

Des capacités de grands modèles émergent. Plus l’échelle des paramètres est grande, mieux c’est ?
Cependant, un nombre croissant de chercheurs affirment que les modèles inférieurs à 10B peuvent également atteindre des performances comparables à celles de GPT-3.5.
Est-ce vraiment le cas ?
Dans le blog d'OpenAI publiant GPT-4, il a été mentionné :
Dans des conversations informelles, la différence entre GPT-3.5 et GPT-4 peut être très subtile. Des différences apparaissent lorsque la complexité de la tâche atteint un seuil suffisant : GPT-4 est plus fiable, plus créatif et capable de gérer des instructions plus nuancées que GPT-3.5.
Les développeurs de Google ont également fait des observations similaires sur le modèle PaLM. Ils ont constaté que la capacité de raisonnement en chaîne de pensée du grand modèle était nettement plus forte que celle du petit modèle.
Ces observations montrent toutes que la capacité à effectuer des tâches complexes est la clé pour incarner les capacités des grands modèles.
Tout comme le vieil adage, les modèles et les programmeurs sont les mêmes : "Arrête de dire des bêtises, montre-moi le raisonnement".

Des chercheurs de l'Université d'Édimbourg, de l'Université de Washington et de l'Allen AI Institute estiment que les capacités de raisonnement complexes constituent la base du développement futur de grands modèles en outils plus intelligents.
Capacité de base de synthèse de texte, l'exécution de grands modèles est en effet une « mise à mort de la poule dans le mille ».
L'évaluation de ces capacités de base semble un peu peu professionnelle pour étudier le développement futur des grands modèles.
Adresse papier : https://arxiv.org/pdf/2305.17306.pdf
C'est pourquoi les chercheurs ont compilé une liste de tâches d'inférence complexe, Chain-of-Thought Hub, pour mesurer les performances du modèle dans des tâches d'inférence difficiles.
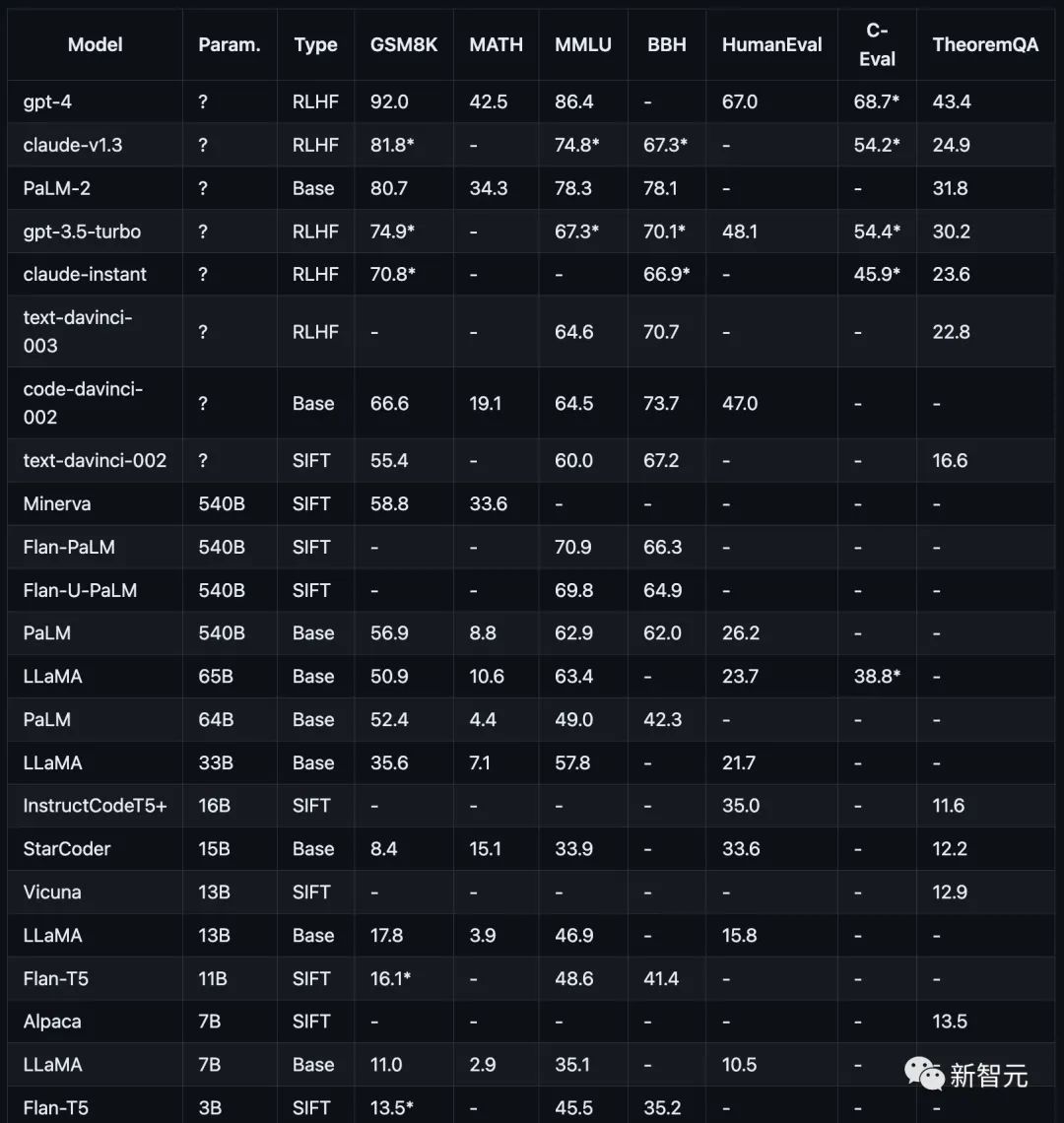
Les éléments du test comprennent les mathématiques (GSM8K)), les sciences (MATH, théorème QA), les symboles (BBH), les connaissances (MMLU, C-Eval), le codage (HumanEval).
Ces projets de test ou ensembles de données visent tous les capacités de raisonnement complexes des grands modèles. Il n'existe pas de tâche simple à laquelle quiconque puisse répondre avec précision.
Les chercheurs utilisent toujours la méthode COT Prompt pour évaluer la capacité de raisonnement du modèle.
Pour le test de capacité de raisonnement, les chercheurs utilisent uniquement la performance de la réponse finale comme seul critère de mesure, et les étapes de raisonnement intermédiaires ne sont pas utilisées comme base de jugement.
Comme le montre la figure ci-dessous, les performances des modèles traditionnels actuels sur différentes tâches de raisonnement.
Les recherches des chercheurs se concentrent sur les modèles actuellement populaires, notamment la famille de modèles GPT, Claude, PaLM, LLaMA et T5, en particulier :
OpenAI GPT comprend GPT-4 (actuellement le plus puissant), GPT3.5-Turbo (plus rapide, mais plus faible), text-davinci-003, text-davinci-002 et code-davinci-002 (avant la version importante de Turbo) .

Anthropic Claude inclut claude-v1.3 (plus lent mais plus performant) et claude-instant-v1.0 (plus rapide mais moins performant).
Google PaLM, y compris PaLM, PaLM-2 et leurs versions ajustées en fonction des instructions (FLan-PaLM et Flan-UPaLM), une base solide et des modèles ajustés en fonction des instructions.

Meta LLaMA, comprenant les variantes 7B, 13B, 33B et 65B, modèle de base open source important.
GPT-4 surpasse considérablement tous les autres modèles sur GSM8K et MMLU, tandis que Claude est le seul comparable à la série GPT.
Les modèles plus petits tels que le FlanT5 11B et le LLaMA 7B sont loin derrière.
Grâce à des expériences, les chercheurs ont découvert que les performances du modèle sont généralement liées à l'échelle, montrant une tendance linéaire à peu près logarithmique.
Les modèles qui ne divulguent pas les échelles de paramètres fonctionnent généralement mieux que les modèles qui divulguent les informations sur l'échelle.
De plus, les chercheurs ont souligné que la communauté open source devra peut-être encore explorer les « fossés » concernant l'échelle et le RLHF pour de nouvelles améliorations.
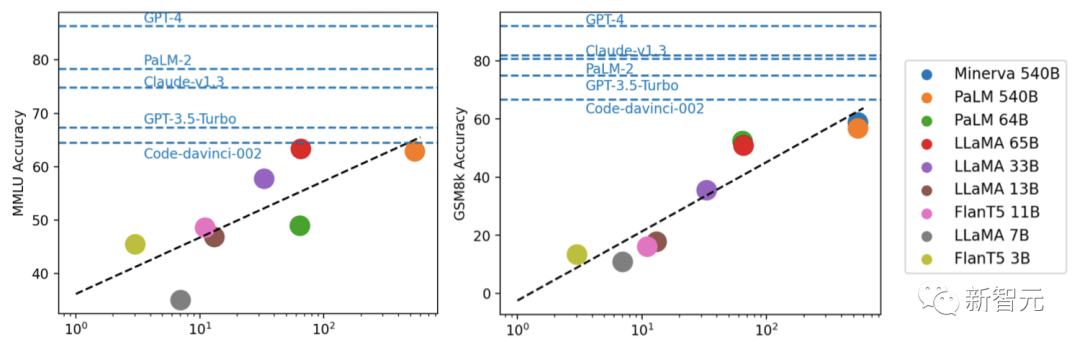
Fu Yao, le premier auteur de l'article, a conclu :
1 Il existe un écart évident entre l'open source et le fermé.
2. La plupart des modèles grand public les mieux classés sont RLHF
3 est très proche du code-davinci-002, le modèle de base de GPT-3.5
4. ce qui précède, le plus La direction de l'espoir est de "faire du RLHF sur LLaMA 65B".

Pour ce projet, l'auteur explique d'autres optimisations à l'avenir :
À l'avenir, davantage d'ensembles de données de raisonnement, y compris des ensembles de données plus soigneusement sélectionnés, seront ajoutés, notamment pour mesurer le raisonnement de bon sens. et les théorèmes mathématiques des ensembles de données.
et la possibilité d'appeler des API externes.
Ce qui est plus important est d'inclure davantage de modèles de langage, tels que des modèles de réglage fin des instructions basés sur LLaMA, tels que Vicuna7 et d'autres modèles open source.
Vous pouvez également accéder aux capacités de modèles tels que PaLM-2 via l'API comme Cohere 8.
En bref, l'auteur estime que ce projet peut jouer un grand rôle en tant qu'installation de bien-être public pour évaluer et guider le développement de grands modèles de langage open source.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



