

Comment utiliser JOIN dans MySql

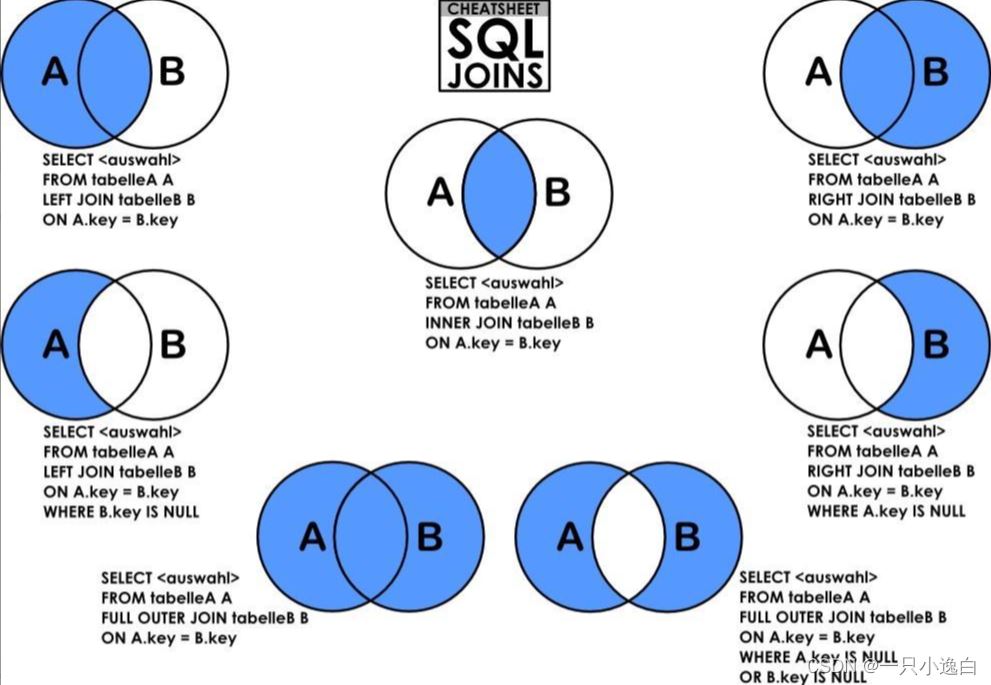
JOIN signifie tout comme le mot anglais "join". Il relie deux tables et peut être grossièrement divisé en jointure interne, jointure externe, jointure droite, jointure gauche et jointure naturelle.
Créez d'abord deux tables, les suivantes sont utilisées comme exemples
CREATE TABLE t_blog(
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(50),
typeId INT
);
SELECT * FROM t_blog;
+----+-------+--------+
| id | title | typeId |
+----+-------+--------+
| 1 | aaa | 1 |
| 2 | bbb | 2 |
| 3 | ccc | 3 |
| 4 | ddd | 4 |
| 5 | eee | 4 |
| 6 | fff | 3 |
| 7 | ggg | 2 |
| 8 | hhh | NULL |
| 9 | iii | NULL |
| 10 | jjj | NULL |
+----+-------+--------+
-- 博客的类别
CREATE TABLE t_type(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
SELECT * FROM t_type;
+----+------------+
| id | name |
+----+------------+
| 1 | C++ |
| 2 | C |
| 3 | Java |
| 4 | C# |
| 5 | Javascript |
+----+------------+Produit cartésien : CROSS JOIN
Pour comprendre les différentes JOIN, vous devez d'abord comprendre le produit cartésien. Le produit cartésien combine chaque enregistrement du tableau A avec chaque enregistrement du tableau B. Par conséquent, lorsqu'il y a n enregistrements dans la table A et m enregistrements dans la table B, le résultat de l'opération de produit cartésien sera n*m enregistrements. Dans l'exemple suivant, t_blog a 10 enregistrements, t_type a 5 enregistrements et le produit cartésien des deux a 50 enregistrements. Il existe cinq façons de produire un produit cartésien comme suit.
SELECT * FROM t_blog CROSS JOIN t_type;
SELECT * FROM t_blog INNER JOIN t_type;
SELECT * FROM t_blog,t_type;
SELECT * FROM t_blog NATURE JOIN t_type;
select * from t_blog NATURA join t_type;
+----+-------+--------+----+------------+
| id | title | typeId | id | name |
+----+-------+--------+----+------------+
| 1 | aaa | 1 | 1 | C++ |
| 1 | aaa | 1 | 2 | C |
| 1 | aaa | 1 | 3 | Java |
| 1 | aaa | 1 | 4 | C# |
| 1 | aaa | 1 | 5 | Javascript |
| 2 | bbb | 2 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 2 | bbb | 2 | 3 | Java |
| 2 | bbb | 2 | 4 | C# |
| 2 | bbb | 2 | 5 | Javascript |
| 3 | ccc | 3 | 1 | C++ |
| 3 | ccc | 3 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 3 | ccc | 3 | 4 | C# |
| 3 | ccc | 3 | 5 | Javascript |
| 4 | ddd | 4 | 1 | C++ |
| 4 | ddd | 4 | 2 | C |
| 4 | ddd | 4 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 4 | ddd | 4 | 5 | Javascript |
| 5 | eee | 4 | 1 | C++ |
| 5 | eee | 4 | 2 | C |
| 5 | eee | 4 | 3 | Java |
| 5 | eee | 4 | 4 | C# |
| 5 | eee | 4 | 5 | Javascript |
| 6 | fff | 3 | 1 | C++ |
| 6 | fff | 3 | 2 | C |
| 6 | fff | 3 | 3 | Java |
| 6 | fff | 3 | 4 | C# |
| 6 | fff | 3 | 5 | Javascript |
| 7 | ggg | 2 | 1 | C++ |
| 7 | ggg | 2 | 2 | C |
| 7 | ggg | 2 | 3 | Java |
| 7 | ggg | 2 | 4 | C# |
| 7 | ggg | 2 | 5 | Javascript |
| 8 | hhh | NULL | 1 | C++ |
| 8 | hhh | NULL | 2 | C |
| 8 | hhh | NULL | 3 | Java |
| 8 | hhh | NULL | 4 | C# |
| 8 | hhh | NULL | 5 | Javascript |
| 9 | iii | NULL | 1 | C++ |
| 9 | iii | NULL | 2 | C |
| 9 | iii | NULL | 3 | Java |
| 9 | iii | NULL | 4 | C# |
| 9 | iii | NULL | 5 | Javascript |
| 10 | jjj | NULL | 1 | C++ |
| 10 | jjj | NULL | 2 | C |
| 10 | jjj | NULL | 3 | Java |
| 10 | jjj | NULL | 4 | C# |
| 10 | jjj | NULL | 5 | Javascript |
+----+-------+--------+----+------------+Inner JOIN : INNER JOIN
Inner JOIN est l'opération de connexion la plus couramment utilisée. D'un point de vue mathématique, il s'agit de calculer l'intersection des deux tables ; et du point de vue du produit cartésien, il s'agit de filtrer les enregistrements qui remplissent les conditions de la clause ON du produit cartésien. Il existe quatre méthodes d'écriture : INNER JOIN, WHERE (jointure équivalente), STRAIGHT_JOIN et JOIN (INNER omis).
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId=t_type.id;
SELECT * FROM t_blog,t_type WHERE t_blog.typeId=t_type.id;
SELECT * FROM t_blog STRAIGHT_JOIN t_type ON t_blog.typeId=t_type.id; --注意STRIGHT_JOIN有个下划线
SELECT * FROM t_blog JOIN t_type ON t_blog.typeId=t_type.id;
+----+-------+--------+----+------+
| id | title | typeId | id | name |
+----+-------+--------+----+------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 5 | eee | 4 | 4 | C# |
+----+-------+--------+----+------+LEFT JOIN : LEFT JOIN
La signification de LEFT JOIN est de trouver l'intersection de deux tables plus les données restantes dans la table de gauche. Toujours du point de vue du produit cartésien, nous sélectionnons d'abord les enregistrements pour lesquels la condition de la clause ON est vraie à partir du produit cartésien, puis ajoutons les enregistrements restants dans le tableau de gauche (voir les trois derniers éléments).
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id;
+----+-------+--------+------+------+
| id | title | typeId | id | name |
+----+-------+--------+------+------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 5 | eee | 4 | 4 | C# |
| 8 | hhh | NULL | NULL | NULL |
| 9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
+----+-------+--------+------+------+RIGHT JOIN : RIGHT JOIN
De même, RIGHT JOIN consiste à trouver l'intersection de deux tables plus les données restantes dans la table de droite. Encore une fois décrite du point de vue du produit cartésien, la jointure de droite consiste à sélectionner les enregistrements dont la condition de clause ON est vraie dans le produit cartésien, puis à ajouter les enregistrements restants dans la table de droite (voir le dernier élément).
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+----+------------+
| id | title | typeId | id | name |
+------+-------+--------+----+------------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 5 | eee | 4 | 4 | C# |
| 6 | fff | 3 | 3 | Java |
| 7 | ggg | 2 | 2 | C |
| NULL | NULL | NULL | 5 | Javascript |
+------+-------+--------+----+------------+Jointure externe : OUTER JOIN
La jointure externe consiste à trouver l'union de deux ensembles. Du point de vue du produit cartésien, il s'agit de sélectionner les enregistrements pour lesquels la condition de la clause ON est vraie à partir du produit cartésien, puis d'ajouter les enregistrements restants dans le tableau de gauche, et enfin d'ajouter les enregistrements restants dans le tableau de droite. MySQL ne prend pas en charge OUTER JOIN, mais nous pouvons y parvenir en UNIONnant les résultats de la jointure gauche et de la jointure droite.
SELECT * FROM t_blog LEFT JOIN t_type ON t_blog.typeId=t_type.id
UNION
SELECT * FROM t_blog RIGHT JOIN t_type ON t_blog.typeId=t_type.id;
+------+-------+--------+------+------------+
| id | title | typeId | id | name |
+------+-------+--------+------+------------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 5 | eee | 4 | 4 | C# |
| 8 | hhh | NULL | NULL | NULL |
| 9 | iii | NULL | NULL | NULL |
| 10 | jjj | NULL | NULL | NULL |
| NULL | NULL | NULL | 5 | Javascript |
+------+-------+--------+------+------------+Clause USING
Dans l'instruction SQL de connexion dans MySQL, le format de syntaxe de la clause ON est : table1.column_name = table2.column_name. Lorsque la conception du schéma adopte le même style de dénomination pour les colonnes de la table jointe, la syntaxe USING peut être utilisée pour simplifier la syntaxe ON, au format : USING(column_name).
Ainsi, la fonction de USING est équivalente à ON. La différence est que USING spécifie un nom d'attribut pour connecter deux tables, tandis que ON spécifie une condition. De plus, lorsque SELECT *, USING supprimera les colonnes spécifiées par USING, mais pas ON. Les exemples sont les suivants.
SELECT * FROM t_blog INNER JOIN t_type ON t_blog.typeId =t_type.id;
+----+-------+--------+----+------+
| id | title | typeId | id | name |
+----+-------+--------+----+------+
| 1 | aaa | 1 | 1 | C++ |
| 2 | bbb | 2 | 2 | C |
| 7 | ggg | 2 | 2 | C |
| 3 | ccc | 3 | 3 | Java |
| 6 | fff | 3 | 3 | Java |
| 4 | ddd | 4 | 4 | C# |
| 5 | eee | 4 | 4 | C# |
+----+-------+--------+----+------+
SELECT * FROM t_blog INNER JOIN t_type USING(typeId);
ERROR 1054 (42S22): Unknown column 'typeId' in 'from clause'
SELECT * FROM t_blog INNER JOIN t_type USING(id); -- 应为t_blog的typeId与t_type的id不同名,无法用Using,这里用id代替下。
+----+-------+--------+------------+
| id | title | typeId | name |
+----+-------+--------+------------+
| 1 | aaa | 1 | C++ |
| 2 | bbb | 2 | C |
| 3 | ccc | 3 | Java |
| 4 | ddd | 4 | C# |
| 5 | eee | 4 | Javascript |
+----+-------+--------+------------+Jointure naturelle : NATURE JOIN
La jointure naturelle est une version simplifiée de la clause USING. Elle trouve les mêmes colonnes dans les deux tables et les utilise comme conditions de jointure pour se joindre. Il existe des connexions naturelles à gauche, des connexions naturelles à droite et des connexions naturelles ordinaires. Dans les exemples t_blog et t_type, la même colonne dans les deux tables est id, donc id sera utilisé comme condition de connexion.
De plus, veillez à bien distinguer la différence entre les trois affirmations suivantes.
NATURAL JOIN:SELECT * FROM t_blog NATURAL JOIN t_type;
Produit cartésien:SELECT * FROM t_blog NATURA JOIN t_type;
Produit cartésien:SELECT * FROM t_blog NATURE JOIN t_type;
SELECT * FROM t_blog NATURAL JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog,t_type WHERE t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog INNER JOIN t_type USING(id);
+----+-------+--------+------------+
| id | title | typeId | name |
| 1 | aaa | 1 | C++ |
| 2 | bbb | 2 | C |
| 3 | ccc | 3 | Java |
| 4 | ddd | 4 | C# |
| 5 | eee | 4 | Javascript |
SELECT * FROM t_blog NATURAL LEFT JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog LEFT JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog LEFT JOIN t_type USING(id);
| 6 | fff | 3 | NULL |
| 7 | ggg | 2 | NULL |
| 8 | hhh | NULL | NULL |
| 9 | iii | NULL | NULL |
| 10 | jjj | NULL | NULL |
SELECT * FROM t_blog NATURAL RIGHT JOIN t_type;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog RIGHT JOIN t_type ON t_blog.id=t_type.id;
SELECT t_blog.id,title,typeId,t_type.name FROM t_blog RIGHT JOIN t_type USING(id);
+----+------------+-------+--------+
| id | name | title | typeId |
| 1 | C++ | aaa | 1 |
| 2 | C | bbb | 2 |
| 3 | Java | ccc | 3 |
| 4 | C# | ddd | 4 |
| 5 | Javascript | eee | 4 |Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1209
24
52
1209
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
