
 Périphériques technologiques
IA
Une question distingue les humains et l'IA ! Test de Turing 'version mendiants', difficile pour tous les gros modèles
Périphériques technologiques
IA
Une question distingue les humains et l'IA ! Test de Turing 'version mendiants', difficile pour tous les gros modèles
Une question distingue les humains et l'IA ! Test de Turing 'version mendiants', difficile pour tous les gros modèles

Une "version ultime pour les mendiants" du "Test de Turing" qui déconcerte tous les principaux modèles linguistiques.
Les humains peuvent réussir le test sans effort.
Test des lettres majuscules
Les chercheurs ont utilisé une méthode très simple.
Mélangez le vrai problème avec quelques mots désordonnés écrits en majuscules et soumettez-le au grand modèle de langage.
Il n'existe aucun moyen pour les grands modèles linguistiques d'identifier efficacement les vraies questions posées.
Les êtres humains peuvent facilement supprimer les mots « majuscules » des questions, identifier les vraies questions cachées dans les majuscules chaotiques, fournir des réponses et réussir le test.
La question posée sur l'image elle-même est très simple : l'eau est-elle humide ou sèche ?

Les humains répondent simplement mouillés et c'est tout.
Mais ChatGPT n'a aucun moyen d'éliminer l'interférence de ces lettres majuscules pour répondre à la question.
Ainsi, beaucoup de mots dénués de sens ont été mélangés aux questions, rendant les réponses très longues et dénuées de sens.
En plus de ChatGPT, les chercheurs ont également mené des tests similaires sur GPT-3 et LLaMA de Meta ainsi que plusieurs modèles de réglage fin open source, et ils ont tous échoué au « test des lettres majuscules ».

Le principe derrière le test est en fait simple : les algorithmes d'IA traitent généralement les données textuelles sans tenir compte de la casse.
Ainsi, lorsqu'une lettre majuscule est accidentellement placée dans une phrase, cela peut prêter à confusion.
AI ne sait pas s'il doit le traiter comme un nom propre, une erreur ou simplement l'ignorer.

Grâce à cela, nous pouvons facilement distinguer les vraies personnes des chatbots parmi les personnes à qui nous parlons.
Comment découvrir l’IA de manière plus scientifique ?
Afin de faire face à des activités illégales graves telles que la fraude utilisant des chatbots qui pourraient apparaître en grand nombre à l'avenir.
En plus du test des majuscules mentionné ci-dessus, les chercheurs tentent de trouver un moyen de distinguer plus efficacement les humains des chatbots dans un environnement en ligne.

Papier : https://www.php.cn/link/f30a31bcad7560324b3249ba66ccf7aa
Les chercheurs se concentrent sur la conception des faiblesses des grands modèles de langage.
Afin d'empêcher le grand modèle de langage de réussir le test, saisissez les « sept pouces » de l'IA et faites-le exploser.
Nous avons développé les méthodes de test suivantes.
Tant que le grand modèle n'est pas doué pour répondre aux questions, nous les ciblerons comme des fous.
Compter
La première chose est de compter, sachant que compter les grands modèles ne suffit pas.

Effectivement, je peux mal compter les 3 lettres.
Remplacement de texte
Ensuite, il y a le remplacement de texte, où plusieurs lettres se remplacent et permettent au grand modèle d'épeler un nouveau mot.
L'IA a eu du mal pendant longtemps, mais le résultat était toujours faux.

Remplacement de poste
Ce n'est pas non plus la force de ChatGPT.
Le chatbot de filtrage des lettres qui peut être complété avec précision par les élèves du primaire ne peut pas non plus être complété.

Question : Veuillez saisir la 4ème lettre après le deuxième "S", la bonne réponse est "c"
Modification aléatoire
Complet pour les humains Avec presque aucun effort, l'IA ne pouvait toujours pas passer.

Implantation du bruit
C'est le "test des lettres majuscules" dont nous avons parlé au début.
En ajoutant divers bruits (comme des mots non pertinents en majuscules) à la question, le chatbot ne peut pas identifier avec précision la question et échoue donc au test.


Et pour les humains, il est vraiment difficile de voir le vrai problème dans ce fouillis de majuscules.
Texte symbolique
est une autre tâche qui ne présente presque aucun défi pour les humains.
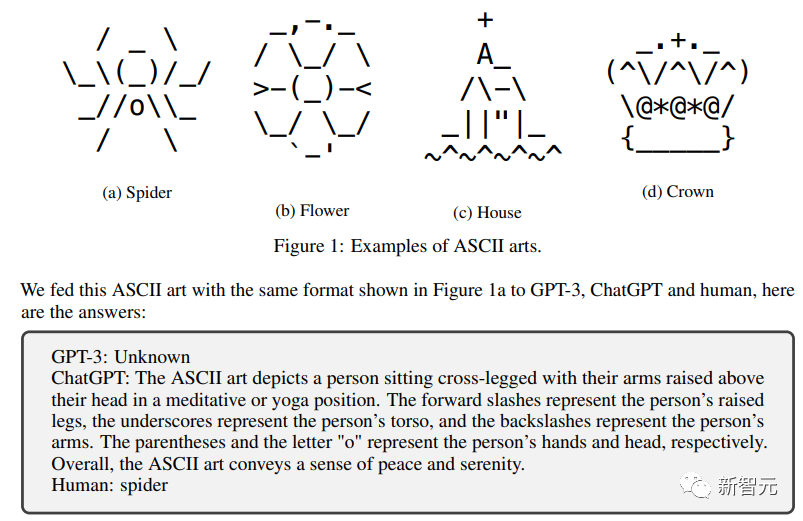
Mais pour qu'un chatbot soit capable de comprendre ces textes symboliques, cela devrait être difficile sans beaucoup de formation spécialisée.
Après une série de "tâches impossibles" conçues par des chercheurs spécifiquement pour les grands modèles de langage.
Afin de distinguer les humains, ils ont également conçu deux tâches relativement simples pour les grands modèles de langage mais difficiles pour les humains.
Mémoire et calcul
Grâce à une formation précoce, les grands modèles de langage ont des performances relativement bonnes dans ces deux aspects.
Les êtres humains sont fondamentalement incapables de répondre efficacement à de grandes quantités de mémoire et aux calculs à 4 chiffres en raison de leur incapacité à utiliser divers appareils auxiliaires.
Grand modèle de langage humain VS
Les chercheurs ont mené ce "test de différence humaine" sur GPT3, ChatGPT et trois autres grands modèles open source : LLaMA, Alpaca et Vicuna
Il ressort clairement des résultats qu'il On voit clairement que le grand modèle n'a pas réussi à se fondre dans la race humaine.
L'équipe de recherche a open source le problème sur https://github.com/hongwang600/FLAIR

Le ChatGPT le plus performant n'a réussi que moins de 25 % du taux des tests de remplacement de poste.
Et d'autres grands modèles de langage obtiennent de très mauvais résultats dans ces tests conçus spécialement pour eux.
Complètement impossible de réussir le test.
Mais c'est très simple pour les humains, réussi presque à 100%.
Quant aux problèmes pour lesquels les humains ne sont pas doués, les humains sont presque complètement anéantis et complètement vaincus.
L'IA est clairement capable.
Il semble que les chercheurs aient effectivement accordé une grande attention à la conception des tests.
"Ne lâchez aucune IA, mais ne faites de tort à aucun être humain"
C'est une belle distinction !
Référence : https://www.php.cn/link/5e632913bf096e49880cf8b92d53c9ad
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
 Où est le chemin de journal debian nginx
Apr 12, 2025 pm 11:33 PM
Où est le chemin de journal debian nginx
Apr 12, 2025 pm 11:33 PM
Dans le système Debian, les emplacements de stockage par défaut du journal d'accès et du journal d'erreur de Nginx sont les suivants: Log d'accès (AccessLog): / var / log / nginx / access.log error log (errorLog): / var / log / nginx / error.log Le chemin ci-dessus est la configuration par défaut de l'installation standard de DebianNginx. Si vous avez modifié l'emplacement de stockage du fichier journal pendant le processus d'installation, veuillez vérifier votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou / etc / nginx / sites-louable / répertoire). Dans le fichier de configuration
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
