
 Périphériques technologiques
IA
Dernière interview avec le fondateur d'OpenAI, Sam Altman : GPT-3 ou open source, les règles de mise à l'échelle accélèrent la construction de l'AGI
Périphériques technologiques
IA
Dernière interview avec le fondateur d'OpenAI, Sam Altman : GPT-3 ou open source, les règles de mise à l'échelle accélèrent la construction de l'AGI
Dernière interview avec le fondateur d'OpenAI, Sam Altman : GPT-3 ou open source, les règles de mise à l'échelle accélèrent la construction de l'AGI

Big Data Digest Produced
« Nous sommes très à court de GPU »
Dans une récente interview, Sam Altman, le responsable d'OpenAI, a répondu à la question de l'hôte à propos de " Ce dont je ne suis pas satisfait, c'est la fiabilité et la rapidité de l'API. "
Cette interview vient de Raza Habib, PDG de la startup d'intelligence artificielle Humanloop. Il a compilé les moments forts de l'interview sur Twitter.
Adresse Twitter :
https://twitter.com/dr_cintas/status/1664281914948337664
 # 🎜 🎜#
# 🎜 🎜#
 Dans l'interview, Altman a également mentionné qu'ils envisageaient d'ouvrir GPT-3 en source ouverte, et là Il ne fait aucun doute que ce sera open source est très important. Dans le même temps, il a également déclaré que les modèles d’IA actuels ne sont pas si dangereux. Même s’il est très important de réglementer les modèles futurs, l’interdiction du développement est une très grande idée fausse.
Dans l'interview, Altman a également mentionné qu'ils envisageaient d'ouvrir GPT-3 en source ouverte, et là Il ne fait aucun doute que ce sera open source est très important. Dans le même temps, il a également déclaré que les modèles d’IA actuels ne sont pas si dangereux. Même s’il est très important de réglementer les modèles futurs, l’interdiction du développement est une très grande idée fausse.
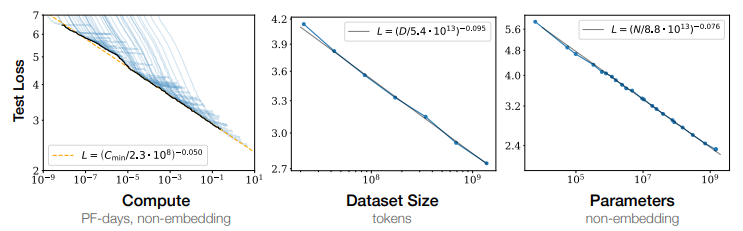
Scaling Laws, le nom anglais est Scaling Laws, est une description du phénomène, qui fait généralement référence à : l'effet du modèle de langage Il s'agit essentiellement d'une loi de puissance lisse avec la quantité de paramètres, de données et de calculs.
En d'autres termes, à mesure que le nombre de paramètres du modèle (Paramètres), la quantité de données impliquées dans la formation (Tokens) et la quantité de calcul accumulée dans le processus de formation (FLOPS) augmentent de façon exponentielle , le modèle fonctionne mieux sur l'ensemble de test. La perte diminue linéairement, ce qui signifie que le modèle fonctionne mieux.

Légende : La performance empirique est présentée avec chaque facteur individuel lorsqu'elle n'est pas contrainte par les deux autres facteurs Une relation de loi de puissance émerge.
En 2022, DeepMind a mené une analyse plus approfondie dans ScalingLaw. La recherche a vérifié grâce à des expériences quantitatives que la taille des données de formation du modèle linguistique doit être agrandie proportionnellement à la taille des paramètres du modèle. Lorsque la quantité totale de calcul reste inchangée, l'effet de la formation du modèle a un point d'équilibre optimal entre la taille du paramètre et la quantité de données de formation. Le point le plus bas sous la courbe est un très bon compromis entre la taille du paramètre et la quantité de données de formation. indiquer.
 Le succès d'OpeaAI et GPT-4
Le succès d'OpeaAI et GPT-4
En 2019, OpenAI s'est transformé en laboratoire de recherche en intelligence artificielle à but lucratif pour absorber les fonds des investisseurs.
Alors qu'il ne reste plus au laboratoire que très peu d'argent pour soutenir ses recherches, Microsoft a annoncé qu'il investirait 1 milliard de dollars supplémentaires dans le laboratoire.
Chaque version de la série GPT lancée par OpenAI peut provoquer un carnaval dans l'industrie. Lors de la conférence des développeurs Microsoft Build 2023, le fondateur d'OpenAI, Andrej Karpthy, a prononcé un discours : État du GPT (La situation actuelle du GPT). , affirmant qu’ils ont formé de grands modèles en tant que « cerveaux humains ».
Andrej a mentionné que le grand modèle de langage LLM actuel peut être comparé au système 1 (système rapide) du mode de pensée humaine, qui est comparé au système 2 (système lent) qui répond lentement mais a un fonctionnement à plus long terme. raisonnement.
« Le système un est un processus automatique rapide qui, je pense, correspond en quelque sorte au LLM, il suffit d'échantillonner les jetons
Le système deux est le processus le plus lent et le plus délibéré dans le cerveau. La partie plan.
Le projet prompt espère essentiellement restaurer certaines des capacités de notre cerveau "
Andrej Karpthy a également mentionné que GPT-4 est un artefact incroyable. et il était très reconnaissant de son existence. Il possède une tonne de connaissances dans de nombreux domaines, il peut faire des mathématiques, du code et bien plus encore, à portée de main.
Le PDG Altman a déclaré qu'au début, GPT-4 était très lent, avait des bugs et faisait beaucoup de choses mal. Mais il en a été de même pour les premiers ordinateurs, qui ouvraient encore la voie à quelque chose qui allait devenir très important dans nos vies, même si son développement prenait des décennies.
Il semble qu'OpenAI soit une organisation qui insiste sur les rêves et qui veut faire les choses à l'extrême.
Comme l'a mentionné Zhou Ming, ancien vice-président de Microsoft Research Asia et fondateur de Lanzhou Technology, dans une interview :
#🎜 🎜# La plus grande réussite d'OpenAI est d'atteindre la perfection dans tous les aspects et est un modèle d'innovation intégrée. Il existe plusieurs types de personnes dans le monde, et certaines personnes souhaitent simplement étudier l'innovation sous-jacente. Certaines sont des applications basées sur des innovations sous-jacentes, tandis que les applications générales visent à résoudre une seule tâche. Il peut être réécrit ainsi : Une autre approche consiste à parvenir à une innovation intégrée, en concentrant tous les travaux, applications et algorithmes sur une grande plate-forme pour créer des jalons. Il se trouve qu’OpenAI fait un très bon travail d’intégration de l’innovation.Référence : https:// mp.weixin.qq.com/s/p42pBVyjZws8XsstDoR2Jw https://mp.weixin.qq.com/s/zmEGzm1cdXupNoqZ65h7yg https://weibo.com/1727858283/4907695679472174?wm=3333_2001&from=10D5 293 010&sourcetype=weixin&s_trans=6289897940_4907695679472174&s_channel=4 https://humanloop.com/blog/openai-plans?cnotallow=bd9e76a5f41a6d847de52fa275480e22
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment vérifier rapidement la version numpy
Jan 19, 2024 am 08:23 AM
Comment vérifier rapidement la version numpy
Jan 19, 2024 am 08:23 AM
Numpy est une bibliothèque mathématique importante en Python. Elle fournit des opérations de tableau efficaces et des fonctions de calcul scientifique et est largement utilisée dans l'analyse de données, l'apprentissage automatique, l'apprentissage profond et d'autres domaines. Lors de l'utilisation de numpy, nous devons souvent vérifier le numéro de version de numpy pour déterminer les fonctions prises en charge par l'environnement actuel. Cet article explique comment vérifier rapidement la version numpy et fournit des exemples de code spécifiques. Méthode 1 : utilisez l'attribut __version__ fourni avec numpy Le module numpy est livré avec un __.
 Comment vérifier la version de Maven
Jan 17, 2024 pm 05:06 PM
Comment vérifier la version de Maven
Jan 17, 2024 pm 05:06 PM
Méthodes pour vérifier la version maven : 1. Utilisez la ligne de commande ; 2. Vérifiez les variables d'environnement 3. Utilisez l'IDE 4. Vérifiez le fichier pom.xml ; Introduction détaillée : 1. Utilisez la ligne de commande, entrez « mvn -v » ou « mvn --version » dans la ligne de commande, puis appuyez sur Entrée. Cela affichera les informations sur la version Maven et les informations sur la version Java. 2. Affichez l'environnement. variables , sur certains systèmes, vous pouvez vérifier les variables d'environnement pour trouver les informations de version de Maven, saisir la commande sur la ligne de commande, puis appuyer sur Entrée, etc.
 Tutoriel sur la mise à jour de la version curl sous Linux !
Mar 07, 2024 am 08:30 AM
Tutoriel sur la mise à jour de la version curl sous Linux !
Mar 07, 2024 am 08:30 AM
Pour mettre à jour la version curl sous Linux, vous pouvez suivre les étapes ci-dessous : Vérifiez la version actuelle de curl : Tout d'abord, vous devez déterminer la version de curl installée dans le système actuel. Ouvrez un terminal et exécutez la commande suivante : curl --version Cette commande affichera les informations sur la version actuelle de curl. Confirmer la version curl disponible : Avant de mettre à jour curl, vous devez confirmer la dernière version disponible. Vous pouvez visiter le site officiel de curl (curl.haxx.se) ou des sources de logiciels associées pour trouver la dernière version de curl. Téléchargez le code source de curl : à l'aide de curl ou d'un navigateur, téléchargez le fichier de code source pour la version curl de votre choix (généralement .tar.gz ou .tar.bz2).
 Comment vérifier facilement la version installée d'Oracle
Mar 07, 2024 am 11:27 AM
Comment vérifier facilement la version installée d'Oracle
Mar 07, 2024 am 11:27 AM
Comment vérifier facilement la version installée d'Oracle nécessite des exemples de code spécifiques. En tant que logiciel largement utilisé dans les systèmes de gestion de bases de données au niveau de l'entreprise, la base de données Oracle possède de nombreuses versions et différentes méthodes d'installation. Dans notre travail quotidien, nous devons souvent vérifier la version installée de la base de données Oracle pour les opérations et la maintenance correspondantes. Cet article explique comment vérifier facilement la version installée d'Oracle et donne des exemples de code spécifiques. Méthode 1 : Grâce à une requête SQL dans la base de données Oracle, nous pouvons
 Vérifiez la version du système d'exploitation Kirin et la version du noyau
Feb 21, 2024 pm 07:04 PM
Vérifiez la version du système d'exploitation Kirin et la version du noyau
Feb 21, 2024 pm 07:04 PM
Vérification de la version du système d'exploitation Kylin et de la version du noyau Dans le système d'exploitation Kirin, savoir comment vérifier la version du système et la version du noyau est la base de la gestion et de la maintenance du système. Méthode 1 pour vérifier la version du système d'exploitation Kylin : Utilisez le fichier /etc/.kyinfo Pour vérifier la version du système d'exploitation Kylin, vous pouvez vérifier le fichier /etc/.kyinfo. Ce fichier contient des informations sur la version du système d'exploitation. Exécutez la commande suivante : cat/etc/.kyinfo Cette commande affichera des informations détaillées sur la version du système d'exploitation. Méthode 2 : utiliser le fichier /etc/issue Une autre façon de vérifier la version du système d'exploitation consiste à consulter le fichier /etc/issue. Ce fichier fournit également des informations sur la version, mais peut ne pas être aussi bon que le fichier .kyinfo.
 Étapes simples pour mettre à jour la version pip : effectuée en 1 minute
Jan 27, 2024 am 09:45 AM
Étapes simples pour mettre à jour la version pip : effectuée en 1 minute
Jan 27, 2024 am 09:45 AM
Fait en une minute : Comment mettre à jour la version pip, des exemples de code spécifiques sont nécessaires Avec le développement rapide de Python, pip est devenu un outil standard pour la gestion des packages Python. Cependant, au fil du temps, les versions de pip sont constamment mises à jour. Afin de pouvoir utiliser les dernières fonctionnalités et corriger d'éventuelles failles de sécurité, il est très important de mettre à jour la version de pip. Cet article explique comment mettre à jour rapidement pip en une minute et fournit des exemples de code spécifiques. Tout d’abord, nous devons ouvrir une fenêtre de ligne de commande. Dans les systèmes Windows, vous pouvez utiliser
 750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
Concernant Llama3, de nouveaux résultats de tests ont été publiés - la grande communauté d'évaluation de modèles LMSYS a publié une liste de classement des grands modèles, Llama3 s'est classé cinquième et à égalité pour la première place avec GPT-4 dans la catégorie anglaise. Le tableau est différent des autres benchmarks. Cette liste est basée sur des batailles individuelles entre modèles, et les évaluateurs de tout le réseau font leurs propres propositions et scores. Au final, Llama3 s'est classé cinquième sur la liste, suivi de trois versions différentes de GPT-4 et Claude3 Super Cup Opus. Dans la liste simple anglaise, Llama3 a dépassé Claude et est à égalité avec GPT-4. Concernant ce résultat, LeCun, scientifique en chef de Meta, était très heureux et a transmis le tweet et
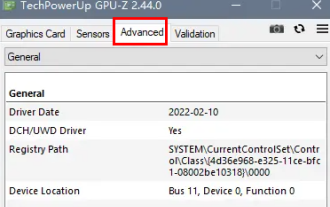 Comment savoir si l'interface dp est 1.2 ou 1.4 ?
Feb 06, 2024 am 10:27 AM
Comment savoir si l'interface dp est 1.2 ou 1.4 ?
Feb 06, 2024 am 10:27 AM
L'interface DP est un câble d'interface important dans l'ordinateur. Lors de l'utilisation de l'ordinateur, de nombreux utilisateurs veulent savoir comment vérifier si l'interface DP est 1.2 ou 1.4. En fait, il leur suffit de la vérifier dans GPU-Z. Comment déterminer si l'interface dp est 1.2 ou 1.4 : 1. Tout d'abord, sélectionnez "Avancé" dans GPU-Z. 2. Regardez « Monitor1 » dans « General » sous « Advanced », vous pouvez voir les deux éléments « LinkRate (current) » et « Lanes (current) ». 3. Enfin, si 8,1 Gbps × 4 est affiché, cela signifie la version DP1.3 ou supérieure, généralement DP1.4. S'il s'agit de 5,4 Gbps × 4, alors.
