
 Périphériques technologiques
IA
L'Université Tsinghua et d'autres « références d'apprentissage d'outils » open source ToolBench, modèle de réglage fin, les performances de ToolLLaMA dépassent ChatGPT
Périphériques technologiques
IA
L'Université Tsinghua et d'autres « références d'apprentissage d'outils » open source ToolBench, modèle de réglage fin, les performances de ToolLLaMA dépassent ChatGPT
L'Université Tsinghua et d'autres « références d'apprentissage d'outils » open source ToolBench, modèle de réglage fin, les performances de ToolLLaMA dépassent ChatGPT

Les êtres humains ont la capacité de créer et d'utiliser des outils, nous permettant de dépasser les limites du corps et d'explorer un monde plus vaste.
Le modèle de base de l'intelligence artificielle est similaire. Si vous vous fiez uniquement aux poids obtenus lors de la phase de formation, les scénarios d'utilisation seront très limités. Cependant, l'apprentissage des outils récemment proposé combine des outils spécialisés dans des domaines spécifiques avec des outils de base à grande échelle. Modèles, peuvent atteindre une efficacité et des performances plus élevées.
Cependant, les recherches actuelles sur l'apprentissage des outils ne sont pas suffisamment approfondies et il y a un manque de données et de codes open source pertinents.
Récemment, OpenBMB (Open Lab for Big Model Base), une communauté open source soutenue par le Natural Language Processing Laboratory de l'Université Tsinghua et d'autres, a publié le projet ToolBench, qui peut aider les développeurs à créer des applications open source, à grande échelle et de haute qualité. données de réglage des instructions de qualité Facilite la construction de grands modèles de langage avec la possibilité d’utiliser des outils communs.
Lien du référentiel : https://github.com/OpenBMB/ToolBench
Le référentiel ToolBench fournit des ensembles de données pertinents, des scripts de formation et d'évaluation, ainsi que le modèle fonctionnel ToolLLaMA affiné sur ToolBench. , les fonctionnalités spécifiques sont :
1. Prise en charge des solutions à outil unique et multi-outils
Le paramètre d'outil unique suit le style d'invite LangChain et le paramètre multi-outil suit le style d'invite AutoGPT.
2. La réponse du modèle inclut non seulement la réponse finale, mais inclut également le processus de chaîne de réflexion du modèle, l'exécution de l'outil et les résultats de l'exécution de l'outil
3. Prend en charge la complexité du monde réel et les appels d'outils en plusieurs étapes
.4. API riche qui peut être utilisée pour des scénarios du monde réel, tels que les informations météorologiques, la recherche, les mises à jour des stocks et l'automatisation PowerPoint
5. Toutes les données sont automatiquement générées par l'API OpenAI et filtrées par l'équipe de développement . Le processus de création est facilement évolutif
Cependant, il est important de noter que les données publiées jusqu'à présent ne sont pas définitives et que les chercheurs sont encore en train de post-traiter les données pour améliorer la qualité des données et augmenter la couverture des outils du monde réel. .
ToolBench
L'idée générale de ToolBench est basée sur BMTools, entraînant de grands modèles de langage dans des données supervisées.
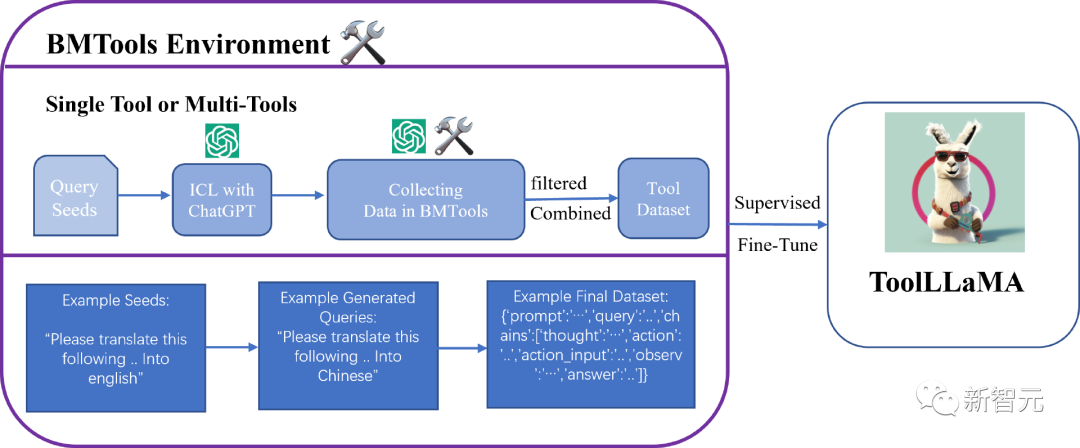
L'entrepôt contient 9 800 éléments de données obtenus à partir de 312 000 appels d'API réels, couvrant des scénarios à outil unique et des scénarios à outils multiples. Voici les informations statistiques d'un seul outil.
Chaque ligne de données est un dict json, comprenant le modèle d'invite pour la création de données, les instructions manuelles (requête) pour l'utilisation de l'outil, la boucle intermédiaire de réflexion/exécution de l'outil et la finale répondre.
Tool Descrition:BMTools Tool_name: translationTool action: get_translationaction_input: {"text": target texts, "tgt_lang": target language}Generated Data:{"prompt": "Answer the following questions as best you can. Specifically, you have access to the following APIs:\n\nget_translation: . Your input should be a json (args json schema): {{\"text\" : string, \"tgt_lang\" : string, }} The Action to trigger this API should be get_translation and the input parameters should be a json dict string. Pay attention to the type of parameters.\n\nUse the following format:\n\nQuestion: the input question you must answer\nThought: you should always think about what to do\nAction: the action to take, should be one of [get_translation]\nAction Input: the input to the action\nObservation: the result of the action\n... (this Thought/Action/Action Input/Observation can repeat N times, max 7 times)\nThought: I now know the final answer\nFinal Answer: the final answer to the original input question\n\nBegin! Remember: (1) Follow the format, i.e,\nThought:\nAction:\nAction Input:\nObservation:\nFinal Answer:\n (2) Provide as much as useful information in your Final Answer. (3) Do not make up anything, and if your Observation has no link, DO NOT hallucihate one. (4) If you have enough information and want to stop the process, please use \nThought: I have got enough information\nFinal Answer: **your response. \n The Action: MUST be one of the following:get_translation\nQuestion: {input}\n Agent scratchpad (history actions):\n {agent_scratchpad}","query": "My intention is to convert the data provided in ما هي الأقسام الثلاثة للقوات المسلحة؟ into Arabic(ara).\n","chains": [{"thought": "I need to use the get_translation API to convert the text into Arabic.","action": "get_translation","action_input": "{\"text\": \"What are the three branches of the military?\", \"tgt_lang\": \"ara\"}","observation": "\"ما هي الفروع الثلاثة للجيش ؟\""}],"answer": "The translation of \"What are the three branches of the military?\" into Arabic is \"ما هي الفروع الثلاثة للجيش ؟\"."}Expérience sur modèle
Évaluation de la machine : les chercheurs ont sélectionné au hasard 100 étapes de chaîne pour chaque outil afin de construire une plate-forme de test d'évaluation de machine, avec une moyenne de 27 étapes finales et 73 étapes d'appel d'outils intermédiaires, où la finale L'étape est évaluée à l'aide de la métrique Rouge-L et les étapes intermédiaires sont évaluées à l'aide de la métrique ExactMatch.
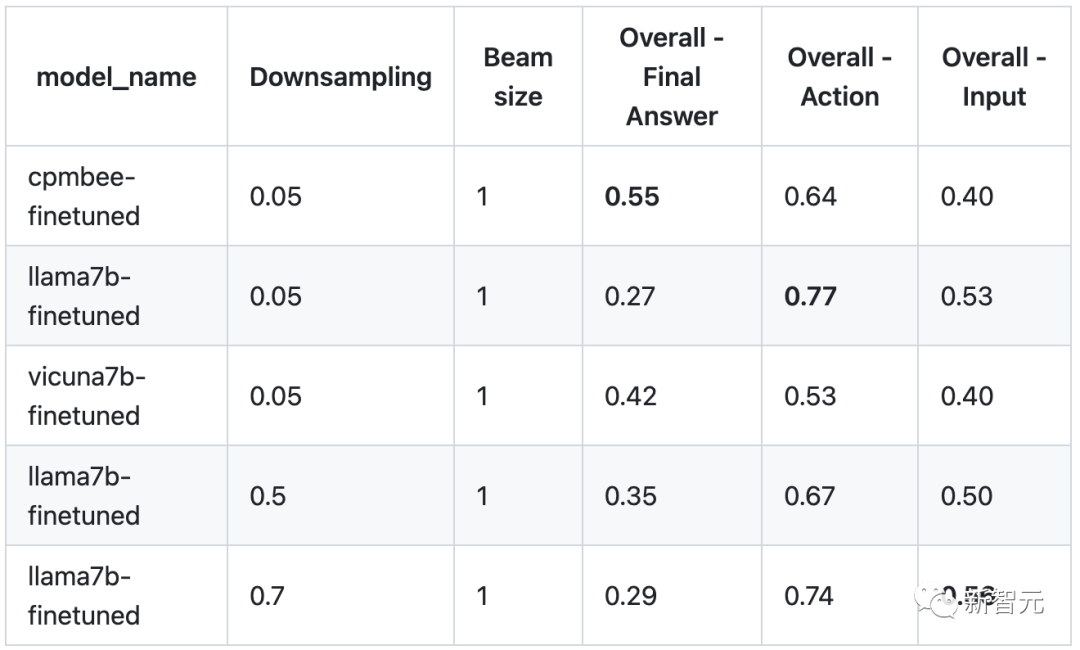
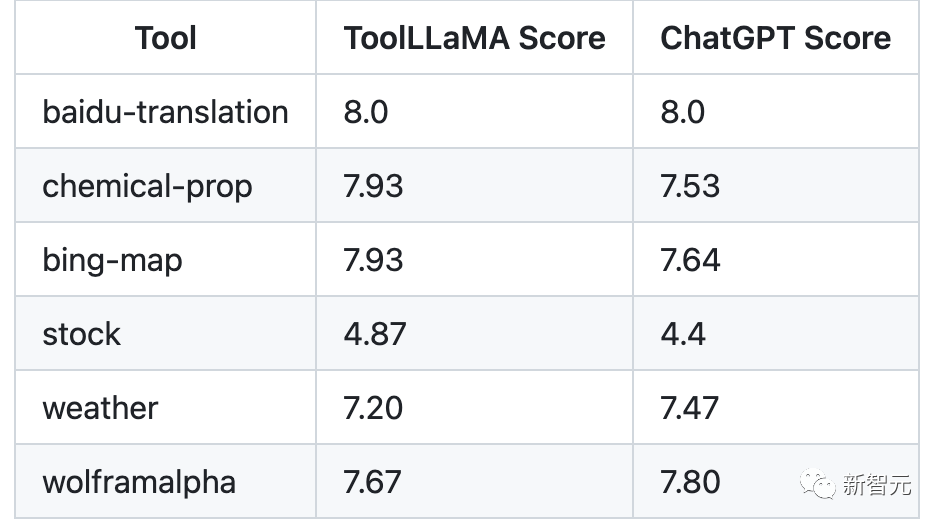
Évaluation manuelle : sélectionnez au hasard 10 requêtes parmi les outils météo, carte, stock, traduction, chimie et WolframAlpha, puis évaluez le taux de réussite du processus d'appel de l'outil, le résultat final réponse et comparaison des réponses finales de ChatGPT.
Évaluation ChatGPT : évaluation automatique des réponses et des chaînes d'utilisation des outils pour LLaMA et ChatGPT via ChatGPT.
Les résultats de l'évaluation sont les suivants (plus le score est élevé, mieux c'est). On peut voir que ToolLLaMA a des performances identiques ou meilleures que ChatGPT dans différents scénarios.
Tool Learning
Dans un article publié conjointement par des collèges et universités nationaux et étrangers bien connus tels que l'Université Tsinghua, l'Université Renmin et l'Université des postes et télécommunications de Pékin, l'apprentissage par outils a été étudiée systématiquement, présente le contexte de l'apprentissage instrumental, y compris les origines cognitives, les changements de paradigme dans les modèles sous-jacents et les rôles complémentaires des outils et des modèles.

Lien papier : https://arxiv.org/pdf/2304.08354.pdf
L'article passe également en revue les recherches existantes sur l'apprentissage des outils, y compris l'apprentissage amélioré et orienté vers les outils, et formule un cadre général d'apprentissage des outils : à partir de la compréhension des instructions utilisateur, le modèle doit apprendre à décomposer une tâche complexe en plusieurs sous-composants. , adaptez dynamiquement vos plans grâce au raisonnement et maîtrisez chaque sous-tâche efficacement en choisissant les bons outils.
L'article explique également comment former des modèles pour améliorer l'utilisation des outils et promouvoir la vulgarisation de l'apprentissage des outils.
Considérant l'absence d'évaluation systématique de l'apprentissage des outils dans les travaux antérieurs, les chercheurs ont mené des expériences avec 17 outils représentatifs et ont démontré le potentiel du modèle de base actuel dans l'utilisation habile des outils.
Le document se termine en abordant plusieurs questions ouvertes dans l'apprentissage des outils qui nécessitent des recherches plus approfondies, telles que garantir une utilisation sûre et fiable des outils, mettre en œuvre la création d'outils avec des modèles de base et résoudre les défis de personnalisation.
Référence :
https://github.com/OpenBMB/ToolBench
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
