
 Périphériques technologiques
IA
Test urgent de modèle en langue chinoise : SenseTime, Shanghai AI Lab et d'autres ont récemment publié 'Scholar·Puyu'
Périphériques technologiques
IA
Test urgent de modèle en langue chinoise : SenseTime, Shanghai AI Lab et d'autres ont récemment publié 'Scholar·Puyu'
Test urgent de modèle en langue chinoise : SenseTime, Shanghai AI Lab et d'autres ont récemment publié 'Scholar·Puyu'

Heart of Machine est sorti
Département éditorial Heart of Machine
Aujourd'hui, l'examen annuel d'entrée à l'université commence officiellement.
Ce qui diffère des années précédentes, c'est que tandis que les candidats de tout le pays se précipitent vers la salle d'examen, certains grands modèles linguistiques sont également devenus des acteurs privilégiés dans ce concours.
Alors que les grands modèles de langage d'IA démontrent de plus en plus une intelligence proche de l'humain, des examens très difficiles et complets conçus pour les humains sont de plus en plus introduits pour évaluer le niveau d'intelligence des modèles de langage.
Par exemple, dans le rapport technique sur GPT-4, OpenAI teste principalement la capacité du modèle à travers des examens dans divers domaines, et l'excellente « capacité de test » affichée par GPT-4 est également inattendue.
Comment sont les résultats de l'examen d'entrée à l'université du Chinese Language Model Challenge ? Peut-il rattraper ChatGPT ? Jetons un coup d'œil à la performance d'un « candidat ».
"Grand test" complet : "Scholar Puyu" a de nombreux résultats devant ChatGPT
Récemment, SenseTime et Shanghai AI Laboratory, en collaboration avec l'Université chinoise de Hong Kong, l'Université Fudan et l'Université Jiao Tong de Shanghai, ont publié le grand modèle de langage de paramètres de 100 milliards de niveaux « Scholar Puyu » (InternLM).
"Scholar·Puyu" possède 104 milliards de paramètres et est formé sur un ensemble de données multilingues de haute qualité contenant 1,6 billions de jetons.
Les résultats de l'évaluation complète montrent que "Scholar Puyu" non seulement réussit bien dans plusieurs tâches de test telles que la maîtrise des connaissances, la compréhension écrite, le raisonnement mathématique, la traduction multilingue, etc., mais possède également une forte capacité globale, obtenant ainsi de bons résultats à l'examen de synthèse. , il a obtenu des résultats dépassant ChatGPT dans de nombreux examens chinois, y compris l'ensemble de données (GaoKao) pour diverses matières de l'examen d'entrée à l'université chinoise.
L'équipe conjointe "Scholar·Puyu" a sélectionné plus de 20 évaluations pour le tester, y compris les quatre ensembles d'évaluation d'examen complets les plus influents au monde :
- Ensemble d'évaluation d'examens multitâches MMLU construit par des universités telles que l'Université de Californie à Berkeley ;
- AGIEval, un ensemble d'évaluation d'examens de matières lancé par Microsoft Research (comprenant l'examen d'entrée à l'université de Chine, l'examen judiciaire et les SAT, LSAT, GRE et GMAT américains, etc.) ; C-Eval, un ensemble complet d'évaluation d'examens pour les modèles de langue chinoise, construit conjointement par l'Université Jiao Tong de Shanghai, l'Université Tsinghua et l'Université d'Édimbourg
- ; Et Gaokao, un ensemble d'évaluation de questions d'examen d'entrée à l'université construit par l'équipe de recherche de l'Université de Fudan
- ;
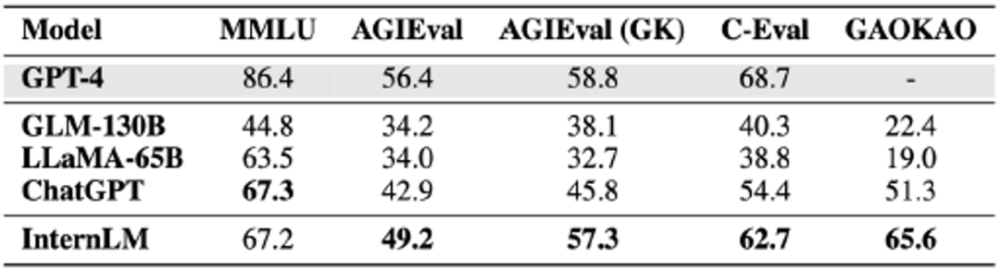
examens de synthèse reflètent les solides connaissances et l'excellente capacité globale du "Scholar·Puyu".
Bien que "Scholar·Puyu" ait obtenu d'excellents résultats lors de l'évaluation de l'examen, on peut également constater dans l'évaluation que les grands modèles de langage ont encore de nombreuses limites. "Scholar Puyu" est limité par la longueur de la fenêtre contextuelle de 2K (la longueur de la fenêtre contextuelle de GPT-4 est de 32K), et il existe des limites évidentes dans la compréhension des textes longs, le raisonnement complexe, l'écriture de code et la déduction logique mathématique. De plus, dans les conversations réelles, les grands modèles de langage présentent encore des problèmes communs tels que l'illusion et la confusion conceptuelle. Ces limitations font que l'utilisation de grands modèles de langage dans des scénarios ouverts a encore un long chemin à parcourir.
Résultats de quatre ensembles de données d'évaluation d'examen complet
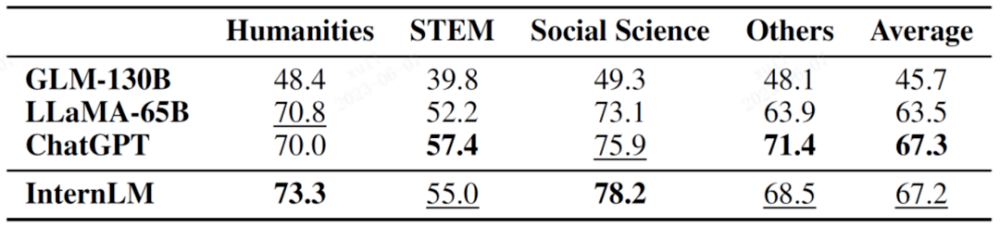
MMLU est un ensemble d'évaluation de tests multitâches construit conjointement par l'Université de Californie à Berkeley (UC Berkeley), l'Université de Columbia, l'Université de Chicago et l'UIUC, couvrant les mathématiques élémentaires, la physique, la chimie, l'informatique, l'histoire des États-Unis et le droit. , économie, diplomatie, etc.Les résultats des matières subdivisées sont présentés dans le tableau ci-dessous.
AGIEval est un nouvel ensemble d'évaluation d'examens de matières proposé par Microsoft Research cette année. Son objectif principal est d'évaluer la capacité des modèles de langage au moyen d'examens orientés, réalisant ainsi une comparaison entre l'intelligence des modèles et l'intelligence humaine.
Cet ensemble d'évaluation comprend 19 éléments d'évaluation basés sur divers examens en Chine et aux États-Unis, notamment les examens d'entrée à l'université en Chine, les examens judiciaires et des examens importants tels que SAT, LSAT, GRE et GMAT aux États-Unis. Il convient de mentionner que 9 de ces 19 spécialisations proviennent de l'examen d'entrée à l'université chinoise et sont généralement répertoriées comme un sous-ensemble d'évaluation important de l'AGIEval (GK).
Dans le tableau suivant, les matières marquées GK sont les matières de l'examen d'entrée à l'université chinoise.
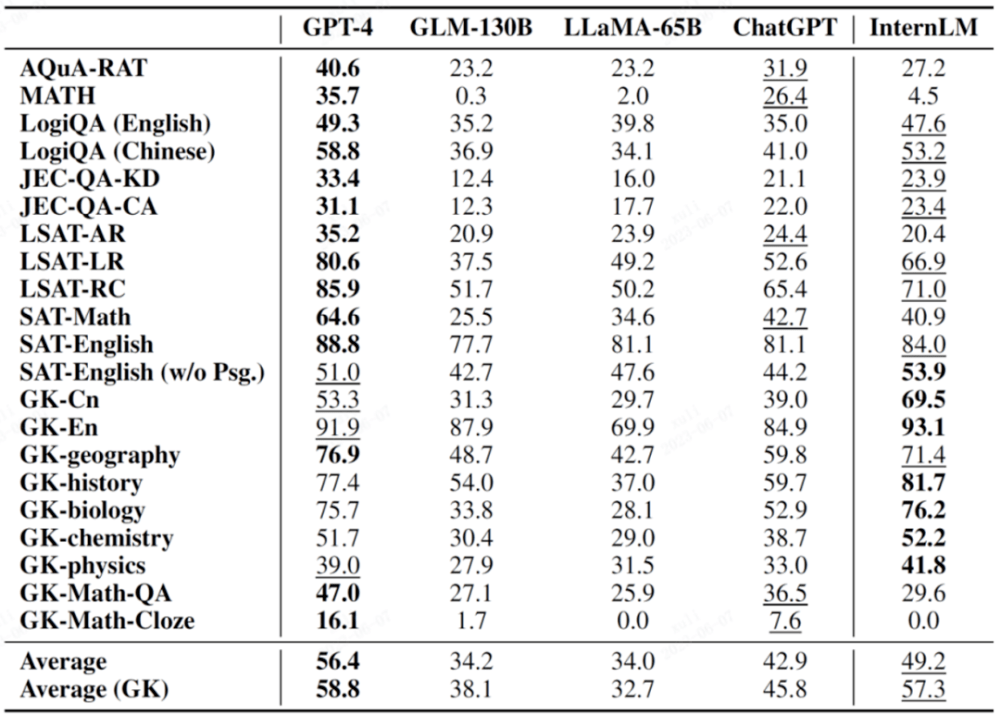
Le gras sur l'image indique le meilleur résultat et le souligné indique le deuxième résultat
C-Eval est un ensemble complet d'évaluation d'examens pour les modèles de langue chinoise construit conjointement par l'Université Jiao Tong de Shanghai, l'Université Tsinghua et l'Université d'Édimbourg.
Il contient près de 14 000 questions de test dans 52 matières, couvrant les mathématiques, la physique, la chimie, la biologie, l'histoire, la politique, l'informatique et d'autres matières, ainsi que des examens professionnels pour les fonctionnaires, les experts-comptables, les avocats et les médecins.
Les résultats des tests peuvent être obtenus via le classement.
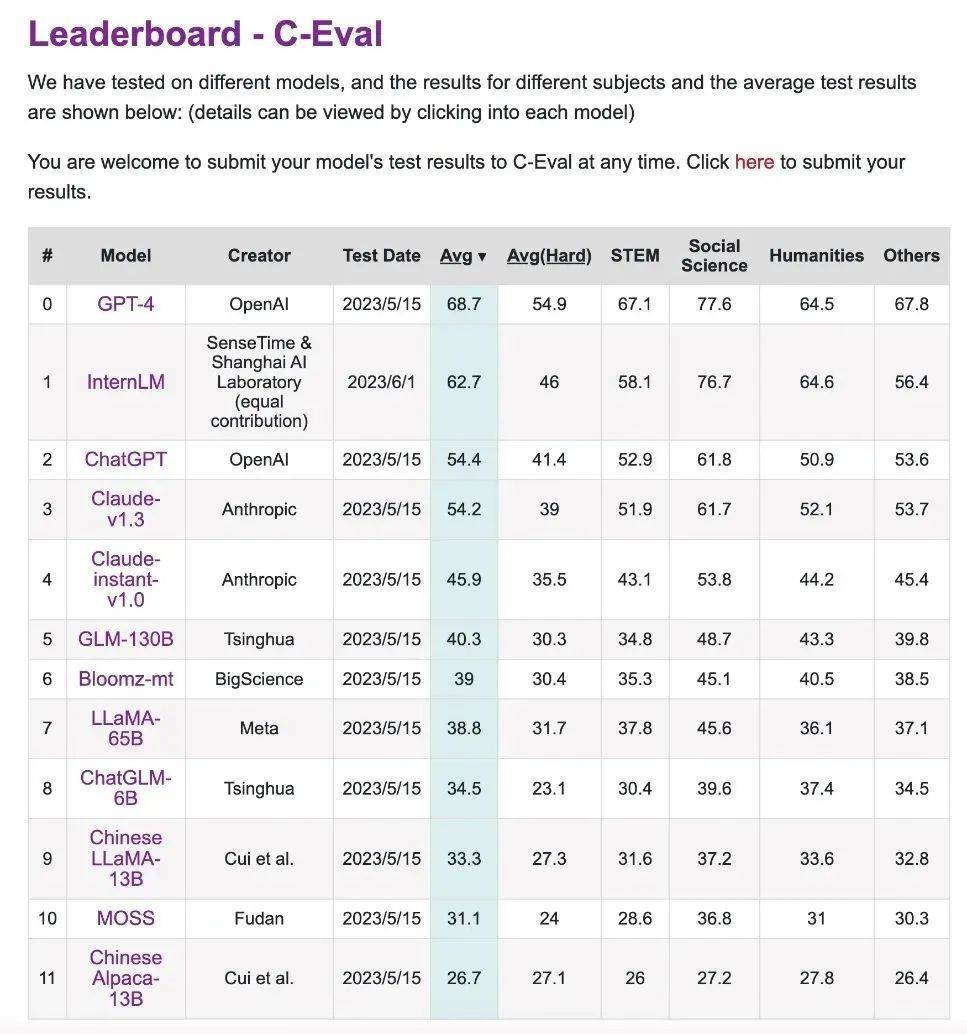
Ce lien est le classement du concours d'évaluation CEVA
Gaokao est un ensemble complet d'évaluation de tests basé sur les questions de l'examen d'entrée à l'université chinoise élaborées par l'équipe de recherche de l'Université de Fudan. Il comprend divers sujets de l'examen d'entrée à l'université chinoise, ainsi que plusieurs types de questions telles que les choix multiples, les questions à remplir. questions en blanc et questions-réponses.
Dans l'évaluation GaoKao, « Scholar·Puyu » est en tête de ChatGPT dans plus de 75 % des projets.
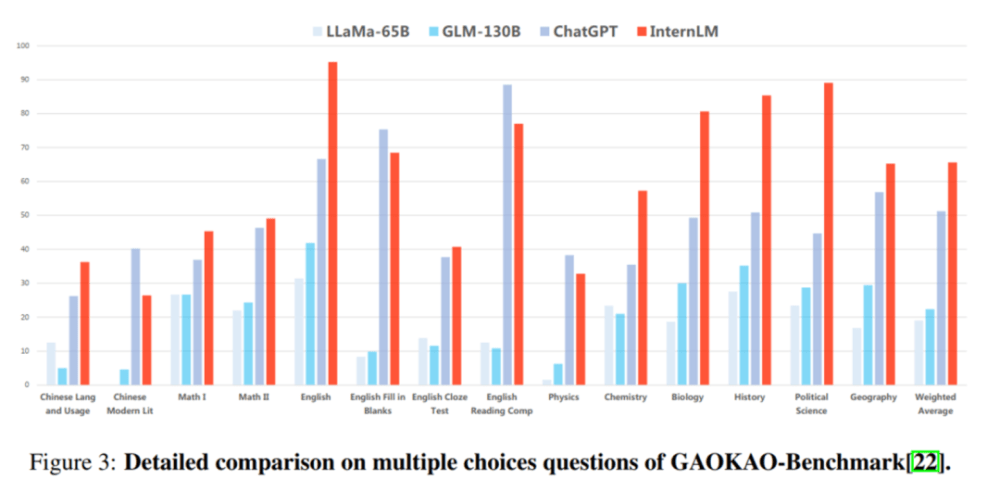
Sous-évaluation : Excellente performance en compréhension écrite et en raisonnement
Afin d'éviter la « partialité », les chercheurs ont également évalué et comparé les capacités de sous-score de modèles de langage tels que « Scholar Puyu » à travers plusieurs ensembles d'évaluation académique.
Les résultats montrent que "Scholar·Puyu" obtient non seulement de bons résultats en compréhension écrite en chinois et en anglais, mais obtient également de bons résultats en raisonnement mathématique, en capacité de programmation et dans d'autres évaluations.
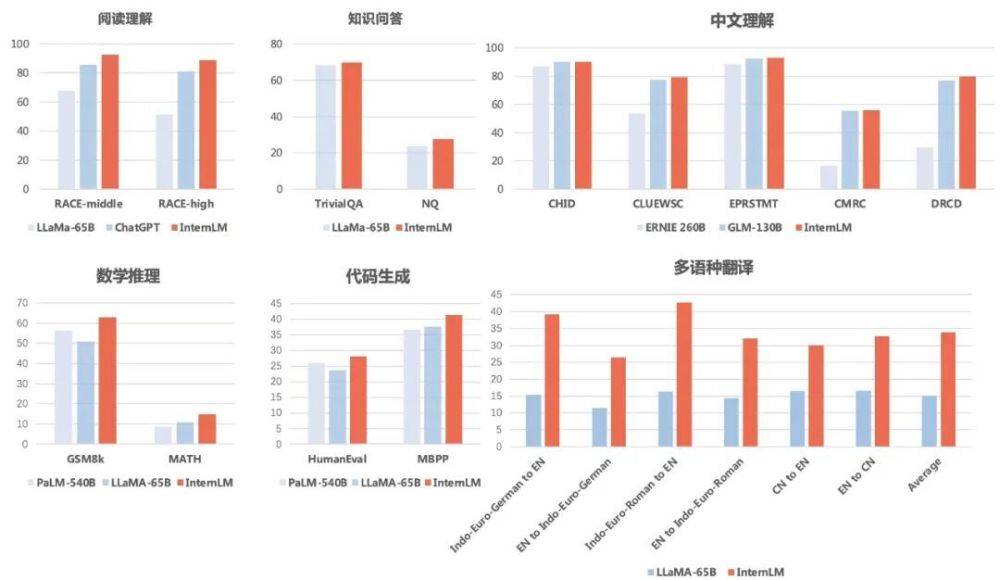
Questions et réponsesEn termes de triviaQA et NaturalQuestions, "Scholar Puyu" a obtenu des scores de 69,8 et 27,6, surpassant tous deux LLaMA-65B (scores de 68,2 et 23,8).
En termes de compréhension écrite (anglais), "Scholar·Puyu" est clairement en avance sur LLaMA-65B et ChatGPT. Puyu a obtenu 92,7 et 88,9 en compréhension écrite de l'anglais au collège et au lycée, 85,6 et 81,2 sur ChatGPT, et encore plus bas sur LLaMA-65B.
En termes de compréhension du chinois, les résultats de « Scholar Puyu » ont largement dépassé les deux principaux modèles de langue chinoise ERNIE-260B et GLM-130B.
En termes de traduction multilingue, "Scholar Puyu" a un score moyen de 33,9 en traduction multilingue, dépassant largement LLaMA (score moyen de 15,1).
Raisonnement mathématiqueEn termes de raisonnement mathématique, "Scholar Puyu" a obtenu des scores de 62,9 et 14,9 respectivement en GSM8K et MATH, deux tests de mathématiques largement utilisés pour l'évaluation, nettement devant le PaLM-540B de Google (score de 56,5 et 8,8 ) versus LLaMA-65B (scores de 50,9 et 10,9).
En termes de capacité de programmation, "Scholar Puyu" a obtenu respectivement 28,1 et 41,4 dans les deux évaluations les plus représentatives, HumanEval et MBPP (après ajustement dans le domaine du codage, le score sur HumanEval peut être amélioré à 45,7), de manière significative devant PaLM-540B (scores de 26,2 et 36,8) et LLaMA-65B (scores de 23,7 et 37,7).
En outre, les chercheurs ont également évalué la sécurité de « Scholar Puyu » sur TruthfulQA (évaluant principalement l'exactitude factuelle des réponses) et CrowS-Pairs (évaluant principalement si les réponses contiennent des biais ont atteint des niveaux avancés).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
Le codage des ambiances est de remodeler le monde du développement de logiciels en nous permettant de créer des applications en utilisant le langage naturel au lieu de lignes de code sans fin. Inspirée par des visionnaires comme Andrej Karpathy, cette approche innovante permet de dev
 Comment utiliser Dall-E 3: Conseils, exemples et fonctionnalités
Mar 09, 2025 pm 01:00 PM
Comment utiliser Dall-E 3: Conseils, exemples et fonctionnalités
Mar 09, 2025 pm 01:00 PM
Dall-E 3: Un outil de création d'images génératifs AI L'IA générative révolutionne la création de contenu, et Dall-E 3, le dernier modèle de génération d'images d'Openai, est à l'avant. Sorti en octobre 2023, il s'appuie sur ses prédécesseurs, Dall-E et Dall-E 2
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Février 2025 a été un autre mois qui change la donne pour une IA générative, nous apportant certaines des mises à niveau des modèles les plus attendues et de nouvelles fonctionnalités révolutionnaires. De Xai's Grok 3 et Anthropic's Claude 3.7 Sonnet, à Openai's G
 Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Yolo (vous ne regardez qu'une seule fois) a été un cadre de détection d'objets en temps réel de premier plan, chaque itération améliorant les versions précédentes. La dernière version Yolo V12 introduit des progrès qui améliorent considérablement la précision
 Sora vs Veo 2: Laquelle crée des vidéos plus réalistes?
Mar 10, 2025 pm 12:22 PM
Sora vs Veo 2: Laquelle crée des vidéos plus réalistes?
Mar 10, 2025 pm 12:22 PM
Veo 2 de Google et Sora d'Openai: Quel générateur de vidéos AI règne en suprême? Les deux plates-formes génèrent des vidéos d'IA impressionnantes, mais leurs forces se trouvent dans différents domaines. Cette comparaison, en utilisant diverses invites, révèle quel outil répond le mieux à vos besoins. T
 Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Gencast de Google Deepmind: une IA révolutionnaire pour les prévisions météorologiques Les prévisions météorologiques ont subi une transformation spectaculaire, passant des observations rudimentaires aux prédictions sophistiquées alimentées par l'IA. Gencast de Google Deepmind, un terreau
 Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
L'article traite des modèles d'IA dépassant Chatgpt, comme Lamda, Llama et Grok, mettant en évidence leurs avantages en matière de précision, de compréhension et d'impact de l'industrie. (159 caractères)
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
