
 Périphériques technologiques
IA
OpenAI domine les deux premiers ! Le classement des grands modèles de génération de codes est publié, avec 7 milliards de LLaMA le dépassant et étant battu par 250 millions de Codex.
Périphériques technologiques
IA
OpenAI domine les deux premiers ! Le classement des grands modèles de génération de codes est publié, avec 7 milliards de LLaMA le dépassant et étant battu par 250 millions de Codex.
OpenAI domine les deux premiers ! Le classement des grands modèles de génération de codes est publié, avec 7 milliards de LLaMA le dépassant et étant battu par 250 millions de Codex.

Récemment, un tweet de Matthias Plappert a déclenché une large discussion dans le cercle des LLM.
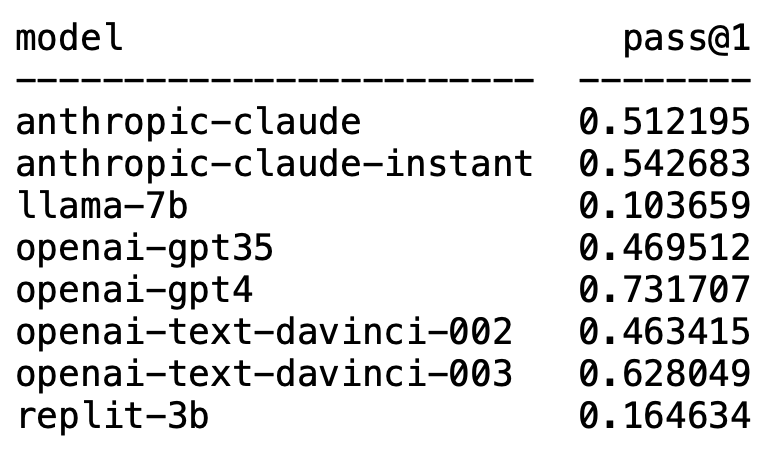
Plappert est un informaticien bien connu. Il a publié ses résultats de tests de référence sur le LLM grand public dans le cercle de l'IA sur HumanEval.
Ses tests sont orientés vers la génération de code.
Les résultats sont à la fois choquants et choquants.

De façon inattendue, GPT-4 domine sans aucun doute la liste et prend la première place.
De façon inattendue, le text-davinci-003 d'OpenAI est soudainement apparu et a pris la deuxième place.
Plappert a déclaré que text-davinci-003 peut être qualifié de modèle "trésor".
Le célèbre LLaMA n'est pas doué pour la génération de code.
OpenAI domine la liste
Plappert a déclaré que les performances de GPT-4 sont encore meilleures que les données de la littérature.
Les données du test en un tour du GPT-4 dans l'article sont un taux de réussite de 67 %, tandis que le test de Plappert a atteint 73 %.

Lors de l'analyse des causes, il a déclaré qu'il existe de nombreuses possibilités de différences dans les données. L’un d’eux est que l’invite qu’il a donnée à GPT-4 était légèrement meilleure que lorsque l’auteur de l’article l’a testée.
Une autre raison est qu'il a deviné que la température du modèle n'était pas 0 lorsque le papier a testé GPT-4.
"Température" est un paramètre utilisé pour ajuster la créativité et la diversité du modèle lors de la génération de texte. « Température » est une valeur supérieure à 0, généralement comprise entre 0 et 1. Cela affecte la distribution de probabilité des mots prédits échantillonnés lorsque le modèle génère du texte.
Lorsque la « température » du modèle est plus élevée (comme 0,8, 1 ou plus), le modèle sera plus enclin à choisir parmi des mots plus divers et différents, ce qui rend le texte généré plus risqué et plus créatif. , mais également susceptible de produire davantage d'erreurs et d'incohérences.
Et lorsque la « température » est basse (comme 0,2, 0,3, etc.), le modèle sélectionnera principalement parmi les mots avec des probabilités plus élevées, ce qui donnera un texte plus fluide et plus cohérent.
Mais à ce stade, le texte généré peut paraître trop conservateur et répétitif.
Donc, dans les applications réelles, il est nécessaire de peser et de sélectionner la valeur de « température » appropriée en fonction des besoins spécifiques.
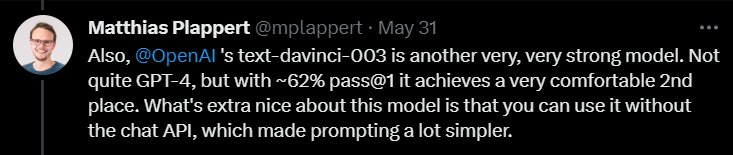
Ensuite, en commentant text-davinci-003, Plappert a déclaré qu'il s'agissait également d'un modèle très performant sous OpenAI.
Bien qu'il ne soit pas aussi bon que GPT-4, il assure toujours la deuxième place avec un taux de réussite de 62 % en une seule série de tests.
Plappert a souligné que la meilleure chose à propos de text-davinci-003 est que les utilisateurs n'ont pas besoin d'utiliser l'API de ChatGPT. Cela signifie que donner des invites peut être plus simple.
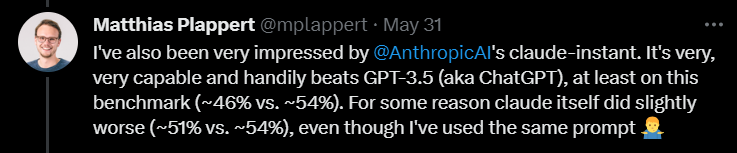
De plus, Plappert a également donné au modèle Claude-Instant d'Anthropic AI une évaluation relativement élevée.
Il pense que les performances de ce modèle sont bonnes et peuvent battre GPT-3.5. Le taux de réussite du GPT-3.5 est de 46 %, tandis que le taux de réussite de Claude-Instant est de 54 %.
Bien sûr, l'autre LLM d'Anthropic AI, Claude, ne peut pas être joué par Claude-Instant, et le taux de réussite n'est que de 51 %.
Plappert a déclaré que les invites utilisées pour tester les deux modèles sont les mêmes, si ça ne marche pas, ça ne marche pas.
En plus de ces modèles familiers, Plappert a également testé de nombreux petits modèles open source.
Plappert a dit que c'était bien qu'il puisse exécuter ces modèles localement.
Cependant, en termes d'échelle, ces modèles ne sont évidemment pas aussi grands que ceux d'OpenAI et d'Anthropic AI, donc les comparer est un peu écrasant.

Génération de code LLaMA ? Bien entendu, Plappert n’était pas satisfait des résultats des tests LLaMA.
À en juger par les résultats des tests, LLaMA fonctionne très mal dans la génération de code. Probablement parce qu'ils ont utilisé le sous-échantillonnage lors de la collecte de données depuis GitHub.
 Même comparée au Codex 2.5B, les performances de LLaMA ne sont pas les mêmes. (Taux de réussite 10% contre 22%)
Même comparée au Codex 2.5B, les performances de LLaMA ne sont pas les mêmes. (Taux de réussite 10% contre 22%)
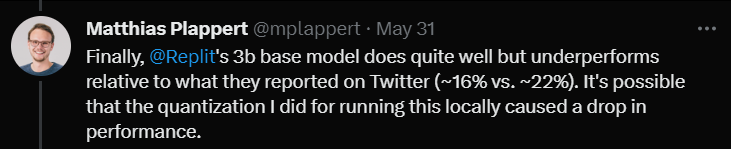
 Enfin, il a testé le modèle taille 3B de Replit.
Enfin, il a testé le modèle taille 3B de Replit.
Il a dit que la performance n'était pas mauvaise, mais comparée aux données promues sur Twitter (taux de réussite de 16% contre 22%)
Plappert pense que cela peut être dû au fait qu'il testait ce modèle. La méthode de quantification utilisé a fait baisser le taux de réussite de plusieurs points de pourcentage.
 À la fin de la revue, Plappert a mentionné un point intéressant.
À la fin de la revue, Plappert a mentionné un point intéressant.
Un utilisateur a découvert sur Twitter que GPT-3.5-turbo fonctionne mieux lors de l'utilisation de l'API Completion de la plateforme Azure (plutôt que de l'API Chat).
Plappert estime que ce phénomène a une certaine légitimité, car la saisie d'invites via l'API Chat peut être assez compliquée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



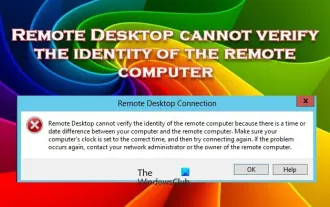 Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le Bureau à distance ne peut pas authentifier l'identité de l'ordinateur distant
Feb 29, 2024 pm 12:30 PM
Le service Bureau à distance Windows permet aux utilisateurs d'accéder aux ordinateurs à distance, ce qui est très pratique pour les personnes qui doivent travailler à distance. Cependant, des problèmes peuvent survenir lorsque les utilisateurs ne peuvent pas se connecter à l'ordinateur distant ou lorsque Remote Desktop ne peut pas authentifier l'identité de l'ordinateur. Cela peut être dû à des problèmes de connexion réseau ou à un échec de vérification du certificat. Dans ce cas, l'utilisateur devra peut-être vérifier la connexion réseau, s'assurer que l'ordinateur distant est en ligne et essayer de se reconnecter. De plus, s'assurer que les options d'authentification de l'ordinateur distant sont correctement configurées est essentiel pour résoudre le problème. De tels problèmes avec les services Bureau à distance Windows peuvent généralement être résolus en vérifiant et en ajustant soigneusement les paramètres. Le Bureau à distance ne peut pas vérifier l'identité de l'ordinateur distant en raison d'un décalage d'heure ou de date. Veuillez vous assurer que vos calculs
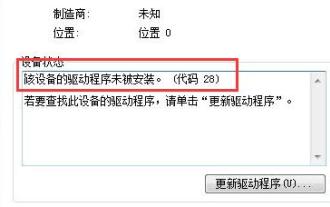 Comment résoudre le code 28 du pilote Win7
Dec 30, 2023 pm 11:55 PM
Comment résoudre le code 28 du pilote Win7
Dec 30, 2023 pm 11:55 PM
Certains utilisateurs ont rencontré des erreurs lors de l'installation du périphérique, provoquant le code d'erreur 28. En fait, cela est principalement dû au pilote. Il nous suffit de résoudre le problème du code de pilote Win7 28. Voyons ce qu'il faut faire. . Que faire avec le code 28 du pilote Win7 : Tout d'abord, nous devons cliquer sur le menu Démarrer dans le coin inférieur gauche de l'écran. Ensuite, recherchez et cliquez sur l'option "Panneau de configuration" dans le menu contextuel. Cette option est généralement située en bas ou près du bas du menu. Après avoir cliqué, le système ouvrira automatiquement l'interface du panneau de configuration. Dans le panneau de configuration, nous pouvons effectuer divers paramètres système et opérations de gestion. C'est la première étape du niveau de nettoyage nostalgique, j'espère que cela aidera. Ensuite, nous devons continuer et entrer dans le système et
 Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Publication du classement national CSRankings 2024 en informatique ! La CMU domine la liste, le MIT sort du top 5
Mar 25, 2024 pm 06:01 PM
Les classements majeurs nationaux en informatique 2024CSRankings viennent d’être publiés ! Cette année, dans le classement des meilleures universités CS aux États-Unis, l'Université Carnegie Mellon (CMU) se classe parmi les meilleures du pays et dans le domaine de CS, tandis que l'Université de l'Illinois à Urbana-Champaign (UIUC) a été classé deuxième pendant six années consécutives. Georgia Tech s'est classée troisième. Ensuite, l’Université de Stanford, l’Université de Californie à San Diego, l’Université du Michigan et l’Université de Washington sont à égalité au quatrième rang mondial. Il convient de noter que le classement du MIT a chuté et est sorti du top cinq. CSRankings est un projet mondial de classement des universités dans le domaine de l'informatique initié par le professeur Emery Berger de la School of Computer and Information Sciences de l'Université du Massachusetts Amherst. Le classement est basé sur des objectifs
 Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire avec le code d'écran bleu 0x0000001. L'erreur d'écran bleu est un mécanisme d'avertissement en cas de problème avec le système informatique ou le matériel. Le code 0x0000001 indique généralement une panne de matériel ou de pilote. Lorsque les utilisateurs rencontrent soudainement une erreur d’écran bleu lors de l’utilisation de leur ordinateur, ils peuvent se sentir paniqués et perdus. Heureusement, la plupart des erreurs d’écran bleu peuvent être dépannées et traitées en quelques étapes simples. Cet article présentera aux lecteurs certaines méthodes pour résoudre le code d'erreur d'écran bleu 0x0000001. Tout d'abord, lorsque nous rencontrons une erreur d'écran bleu, nous pouvons essayer de redémarrer
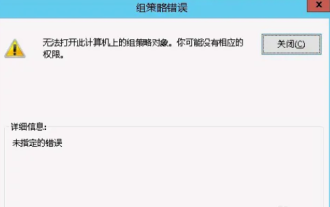 Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Impossible d'ouvrir l'objet Stratégie de groupe sur cet ordinateur
Feb 07, 2024 pm 02:00 PM
Parfois, le système d'exploitation peut mal fonctionner lors de l'utilisation d'un ordinateur. Le problème que j'ai rencontré aujourd'hui était que lors de l'accès à gpedit.msc, le système indiquait que l'objet de stratégie de groupe ne pouvait pas être ouvert car les autorisations appropriées pouvaient faire défaut. L'objet de stratégie de groupe sur cet ordinateur n'a pas pu être ouvert. Solution : 1. Lors de l'accès à gpedit.msc, le système indique que l'objet de stratégie de groupe sur cet ordinateur ne peut pas être ouvert en raison d'un manque d'autorisations. Détails : Le système ne parvient pas à localiser le chemin spécifié. 2. Une fois que l'utilisateur a cliqué sur le bouton de fermeture, la fenêtre d'erreur suivante apparaît. 3. Vérifiez immédiatement les enregistrements du journal et combinez les informations enregistrées pour découvrir que le problème réside dans le fichier C:\Windows\System32\GroupPolicy\Machine\registry.pol.
 L'ordinateur affiche fréquemment des écrans bleus et le code est différent à chaque fois
Jan 06, 2024 pm 10:53 PM
L'ordinateur affiche fréquemment des écrans bleus et le code est différent à chaque fois
Jan 06, 2024 pm 10:53 PM
Le système Win10 est un très excellent système à haute intelligence. Sa puissante intelligence peut apporter la meilleure expérience utilisateur aux utilisateurs. Dans des circonstances normales, les ordinateurs du système Win10 des utilisateurs n'auront aucun problème ! Cependant, il est inévitable que divers défauts se produisent sur d'excellents ordinateurs. Récemment, des amis ont signalé que leurs systèmes Win10 rencontraient fréquemment des écrans bleus ! Aujourd'hui, l'éditeur vous proposera des solutions aux différents codes qui provoquent des écrans bleus fréquents sur les ordinateurs Windows 10. Jetons un coup d'œil. Solutions aux écrans bleus fréquents de l'ordinateur avec des codes différents à chaque fois : causes des différents codes d'erreur et suggestions de solutions 1. Cause de l'erreur 0×000000116 : Il se peut que le pilote de la carte graphique soit incompatible. Solution : Il est recommandé de remplacer le pilote d'origine du fabricant. 2,
 Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Code de terminaison 0xc000007b Lors de l'utilisation de votre ordinateur, vous rencontrez parfois divers problèmes et codes d'erreur. Parmi eux, le code de terminaison est le plus inquiétant, notamment le code de terminaison 0xc000007b. Ce code indique qu'une application ne peut pas démarrer correctement, provoquant des désagréments pour l'utilisateur. Tout d’abord, comprenons la signification du code de terminaison 0xc000007b. Ce code est un code d'erreur du système d'exploitation Windows qui se produit généralement lorsqu'une application 32 bits tente de s'exécuter sur un système d'exploitation 64 bits. Cela signifie que ça devrait
 Explication détaillée des causes et des solutions du code d'écran bleu 0x0000007f
Dec 25, 2023 pm 02:19 PM
Explication détaillée des causes et des solutions du code d'écran bleu 0x0000007f
Dec 25, 2023 pm 02:19 PM
L'écran bleu est un problème que nous rencontrons souvent lors de l'utilisation du système. Selon le code d'erreur, il existe de nombreuses raisons et solutions différentes. Par exemple, lorsque nous rencontrons le problème d'arrêt : 0x0000007f, il peut s'agir d'une erreur matérielle ou logicielle. Suivons l'éditeur pour découvrir la solution. Raison du code d'écran bleu 0x000000c5 : Réponse : La mémoire, le processeur et la carte graphique sont soudainement overclockés ou le logiciel ne fonctionne pas correctement. Solution 1 : 1. Continuez à appuyer sur F8 pour entrer lors du démarrage, sélectionnez le mode sans échec et appuyez sur Entrée pour entrer. 2. Après être entré en mode sans échec, appuyez sur win+r pour ouvrir la fenêtre d'exécution, entrez cmd et appuyez sur Entrée. 3. Dans la fenêtre d'invite de commande, saisissez « chkdsk /f /r », appuyez sur Entrée, puis appuyez sur la touche y. 4.
