

Comment résoudre l'échec de l'index MySQL

1. Avant-propos
Lors de l'indexation d'une instruction SQL, vous rencontrerez un échec d'indexation, ce qui a un impact crucial sur la faisabilité et l'efficacité des performances de l'instruction. Cet article analyse pourquoi. l'index échoue, quelles situations conduiront à l'échec de l'index et les solutions d'optimisation en cas d'échec de l'index, en se concentrant sur le principe de correspondance des préfixes les plus à gauche, <code>architecture logique et optimiseur MySQL, scénarios d'échec d'index et pourquoi ils échouent. 索引为何失效,有哪些情况会导致索引失效以及对于索引失效时的优化解决方案,其中着重介绍最左前缀匹配原则、MySQL逻辑架构和优化器、索引失效场景以及为何会失效。
二、最左前缀匹配原则
之前有写了一篇关于MySQL添加索引特点及优化问题方面的文章,下面将介绍索引失效的相关内容。
首先引入在之后的索引失效原因中会使用到的一个原则:最左前缀匹配原则。
最左前缀底层原理:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
什么是最左前缀匹配原则呢?要想理解联合索引的最左匹配原则,先来理解下索引的底层原理:索引的底层是一颗B+树,那么联合索引的底层也就是一颗B+树,只不过联合索引的B+树节点中存储的是键值。数据库需要依赖联合索引中最左边的字段来构建,因为B+树只能根据一个值来确定索引关系。
举例:创建一个(a,b)的联合索引,那么它的索引树就是下图的样子。
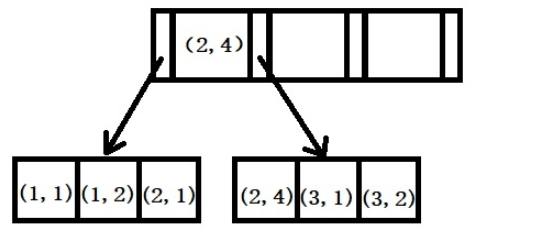
a的值有序,出现的顺序为1,1,2,2,3,3。b的值无序,出现的数字为1,2,1,4,1,2。在a的值相等的情况下,我们可以观察到b的值按照一定顺序排列,但要注意这个顺序是相对的。这是因为MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序。所以b=2这种查询条件没有办法利用索引。
由于整个过程是基于explain结果分析的,那接下来在了解下explain中的type字段和key_lef字段。
1.type:联接类型。
system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计
const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。因为只需匹配一行数据,所有很快。将主键放在WHERE条件中,MySQL会将该查询转换为一个const查询。
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。注意:ALL全表扫描的表记录最少的表如t1表
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。-
2. Principe de correspondance des préfixes les plus à gaucheindex - J'ai déjà écrit un article sur les caractéristiques et les problèmes d'optimisation liés à l'ajout d'index à MySQL. Ce qui suit présentera le contenu pertinent de l'échec d'un index. . Introduisez d'abord un principe qui sera utilisé dans les raisons d'échec d'index suivantes :
Le principe de correspondance de préfixe le plus à gauche.
Quel est le principe de correspondance des préfixes les plus à gauche ? Pour comprendre le principe de correspondance le plus à gauche de l'index conjoint, comprenez d'abord le principe sous-jacent de l'index : la couche inférieure de l'index est un arbre B+, puis la couche inférieure de l'index conjoint est également un arbre B+, mais dans l'arbre B+ nœuds de l'index commun Les valeurs clés sont stockées. La base de données doit être construite en s'appuyant sur le champ le plus à gauche de l'index conjoint, car l'arborescence B+ ne peut déterminer la relation d'index qu'en fonction d'une seule valeur.
Exemple : Créez un index conjoint de (a, b), puis son arbre d'index ressemblera à la figure ci-dessous.
# 🎜 Les valeurs de 🎜#- a sont dans l'ordre, et l'ordre d'apparition est 1, 1, 2, 2, 3, 3. Les valeurs de b ne sont pas ordonnées et les nombres qui apparaissent sont 1, 2, 1, 4, 1, 2. Lorsque les valeurs de a sont égales, on peut observer que les valeurs de b sont disposées dans un certain ordre, mais il faut noter que cet ordre est relatif. En effet, la règle de MySQL pour créer un index commun consiste à trier d'abord le premier champ le plus à gauche de l'index commun, en fonction du tri du premier champ, puis à trier le deuxième champ. Par conséquent, il n’existe aucun moyen d’utiliser l’index pour des conditions de requête telles que b=2.
Puisque l'ensemble du processus est basé sur l'analyse des résultats d'explication, apprenons-en davantage sur le champ type et le champ key_lef dans Explication.
1.- type : Type de connexion
.
-
system : La table n'a qu'une seule ligne d'enregistrements (égale à la table système). Il s'agit d'un cas particulier de type const. peut être ignoré.
#🎜🎜 #
- eq_ref : Analyse d'index unique, pour chaque clé d'index, un seul enregistrement de la table lui correspond. Couramment observé dans les analyses de clé primaire ou d’index unique. Remarque : L'analyse complète de la table contenant le moins d'enregistrements, telle que la table t1
ref: analyse d'index non unique, renvoie toutes les lignes correspondant à une seule valeur. Essentiellement, il s'agit d'un accès à l'index qui renvoie toutes les lignes correspondant à une seule valeur. Cependant, il peut trouver plusieurs lignes correspondantes, il doit donc s'agir d'un mélange de recherche et d'analyse.
range : Récupère uniquement les lignes de la plage donnée, en utilisant un index pour sélectionner les lignes. La colonne clé indique quel index est utilisé. Généralement, les requêtes telles que between, , in, etc. apparaissent dans l'instruction Where. Cette analyse de plage sur les colonnes d'index est meilleure qu'une analyse d'index complète. Il suffit de commencer à un certain point et de se terminer à un autre point, sans analyser l'intégralité de l'index. #🎜🎜##🎜🎜#index : Full Index Scan, la différence entre index et ALL est que le type d'index ne traverse que l'arborescence d'index. Il s'agit généralement de TOUS les blocs, car les fichiers d'index sont généralement plus petits que les fichiers de données. (Bien qu'Index et ALL lisent tous deux la table entière, l'index est lu à partir de l'index, tandis que ALL est lu à partir du disque dur) la table entière pour trouver les lignes correspondantes #🎜🎜##🎜🎜##🎜🎜##🎜🎜#2 #🎜🎜#key_len#🎜🎜# : Affiche la longueur de l'index que MySQL a réellement décidé d'utiliser. Si l'index est NULL, la longueur est NULL. Si ce n'est pas NULL, la longueur de l'index utilisé. Ce champ peut donc être utilisé pour déduire quel index est utilisé. #🎜🎜##🎜🎜##🎜🎜#Règles de calcul : #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜#1. octets, char(n) occupe n caractères. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#2. Le champ de longueur variable varchar(n) occupe n caractères + deux octets. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#3. Différents jeux de caractères, le nombre d'octets occupés par un caractère est différent. En codage Latin1, un caractère occupe un octet, en codage gdk, un caractère occupe deux octets et en codage UTF-8, un caractère occupe trois octets. #🎜🎜##🎜🎜##🎜🎜##🎜🎜# (Comme ma base de données utilise le format d'encodage Latin1, dans les calculs ultérieurs, un caractère compte pour un octet) #🎜🎜##🎜🎜 ##🎜🎜 ##🎜🎜#4. Pour tous les champs d'index, s'ils sont définis sur NULL, 1 octet est requis. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Après avoir compris le principe de correspondance des préfixes les plus à gauche, examinons le scénario d'échec de l'index et analysons pourquoi il échoue. #🎜🎜#3. Architecture logique MySQL et optimiseur
Architecture logique MySQL : MySQL逻辑架构:
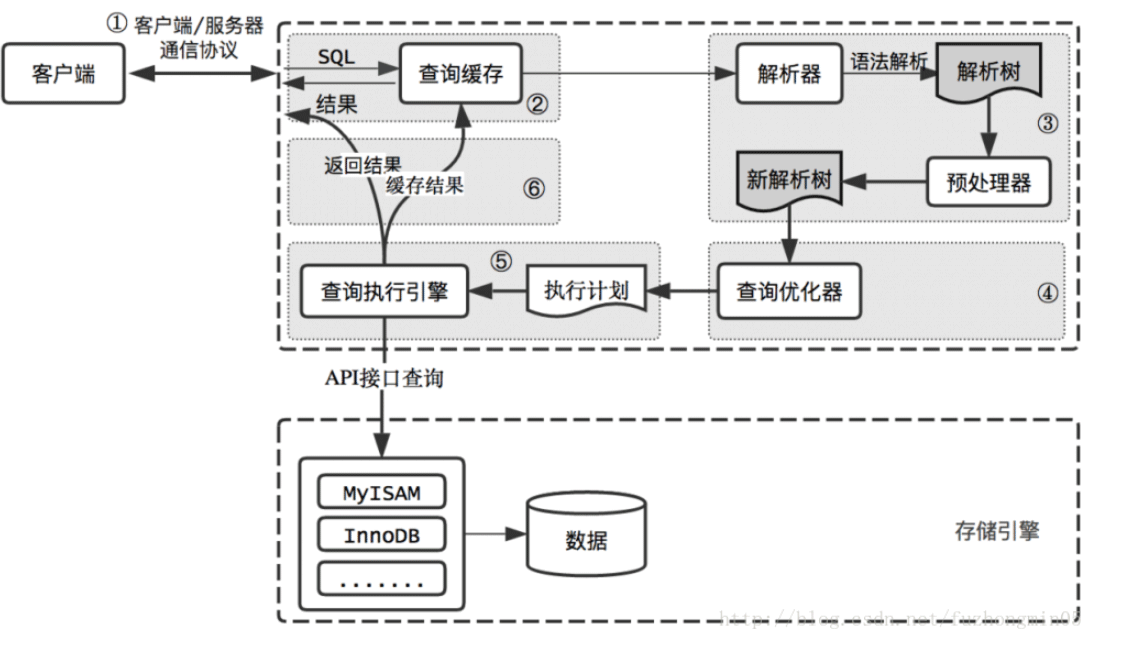
mysql架构可分为大概的4层,分别是:
1.客户端:各种语言都提供了连接mysql数据库的方法,比如jdbc、php、go等,可根据选择 的后端开发语言选择相应的方法或框架连接mysql
2.server层:包括连接器、查询缓存、分析器、优化器、执行器等,涵盖mysql的大多数核心服务功能,以及所有的内置函数(例如日期、世家、数 学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
3.存储引擎层:负责数据的存储和提取,是真正与底层物理文件打交道的组件。 数据本质是存储在磁盘上的,通过特定的存储引擎对数据进行有组织的存放并根据业务需要对数据进行提取。存储引擎的架构模式是插件式的,支持Innodb,MyIASM、Memory等多个存储引擎。现在最常用的存储引擎是Innodb,它从mysql5.5.5版本开始成为了默认存储引擎。
4.物理文件层:存储数据库真正的表数据、日志等。物理文件包括:redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等。
server层重要组件介绍:
1.连接器
连接器负责来自客户端的连接、获取用户权限、维持和管理连接。
一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建连接才会使用新的权限设置。
2.查询缓存
mysql拿到一个查询请求后,会先到查询缓存查看之前是否执行过这条语句。之前运行的语句及其输出结果可能直接存储在内存中,以键值对的形式缓存。key是查询的语句,value是查询的结果。当SQL查询的关键字(key)能够直接在查询缓存中匹配时,查询结果(value)就会被直接返回给客户端。
其实大多数情况下建议不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。只要涉及到一个表的更新操作,所有和该表相关的查询缓存都很容易失效并被清空。因此很有可能经过费力将结果存储之后,还未来得及使用就被新的更新操作全部清空了。对于更新操作多的数据库来说,查询缓存的命中率会非常低。除非业务需要的是一张静态表,很长时间才会更新一次。比如,一个系统配置表,那么这张表的查询才适合使用查询缓存。
3.分析器
词法分析(识别关键字,操作,表名,列名)
语法分析 (判断是否符合语法)
4.优化器
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
5.执行器
开始执行的时候,要先判断一下用户对这个表 T 有没有执行查询的权限。如果没有,就会返回没有权限的错误。如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去调用这个引擎提供的接口。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的。
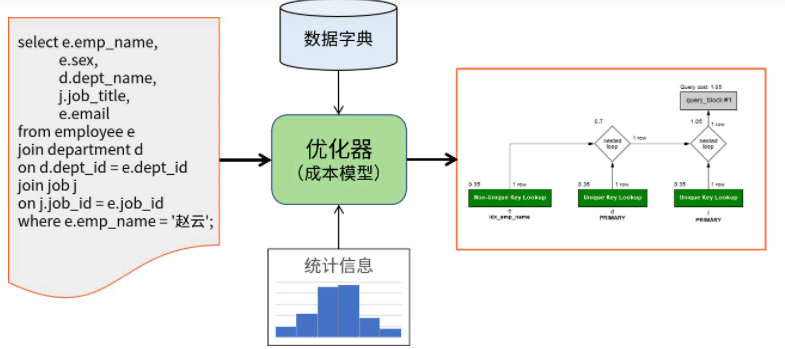
MySQL优化器
L'architecture mysql peut être divisée en environ 4 couches, qui sont :
-
1.
Client: Différents langages fournissent des méthodes pour se connecter à la base de données MySQL, telles que jdbc, php, go, etc. Vous pouvez choisir la méthode ou le framework correspondant pour vous connecter à MySQL en fonction du langage de développement back-end sélectionné li> 2.
Couche serveur🎜 : Y compris les connecteurs, le cache de requêtes, les analyseurs, les optimiseurs, les exécuteurs, etc., couvrant la plupart des fonctions de base du service MySQL, ainsi que toutes les fonctions intégrées (telles que la date, la famille , fonctions mathématiques et de chiffrement, etc.), toutes les fonctions du moteur de stockage croisé sont implémentées dans cette couche, telles que les procédures stockées, les déclencheurs, les vues, etc. 🎜 - 🎜3.🎜Couche moteur de stockage🎜 : Responsable du stockage et de la récupération des données, c'est le composant qui s'occupe réellement des fichiers physiques sous-jacents. L'essentiel des données est stocké sur le disque. Les données sont stockées de manière organisée via un moteur de stockage spécifique et extraites en fonction des besoins de l'entreprise. Le modèle architectural du moteur de stockage est un plug-in et prend en charge plusieurs moteurs de stockage tels que Innodb, MyIASM et Memory. Le moteur de stockage le plus couramment utilisé est désormais Innodb, qui est devenu le moteur de stockage par défaut à partir de mysql5.5.5. 🎜
- 🎜4.🎜Couche de fichiers physiques🎜 : stocke les données réelles de la table, les journaux, etc. de la base de données. Les fichiers physiques incluent : redolog, undolog, binlog, errorlog, querylog, slowlog, data, index, etc. 🎜
Analyse syntaxique (déterminer si elle est conforme à la grammaire)🎜🎜🎜4. Optimiseur🎜🎜🎜L'optimiseur est. Lorsqu'il y a plusieurs index dans la table, décidez quel index utiliser ; ou lorsqu'une instruction a plusieurs associations de tables (jointure), décidez de l'ordre dans lequel les tables sont jointes. Une fois la phase d'optimisation terminée, le plan d'exécution de cette instruction est déterminé, puis entre dans la phase d'exécution. 🎜🎜🎜5. Lorsque l'exécuteur 🎜🎜🎜 démarre l'exécution, il doit d'abord déterminer si l'utilisateur a l'autorisation d'exécuter des requêtes sur cette table T. Sinon, une erreur d’absence d’autorisation sera renvoyée. Si le cache de requêtes est atteint, la vérification des autorisations sera effectuée lorsque le cache de requêtes renvoie les résultats. La requête appelle également precheck pour vérifier les autorisations avant l'optimiseur. Si vous avez l'autorisation, ouvrez la table et poursuivez l'exécution. Lorsqu'une table est ouverte, l'exécuteur appellera l'interface fournie par le moteur en fonction de la définition du moteur de la table. Dans certains scénarios, l'exécuteur est appelé une fois et plusieurs lignes sont analysées à l'intérieur du moteur, de sorte que le nombre de lignes analysées par le moteur n'est pas exactement le même que celui de rows_examined
MySQL Optimizer : 🎜🎜L'optimiseur MySQL utilise une optimisation basée sur les coûts (Optimisation basée sur les coûts), prend les instructions SQL en entrée et utilise le modèle de coûts intégré et les informations du dictionnaire de données ainsi qu'un moteur de stockage. Les informations statistiques déterminent les étapes utilisées pour mettre en œuvre l'instruction de requête, c'est-à-dire le plan de requête. 🎜🎜🎜🎜🎜D'un niveau élevé, le serveur MySQL est divisé en deux composants : la couche serveur et la couche moteur de stockage. Parmi eux, l'optimiseur fonctionne au niveau de la couche serveur, située au-dessus de l'API du moteur de stockage. 🎜🎜🎜Le processus de travail de l'optimiseur peut être divisé sémantiquement en quatre étapes : 🎜🎜1.Transformation logique, y compris l'élimination de la négation, le transfert équivalent et le transfert constant, l'évaluation d'expression constante, la conversion des jointures externes en jointures internes, la conversion de sous-requêtes, la fusion de vues, etc.
2.Préparation à l'optimisation, telle que l'indexation ; analyse des méthodes d'accès aux références et aux plages, analyse de la valeur de diffusion des conditions de requête (sortie, nombre d'enregistrements après filtrage), détection de table constante
3.Basée sur l'optimisation des coûts, y compris la sélection des méthodes d'accès et des séquences de connexion ; 4.
Améliorations du plan d'exécution, telles que le refoulement des conditions de table, l'ajustement de la méthode d'accès, l'évitement du tri et le refoulement des conditions d'index.
like commence par le caractère générique % et l'index échoue. Ce qui précède présente le principe sous-jacent de la correspondance des préfixes les plus à gauche. Nous savons que la structure de données d'index couramment utilisée est un arbre B+ et que l'index est ordonné. Si le type du mot-clé d'index est Int type, L'ordre de l'index est le suivant : like以通配符%开头索引失效。上面介绍了最左前缀匹配底层原理,我们知道了通常用的索引数据结构是B+树,而索引是有序排列的。如果索引关键字的类型是Int 类型,索引的排列顺序如下:
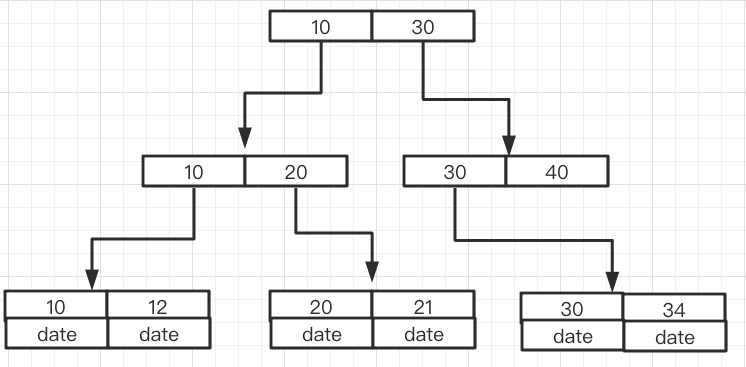
数据只存放在叶子节点,而且是有序的排放。
如果索引关键字的类型是String类型,排列顺序如下:
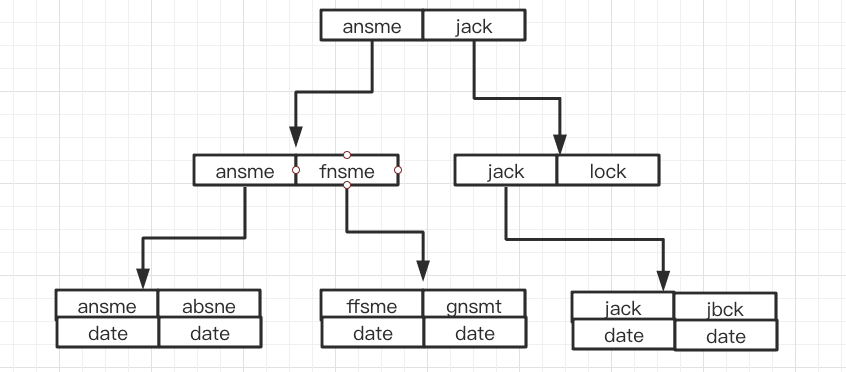
可以看出,索引的排列顺序是根据比较字符串的首字母排序的。
我们在进行模糊查询的时候,如果把 % 放在了前面,最左的 n 个字母便是模糊不定的,无法根据索引的有序性准确的定位到某一个索引,只能进行全表扫描,找出符合条件的数据。(最左前缀底层原理)
在使用联合索引时也是如此,如果违背了索引有序排列的规则,同样会造成索引失效,进行全表扫描。
例子:表example中有个组合索引为:(A,B,C)
SELECT * FROM example WHERE A=1 and B =1 and C=1; 可以走索引;
SELECT A FROM example WHERE C =1 and B=1 ORDER BY A; 可以走索引(使用了覆盖索引)
SELECT * FROM example WHERE C =1 and B=1 ORDER BY A; 不可以走索引
覆盖索引:索引包含所有满足查询需要的数据的索引,称为覆盖索引(Covering Index)
可以有两种方式优化:
一种是使用覆盖索引,第二种是把%放后面。
2.字段类型是字符串,where时没有用引号括起来。表中的字段为字符串类型,是B+树的普通索引,如果查询条件传了一个数字过去,它是不走索引的。
例子:表example中有个字段为pid是varchar类型。
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE pid = 1
//此时执行语句type为ref索引查询 explain SELECT * FROM example WHERE pid = '1'
为什么第一条语句未加单引号就不走索引了呢? 这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。
3.OR 前后只要存在非索引的列,都会导致索引失效。查询条件包含or,就有可能导致索引失效。
例子:表example中有字段为pid是int类型,score是int类型。
//此时执行语句type为ref索引查询 explain SELECT * FROM example WHERE pid = 1
//把or条件加没有索引的score,并不会走索引,为ALL全表查询 explain SELECT * FROM example WHERE pid = 1 OR score = 10
这里对于OR后面加上没有索引的score这种情况,假设它走了p_id的索引,但是走到score查询条件时,它还得全表扫描,也就是需要三步过程: 全表扫描+索引扫描+合并。
mysql是有优化器的,处于效率与成本,遇到OR条件,索引可能会失效也是合理的。
注意: 如果or条件的列都加了索引,索引可能会走的。
4.联合索引(组合索引),查询时的条件列不是联合索引中的第一个列,索引失效。在联合索引中,查询条件满足最左匹配原则时,索引是正常生效的。
当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
例子:有一个联合索引idx_pid_score,pid在前,score在后。
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1 OR score = 10
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score = 10
联合索引不满足最左原则,索引一般会失效,但是这个还跟Mysql优化器有关。
5.计算、函数、类型转换(自动或手动)导致索引失效,索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
Les données sont uniquement stockées dans les 还有不等于(!= 或者<>)导致索引失效。 虽然score 加了索引,但是使用了!= 或者 < >,not in这些时,索引如同虚设。 7. 当把两表的字段类型改为一致时: 所以字段类型也会导致索引失效 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!nœuds feuilles et sont déchargées dans ordonné</code >. <br/></p>Si le type du mot-clé d'index est <code>String type, 🎜L'ordre de tri est le suivant : 🎜🎜🎜🎜🎜On peut voir que l'ordre de l'index est trié selon la première lettre du chaîne de comparaison. 🎜Lorsque nous effectuons une requête floue, si nous mettons % devant, les n lettres les plus à gauche seront floues et incertaines. Nous ne pouvons pas localiser avec précision un certain index en fonction de l'ordre de l'index. Nous ne pouvons effectuer qu'une analyse complète de la table. données qui remplissent les conditions. (Le principe sous-jacent du préfixe le plus à gauche)🎜🎜La même chose est vraie lors de l'utilisation de index conjoint Si les règles d'ordre des index sont violées, l'index sera également invalide. Analyse Table complète. 🎜Exemple : Il y a un index combiné dans l'exemple de tableau : (A, B, C) 🎜SELECT * FROM exemple WHERE A=1 et B =1 et C=1 ; Peut utiliser l'index ; 🎜SELECT A FROM exemple WHERE C =1 et B=1 ORDER BY A; index Can (en utilisant l'index de couverture) 🎜SELECT * FROM exemple WHERE C =1 et B=1 ORDER BY A 🎜🎜Index couvert :🎜L'index contient toutes les données qui répondent aux besoins de la requête, appelé index de couverture (Covering Index)🎜
🎜Il existe deux manières< code>Optimisation : 🎜La première consiste à utiliser l'index de couverture, et la seconde consiste à mettre % à la fin. 🎜🎜2.Le type de champ est une chaîne et le où n'est pas mis entre guillemets. Les champs de la table sont de type chaîne et sont des index ordinaires d'arbres B+. Si la condition de requête passe un nombre, elle ne sera pas indexée. 🎜Exemple : Il y a un champ dans l'exemple de table appelé pid qui est de type varchar. 🎜//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE Date_ADD(birthtime,INTERVAL 1 DAY) = 6
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score-1=5
implicite et les convertira en nombres à virgule flottante avant la comparaison. 🎜🎜3.Tant qu'il y a des colonnes non indexées avant et après OR, l'index échouera. Si la condition de requête contient ou, cela peut provoquer un échec de l'index. 🎜Exemple : Il y a des champs dans l'exemple de tableau où pid est de type int et score est de type int. 🎜//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score != 2
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score <> 3
Analyse complète de la table + analyse d'index + fusion. 🎜MySQL dispose d'un optimiseur en termes d'efficacité et de coût, il est raisonnable que l'index puisse échouer lorsqu'il rencontre des conditions OR. 🎜🎜Remarque : Si les colonnes de la condition OR sont indexées, l'index risque d'être perdu. 🎜🎜4.Index conjoint (index combiné), la colonne de condition lors de la requête n'est pas la première colonne de l'index conjoint et l'index devient invalide. Dans l'index conjoint, lorsque les conditions de requête répondent au principe de correspondance le plus à gauche, l'index prendra effet normalement. 🎜Lorsque nous créons un index conjoint, tel que (k1,k2,k3), cela équivaut à créer trois index (k1), (k1,k2) et (k1,k2,k3). C'est le principe de correspondance le plus à gauche. 🎜Exemple : Il existe un index commun idx_pid_score, avec pid en premier et score en second. 🎜//此时执行语句type为range索引查询
explain SELECT * FROM example WHERE name is not null
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE name is not null OR card is not null
//此时执行语句example表会走type为index类型索引,example_two则为ALL全表搜索不走索引
explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
Le calcul, la fonction, la conversion de type (automatique ou manuelle) provoquent un échec de l'index. Lors de l'utilisation de (!= ou < >, pas dedans) sur le champ d'index, cela peut provoquer un échec de l'index. 🎜Birthtime est indexé, mais comme il utilise la fonction intégrée de MySQL Date_ADD(), il n'est pas indexé. 🎜Exemple : Dans l'exemple de table, l'index idx_birth_time est un champ d'heure de naissance de type datetime🎜//此时执行语句example表会走type为index类型索引,example_two会走type为ref类型索引
explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score-1=5
例子:在表example中有int类型的score字段索引idx_score//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score != 2
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE score <> 3
6. is null可以使用索引,is not null无法使用索引。
例子:在表example中有varchar类型的name字段索引idx_name,varchar类型的card字段索引idx_card。//此时执行语句type为range索引查询
explain SELECT * FROM example WHERE name is not null
//此时执行语句type为ALL全表查询
explain SELECT * FROM example WHERE name is not null OR card is not null
左连接查询或者右连接查询查询关联的字段编码格式不一样。两张表相同字段外连接查询时字段编码格式不同则会不走索引查询。
例子:在表example中有varchar类型的name字段编码是utf8mb4,索引为idx_name
在表example_two中有varchar类型的name字段编码为utf8,索引为idx_name。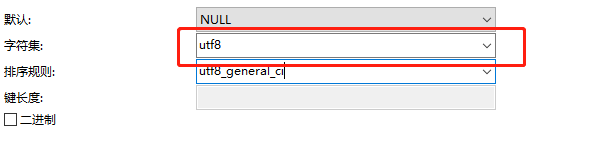
//此时执行语句example表会走type为index类型索引,example_two则为ALL全表搜索不走索引
explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
//此时执行语句example表会走type为index类型索引,example_two会走type为ref类型索引
explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name
8.mysql估计使用全表扫描要比使用索引快,则不使用索引。当表的索引被查询,会使用最好的索引,除非优化器使用全表扫描更有效。优化器优化成全表扫描取决与使用最好索引查出来的数据是否超过表的30%的数据。建议:不要给’性别’等增加索引。如果某个数据列里包含了均是"0/1"或“Y/N”等值,即包含着许多重复的值,就算为它建立了索引,索引效果不会太好,还可能导致全表扫描。
Mysql出于效率与成本考虑,估算全表扫描与使用索引,哪个执行快,这跟它的优化器有关。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
