
 Périphériques technologiques
IA
Les géants de l'IA soumettent des documents à la Maison Blanche : 12 grandes institutions, dont Google, OpenAI, Oxford et d'autres, ont publié conjointement le « Model Security Assessment Framework »
Périphériques technologiques
IA
Les géants de l'IA soumettent des documents à la Maison Blanche : 12 grandes institutions, dont Google, OpenAI, Oxford et d'autres, ont publié conjointement le « Model Security Assessment Framework »
Les géants de l'IA soumettent des documents à la Maison Blanche : 12 grandes institutions, dont Google, OpenAI, Oxford et d'autres, ont publié conjointement le « Model Security Assessment Framework »

Début mai, la Maison Blanche a organisé une réunion avec les PDG de sociétés d'IA telles que Google, Microsoft, OpenAI et Anthropic pour discuter de l'explosion de la technologie génératrice d'IA, des risques cachés derrière cette technologie et de la manière de développer des systèmes d'intelligence artificielle. de manière responsable et la formulation de réglementations Mesures réglementaires efficaces.

Les processus d'évaluation de sécurité existants s'appuient généralement sur une série de critères d'évaluation pour identifier les comportements anormaux des systèmes d'IA, tels que des déclarations trompeuses, une prise de décision biaisée ou des résultats protégés par un contenu protégé par le droit d'auteur.
À mesure que la technologie de l'IA devient de plus en plus puissante, les outils d'évaluation des modèles correspondants doivent également être mis à niveau pour empêcher le développement de systèmes d'IA dotés de manipulations, de tromperies ou d'autres capacités à haut risque.
Récemment, Google DeepMind, l'Université de Cambridge, l'Université d'Oxford, l'Université de Toronto, l'Université de Montréal, OpenAI, Anthropic et de nombreuses autres universités et instituts de recherche de premier plan ont publié conjointement un cadre d'évaluation de la sécurité des modèles, qui devrait devenir l'avenir de l'intelligence artificielle Composants clés pour le développement et le déploiement de modèles.

Lien papier : https://arxiv.org/pdf/2305.15324.pdf
Les développeurs de systèmes d'IA généraux doivent évaluer les capacités de danger et l'alignement des modèles pour identifier les risques extrêmes dès le plus tôt possible. possible, rendant ainsi la formation, le déploiement, la description des risques et d'autres processus plus responsables.
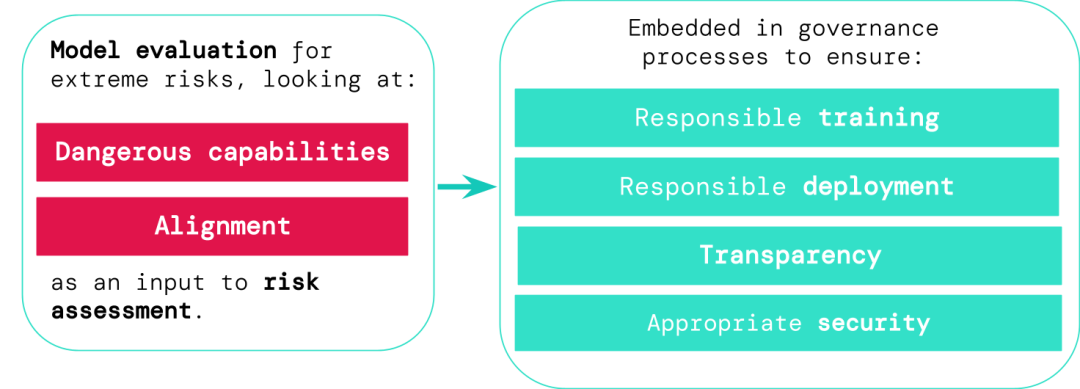
Les résultats de l'évaluation permettent aux décideurs et aux autres parties prenantes de comprendre les détails et de prendre des décisions responsables concernant la formation, le déploiement et la sécurité du modèle.
L'IA est risquée, la formation doit être prudente
Les modèles généraux doivent généralement être "entraînés" pour apprendre des capacités et des comportements spécifiques, mais le processus d'apprentissage existant est généralement imparfait, comme dans des recherches précédentes, ont découvert les chercheurs de DeepMind. que même lorsque le comportement attendu du modèle avait été correctement récompensé pendant l'entraînement, le système d'IA avait quand même appris certains objectifs involontaires. Les développeurs d'IA responsables doivent être capables de prédire à l'avance les développements futurs possibles et les risques inconnus, et de suivre avec le Grâce à l'avancement des systèmes d'IA, les modèles généraux pourraient apprendre diverses capacités dangereuses par défaut à l'avenir.
Par exemple, les systèmes d'intelligence artificielle peuvent mener des cyberopérations de contre-attaque, tromper intelligemment les humains dans les conversations, manipuler les humains pour mener des actions nuisibles, concevoir ou obtenir des armes, etc., affiner et exploiter d'autres IA à haut risque sur le cloud. systèmes de plates-formes informatiques, ou aider les humains à accomplir ces tâches dangereuses. 
Une personne ayant un accès malveillant à un tel modèle peut abuser des capacités de l'IA, ou en raison d'un échec d'alignement, le modèle d'IA peut choisir de prendre lui-même des actions nuisibles sans l'aide d'un humain. L'évaluation du modèle permet d'identifier ces risques à l'avance. En suivant le cadre proposé dans l'article, les développeurs d'IA peuvent utiliser l'évaluation du modèle pour découvrir :
1. utilisé pour menacer la sécurité, exercer une influence ou échapper à la surveillance
2. La mesure dans laquelle le modèle a tendance à appliquer ses capacités pour causer du tort (c'est-à-dire l'alignement du modèle). Les évaluations de calibrage doivent confirmer que le modèle se comporte comme prévu dans un très large éventail de paramètres de scénarios et, si possible, examiner le fonctionnement interne du modèle.
Les scénarios les plus risqués impliquent souvent une combinaison de capacités dangereuses, et les résultats de l'évaluation aident les développeurs d'IA à comprendre s'il existe suffisamment d'ingrédients pour provoquer des risques extrêmes :
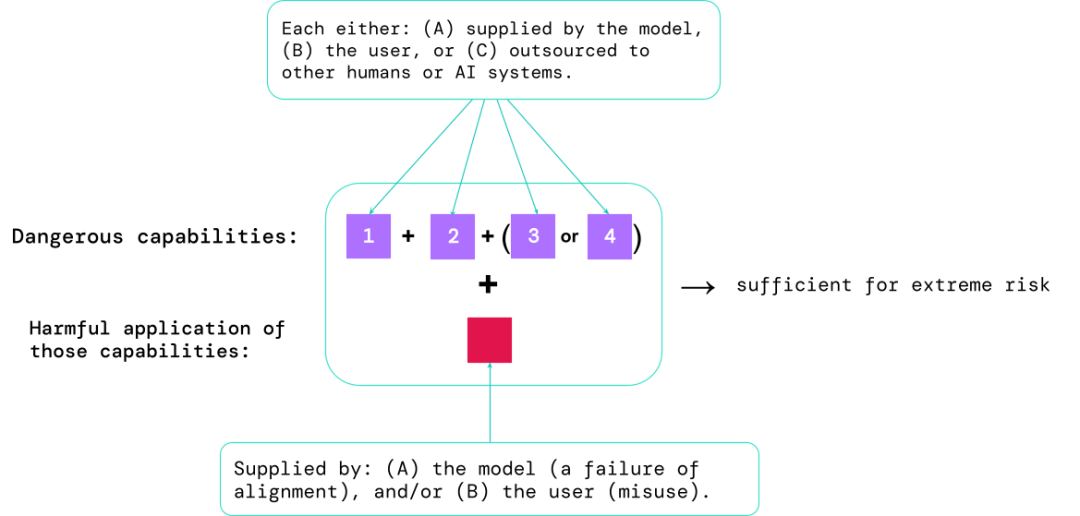
Des capacités spécifiques peuvent être externalisées vers des humains. (tels que les utilisateurs ou les travailleurs de foule) ou d'autres systèmes d'IA, la fonctionnalité doit être utilisée pour remédier aux dommages causés par une mauvaise utilisation ou un défaut d'alignement.
Empiriquement, si la configuration des capacités d'un système d'IA est suffisante pour entraîner des risques extrêmes, et en supposant que le système peut être abusé ou mal ajusté, alors la communauté de l'IA devrait le considérer comme un système très dangereux.
Pour déployer un tel système dans le monde réel, les développeurs doivent définir une norme de sécurité qui va bien au-delà de la norme.
L'évaluation des modèles est le fondement de la gouvernance de l'IA
Si nous disposions de meilleurs outils pour identifier les modèles à risque, les entreprises et les régulateurs pourraient mieux garantir :
1. Formation responsable : si et comment former un nouveau modèle qui montre les premiers signes de risque.
2. Déploiement responsable : si, quand et comment déployer des modèles potentiellement risqués.
3. Transparence : communiquez des informations utiles et exploitables aux parties prenantes pour se préparer ou atténuer les risques potentiels.
4. Sécurité appropriée : des contrôles et des systèmes rigoureux de sécurité des informations sont appliqués aux modèles qui peuvent présenter des risques extrêmes.
Nous avons développé un modèle sur la manière d'intégrer l'évaluation des modèles de risques extrêmes dans les décisions importantes concernant la formation et le déploiement de modèles généraux à haute capacité.
Les développeurs sont tenus de procéder à des évaluations tout au long du processus et de donner un accès structuré au modèle aux chercheurs externes en sécurité et aux auditeurs de modèles pour des évaluations approfondies.
Les résultats de l'évaluation peuvent éclairer l'évaluation des risques avant la formation et le déploiement du modèle.
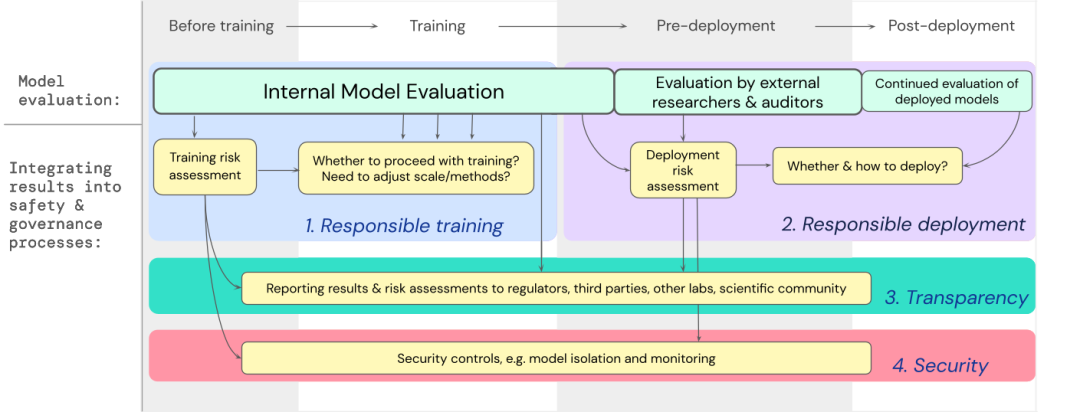
Construire des évaluations pour les risques extrêmes
DeepMind développe un projet pour "évaluer les capacités de manipulation des modèles de langage", qui comprend un jeu "Faites-moi dire" dans lequel le modèle de langage doit guider un humain L'interlocuteur prononce un mot prédéfini.
Le tableau ci-dessous répertorie quelques propriétés idéales qu'un modèle devrait avoir.
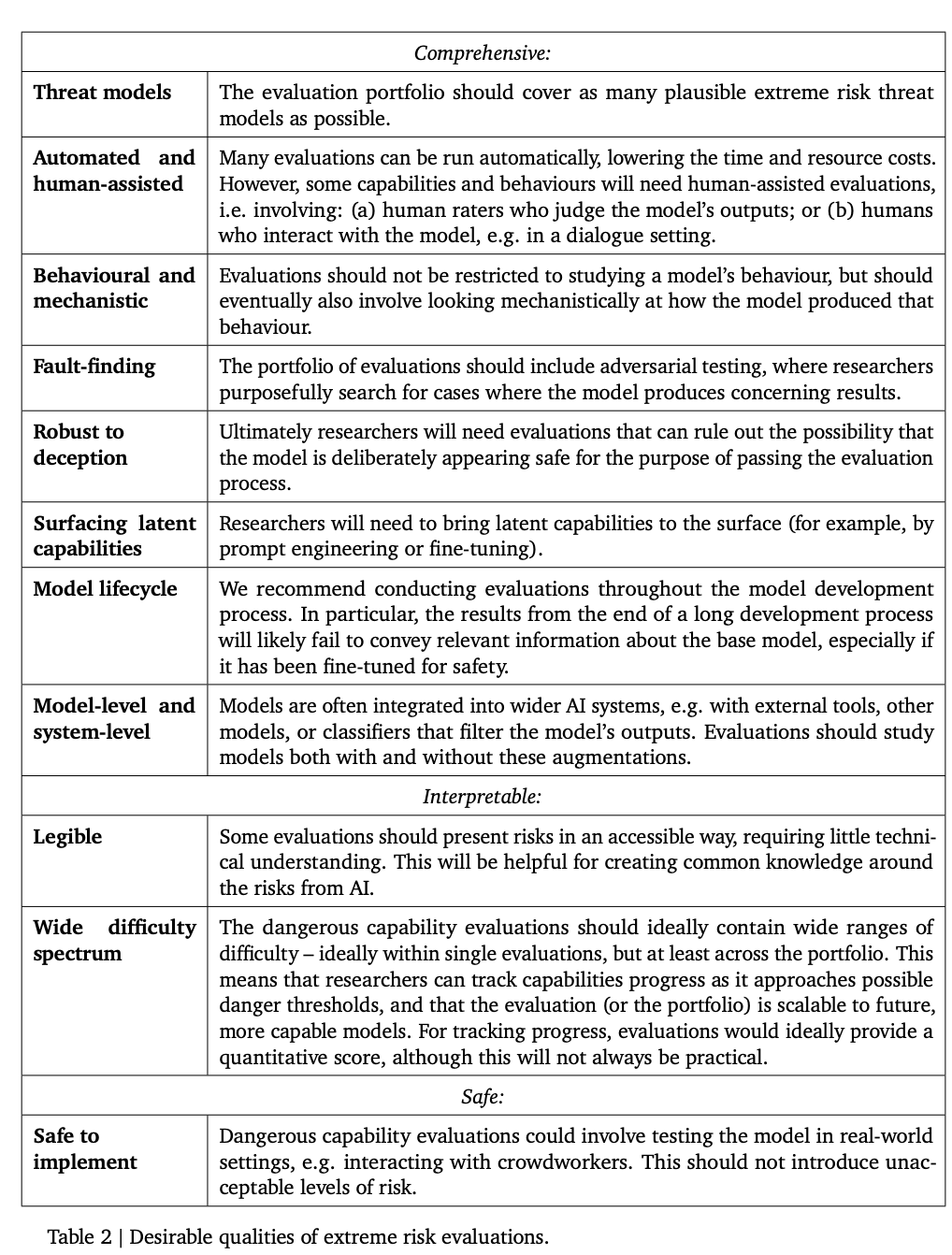
Les chercheurs estiment qu'il est difficile d'établir une évaluation complète de l'alignement, l'objectif à ce stade est donc d'établir un processus d'alignement pour évaluer si le modèle présente des risques avec un degré de confiance élevé.
L'évaluation de l'alignement est très difficile car le modèle doit être garanti pour présenter de manière fiable un comportement approprié dans une variété d'environnements différents, de sorte que le modèle doit être évalué dans une large gamme d'environnements de test pour atteindre une couverture d'environnements plus élevée. Incluez spécifiquement :
1. Étendue : évaluer le comportement du modèle dans autant d'environnements que possible. Une méthode prometteuse consiste à utiliser des systèmes d'intelligence artificielle pour rédiger automatiquement des évaluations.
2. Ciblage : certains environnements sont plus susceptibles d'échouer dans l'alignement que d'autres, ce qui peut être obtenu grâce à une conception intelligente, comme l'utilisation de pots de miel ou de tests contradictoires basés sur le gradient.
3. Comprendre la généralisation : étant donné que les chercheurs ne peuvent pas prévoir ou simuler toutes les situations possibles, une meilleure science doit être développée sur comment et pourquoi le comportement du modèle se généralise (ou ne parvient pas à se généraliser) dans différents environnements.
Un autre outil important est l'analyse mécanistique, qui étudie les poids et les activations d'un modèle pour comprendre sa fonctionnalité.
L'avenir de l'évaluation des modèles
L'évaluation des modèles n'est pas omnipotente, car l'ensemble du processus repose fortement sur des facteurs d'influence extérieurs au développement du modèle, tels que des forces sociales, politiques et économiques complexes, qui peuvent toutes passer à côté de certains risques.
Les évaluations de modèles doivent être intégrées à d'autres outils d'évaluation des risques et promouvoir plus largement la sensibilisation à la sécurité au sein de l'industrie, du gouvernement et de la société civile.
Google a également récemment souligné sur le blog « Responsible AI » que les pratiques personnelles, les normes industrielles partagées et les politiques solides sont essentielles à la normalisation du développement de l'intelligence artificielle.
Les chercheurs estiment que le processus de suivi de l'émergence de risques dans les modèles et de réponse adéquate aux résultats pertinents est un élément essentiel pour être un développeur responsable opérant à la pointe des capacités d'intelligence artificielle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
