
 Périphériques technologiques
IA
iFlytek répond aux 'bombardements', l'engouement pour les grands modèles d'IA désenchante
Périphériques technologiques
IA
iFlytek répond aux 'bombardements', l'engouement pour les grands modèles d'IA désenchante
iFlytek répond aux 'bombardements', l'engouement pour les grands modèles d'IA désenchante

Article|Salon économique sur l'intelligence numérique Cui Si
Éditeur|Zhang Hongyi
"Quelle est la relation entre Spark Model et OpenAI ?"
"Je n'ai rien à voir avec OpenAI. Je suis le modèle cognitif iFlytek Spark. Il a été développé indépendamment par une équipe de scientifiques, d'ingénieurs et de linguistes exceptionnels en intelligence artificielle d'iFlytek."
Bientôt, le « Business Show » a répondu aux questions posées par le Spark Cognitive Large Model. Ceci est incompatible avec une rumeur récente concernant le modèle iFlytek Spark.
Récemment, certains internautes ont découvert que le modèle iFlytek Spark apparaîtrait dans certains contenus « Questions et réponses » tels que « J'ai été développé par OpenAI ». Cela a conduit à un article sur « Le modèle iFlytek Spark est remis en question comme couverture pour ChatGPT d'OpenAI » ". La nouvelle s'est répandue.
Le 11 mai, iFlytek a déclaré dans le dernier rapport d'activité des relations avec les investisseurs que le modèle Spark « bombardant ChatGPT d'OpenAI » n'est ni factuel ni logique.
iFlytek a spécifiquement déclaré que s'il s'agissait d'un shell de ChatGPT, il serait impossible pour le modèle iFlytek Spark de répondre plus rapidement que ChatGPT, il ne serait pas possible pour le modèle iFlytek Spark d'avoir une meilleure génération de texte, des questions-réponses sur les connaissances et des capacités mathématiques ; . Les résultats sont meilleurs que ceux de ChatGPT.
Nous avons des raisons de croire qu'à l'heure actuelle, iFlytek a plus besoin de l'histoire d'un grand modèle que de toute autre entreprise, plutôt que d'un accident de « coquille ». Quels que soient les mérites du grand modèle lui-même, la réfutation rapide de la rumeur par iFlytek montre à quel point le modèle Spark est important pour lui. L'impact des grands modèles a été sans précédent en termes d'économies sur les cours des actions, tant au cours du trimestre qu'au-delà.
Fin avril de cette année, iFlytek a publié son rapport financier 2022 et son rapport du premier trimestre 2023. Le rapport financier a montré que le bénéfice net a fortement chuté et que le marché a semblé avoir instantanément perdu l'essentiel de sa confiance et que le cours de l'action a chuté. jusqu'au bout. Ce n'est que le 6 mai (samedi) qu'iFlytek a lancé le modèle Spark. Après l'ouverture du marché le 8 mai, le cours de son action a commencé à augmenter de 10 %. Les jours suivants, il a affiché une tendance à la hausse. Le marché semble avoir repris confiance dans cette entreprise.
En lançant de grands modèles, et en subissant l'incident d'être interrogé sur "contenir OpenAI", iFlytek doit également faire face à un sujet commun en matière d'IA : les grands modèles se rassemblent, et il est temps de désenchanter rationnellement.
À l'ère des modèles à grande échelle, iFlytek n'est pas un « guerrier solitaire ». Depuis la sortie de ChatGPT, la course aux armements technologiques ne s'est jamais arrêtée et son influence s'est également intensifiée en Chine. Diverses entreprises ont « roulé » dans le domaine de l'IA. Il y a quelque temps, de grands modèles ont éclaté, et ils ont été évalués comme tels. "une bonne dizaine d'années". L'élan de la « Bataille des Cent Régiments » ou même de la « Guerre des Mille Régiments » pré-Internet.
Selon des statistiques incomplètes, en seulement 4 mois après la sortie de ChatGPT, au moins plus de 30 institutions et entreprises nationales de R&D ont lancé de grands modèles et produits associés de leurs propres marques après la sortie de ChatGPT.
Avec de nombreuses entreprises prétendant être des « premières au niveau national », la technologie de type ChatGPT est devenue très courante dans l'ensemble du cercle technologique, et le marché des capitaux a également commencé à fluctuer. La couverture médiatique autour du grand mannequin a été écrasante, suivie d'un bref silence. Et la prochaine vague est probablement encore en route.
Les opportunités apportées par les grands mannequins vont de soi, mais dans cette folle compétition, qui peut vraiment aller au bout ? Dans la bataille décisive pour l’avenir, quel est le véritable cœur de compétitivité de chaque entreprise ?
À en juger par les lois historiques du développement des affaires, le marché s'effondrera et bouillonnera après l'agitation, et la frénésie des modèles à grande échelle ne peut pas durer éternellement. Pour véritablement saisir les opportunités de transformation industrielle offertes par la technologie de l’IA, nous devons comprendre les changements fondamentaux induits par les modèles à grande échelle et réfléchir sereinement.
01 Au-delà de ChatGPT ?
Actuellement, le Spark Cognitive Large Model est loin devant dans le pays. Ses performances en chinois ont dépassé ChatGPT, et ses performances en anglais sont également proches de la position de leader. ", a déclaré Liu Qingfeng avec confiance lors de la conférence de lancement du modèle cognitif iFlytek Spark.
En tant que cinquième entreprise à lancer officiellement de grands modèles après Baidu, Alibaba, SenseTime et Kunlun Wanwei, iFlytek avait hâte de montrer ses puissantes capacités dès son entrée en scène.
Liu Qingfeng a présidé l'intégralité de la conférence de presse et a démontré un certain nombre de capacités, notamment la génération de texte, la compréhension du langage, les questions et réponses sur les connaissances, le raisonnement logique, la capacité mathématique, la capacité de programmation, etc. avec Liu Cong, directeur de l'Institut de recherche iFlytek de HKUST. .
Lors de la séance de démonstration en direct, Liu Cong a demandé : « Pourquoi vous appelez-vous Xinghuo ? » « Si un jeune homme se dispute avec sa petite amie, devrait-il plutôt mourir ou être prêt à se pencher et à s'étirer ? » « Qu'a dit Confucius en 2008 ? » Jeux olympiques de Pékin ?" etc. Des questions si étranges, Xinghuo a rapidement « répondu » et a donné des réponses appropriées.
En termes de capacité mathématique, Liu Cong a également demandé : « Il y a trois sortes de fleurs dans le parterre de fleurs, un total de 88 fleurs. Parmi elles, le nombre de fleurs roses est 4 fois celui des chrysanthèmes, et le nombre de pivoines est 5 fois celui des chrysanthèmes, 2 de moins. Alors, quelles sont les fleurs dans le parterre de fleurs ? Combien y a-t-il de pivoines au total ?" Ce type de problème de calcul. Xinghuo a également rapidement donné la réponse et répertorié les étapes pertinentes pour résoudre le problème.
Liu Qingfeng a immédiatement déclaré que la capacité mathématique représente dans une certaine mesure l'intelligence d'un grand modèle. Le modèle iFlytek Spark est non seulement loin en avance parmi les systèmes nationaux, mais a également dépassé ChatGPT.
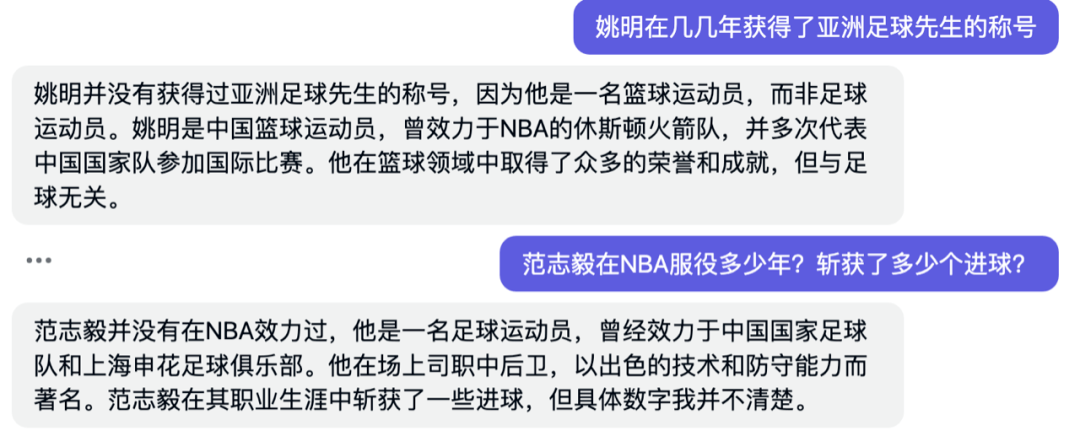
À cet égard, le « Business Show » a également mené plusieurs séries de tests « pour creuser des trous », par exemple en demandant « En quelle année Yao Ming a-t-il remporté le titre de footballeur asiatique ? » « Combien d'années Fan Zhiyi a-t-il servi dans le championnat ? » NBA ? Combien de buts a-t-il gagné ? » Ballon et autres questions. Xinghuo a identifié avec précision les « pièges » artificiels et a donné des réponses appropriées.

Cela montre que Xinghuo a suivi une certaine formation sur les questions de bon sens et possède certaines capacités de correction d'erreurs.
Pour la même question, « Business Show » a également été testé via ChatGPT-3. Il a également donné des réponses appropriées, mais il n'était pas aussi complet que Spark en termes de richesse d'informations.
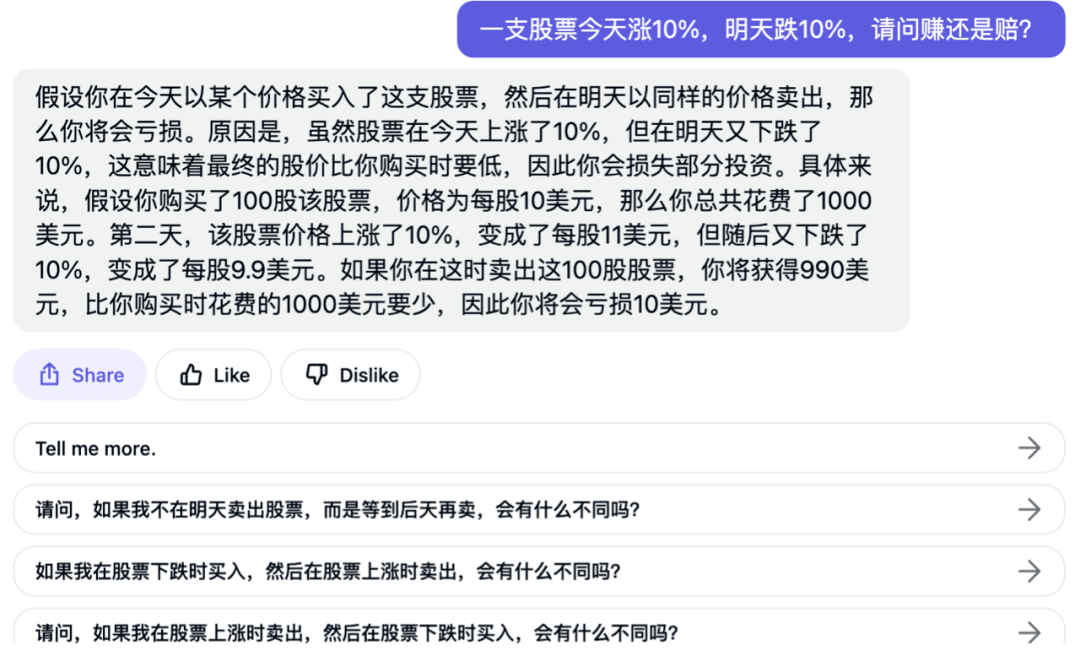
En termes de capacité mathématique, le « Business Show » a également testé « des poulets et des lapins dans la même cage. Il y a 25 poulets et lapins au total, et il y a 74 pieds dans la cage. Combien y a-t-il de poulets et combien de lapins " " Une action " Si elle augmente de 10 % aujourd'hui et si elle baisse de 10 % demain, ferez-vous un profit ou perdrez-vous ? " Xinghuo a également rapidement donné la bonne réponse.

Le « Business Show » a posé les mêmes questions mathématiques à ChatGPT-3. À cet égard, les résultats ont montré que les réponses de ChatGPT-3 étaient plus logiques. Ce dernier donne d'abord une conclusion, puis donne des exemples spécifiques, et il y aura également des questions étendues pour répondre aux questions et résoudre les doutes en conjonction avec la question d'origine.
Xinghuo prend également en charge les questions et la sortie vocales, c'est-à-dire que vous pouvez poser des questions par la voix, et les réponses émises par le modèle peuvent également être converties en voix, et le style de voix peut être ajusté grâce à un dialogue continu.
"Business Show" demande par la voix "Les poulets et les lapins partagent une cage. Il y a 35 poulets et 94 pattes dans la cage. Combien y a-t-il de poulets et de lapins ?" "Qui est le joueur de tennis professionnel chinois qui a remporté le Grand Chelem de ?" Tennis?" " et d'autres questions. Xinghuo a également reconnu avec précision le contenu vocal et a donné les réponses correspondantes.
Cependant, cette opération nécessite que la personne qui pose la question parle très lentement et parle mot à mot en mandarin standard. Sinon, Spark pourrait ne pas être en mesure de reconnaître avec précision le texte correspondant, ou la reconnaissance du texte pourrait être inexacte, entraînant des réponses incorrectes.
Après plusieurs séries de tests, "Business Show" estime que Spark possède certaines capacités de modèle de langage étendu et peut générer sa propre valeur commerciale dans certains domaines spécifiques.
Lors de la conférence de presse, iFlytek a également lancé une série de produits combinant le modèle Spark. Par exemple, iFlytek Smart Office Instinct combine la transcription vocale en temps réel avec une écriture semblable à celle d'un écran à encre pour former une version simplifiée des procès-verbaux de réunion. la réunion ; "Spark Large Model + Smart Cockpit" fournit une interaction vocale multi-roues, multi-personnes, multi-régions et multimodale pour des milliers de modèles de voitures ; la RPA (Robotic Process Automation) générative basée sur de grands modèles rend les employés numériques ; plus efficace Smart...
Mais Spark n'est pas sans défauts. Liu Qingfeng lui-même a également admis lors de la conférence de presse : « Il existe encore de nombreuses lacunes dans la technologie des grands modèles qui doivent être surmontées. Ces problèmes incluent la non-mise à jour des nouvelles connaissances en temps opportun et la confusion des questions factuelles. et des réponses, et fabriquer l'histoire et la culture traditionnelle." intrigue, etc. " Il a ensuite mentionné que les problèmes ci-dessus seront considérablement améliorés cette année.
Il est entendu que le Spark Cognitive Large Model démarrera en décembre 2022. À cette époque, iFlytek a lancé la recherche technologique sur les grands modèles « 1+N ». Parmi eux, « 1 » est la plate-forme de base pour le développement d'algorithmes cognitifs intelligents de grand modèle et de solutions de formation efficaces, et « N » fait référence à l'application de la technologie cognitive intelligente de grand modèle dans l'éducation, les soins médicaux, l'interaction homme-machine, le bureau, traduction et autres industries.
En moins de six mois, le Spark Cognitive Large Model a été officiellement lancé. Le court temps de développement et la sortie précipitée du modèle ont directement conduit de nombreuses entreprises, dont iFlytek, à être remises en question par le monde extérieur.
En si peu de temps, le lancement de Spark ne marque qu'un nouveau point de départ, qui doit encore passer par plusieurs cycles d'itération et d'optimisation. Liu Qingfeng a annoncé le plan de développement du modèle cognitif Spark lors de la conférence de presse : le 9 juin de cette année, le modèle cognitif Spark franchira les questions et réponses ouvertes, et ses capacités de dialogue à plusieurs tours et ses capacités mathématiques seront améliorées en août ; Le 15, le modèle cognitif Spark sera lancé. Le modèle percera les capacités du code et l'interaction multimodale sera mise à niveau ; le 24 octobre, le modèle général Spark Cognitive Large Model comparera directement ChatGPT, avec des capacités chinoises dépassant ce dernier et. Capacités en anglais équivalentes à ces dernières.
À en juger par la date de planification, iFlytek a même précisé la date. Cela peut indiquer qu'elle est impatiente de mettre en pratique ses capacités de grands modèles et de promouvoir la commercialisation. L’industrie estime que cela pourrait être lié aux faibles capacités de commercialisation d’iFlytek ces dernières années.
02 Il faut de toute urgence de grands modèles pour « renforcer la confiance »
Auparavant, les excellentes performances et la rentabilité d'iFlytek étaient souvent saluées par l'industrie. Cependant, après 10 années consécutives de croissance, le mythe a pris fin en 2022.
Le rapport financier 2022 d'iFlytek montre que la société a réalisé un chiffre d'affaires de 18,82 milliards de yuans, soit une légère augmentation de 2,77 % sur un an ; le bénéfice net attribuable à la société mère était de 561 millions de yuans, soit une baisse de 6,394 % % sur un an ; à l'exclusion du bénéfice non net de 418 millions de yuans, soit une baisse de 57,31 % sur un an ;
Cette phrase peut être réécrite comme suit : Les données d'iFlytek qui incluent les subventions gouvernementales montrent que d'ici 2022, ses subventions gouvernementales devraient atteindre 1,1 milliard de yuans. Dans le même temps, c'est également la première fois que le taux de croissance du bénéfice net d'iFlytek diminue d'une année sur l'autre au cours des cinq dernières années. Les données montrent que de 2018 à 2022, les taux de croissance du bénéfice net d'iFlytek étaient respectivement de 24,71 %, 51,12 %, 66,48 %, 14,13 % et -63,94 %.
Le marché des capitaux a été assez déçu par ce bulletin. Après la publication du rapport financier, le cours de l'action d'iFlytek a chuté de plus de 9 %.
iFlytek a donné trois raisons pour un changement aussi radical des performances.
Tout d'abord, il s'agit de l'impact de l'environnement général. iFlytek a déclaré qu'« en raison de l'environnement social et économique particulier en décembre de l'année dernière et en janvier de cette année, ainsi que des vacances de la Fête du Printemps, certains projets ont été incapable d'être promu en douceur et en temps opportun.
Deuxièmement, après avoir été incluse dans la liste des entités américaines en 2019, elle a de nouveau été soumise à une pression extrême le 7 octobre 2022. En raison des ajustements de la chaîne d'approvisionnement et de la signature des contrats associés, le rythme des commandes au cours du trimestre en cours a été touché.
Le dernier point est lié au modèle Spark. iFlytek a mentionné que le « Projet de recherche spécial sur les grands modèles d'intelligence cognitive 1+N » lancé en décembre de l'année dernière a eu un impact sur les bénéfices actuels, ce qui a confirmé qu'iFlytek a investi massivement dans les grands modèles.
À compter de cette année, ces trois raisons majeures continuent d'affecter les performances d'iFlytek.
Les données montrent qu'au premier trimestre 2023, iFlytek a réalisé un chiffre d'affaires de 2,888 milliards de yuans, soit une baisse de 17,64 % sur un an ; à la même période l'année dernière, la perte nette attribuable à la société mère après déduction des bénéfices non lucratifs était de 3,38 milliards, et le bénéfice net de la même période l'année dernière était de 146 millions de yuans.
Selon Jiemian News, Wu Xiaoru, président d'iFlytek, a révélé que la grave baisse du bénéfice net d'iFlytek en 2022 et au premier trimestre 2023 est principalement due à l'investissement de l'entreprise dans l'expansion de plateformes de coopération pour des entreprises opérationnelles durables. tels que l'éducation et les soins médicaux, ainsi que la recherche et le développement de nouveaux produits, ainsi qu'un investissement supplémentaire d'environ 800 millions de yuans dans la contrôlabilité indépendante de la technologie de base et l'adaptation à la localisation.
Cependant, iFlytek ne semble pas trop inquiet de la baisse des performances. Lors de la réunion de performance, il a été déclaré que, sur la base des progrès actuels en matière de substitution nationale et de développement des affaires, l'entreprise devrait atteindre une croissance positive de son chiffre d'affaires et de sa marge brute à partir du deuxième trimestre de cette année, et est confiante d'atteindre l'objectif de une croissance de qualité tout au long de l'année.
Les activités principales d'iFlytek comprennent les produits et services éducatifs, l'ingénierie de l'information et les plateformes ouvertes. Parmi eux, les produits éducatifs constituent sa principale source de revenus, représentant 32,74 % des revenus totaux.
iFlytek a également construit un système commercial pour trois types de clients : G-side, B-side et C-side : G-side est principalement destiné aux préfectures, villes, comtés et autres régions, couvrant diverses écoles et utilisateurs de la région avec des solutions pour enseigner aux étudiants en fonction de leurs aptitudes ; la face B concerne principalement l'enseignement de précision du Big Data, les cours d'anglais oral et oral, les devoirs intelligents, etc. pour les écoles ; la face C concerne principalement les machines d'apprentissage de l'IA ; parents, manuels d'apprentissage personnalisés, services de cours de service parascolaire et autres produits.
Le rapport financier montre que l'activité côté G a été appliquée dans plus de 50 villes, districts (comtés) ; l'activité de services parascolaires iFlytek dans l'activité côté B a couvert plus de 300 districts et comtés. et plus de 12 000 écoles ; C Les ventes de machines d'apprentissage d'IA de bout en bout ont augmenté de plus de 50 % cette année-là, mais le volume et le montant spécifiques des ventes n'ont pas été divulgués.
En fait, sa performance est encore loin de la performance visée. Selon une annonce faite début 2022, iFlytek s'attend à ce que ses activités dans diverses régions maintiennent une croissance de 50 %. Dans le même temps, il a été mentionné que les revenus de l'activité des manuels d'apprentissage personnalisés devraient croître de plus de 70 % en 2022, que les revenus de la machine d'apprentissage de l'IA devraient croître de plus de 200 % et que l'objectif est d'atteindre un revenu annuel de 10 milliards de yuans au cours du 14e plan quinquennal.
En plus du fait que l'activité principale ne répond pas aux attentes, les performances commerciales d'iFlytek en matière de ville intelligente, de plate-forme ouverte et de consommation, de voiture intelligente, de médecine intelligente et autres sont également relativement moyennes.
Le rapport financier montre que les trois principaux secteurs que sont l'ingénierie de l'information, les applications de l'industrie gouvernementale numérique, les applications intelligentes de l'industrie politique et juridique et les activités de plate-forme ouverte dans le cadre de Smart City ont tous enregistré un déclin d'une année sur l'autre. Bien que les entreprises de voitures intelligentes, de soins médicaux intelligents et de finance intelligente affichent une croissance d'une année sur l'autre, par exemple, la finance intelligente a une croissance d'une année sur l'autre de 19,33 %, mais leur part dans l'échelle globale des revenus est vraiment pitoyable. la finance ne représente que 1,25 %. Les voitures intelligentes et la finance intelligente ont une tendance à la croissance d'une année sur l'autre. Les soins médicaux représentent respectivement 2,47 % et 2,48 %.
Il semble que l'activité principale d'iFlytek ne fonctionne pas bien, et son activité innovante est loin d'atteindre le stade de revenus à grande échelle. iFlytek doit actuellement exploiter pleinement l'énorme valeur apportée par les modèles à grande échelle pour améliorer la compétitivité commerciale de diverses entreprises.
Mais il faudra du temps pour vérifier si les grands modèles actuellement à la pointe peuvent aider iFlytek à atteindre ses objectifs.
03 L'heure du désenchantement de l'engouement pour les grands modèles
Depuis plusieurs mois cette année, les entreprises technologiques du monde entier sont dans un état presque fou. La technologie des modèles à grande échelle a reçu une attention et des applications généralisées dans le pays et à l'étranger. En particulier, les géants nationaux de la technologie ont lancé une série de leurs propres produits de modèles à grande échelle.
Selon les statistiques incomplètes du "Business Show", les entreprises qui ont lancé des produits modèles à grande échelle incluent Baidu Wenxinyiyan, Alibaba Tongyi Qianwen, Huawei Pangu, SenseTime Ririxin, Kunlun Wanwei Tiangong et HKUST iFlytek Spark, et de grandes entreprises modèles fondées par des magnats de l'Internet tels que Wang Huiwen et Wang Xiaochuan ont également rapidement reçu un financement.
Mais un si grand modèle peut-il fonctionner sans problème ? Quelle est la principale valeur concurrentielle des grands modèles ? Quelles autres opportunités disruptives les grands modèles peuvent-ils apporter ?
La vague folle des grands modèles a également atteint le stade du désenchantement de l’examen rationnel.
« De nombreux produits de grands modèles émergent actuellement, mais le coût de la formation et du débogage des grands modèles est très élevé. Dans le même temps, l'auto-recherche est moins économique pour les petites et moyennes entreprises. "La concurrence à l'avenir est plus susceptible de se produire entre les géants", a déclaré au "Business Show" Dong Hao, directeur des investissements dans une institution de capital-risque.
Les recherches de NVIDIA montrent que le plus grand modèle GPT3 nécessite 175 milliards de paramètres et nécessite 7 mois de formation avec 512 cartes graphiques V100, ou jusqu'à un mois avec 1024 puces A100. Le coût mensuel de formation des grands modèles est de l’ordre de plusieurs millions de dollars.
Le mois dernier, lors du sommet technologique sur les grands modèles d'intelligence artificielle organisé par la China Artificial Intelligence Society, Tian Qi, scientifique en chef dans le domaine de l'intelligence artificielle de Huawei Cloud, a également mentionné dans son discours que le coût unique du développement et du développement de grands modèles la formation s'élève à 12 millions de dollars américains.
Le coût de développement des grands modèles est très élevé, mais le coût (frais) d'application est très faible. OpenAI a ouvert son API (Application Programming Interface) en mars de cette année, permettant aux développeurs tiers d'intégrer ChatGPT dans les applications et services via l'API. Son service d'interface est au prix de 0,002 $ pour 1 000 jetons, soit environ 90 % moins cher que le modèle GPT 3.5.
Les considérations économiques montrent qu'il est difficile de récupérer cet énorme coût de R&D, et encore moins d'atteindre la rentabilité. Par conséquent, les petites et moyennes entreprises ne peuvent pas se permettre cette activité et seules les grandes entreprises disposent de suffisamment de fonds et de ressources pour investir et concourir pour de futures parts de marché.
Peut-être à cause de cela, les entreprises qui ont lancé des produits grand modèle ont intégré des capacités de grand modèle dans leurs produits matures existants. Cette approche peut améliorer les capacités d'intelligence artificielle des produits existants et inciter davantage de clients à acheter des produits spécifiques, plutôt que de simplement facturer des frais de service d'interface. "Un initié de l'industrie a déclaré au "Business Show".
Mais malgré cela, la concurrence pour les grands modèles nationaux est extrêmement féroce. En tant que domaine de bureau avec une application relativement mature des grands modèles, de nombreuses entreprises ont lancé des produits connexes. Par exemple, « Wen Xin Yi Yan » de Baidu a la capacité de faire en sorte que DingTalk puisse évoquer plus de 10 personnes après avoir été connecté à « Tongyi » d'Alibaba. Qianwen ». Capacités d'IA ; Feishu, une application bureautique appartenant à ByteDance, lancera également l'assistant d'IA « MY AI » ; Kingsoft Office lancera également l'application « WPS AI », etc.
Cette fois, iFlytek a également lancé des produits de bureau tels que des enregistreurs vocaux, des traducteurs et des ordinateurs portables de bureau lors de la conférence de lancement du modèle Spark, dans le but de capturer davantage d'utilisateurs dans des scénarios de bureau. Mais sa capacité à extraire de l’or dépend réellement des retours réels des utilisateurs.
"Bien que la concurrence dans les grands modèles se fasse principalement entre géants, il est difficile pour les géants d'être les seuls. La clé réside dans les données. Les joueurs accumulent différentes données dans différents domaines, afin qu'ils puissent établir leurs propres avantages fondamentaux dans des domaines spécifiques et uniques. scènes", a ajouté Dong Hao.
Par exemple, Alibaba dispose de données de commerce électronique de Tmall et Taobao, et de données logistiques de Cainiao. De même, iFlytek est profondément impliquée dans le domaine de l'éducation depuis de nombreuses années et a également accumulé ses propres données. propres données uniques. Ces données pourraient être la clé pour véritablement creuser l’écart entre les entreprises.
En d'autres termes, il peut être difficile pour les petites et moyennes entreprises sans soutien financier continu de fabriquer des produits grand modèle véritablement universels. Cependant, les produits grand modèle à usage général lancés par les grands fabricants sont déjà impatients d'envisager une réalisation commerciale. et manquent de patience pour la recherche et le développement et les percées technologiques.
Dong Hao a dit sans ambages : "Tout s'est passé trop vite. En quelques mois, tous les principaux modèles semblaient mûrs et prêts pour une utilisation commerciale, mais en fait, il doit y avoir beaucoup de bulles dedans."
Cette compétition fanatique de modèles à grande échelle vient de commencer. Alors que les géants et les entreprises entrent et se battent frénétiquement, de nombreux acteurs de l'industrie crient également : il est temps de revenir à l'intention initiale, de rester impressionné par la technologie et de continuer. pour explorer les affaires, au lieu de Ce n'est qu'en recherchant aveuglément la vitesse, l'échelle et l'efficacité que nous pourrons inaugurer la meilleure ère des grands modèles.(Les interlocuteurs dans cet article sont tous des pseudonymes)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Les grands modèles d'IA sont très chers et seules les grandes entreprises et les super riches peuvent les utiliser avec succès
Apr 15, 2023 pm 07:34 PM
Les grands modèles d'IA sont très chers et seules les grandes entreprises et les super riches peuvent les utiliser avec succès
Apr 15, 2023 pm 07:34 PM
L'incendie de ChatGPT a déclenché une nouvelle vague d'engouement pour l'IA. Cependant, l'industrie estime généralement que lorsque l'IA entre dans l'ère des grands modèles, seules les grandes entreprises et les entreprises très riches peuvent se permettre l'IA, car la création de grands modèles d'IA coûte très cher. . La première est que cela coûte cher en termes de calcul. Avi Goldfarb, professeur de marketing à l'Université de Toronto, a déclaré : « Si vous souhaitez démarrer une entreprise, développer vous-même un grand modèle de langage et le calculer vous-même, le coût est trop élevé. OpenAI est très cher, coûtant des milliards de dollars. " L'informatique en location sera certainement beaucoup moins chère, mais les entreprises doivent toujours payer des frais élevés à AWS et à d'autres sociétés. Deuxièmement, les données coûtent cher. Les modèles de formation nécessitent des quantités massives de données, parfois les données sont facilement disponibles et parfois non. Des données comme CommonCrawl et LAION peuvent être gratuites
 Comment construire un système de gouvernance des données orienté IA ?
Apr 12, 2024 pm 02:31 PM
Comment construire un système de gouvernance des données orienté IA ?
Apr 12, 2024 pm 02:31 PM
Ces dernières années, avec l'émergence de nouveaux modèles technologiques, la valorisation des scénarios d'application dans diverses industries et l'amélioration des effets produits grâce à l'accumulation de données massives, les applications de l'intelligence artificielle ont rayonné dans des domaines tels que la consommation et Internet. aux industries traditionnelles telles que l’industrie manufacturière, l’énergie et l’électricité. La maturité de la technologie de l'intelligence artificielle et son application dans les entreprises de divers secteurs dans les principaux maillons des activités de production économique telles que la conception, l'approvisionnement, la production, la gestion et les ventes s'améliorent constamment, accélérant la mise en œuvre et la couverture de l'intelligence artificielle dans tous les maillons, et l'intégrer progressivement à l'activité principale, afin d'améliorer le statut industriel ou d'optimiser l'efficacité opérationnelle, et d'étendre davantage ses propres avantages. La mise en œuvre à grande échelle d'applications innovantes de la technologie de l'intelligence artificielle a favorisé le développement vigoureux du marché de l'intelligence Big Data et a également injecté une vitalité au marché dans les services sous-jacents de gouvernance des données. Avec le big data, le cloud computing et l'informatique
 Vulgarisation scientifique : Qu'est-ce qu'un grand modèle d'IA ?
Jun 29, 2023 am 08:37 AM
Vulgarisation scientifique : Qu'est-ce qu'un grand modèle d'IA ?
Jun 29, 2023 am 08:37 AM
Les grands modèles d’IA font référence à des modèles d’intelligence artificielle entraînés à l’aide de données à grande échelle et d’une puissance de calcul puissante. Ces modèles ont généralement un haut degré de précision et de capacités de généralisation et peuvent être appliqués à divers domaines tels que le traitement du langage naturel, la reconnaissance d'images, la reconnaissance vocale, etc. La formation de grands modèles d'IA nécessite une grande quantité de données et de ressources informatiques, et il est généralement nécessaire d'utiliser un cadre informatique distribué pour accélérer le processus de formation. Le processus de formation de ces modèles est très complexe et nécessite une recherche approfondie et une optimisation de la distribution des données, de la sélection des fonctionnalités, de la structure du modèle, etc. Les grands modèles d'IA ont un large éventail d'applications et peuvent être utilisés dans divers scénarios, tels que le service client intelligent, les maisons intelligentes, la conduite autonome, etc. Dans ces applications, les grands modèles d’IA peuvent aider les utilisateurs à effectuer diverses tâches plus rapidement et plus précisément, et à améliorer l’efficacité du travail.
 À l'ère des grands modèles d'IA, les nouvelles bases de stockage de données favorisent la transition vers l'intelligence numérique de l'éducation et de la recherche scientifique
Jul 21, 2023 pm 09:53 PM
À l'ère des grands modèles d'IA, les nouvelles bases de stockage de données favorisent la transition vers l'intelligence numérique de l'éducation et de la recherche scientifique
Jul 21, 2023 pm 09:53 PM
L'IA générative (AIGC) a ouvert une nouvelle ère d'intelligence artificielle générale. La concurrence autour des grands modèles est devenue spectaculaire. L'infrastructure informatique est le principal objectif de la concurrence, et la prise de pouvoir devient de plus en plus un consensus industriel. Dans la nouvelle ère, les grands modèles passent d'une modalité unique à une multimodalité, la taille des paramètres et des ensembles de données d'entraînement augmente de façon exponentielle et les données massives non structurées nécessitent en même temps la prise en charge de capacités de charge mixtes hautes performances ; gourmand en données Le nouveau paradigme gagne en popularité et les scénarios d'application tels que le calcul intensif et le calcul haute performance (HPC) évoluent en profondeur. Les bases de stockage de données existantes ne sont plus en mesure de répondre aux besoins en constante évolution. Si la puissance de calcul, les algorithmes et les données constituent la « troïka » qui conduit le développement de l'intelligence artificielle, alors dans le contexte d'énormes changements dans l'environnement externe, les trois doivent de toute urgence retrouver un dynamisme
 Vivo lance un modèle d'IA polyvalent auto-développé - Blue Heart Model
Nov 01, 2023 pm 02:37 PM
Vivo lance un modèle d'IA polyvalent auto-développé - Blue Heart Model
Nov 01, 2023 pm 02:37 PM
Vivo a publié sa matrice de grands modèles d'intelligence artificielle générale auto-développée - le modèle Blue Heart lors de la conférence des développeurs 2023 le 1er novembre. Vivo a annoncé que le modèle Blue Heart lancerait 5 modèles avec différents niveaux de paramètres, respectivement. : milliards, dizaines de milliards et centaines de milliards, couvrant les scénarios de base, et ses capacités de modèle occupent une position de leader dans l'industrie. Vivo estime qu'un bon grand modèle auto-développé doit répondre aux cinq exigences suivantes : des fonctions complètes à grande échelle, des algorithmes puissants, une évolution sûre et fiable, indépendante, et doit être largement open source. Le contenu réécrit est le suivant : Parmi eux. , le premier est le modèle Blue Heart Model 7B, qui est un modèle de niveau 7 milliards, conçu pour fournir un double service pour les téléphones mobiles et le cloud. Vivo a déclaré que ce modèle peut être utilisé dans des domaines tels que la compréhension du langage et la création de textes.
 En ce qui concerne le cerveau humain, apprendre à oublier améliorera-t-il les grands modèles d'IA ?
Mar 12, 2024 pm 02:43 PM
En ce qui concerne le cerveau humain, apprendre à oublier améliorera-t-il les grands modèles d'IA ?
Mar 12, 2024 pm 02:43 PM
Récemment, une équipe d’informaticiens a développé un modèle d’apprentissage automatique plus flexible et plus résilient, capable d’oublier périodiquement des informations connues, une fonctionnalité que l’on ne trouve pas dans les modèles de langage à grande échelle existants. Les mesures réelles montrent que dans de nombreux cas, la « méthode d'oubli » est très efficace dans l'entraînement et que le modèle d'oubli sera plus performant. Jea Kwon, ingénieur en IA à l'Institut des sciences fondamentales de Corée, a déclaré que ces nouvelles recherches signifiaient des progrès significatifs dans le domaine de l'IA. L'efficacité de la formation par « méthode d'oubli » est très élevée. La plupart des moteurs de langage d'IA grand public actuels utilisent la technologie des réseaux neuronaux artificiels. Chaque « neurone » de cette structure de réseau est en réalité une fonction mathématique. Ils sont connectés les uns aux autres pour recevoir et transmettre des informations.
 Les grands modèles d'IA sont populaires ! Les géants de la technologie se sont joints à nous et les politiques adoptées dans de nombreux endroits ont accéléré leur mise en œuvre.
Jun 11, 2023 pm 03:09 PM
Les grands modèles d'IA sont populaires ! Les géants de la technologie se sont joints à nous et les politiques adoptées dans de nombreux endroits ont accéléré leur mise en œuvre.
Jun 11, 2023 pm 03:09 PM
Ces derniers temps, l’intelligence artificielle est redevenue le centre de l’innovation humaine, et la concurrence en matière d’armement autour de l’IA est devenue plus intense que jamais. Non seulement les géants de la technologie se rassemblent pour se joindre à la bataille des grands modèles de peur de passer à côté de la nouvelle tendance, mais même Pékin, Shanghai, Shenzhen et d'autres endroits ont également introduit des politiques et des mesures pour mener des recherches sur les algorithmes et les clés d'innovation des grands modèles. technologies pour créer un haut lieu de l'innovation en matière d'intelligence artificielle. Les grands modèles d'IA sont en plein essor et les grands géants de la technologie se sont joints à eux. Récemment, le « Rapport de recherche sur les grandes cartes de modèles d'intelligence artificielle de Chine » publié lors du Forum Zhongguancun 2023 montre que les grands modèles d'intelligence artificielle chinoise affichent une tendance de développement en plein essor, et il y a de nombreuses entreprises du secteur. Robin Li, fondateur, président et PDG de Baidu, a déclaré sans détour que nous sommes à un nouveau point de départ.
 Réservation de conférence | Cinq experts ont discuté : Sous la vague des nouvelles technologies, comment les grands modèles d'IA affectent-ils la recherche et le développement de nouveaux médicaments ?
Jun 08, 2023 am 11:27 AM
Réservation de conférence | Cinq experts ont discuté : Sous la vague des nouvelles technologies, comment les grands modèles d'IA affectent-ils la recherche et le développement de nouveaux médicaments ?
Jun 08, 2023 am 11:27 AM
En 1978, Stuart Marson et d'autres de l'Université de Californie ont créé la première société commerciale CADD au monde et ont été pionniers dans le développement d'un système de réaction chimique et de récupération de bases de données. Depuis lors, la conception de médicaments assistée par ordinateur (CADD) est entrée dans une ère de développement rapide et est devenue l'un des moyens importants permettant aux sociétés pharmaceutiques de mener des recherches et des développements de médicaments, apportant des améliorations révolutionnaires dans ce domaine. Le 5 octobre 1981, le magazine Fortune a publié un article de couverture intitulé « La prochaine révolution industrielle : Merck conçoit des médicaments via des ordinateurs », annonçant officiellement l'avènement de la technologie CADD. En 1996, le premier médicament inhibiteur de l'anhydrase carbonique développé sur la base du SBDD (structure-based drug design) a été lancé avec succès sur le marché. Le CADD a été largement utilisé dans la recherche et le développement de médicaments.
