
 base de données
tutoriel mysql
Quel est le mécanisme d'implémentation interne du verrouillage Mysql ?
base de données
tutoriel mysql
Quel est le mécanisme d'implémentation interne du verrouillage Mysql ?
Quel est le mécanisme d'implémentation interne du verrouillage Mysql ?

Vue d'ensemble
Bien que les bases de données relationnelles modernes soient de plus en plus similaires, elles peuvent avoir des mécanismes complètement différents derrière leur mise en œuvre. En termes d'utilisation réelle, en raison de l'existence de spécifications de syntaxe SQL, il n'est pas difficile pour nous de nous familiariser avec plusieurs bases de données relationnelles, mais il peut y avoir autant de méthodes d'implémentation de verrous qu'il y a de bases de données.
Microsoft Sql Server ne fournissait les verrous de page qu'avant 2005. Ce n'est que dans la version 2005 qu'il a commencé à prendre en charge la concurrence optimiste et la concurrence pessimiste sont autorisées en mode optimiste. ressource rare. Plus il y a de verrous, plus il y a de verrous, plus la surcharge est importante. Afin d'éviter une chute des performances due à l'augmentation rapide du nombre de verrous, il prend en charge un mécanisme appelé mise à niveau des verrous. Une fois le verrouillage de ligne mis à niveau vers un verrouillage de page, les performances de concurrence reviendront à leur point d'origine.
En fait, il existe encore de nombreux différends sur l'interprétation des fonctions de verrouillage par différents moteurs d'exécution dans une même base de données. MyISAM ne prend en charge que le verrouillage au niveau des tables, ce qui convient à la lecture simultanée, mais présente certaines limitations en matière de modification simultanée. Innodb est très similaire à Oracle, offrant une prise en charge de la lecture cohérente et du verrouillage de ligne sans verrouillage. La différence évidente avec Sql Server est qu'à mesure que le nombre total de verrous augmente, Innodb n'a qu'à payer un petit prix.
Structure de verrouillage de ligne
Innodb prend en charge les verrous de ligne, et il n'y a pas de surcharge particulièrement importante dans la description des verrous. Par conséquent, il n'est pas nécessaire d'avoir recours à un mécanisme de mise à niveau des verrous comme mesure de secours après qu'un grand nombre de verrous provoque une dégradation des performances.
Extraite du fichier lock0priv.h, la définition des verrous de ligne par Innodb est la suivante :
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};Bien que le contrôle de concurrence puisse être affiné au niveau des lignes, la gestion des verrous est organisée en unités de pages. Dans la conception d'Innodb, la seule page de données peut être déterminée via les deux conditions nécessaires : l'identifiant d'espace et le numéro de page n_bits indiquent le nombre de bits nécessaires pour décrire les informations de verrouillage de ligne de la page.
Chaque enregistrement dans la même page de données se voit attribuer un numéro de séquence unique croissant : heap_no Si vous voulez savoir si une certaine ligne d'enregistrements est verrouillée, il vous suffit de déterminer si le numéro dans la position heap_no du bitmap est. un. Étant donné que le bitmap de verrouillage alloue de l'espace mémoire en fonction du nombre d'enregistrements dans la page de données, il n'est pas explicitement défini et les enregistrements de page peuvent continuer à augmenter, donc un espace de taille LOCK_PAGE_BITMAP_MARGIN est réservé.
/** * Safety margin when creating a new record lock: this many extra records * can be inserted to the page without need to create a lock with * a bigger bitmap */ #define LOCK_PAGE_BITMAP_MARGIN 64
Supposons que la page de données avec l'identifiant d'espace = 20, le numéro de page = 100 contient actuellement 160 enregistrements et que les enregistrements avec heap_no de 2, 3 et 4 ont été verrouillés, alors la structure lock_rec_t et la page de données correspondantes doivent être décrites comme ceci :
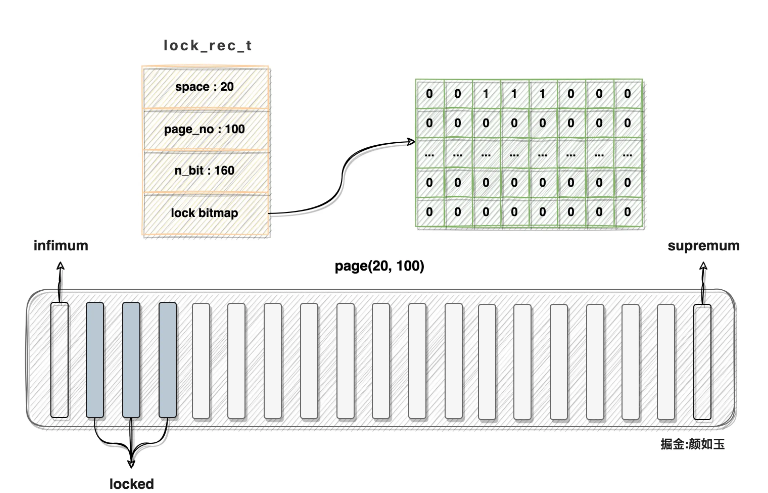
Remarque :
Le bitmap de verrouillage dans la mémoire doit être distribué linéairement. La structure bidimensionnelle montrée dans l'image est pour faciliter la description
La structure bitmap et lock_rec_t sont une structure continue. mémoire, et la relation de référence dans l'image est aussi un dessin Besoin
Vous pouvez voir que les deuxième, troisième et quatrième positions du bitmap correspondant à la page sont toutes mises à 1. La mémoire consommée en décrivant une page de données Le verrouillage des rangées est assez limité du point de vue de la perception. Quelle place occupe-t-il spécifiquement ? On peut calculer :
160 / 8 + 8 + 1 = 29octets.
160 enregistrements correspondent à 160 bits
+8 car 64 bits doivent être réservés
+1 car 1 octet est réservé dans le code source
pour éviter que la valeur du résultat ne soit trop petite Question, +1 supplémentaire ajouté ici. Cela peut éviter les erreurs causées par la division entière. S'il y a 161 enregistrements, sinon +1, les 20 octets calculés ne suffisent pas pour décrire les informations de verrouillage de tous les enregistrements (sans utiliser de bits réservés).
Extrait du fichier lock0priv.h :
/* lock_rec_create函数代码片段 */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* 注意这里是分配的连续内存 */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}Structure de verrouillage de table
Innodb prend également en charge les verrous de table. Les verrous de table peuvent être divisés en deux catégories : les verrous d'intention et les verrous à incrémentation automatique. La structure des données est définie comme suit :
Extrait du fichier lock0priv.h
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};Extrait du fichier ut0lst.h
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>Description des verrous dans les transactions
Les structures lock_rec_t et lock_table_t ci-dessus ne sont que des définitions distinctes. Les verrous sont générés dans les transactions, donc chaque transaction aura. un verrou de ligne et un verrou de table correspondants. La structure du verrou est définie comme suit :
Extrait du fichier lock0priv.h
/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};lock_t est défini en fonction de chaque page (ou table) de chaque transaction, mais une transaction implique souvent plusieurs pages. , donc une liste chaînée trx_locks est nécessaire. Concatène toutes les informations de verrouillage liées à une transaction. En plus d'interroger toutes les informations de verrouillage en fonction des transactions, le scénario réel nécessite également que le système soit capable de détecter rapidement et efficacement si un enregistrement de ligne a été verrouillé. Par conséquent, il doit exister une variable globale pour prendre en charge l’interrogation des informations de verrouillage pour les enregistrements de ligne. Innodb a choisi la table de hachage, qui est définie comme suit :
Extrait du fichier lock0lock.h
/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* 就是这里: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};La fonction lock_sys_create est chargée d'initialiser la structure lock_sys_t au démarrage de la base de données. La variable srv_lock_table_size détermine la taille du nombre d'emplacements de hachage dans rec_hash. La valeur clé de la table de hachage rec_hash est calculée en utilisant l'identifiant d'espace et le numéro de page de la page.
Extrait des fichiers lock0lock.ic, ut0rnd.ic
/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}Cela signifiera qu'il n'y a aucun moyen de nous permettre de savoir directement si une certaine ligne est verrouillée. Au lieu de cela, vous devez d'abord obtenir l'identifiant de l'espace et le numéro de page via la page où il se trouve, obtenir la valeur de la clé via la fonction lock_rec_fold, puis obtenir lock_rec_t via une requête de hachage, puis analyser le bitmap selon heap_no pour enfin déterminer le verrouiller les informations. La fonction lock_rec_get_first implémente la logique ci-dessus :
这里返回的其实是lock_t对象,摘自lock0lock.cc文件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}以页面为粒度进行锁维护并非最直接有效的方式,它明显是时间换空间,不过这种设计使得锁开销很小。某一事务对任一行上锁的开销都是一样的,锁数量的上升也不会带来额外的内存消耗。
对应每个事务的内存对象trx_t中,包含了该事务的锁信息链表和等待的锁信息。因此存在如下两种途径对锁进行查询:
根据事务: 通过trx_t对象的trx_locks链表,再通过lock_t对象中的trx_locks遍历可得某事务持有、等待的所有锁信息。
根据记录: 根据记录所在的页,通过space id、page number在lock_sys_t结构中定位到lock_t对象,扫描bitmap找到heap_no对应的bit位。
上述各种数据结构,对其整理关系如下图所示:
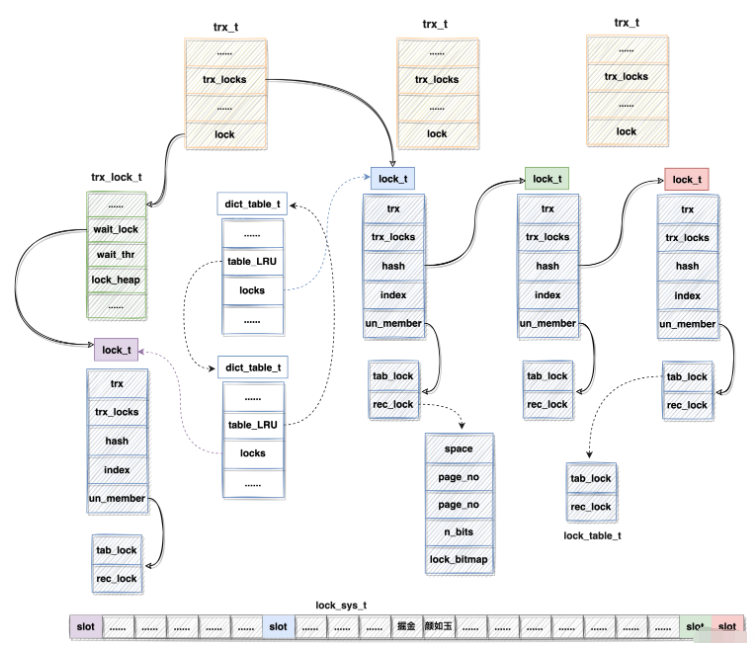
注:
lock_sys_t中的slot颜色与lock_t颜色相同则表明lock_sys_t slot持有lock_t 指针信息,实在是没法连线,不然图很混乱
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
