
 Périphériques technologiques
IA
En identifiant la « fraude ChatGPT », l'effet surpasse OpenAI : l'Université de Pékin et les détecteurs générés par l'IA de Huawei sont ici
Périphériques technologiques
IA
En identifiant la « fraude ChatGPT », l'effet surpasse OpenAI : l'Université de Pékin et les détecteurs générés par l'IA de Huawei sont ici
En identifiant la « fraude ChatGPT », l'effet surpasse OpenAI : l'Université de Pékin et les détecteurs générés par l'IA de Huawei sont ici

Avec l’avancée continue des grands modèles génératifs, le corpus qu’ils génèrent se rapproche progressivement de celui des humains. Bien que les grands modèles libèrent les mains d'innombrables employés, leur puissante capacité à simuler de fausses mains a également été utilisée par certains criminels, provoquant une série de problèmes sociaux :


Adresse papier : https://arxiv.org/abs/2305.18149
Adresse code (MindSpore) : https://github.com/mindspore-lab/mindone/tree/master/ examples/detect_chatgpt
- Adresse de code (PyTorch) : https://github.com/YuchuanTian/AIGC_text_detector
- IntroductionComme l'effet de génération de grands modèles de langage devient de plus en plus plus réaliste, diverses industries ont besoin de toute urgence d'un détecteur de texte fiable généré par l'IA. Cependant, différents secteurs ont des exigences différentes en matière de corpus de détection. Par exemple, dans le monde universitaire, il est généralement nécessaire de détecter des textes académiques volumineux et complets ; sur les plateformes sociales, les fausses nouvelles relativement courtes et fragmentées doivent être détectées. Cependant, les détecteurs existants ne peuvent souvent pas répondre à divers besoins. Par exemple, certains détecteurs de texte IA traditionnels ont généralement de faibles capacités de prédiction pour des corpus plus courts. Concernant les différents effets de détection de corpus de différentes longueurs, l'auteur a observé qu'il peut y avoir une certaine « incertitude » dans l'attribution de textes plus courts générés par l'IA ou, pour le dire plus crûment, à cause de certaines phrases courtes générées par l'IA ; souvent également utilisé par les humains, il est difficile de déterminer si le texte court généré par l’IA provient d’humains ou d’IA. Voici plusieurs exemples de personnes et d'IA répondant respectivement à la même question :
On voit à partir de ces exemples qu'il est difficile d'identifier les réponses courtes générées par l'IA : ce type de corpus est trop différent de celle des gens, il est difficile de juger strictement ses véritables propriétés. Par conséquent, il est inapproprié d’annoter simplement des textes courts comme étant humains/IA et d’effectuer une détection de texte selon les problèmes de classification binaire traditionnels.
En réponse à ce problème, cette étude transforme la partie détection de la classification binaire humain/IA en un problème d'apprentissage partiel PU (Positive-Unlabeled), c'est-à-dire que dans des phrases plus courtes, le langage humain est positif, le langage machine est Sans étiquette, ce qui améliore la fonction de perte d'entraînement. Cette amélioration améliore significativement les performances de classification du détecteur sur différents corpus.
 Détails de l'algorithme
Détails de l'algorithme
Dans le cadre d'apprentissage PU traditionnel, un modèle de classification binaire ne peut apprendre que sur la base d'échantillons d'entraînement positifs et d'échantillons d'entraînement non étiquetés. Une méthode d'apprentissage PU couramment utilisée consiste à estimer la perte de classification binaire correspondant aux échantillons négatifs en formulant la perte PU :
Parmi eux, Plus précisément, cette étude propose un modèle récurrent abstrait pour modéliser la détection de textes plus courts. Lorsque la PNL traditionnelle modélise des séquences de processus, elles ont généralement une structure de chaîne de Markov, telle que RNN, LSTM, etc. Le processus de ce type de modèle cyclique peut généralement être compris comme un processus progressivement itératif, c'est-à-dire que la prédiction de chaque sortie de jeton est obtenue en transformant et en fusionnant les résultats de prédiction du jeton précédent et de la séquence précédente avec les résultats de prédiction de cette séquence. jeton. C'est-à-dire le processus suivant : Afin d'estimer la probabilité a priori sur la base de ce modèle abstrait, il est nécessaire de supposer que le résultat du modèle est la confiance qu'une certaine phrase est positive, c'est-à-dire , il est jugé prononcé par une personne avec une probabilité d'échantillonnage. On suppose que la taille de la contribution de chaque jeton est l'inverse de la longueur du jeton de phrase, qu'elle est positive, c'est-à-dire sans étiquette, et que la probabilité d'être sans étiquette est bien supérieure à la probabilité d'être positive. Car à mesure que le vocabulaire des grands modèles se rapproche progressivement de celui des humains, la plupart des mots apparaîtront aussi bien dans l’IA que dans les corpus humains. Sur la base de ce modèle simplifié et de la probabilité de jeton positive définie, l'estimation préalable finale est obtenue en trouvant l'espérance totale de la confiance de sortie du modèle dans différentes conditions d'entrée. 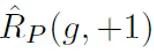 représente la perte de classification binaire calculée par les échantillons positifs et les étiquettes positives ;
représente la perte de classification binaire calculée par les échantillons positifs et les étiquettes positives ; 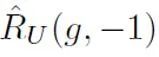 représente la perte de classification binaire calculée en supposant que tous les échantillons non étiquetés sont des étiquettes négatives ;
représente la perte de classification binaire calculée en supposant que tous les échantillons non étiquetés sont des étiquettes négatives ; 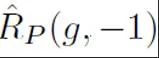 représente la perte de classification binaire calculée par ; en supposant que les échantillons positifs sont des étiquettes négatives. La perte de classification binaire
représente la perte de classification binaire calculée par ; en supposant que les échantillons positifs sont des étiquettes négatives. La perte de classification binaire 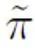 représente la probabilité d'échantillon positif antérieur, c'est-à-dire la proportion estimée d'échantillons positifs dans tous les échantillons PU ; Dans l'apprentissage PU traditionnel, le prior est généralement défini sur un hyperparamètre fixe. Cependant, dans le scénario de détection de texte, le détecteur doit traiter divers textes de longueurs différentes ; et pour les textes de longueurs différentes, la proportion estimée d'échantillons positifs parmi tous les échantillons PU de même longueur que l'échantillon est également différente. Par conséquent, cette étude améliore la perte de PU et propose une fonction de perte de PU multi-échelle (MPU) sensible à la longueur.
représente la probabilité d'échantillon positif antérieur, c'est-à-dire la proportion estimée d'échantillons positifs dans tous les échantillons PU ; Dans l'apprentissage PU traditionnel, le prior est généralement défini sur un hyperparamètre fixe. Cependant, dans le scénario de détection de texte, le détecteur doit traiter divers textes de longueurs différentes ; et pour les textes de longueurs différentes, la proportion estimée d'échantillons positifs parmi tous les échantillons PU de même longueur que l'échantillon est également différente. Par conséquent, cette étude améliore la perte de PU et propose une fonction de perte de PU multi-échelle (MPU) sensible à la longueur. 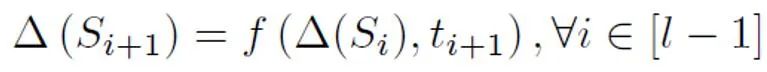
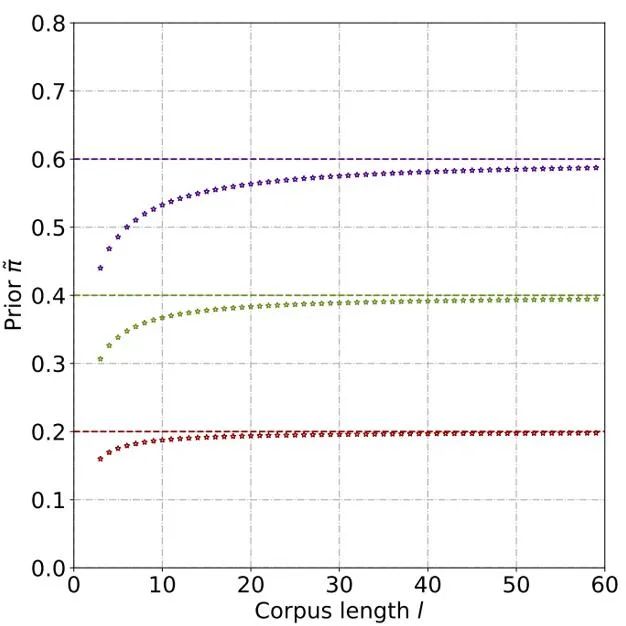
Grâce à des dérivations théoriques et à des expériences, on estime que la probabilité a priori augmente à mesure que la longueur du texte augmente, et finit par se stabiliser. Ce phénomène est également conforme aux attentes, car à mesure que le texte s'allonge, le détecteur peut capturer plus d'informations, et « l'incertitude source » du texte s'affaiblit progressivement :
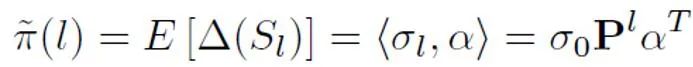
Après cela, pour chaque positif Pour un échantillon, la perte PU est calculée sur la base d'un a priori unique dérivé de la longueur de son échantillon. Enfin, étant donné que les textes plus courts n'ont qu'une certaine « incertitude » (c'est-à-dire que les textes plus courts contiendront également des caractéristiques textuelles de certaines personnes ou de l'IA), la perte binaire et la perte MPU peuvent être pondérées et ajoutées comme objectif d'optimisation final :
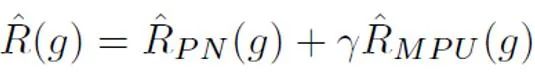
De plus, il convient de noter que la perte de MPU s'adapte à des corpus d'entraînement de différentes longueurs. Si les données de formation existantes sont évidemment homogènes et que la majeure partie du corpus est constituée de textes longs et volumineux, la méthode MPU ne peut pas exercer pleinement son efficacité. Afin de diversifier la durée du corpus de formation, cette étude introduit également un module multi-échelle au niveau de la phrase. Ce module couvre de manière aléatoire certaines phrases du corpus de formation et réorganise les phrases restantes tout en conservant l'ordre d'origine. Après une exploitation à plusieurs échelles du corpus de formation, le texte de formation a été considérablement enrichi en longueur, exploitant ainsi pleinement l'apprentissage PU pour la formation au détecteur de texte IA.
Résultats expérimentaux

Comme le montre le tableau ci-dessus, l'auteur a d'abord testé l'effet de la perte de MPU sur l'ensemble de données de corpus plus court généré par l'IA, Tweep-Fake. Le corpus de cet ensemble de données est constitué de segments relativement courts sur Twitter. L'auteur remplace également la perte traditionnelle à deux catégories par un objectif d'optimisation contenant la perte de MPU basé sur un réglage fin du modèle de langage traditionnel. Le détecteur de modèle de langage amélioré est plus efficace et surpasse les autres algorithmes de base.
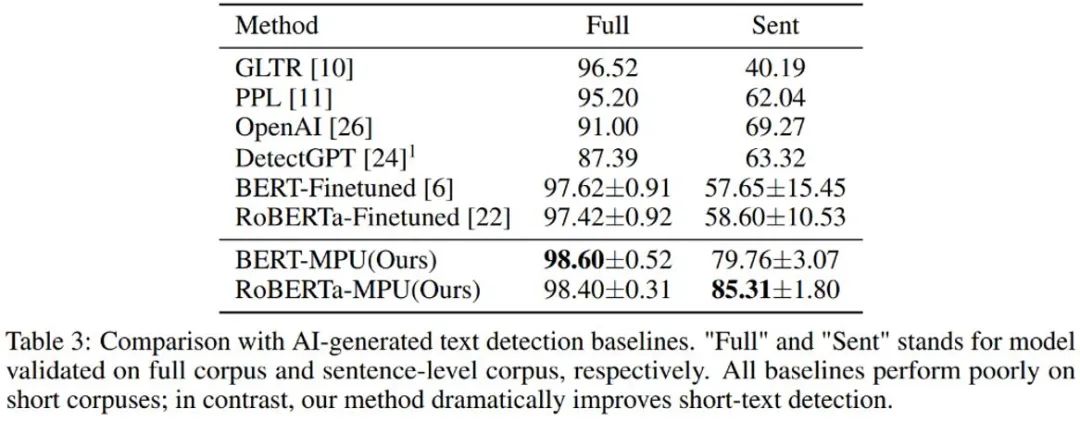
L'auteur a également testé le texte généré par chatGPT. Le détecteur de modèle de langage obtenu par un réglage fin traditionnel a donné de mauvais résultats sur les phrases courtes ; le détecteur formé dans les mêmes conditions via la méthode MPU a mieux fonctionné sur les phrases courtes ; Les performances des phrases sont bonnes et, en même temps, elles peuvent améliorer considérablement le corpus complet. Le score F1 est augmenté de 1 %, dépassant les algorithmes SOTA tels qu'OpenAI et DetectGPT.
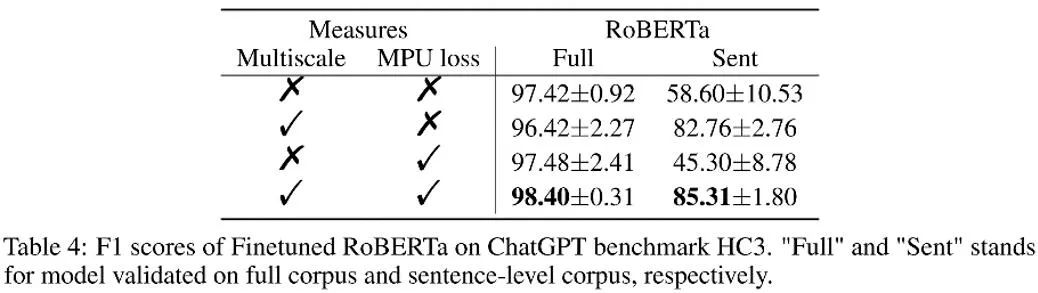
Comme le montre le tableau ci-dessus, l'auteur a observé le gain d'effet apporté par chaque partie de l'expérience d'ablation. La perte de MPU améliore l'effet de classification des matériaux longs et courts.

L'auteur a également comparé le PU traditionnel et le PU multi-échelle (MPU). Le tableau ci-dessus montre que l'effet MPU est meilleur et peut mieux s'adapter à la tâche de détection de texte multi-échelle de l'IA.
Résumé
L'auteur a résolu le problème de la reconnaissance de phrases courtes par détecteur de texte en proposant une solution basée sur l'apprentissage PU multi-échelle Avec la prolifération des modèles de génération AIGC dans le futur, la détection de ce type de contenu. deviendra de plus en plus populaire. Cette recherche a fait un grand pas en avant dans la question de la détection de texte par l'IA. On espère que d'autres recherches similaires seront menées à l'avenir pour mieux contrôler le contenu AIGC et empêcher l'abus du contenu généré par l'IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment faire fonctionner le réglage des performances de Zookeeper sur Debian
Apr 02, 2025 am 07:42 AM
Comment faire fonctionner le réglage des performances de Zookeeper sur Debian
Apr 02, 2025 am 07:42 AM
Cet article décrit comment optimiser les performances de Zookeeper sur Debian Systems. Nous fournirons des conseils sur le matériel, le système d'exploitation, la configuration du gardien de zoo et la surveillance. 1. Optimiser la mise à niveau des supports de stockage au niveau du système: le remplacement des disques durs mécaniques traditionnels par des disques à l'état solide SSD améliorera considérablement les performances des E / S et réduira la latence d'accès. Désactiver le partitionnement du swap: en ajustant les paramètres du noyau, réduisez la dépendance des partitions de swap et évitez les pertes de performances causées par des swaps de mémoire et de disque fréquents. Améliorer le descripteur de fichier Limite supérieure: augmenter le nombre de descripteurs de fichiers autorisés à être ouverts en même temps par le système pour éviter les limitations des ressources affectant l'efficacité de traitement de Zookeeper. 2. Configuration de la configuration zoo
 Comment faire des paramètres de sécurité Oracle sur Debian
Apr 02, 2025 am 07:48 AM
Comment faire des paramètres de sécurité Oracle sur Debian
Apr 02, 2025 am 07:48 AM
Pour renforcer la sécurité de la base de données Oracle sur le système Debian, il faut de nombreux aspects pour commencer. Les étapes suivantes fournissent un cadre pour la configuration sécurisée: 1. Installation de la base de données Oracle et préparation du système de configuration initiale: Assurez-vous que le système Debian a été mis à jour vers la dernière version, la configuration du réseau est correcte et tous les packages logiciels requis sont installés. Il est recommandé de se référer à des documents officiels ou à des ressources tierces fiables pour l'installation. Utilisateurs et groupes: Créez un groupe d'utilisateurs Oracle dédié (tel que Oinstall, DBA, BackupDBA) et définissez-le pour lui. 2. Restrictions de sécurité Définir les restrictions de ressources: Edit /etc/security/limits.d/30-oracle.conf
 Comment récupérer Debian Mail Server
Apr 02, 2025 am 07:33 AM
Comment récupérer Debian Mail Server
Apr 02, 2025 am 07:33 AM
Étapes détaillées pour restaurer Debian Mail Server Cet article vous guidera sur la façon de restaurer Debian Mail Server. Avant de commencer, il est important de se souvenir de l'importance de la sauvegarde des données. Étapes de récupération: données de sauvegarde: assurez-vous de sauvegarder toutes les données d'e-mail et fichiers de configuration importants avant d'effectuer des opérations de récupération. Cela garantira que vous avez une version de secours lorsque des problèmes se produisent pendant le processus de récupération. Vérifiez les fichiers journaux: vérifiez les fichiers journaux du serveur de messagerie (tels que /var/log/mail.log) pour des erreurs ou des exceptions. Les fichiers journaux fournissent souvent des indices précieux sur la cause du problème. Service d'arrêt: Arrêtez le service de messagerie pour éviter une nouvelle corruption des données. Utilisez la commande suivante: su
 Comment surveiller les performances du système via les journaux debian
Apr 02, 2025 am 08:00 AM
Comment surveiller les performances du système via les journaux debian
Apr 02, 2025 am 08:00 AM
La maîtrise de la surveillance du journal du système Debian est la clé d'un fonctionnement et d'une maintenance efficaces. Il peut vous aider à comprendre les conditions de fonctionnement du système en temps opportun, à localiser rapidement les défauts et à optimiser les performances du système. Cet article présentera plusieurs méthodes et outils de surveillance couramment utilisés. Surveillance des ressources système avec la boîte à outils Sysstat La boîte à outils Sysstat fournit une série d'outils de ligne de commande puissants pour collecter, analyser et signaler diverses mesures de ressources système, y compris la charge du processeur, l'utilisation de la mémoire, les E / S de disque, le débit de réseau, etc. MPSTAT: Statistiques des processeurs multi-fond. pidsta
 Comment dépanner Debian Syslog
Apr 02, 2025 am 09:00 AM
Comment dépanner Debian Syslog
Apr 02, 2025 am 09:00 AM
Syslog pour Debian Systems est un outil clé pour les administrateurs système afin de diagnostiquer les problèmes. Cet article fournit quelques étapes et commandes pour résoudre les problèmes de syslog communs: 1. Affichage du journal Affichage en temps réel du dernier journal: Tail-F / var / log / syslog Affichage des journaux du noyau (Démarrer les erreurs et problèmes de pilote): DMESG utilise JournalCTL (Debian8 et ci-dessus, SystemD System): JournalCTL-B (visualisation après le démarrage des journaux), journalcTL-F-F (visualisation de nouveaux logs dans le temps réel). 2. Processus de surveillance et de visualisation des ressources système et utilisation des ressources: PSAUX (Trouver un processus d'occupation des ressources élevé
 Quelle est la stratégie de rotation des journaux de Golang sur Debian
Apr 02, 2025 am 08:39 AM
Quelle est la stratégie de rotation des journaux de Golang sur Debian
Apr 02, 2025 am 08:39 AM
Dans Debian Systems, la rotation des journaux de GO repose généralement sur des bibliothèques tierces, plutôt que sur les fonctionnalités fournies avec des bibliothèques standard GO. Le bûcheron est une option couramment utilisée. Il peut être utilisé avec divers cadres journaux (tels que ZAP et Logrus) pour réaliser la rotation automatique et la compression des fichiers journaux. Voici un exemple de configuration à l'aide des bibliothèques Lumberjack et Zap: PackageMainImport ("gopkg.in/natefinch/lumberjack.v2" "go.uber.org/zap" "go.uber.org/zap/zapcor
 Pourquoi est-il nécessaire de passer des pointeurs lors de l'utilisation de bibliothèques Go et Viper?
Apr 02, 2025 pm 04:00 PM
Pourquoi est-il nécessaire de passer des pointeurs lors de l'utilisation de bibliothèques Go et Viper?
Apr 02, 2025 pm 04:00 PM
GO POINTER SYNTAXE ET ATTENDRE DES PROBLÈMES DANS LA BIBLIOTHÈQUE VIPER Lors de la programmation en langage Go, il est crucial de comprendre la syntaxe et l'utilisation des pointeurs, en particulier dans ...
 Comment rendre les données publiques disponibles pour tous les contrôleurs du framework Go Gin?
Apr 02, 2025 am 10:21 AM
Comment rendre les données publiques disponibles pour tous les contrôleurs du framework Go Gin?
Apr 02, 2025 am 10:21 AM
Comment faire en sorte que tous les contrôleurs obtiennent des données publiques dans le framework Gogin? Utilisation de Go ...
