
 Périphériques technologiques
IA
Le « RL » dans RLHF est-il obligatoire ? Certaines personnes utilisent l'entropie croisée binaire pour affiner directement le LLM, et l'effet est meilleur.
Périphériques technologiques
IA
Le « RL » dans RLHF est-il obligatoire ? Certaines personnes utilisent l'entropie croisée binaire pour affiner directement le LLM, et l'effet est meilleur.
Le « RL » dans RLHF est-il obligatoire ? Certaines personnes utilisent l'entropie croisée binaire pour affiner directement le LLM, et l'effet est meilleur.

Récemment, des modèles de langage non supervisés formés sur de grands ensembles de données ont atteint des capacités surprenantes. Cependant, ces modèles sont formés sur des données générées par des humains avec une variété d’objectifs, de priorités et de compétences, dont certains ne sont pas nécessairement imités.
Sélectionner les réponses et les comportements souhaités d'un modèle à partir de ses connaissances et capacités très larges est essentiel pour créer des systèmes d'IA sûrs, performants et contrôlables. De nombreuses méthodes existantes inculquent les comportements souhaités dans les modèles de langage en utilisant des ensembles de préférences humaines soigneusement sélectionnés qui représentent les types de comportements que les humains considèrent comme sûrs et bénéfiques. Cette étape d'apprentissage des préférences se produit sur de grands ensembles de données textuelles après une phase initiale de pré-apprentissage non supervisé à grande échelle. -entraînement.
Bien que la méthode d'apprentissage des préférences la plus simple soit le réglage fin supervisé des réponses de haute qualité démontrées par les humains, une classe de méthodes relativement populaire récemment est l'apprentissage par renforcement à partir du feedback humain (ou de l'intelligence artificielle) (RLHF/RLAIF). L'approche RLHF associe un modèle de récompense à un ensemble de données de préférences humaines, puis utilise RL pour optimiser une politique de modèle de langage afin de produire des réponses qui attribuent des récompenses élevées sans s'écarter excessivement du modèle d'origine.
Alors que RLHF produit des modèles dotés de capacités conversationnelles et de codage impressionnantes, le pipeline RLHF est beaucoup plus complexe que l'apprentissage supervisé, impliquant la formation de plusieurs modèles de langage et l'échantillonnage de politiques de modèles de langage dans une boucle entraînée, ce qui entraîne des coûts de calcul élevés.
Et une étude récente montre que : L'objectif basé sur RL utilisé par les méthodes existantes peut être optimisé avec précision avec un simple objectif d'entropie croisée binaire, simplifiant ainsi considérablement le pipeline d'apprentissage des préférences. C'est-à-dire qu'il est tout à fait possible d'optimiser directement les modèles de langage pour adhérer aux préférences humaines sans avoir besoin de modèles de récompense explicites ou d'apprentissage par renforcement.

Des chercheurs de l'Université de Stanford et d'autres institutions ont proposé l'optimisation des préférences directes (DPO), cet algorithme optimise implicitement le même objectif que l'algorithme RLHF existant (maximisation des récompenses avec KL - contraintes de divergence), mais est simple à mettre en œuvre et directement entraînable.
Les expériences montrent que le DPO est au moins aussi efficace que les méthodes existantes, y compris le RLHF basé sur le PPO, lorsqu'il est utilisé pour des tâches d'apprentissage des préférences telles que la régulation des émotions, la synthèse et le dialogue avec 6 milliards de modèles de langage de paramètres.
Algorithme DPOComme les algorithmes existants, DPO s'appuie également sur des modèles de préférences théoriques (tels que le modèle Bradley-Terry) pour mesurer dans quelle mesure une fonction de récompense donnée correspond aux données de préférence empiriques. Cependant, les méthodes existantes utilisent un modèle de préférence pour définir une perte de préférence afin de former un modèle de récompense, puis former une politique qui optimise le modèle de récompense appris, tandis que DPO utilise des changements de variables pour définir directement la perte de préférence en fonction de la politique. Compte tenu de l'ensemble de données de préférences humaines pour les réponses du modèle, DPO peut donc optimiser la politique en utilisant un simple objectif d'entropie croisée binaire sans avoir besoin d'apprendre explicitement une fonction de récompense ou un échantillon de la politique pendant la formation. La mise à jour de
DPO augmente la probabilité logarithmique relative des réponses préférées par rapport aux réponses non préférées, mais elle inclut un poids d'importance dynamique par échantillon pour éviter la dégradation du modèle, ce que les chercheurs ont découvert sur une cible de rapport de probabilité naïve.
Afin de comprendre le DPO de manière mécaniste, il est utile d'analyser le gradient de la fonction de perte
. Le gradient par rapport au paramètre θ peut s'écrire :où L'important est que le poids de ces échantillons est déterminé par l'évaluation du modèle de récompense implicite Dans le chapitre 5 de l'article, le chercheur explique plus en détail la méthode DPO, fournit un soutien théorique et relie les avantages du DPO aux problèmes des algorithmes acteur-critique (tels que PPO) pour RLHF. Des détails spécifiques peuvent être trouvés dans le document original. Dans l'expérience, les chercheurs ont évalué la capacité des DPO à former des politiques directement basées sur les préférences. Tout d'abord, dans un environnement de génération de texte bien contrôlé, ils ont examiné la question : par rapport aux algorithmes d'apprentissage des préférences courants tels que PPO, DPO fait un compromis entre l'efficacité de la maximisation des récompenses et la minimisation de la divergence KL dans la politique de référence, comment ? Nous avons ensuite évalué les performances du DPO sur des modèles plus grands et des tâches RLHF plus difficiles, y compris la synthèse et le dialogue. J'ai finalement découvert qu'avec presque aucun réglage des hyperparamètres, DPO fonctionne souvent aussi bien, voire mieux, que des lignes de base puissantes telles que RLHF avec PPO, tout en renvoyant le meilleur N sous la fonction de récompense apprise. Résultats de la trajectoire d'échantillonnage. En termes de tâches, les chercheurs ont exploré trois tâches différentes de génération de texte ouvertes. Dans toutes les expériences, l'algorithme apprend les politiques à partir de l'ensemble de données de préférences 
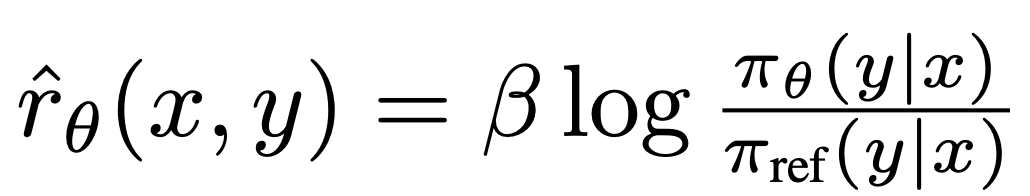 est la récompense implicitement définie par le modèle de langage
est la récompense implicitement définie par le modèle de langage 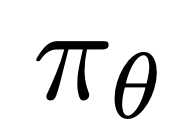 et le modèle de référence
et le modèle de référence 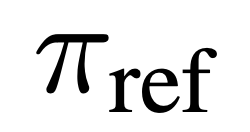 . Intuitivement, le gradient de la fonction de perte
. Intuitivement, le gradient de la fonction de perte  augmente la probabilité d'achèvement préféré y_w et diminue la probabilité d'achèvement non préféré y_l.
augmente la probabilité d'achèvement préféré y_w et diminue la probabilité d'achèvement non préféré y_l. 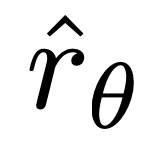 du degré d'achèvement détesté, avec β comme échelle, c'est-à-dire le classement du degré d'achèvement du modèle de récompense implicite has Beaucoup sont incorrects. Cela reflète également la force de la contrainte KL. Les expériences démontrent l’importance de cette pondération, car une version naïve de cette méthode sans coefficients de pondération conduit à une dégradation du modèle de langage (tableau 2 en annexe).
du degré d'achèvement détesté, avec β comme échelle, c'est-à-dire le classement du degré d'achèvement du modèle de récompense implicite has Beaucoup sont incorrects. Cela reflète également la force de la contrainte KL. Les expériences démontrent l’importance de cette pondération, car une version naïve de cette méthode sans coefficients de pondération conduit à une dégradation du modèle de langage (tableau 2 en annexe). Expérience
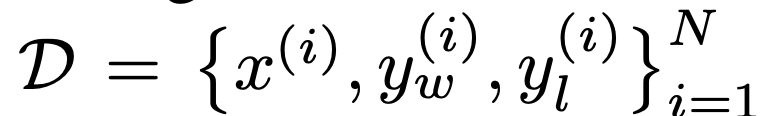 .
.
Dans la génération d'émotions contrôlée, x est le préfixe des critiques de films de l'ensemble de données IMDb et la politique doit générer y avec une émotion positive. Pour une évaluation comparative, l'expérience utilise un classificateur de sentiments pré-entraîné pour générer des paires de préférences, où 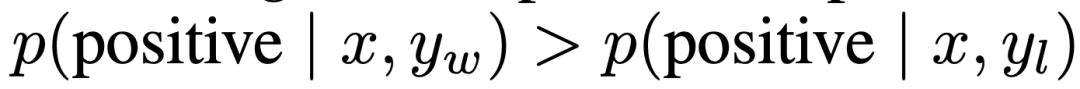 .
.
Pour SFT, les chercheurs ont affiné GPT-2-large jusqu'à ce qu'il converge vers les commentaires de la division d'entraînement de l'ensemble de données IMDB. En résumé, x est un message de forum de Reddit, et la stratégie doit générer un résumé des points clés du message. S'appuyant sur des travaux antérieurs, les expériences ont utilisé l'ensemble de données récapitulatives Reddit TL; DR et les préférences humaines collectées par Stiennon et al. Les expériences ont également utilisé un modèle SFT affiné basé sur des résumés d’articles de forum écrits par des humains 2 et le cadre TRLX de RLHF. L'ensemble de données sur les préférences humaines est un échantillon collecté à partir d'un modèle SFT différent mais formé de manière similaire par Stiennon et al.
Enfin, dans une conversation à tour de rôle, x est une question humaine qui peut aller de l'astrophysique aux conseils relationnels. Une politique doit fournir une réponse intéressante et utile à la requête de l'utilisateur ; la politique doit fournir une réponse intéressante et utile à la requête de l'utilisateur ; l'expérience utilise l'ensemble de conversations Anthropic utile et inoffensif, qui contient 170 000 conversations entre des assistants humains et automatisés. Chaque texte se termine par une paire de réponses générées par un modèle de langage étendu (bien qu'inconnu) et une étiquette de préférence représentant la réponse préférée de l'homme. Dans ce cas, aucun modèle SFT pré-entraîné n'est disponible. Par conséquent, les expériences affinent les modèles de langage disponibles dans le commerce uniquement sur les complétions préférées pour former des modèles SFT.
Les chercheurs ont utilisé deux méthodes d'évaluation. Pour analyser l'efficacité de chaque algorithme dans l'optimisation de l'objectif contraint de maximisation des récompenses, les expériences évaluent chaque algorithme en fonction de ses limites en termes d'obtention de récompenses et de divergence KL par rapport à une stratégie de référence dans un environnement de génération d'émotions contrôlé. Les expériences peuvent utiliser des fonctions de récompense basées sur la vérité terrain (classificateurs de sentiments), afin que cette limite puisse être calculée. Mais en réalité, la fonction de récompense de la vérité terrain est inconnue. Nous évaluons donc le taux de victoire de l'algorithme en fonction du taux de victoire de la stratégie de base et utilisons GPT-4 comme proxy pour l'évaluation humaine de la qualité du résumé et de l'utilité de la réponse dans les paramètres de résumé et de dialogue à un seul tour. Pour les résumés, l'expérience utilise le résumé de référence dans la machine de test comme limite ; pour le dialogue, la réponse préférée dans l'ensemble de données de test est sélectionnée comme référence. Alors que les recherches existantes suggèrent que les modèles linguistiques peuvent être de meilleurs évaluateurs automatiques que les mesures existantes, les chercheurs ont mené une étude humaine qui a démontré la faisabilité de l'utilisation de GPT-4 pour l'évaluation de la corrélation entre les humains et le GPT-4. est généralement similaire ou supérieur à l’accord entre annotateurs humains.
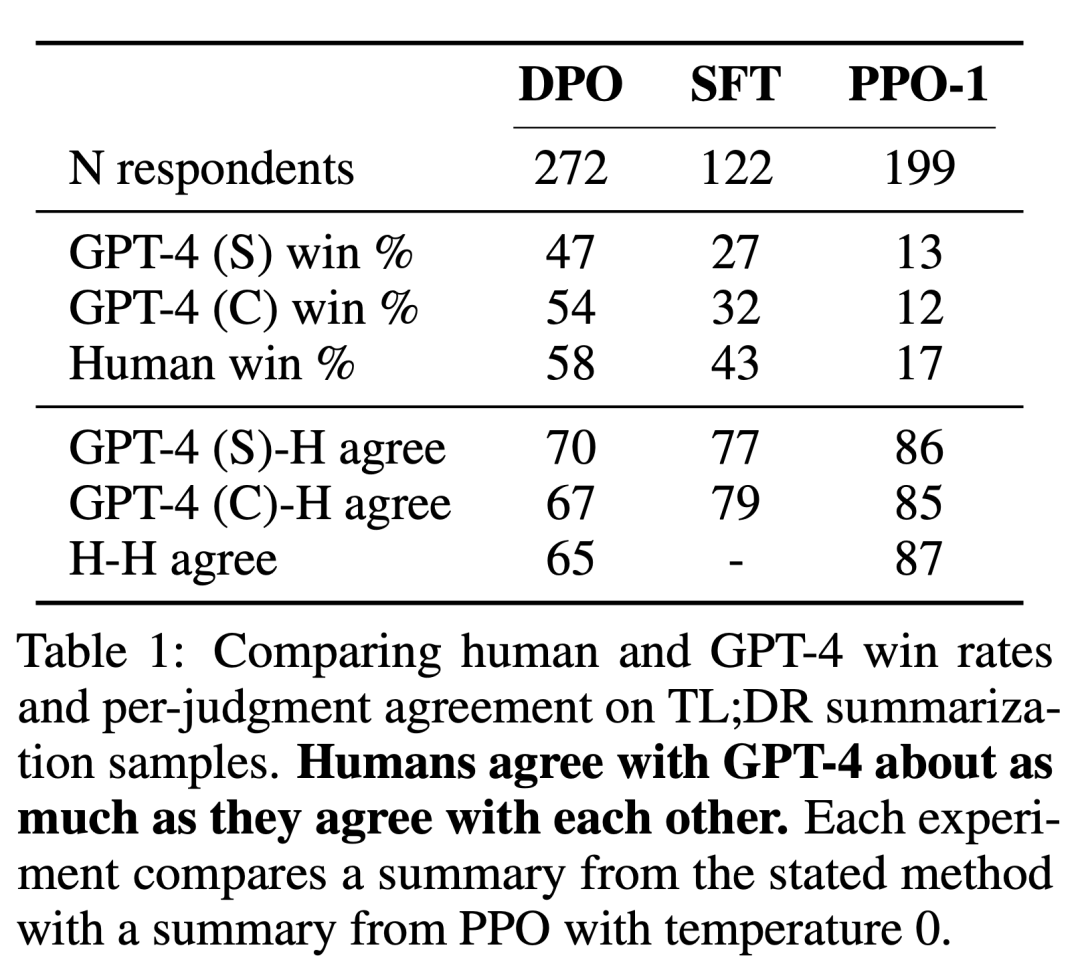
En plus du DPO, les chercheurs ont également évalué plusieurs modèles de langage de formation existants pour les aligner sur les préférences humaines. Dans leur forme la plus simple, les expériences explorent les invites à tir nul de GPT-J sur la tâche récapitulative et les invites à 2 tirs de Pythia-2.8B sur la tâche de dialogue. De plus, des expériences évaluent le modèle SFT et Preferred-FT. Preferred-FT est un modèle affiné via un apprentissage supervisé lors des achèvements y_w sélectionnés parmi les modèles SFT (sentiment contrôlé et résumé) ou les modèles de langage général (dialogue à un seul tour). Une autre méthode pseudo-supervisée est Improbabilité, qui optimise simplement la politique pour maximiser la probabilité attribuée à y_w et minimiser la probabilité attribuée à y_l. L'expérience utilise un coefficient optionnel α∈[0,1] sur « Improbabilité ». Ils ont également considéré la PPO, en utilisant une fonction de récompense tirée des données de préférence, et la PPO-GT. PPO-GT est un oracle tiré des fonctions de récompense de la vérité terrain disponibles dans des contextes d'émotion contrôlés. Dans les expériences sur les émotions, l’équipe a utilisé deux implémentations de PPO-GT, une version standard et une version modifiée. Ce dernier normalise les récompenses et ajuste davantage les hyperparamètres pour améliorer les performances (les expériences ont également utilisé ces modifications lors de l'exécution d'un PPO « normal » avec des récompenses d'apprentissage). Enfin, nous considérons la meilleure des N lignes de base, échantillonnons N réponses du modèle SFT (ou Preferred-FT en termes conversationnels) et renvoyons la réponse la mieux notée en fonction d'une fonction de récompense apprise de l'ensemble de données de préférence. Cette approche haute performance dissocie la qualité du modèle de récompense de l'optimisation PPO, mais est peu pratique sur le plan informatique, même pour un N modéré, car elle nécessite N achèvements d'échantillons par requête au moment du test.
La figure 2 montre les limites de récompense KL pour divers algorithmes dans le cadre des émotions.
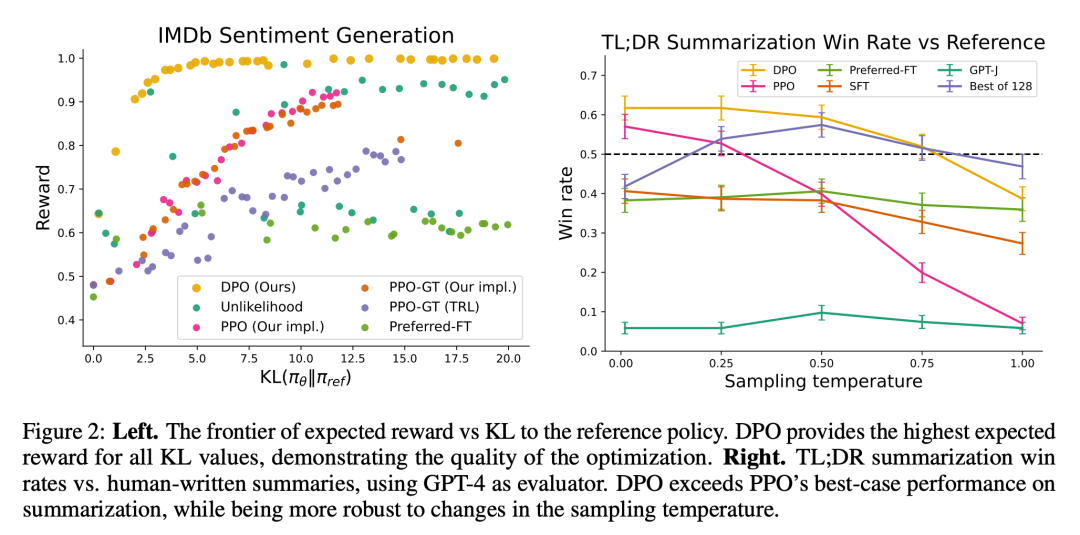
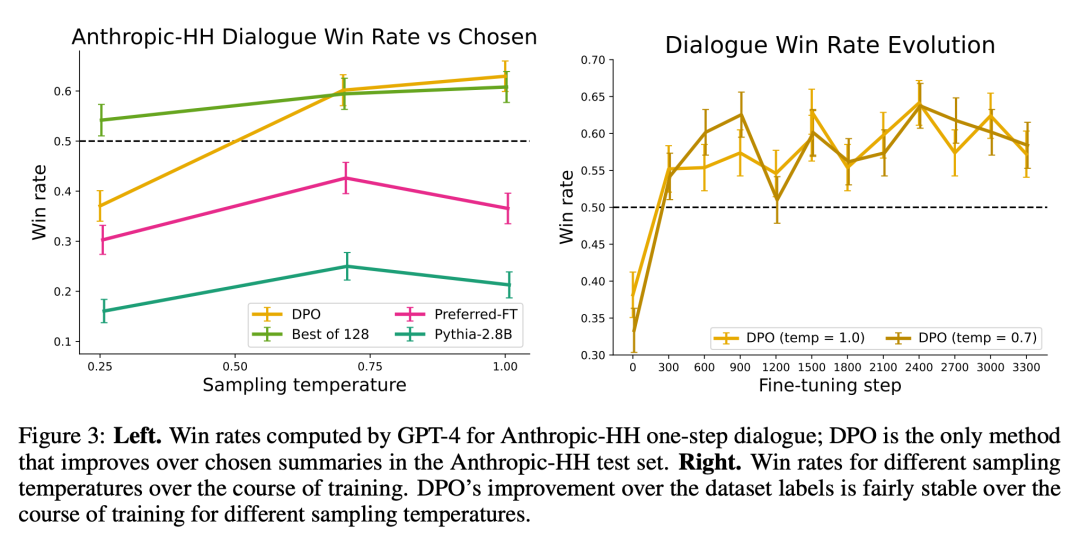
La figure 3 montre que le DPO converge relativement rapidement vers ses performances optimales.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
En utilisant OpenSSL pour la vérification de la signature numérique sur Debian System, vous pouvez suivre ces étapes: Préparation à installer OpenSSL: Assurez-vous que votre système Debian a installé OpenSSL. Si vous n'êtes pas installé, vous pouvez utiliser la commande suivante pour l'installer: SudoaptupDaSudoaptinInStallOpenssl pour obtenir la clé publique: la vérification de la signature numérique nécessite la clé publique du signataire. En règle générale, la clé publique sera fournie sous la forme d'un fichier, comme public_key.pe
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
