée que lorsque Redis est utilisé à la fois comme cache et comme stockage persistant. Non recommandé
5) volatile-aléatoire : lorsque la mémoire est insuffisante pour accueillir les données nouvellement écrites, une clé est supprimée de manière aléatoire de l'espace clé avec un délai d'expiration défini. Toujours pas recommandé
6) volatile-ttl : lorsque la mémoire n'est pas suffisante pour accueillir les données nouvellement écrites, dans l'espace clé avec un délai d'expiration défini, les clés avec un délai d'expiration antérieur seront supprimées en premier. Non recommandé
ps : Si la clé d'expiration n'est pas définie et que les conditions préalables ne sont pas remplies ; alors le comportement des stratégies volatile-lru, volatile-random et volatile-ttl est fondamentalement le même que celui de la noeviction (pas de suppression).
6. Problèmes de cohérence avec Redis et la double écriture de la base de données
Dans les systèmes distribués, les problèmes de cohérence sont des problèmes courants. Ce problème peut être davantage distingué en cohérence éventuelle et cohérence forte. Si la base de données et le cache sont écrits en double, il y aura inévitablement des incohérences. Pour répondre à cette question, comprenez d’abord une prémisse. Autrement dit, s’il existe des exigences strictes de cohérence pour les données, elles ne peuvent pas être mises en cache. Tout ce que nous faisons ne peut que garantir une cohérence à terme. La solution que nous proposons ne peut en réalité que réduire la probabilité d’événements incohérents, mais ne peut pas les éliminer complètement. Par conséquent, les données présentant de fortes exigences de cohérence ne peuvent pas être mises en cache.
Voici une brève introduction à l'analyse détaillée dans l'article "Analyse du schéma de cohérence des bases de données distribuées et du cache en double écriture". Tout d’abord, adoptez une stratégie de mise à jour correcte, mettez d’abord à jour la base de données, puis supprimez le cache. Fournissez une mesure de sauvegarde, telle que l'utilisation d'une file d'attente de messages, en cas d'échec de la suppression du cache.
7. Comment gérer les problèmes de pénétration du cache et d'avalanche de cache
Les petites et moyennes entreprises de logiciels traditionnelles rencontrent rarement ces deux problèmes, pour être honnête. S’il existe de grands projets simultanés, le trafic atteindra environ des millions. Ces deux questions doivent être considérées en profondeur.
Réponse : comme indiqué ci-dessous
Pénétration du cache, c'est-à-dire que le pirate informatique demande délibérément des données qui n'existent pas dans le cache, provoquant l'envoi de toutes les demandes à la base de données, ce qui rend la connexion à la base de données anormale.
Solution :
Lorsque le cache échoue, utilisez un verrou mutex, acquérez d'abord le verrou, puis demandez la base de données une fois le verrou acquis. Si le verrou n'est pas obtenu, il dormira pendant un certain temps et réessayera
(2) Adoptez une stratégie de mise à jour asynchrone et reviendra directement, que la clé ait ou non une valeur. Enregistrez un délai d'expiration du cache dans la valeur value. Une fois le cache expiré, un thread sera démarré de manière asynchrone pour lire la base de données et mettre à jour le cache. Une opération de préchauffage du cache (chargement du cache avant de démarrer le projet) est requise.
Fournir un mécanisme d'interception permettant de déterminer rapidement si la demande est valide. Par exemple, utilisez les filtres Bloom pour gérer en interne une série de clés légales et valides. Déterminez rapidement si la clé transportée dans la demande est légale et valide. Si c'est illégal, revenez directement.
Avalanche de cache, c'est-à-dire que le cache échoue dans une grande zone en même temps, à ce moment-là, une autre vague de requêtes arrive et, par conséquent, les requêtes sont toutes envoyées à la base de données, provoquant l'établissement de la connexion à la base de données. anormal.
Solution :
(1) Ajoutez une valeur aléatoire au délai d'expiration du cache pour éviter un échec collectif.
(2) Utilisez un verrou mutex, mais le débit de cette solution diminue considérablement.
(3) Double cache. Nous avons deux caches, le cache A et le cache B. Le délai d'expiration du cache A est de 20 minutes et il n'y a pas de délai d'expiration pour le cache B. Effectuez vous-même l’opération de préchauffage du cache. Décomposez ensuite les points suivants
Je lis la base de données à partir du cache A, et je reviens directement s'il y en a
II A n'a pas de données, je lis les données directement depuis B, je reviens directement et je démarre un fil de mise à jour de manière asynchrone .
III Le fil de mise à jour met à jour le cache A et le cache B en même temps.
8. Comment résoudre le problème de la concurrence des clés simultanées dans Redis
Analyse : ce problème est en gros qu'il existe plusieurs sous-systèmes définissant une clé en même temps. À quoi devons-nous faire attention à ce moment-là ? Y avez-vous déjà pensé ? Après avoir vérifié au préalable les résultats de la recherche Baidu, le blogueur a constaté que presque toutes les réponses recommandaient d'utiliser le mécanisme de transaction Redis. Le blogueur ne recommande pas d'utiliser le mécanisme de transaction Redis. Étant donné que notre environnement de production est essentiellement un environnement de cluster Redis, des opérations de partitionnement de données sont effectuées. Lorsqu'une même tâche implique plusieurs opérations de clé, ces clés ne sont pas nécessairement stockées sur le même serveur Redis. Par conséquent, le mécanisme de transaction de Redis est très inutile.
Réponse : comme indiqué ci-dessous
(1) Si vous actionnez cette clé, la commande n'est pas requise
Dans ce cas, préparez une serrure distribuée, tout le monde saisira la serrure et effectuera simplement l'opération définie après avoir saisi la serrure, relativement simple.
(2) Si vous utilisez cette clé, la commande est requise
Supposons qu'il y ait une clé1, le système A doit définir la clé1 sur la valeurA, le système B doit définir la clé1 sur la valeurB, le système C doit définir la clé1 sur la valeurC.
Attente Selon la valeur de key1, elle change dans l'ordre valeurA-->valeurB-->valeurC. À l’heure actuelle, nous devons enregistrer un horodatage lors de l’écriture des données dans la base de données. Supposons que l'horodatage soit le suivant
Clé système A 1 {valeurA 3:00}
Clé système B 1 {valeurB 3:05}
Clé système C 1 {valeurC 3:10}
Imaginez si le système B obtient Lors du premier verrouillage, il définira la valeur de key1 sur {valueB 3:05}. Lorsque le système A acquiert le verrou, s'il constate que l'horodatage de la valeur A qu'il stocke est antérieur à l'horodatage stocké dans le cache, le système A n'effectuera pas l'opération définie. Et ainsi de suite.
D'autres méthodes, telles que l'utilisation d'une file d'attente et la transformation de la méthode définie en accès série, peuvent également être utilisées. Bref, soyez flexible.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
