
 Périphériques technologiques
IA
Un long article de 10 000 mots explique l'application des grands modèles dans le domaine de la conduite autonome
Périphériques technologiques
IA
Un long article de 10 000 mots explique l'application des grands modèles dans le domaine de la conduite autonome
Un long article de 10 000 mots explique l'application des grands modèles dans le domaine de la conduite autonome

Avec la popularité de ChatGPT, les grands modèles reçoivent de plus en plus d'attention, et les capacités affichées par les grands modèles sont étonnantes.
Dans les domaines de la génération d'images, des systèmes de recommandation, de la traduction automatique et d'autres domaines, les grands modèles ont commencé à jouer un rôle. Compte tenu de quelques mots rapides, les dessins de conception générés par le site Web de génération d'images Midjourney ont même dépassé le niveau de nombreux designers professionnels.
Pourquoi les grands modèles peuvent-ils montrer des capacités étonnantes ? Pourquoi les performances du modèle s'améliorent-elles à mesure que le nombre de paramètres et la capacité du modèle augmentent ?
Un expert d'une société d'algorithmes d'IA a déclaré à l'auteur : L'augmentation du nombre de paramètres du modèle peut être comprise comme une augmentation de la dimension du modèle, ce qui signifie que nous pouvons utiliser des moyens plus complexes pour simuler le lois du monde réel. Prenons le scénario le plus simple comme exemple. Étant donné un nuage de points sur un plan, si nous utilisons une ligne droite (une fonction à une variable) pour décrire le modèle de points de dispersion sur le tracé, alors quels que soient les paramètres, il y aura il y en aura toujours. Le point est en dehors de cette ligne. Si nous utilisons une fonction binaire pour représenter le modèle de ces points, alors davantage de points tomberont sur cette ligne de fonction. À mesure que la dimension de la fonction augmente ou que le degré de liberté augmente, de plus en plus de points tomberont sur cette ligne, ce qui signifie que les lois de ces points seront ajustées avec plus de précision.
En d'autres termes, plus le nombre de paramètres du modèle est grand, plus il est facile pour le modèle de s'adapter aux lois des données massives.
Avec l'émergence de ChatGPT, les gens ont découvert que lorsque les paramètres du modèle atteignent un certain niveau, l'effet n'est pas seulement « de meilleures performances », mais « meilleur que prévu ».
Dans le domaine du NLP (Natural Language Processing), il existe un phénomène passionnant dont les milieux académiques et industriels n'ont pas encore été en mesure d'expliquer les principes spécifiques de : « Emerging Ability ».
Qu’est-ce que « l’émergence » ? « Émergence » signifie que lorsque le nombre de paramètres du modèle augmente linéairement jusqu'à un certain niveau, la précision du modèle augmente de façon exponentielle.
Nous pouvons regarder une image. Le côté gauche de l'image ci-dessous montre la loi de mise à l'échelle. Il s'agit d'un phénomène découvert par les chercheurs d'OpenAI avant 2022. C'est-à-dire que, à mesure que l'échelle des paramètres du modèle augmente de façon exponentielle, la précision de. le modèle augmente linéairement. Les paramètres du modèle dans l'image de gauche ne croissent pas de façon exponentielle mais linéaire.
En janvier 2022, certains chercheurs ont découvert que lorsque l'échelle des paramètres du modèle dépasse un certain niveau, le degré d'amélioration de la précision du modèle dépasse largement la proportionnalité. courbe, comme suit Sur la photo de droite.
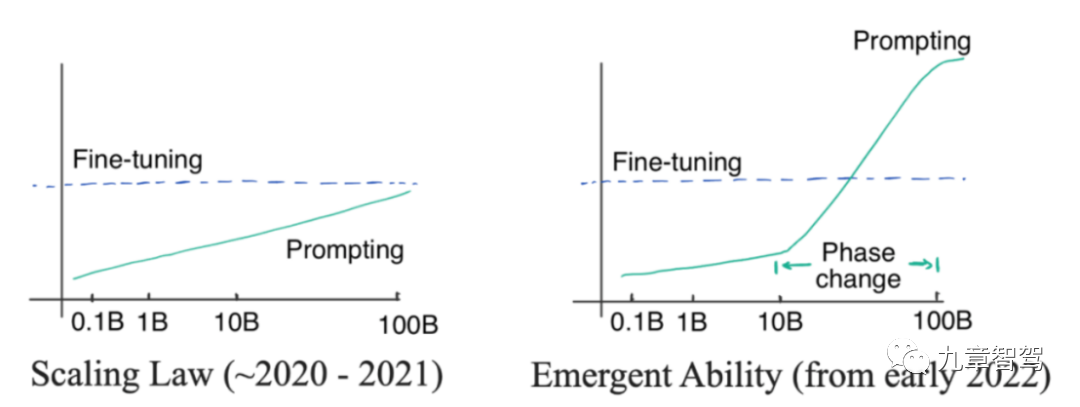
Diagramme "Emergence"
Mis en œuvre au niveau de l'application, nous constaterons que les grands modèles peuvent accomplir certaines tâches que les petits modèles ne peuvent pas accomplir, comme les grands modèles peuvent ajouter et soustraire, et faire raisonnement sur des tâches simples, etc.
Quel type de modèle peut-on appeler grand modèle ?
D'une manière générale, nous pensons que les modèles comportant plus de 100 millions de paramètres peuvent être appelés « grands modèles ». Dans le domaine de la conduite autonome, les grands modèles ont principalement deux significations : l'une est un modèle avec plus de 100 millions de paramètres ; l'autre est un modèle composé de plusieurs petits modèles superposés, bien que le nombre de paramètres soit inférieur à 100 millions. est également appelé modèle comme « grand modèle ».
Selon cette définition, les grands modèles ont commencé à être largement utilisés dans le domaine de la conduite autonome. Dans le cloud, nous pouvons profiter des avantages de capacité apportés par le nombre croissant de paramètres de modèle et utiliser de grands modèles pour effectuer certaines tâches telles que l'exploration de données et l'annotation de données. Du côté de la voiture, nous pouvons fusionner plusieurs petits modèles responsables de différentes sous-tâches en un seul « grand modèle », ce qui peut permettre de gagner du temps de raisonnement dans le calcul côté voiture et d'augmenter la sécurité.
Concrètement, comment les grands modèles peuvent-ils entrer en jeu ? Selon les informations communiquées par l'auteur aux experts du secteur, l'industrie utilise actuellement principalement de grands modèles dans le domaine de la perception. Nous présenterons ensuite comment les grands modèles permettent des tâches de perception respectivement dans le cloud et côté voiture.
01
Application de grands modèles
1.1 Application de grands modèles dans le cloud
1.1.1 Étiquetage automatique des données
Grâce à la pré-formation des grands modèles, l'étiquetage automatique peut être atteint. En prenant l'annotation de clips vidéo comme exemple, vous pouvez d'abord utiliser des données de clips massives non étiquetées pour pré-entraîner un grand modèle via l'auto-supervision, puis utiliser une petite quantité de données de clips étiquetées manuellement pour affiner le modèle afin que le modèle ait capacités de détection. Le modèle peut annoter automatiquement les données de clip.
Plus la précision d'étiquetage du modèle est élevée, plus le degré de remplacement des personnes est élevé.
Actuellement, de nombreuses entreprises étudient comment améliorer la précision de l'étiquetage automatique des grands modèles, dans l'espoir d'obtenir un étiquetage automatique complet et sans pilote une fois que la précision atteint la norme.
Leo, directeur des produits de conduite intelligente de SenseTime Jueying, a déclaré à l'auteur : Nous avons effectué des évaluations et constaté que pour les cibles courantes sur la route, la précision de l'étiquetage automatique des grands modèles de SenseTime peut atteindre plus de 98 %. manière, examen manuel ultérieur Les étapes peuvent être très rationalisées.
Dans le processus de développement de produits de conduite intelligente, SenseTime Jueying a introduit le pré-étiquetage automatique des grands modèles pour la plupart des tâches de perception Par rapport au passé, l'obtention du même nombre d'échantillons de données nécessite moins de cycles d'étiquetage et de coûts d'étiquetage. .Il peut être réduit des dizaines de fois, améliorant considérablement l'efficacité du développement.
De manière générale, les attentes de chacun en matière de tâches d'annotation incluent principalement une grande efficacité du processus d'annotation, une grande précision et une grande cohérence des résultats d'annotation. Une efficacité élevée et une précision élevée sont faciles à comprendre. Que signifient une cohérence élevée ? Dans l’algorithme BEV pour la reconnaissance 3D, les ingénieurs doivent utiliser l’annotation conjointe du lidar et de la vision, et doivent traiter conjointement les nuages de points et les données d’image. Dans ce type de lien de traitement, les ingénieurs peuvent également avoir besoin de faire des annotations au niveau du timing, afin que les résultats des images précédentes et suivantes ne puissent pas être trop différents.
Si l'annotation manuelle est utilisée, l'effet d'annotation dépend du niveau d'annotation de l'annotateur. Le niveau inégal des annotateurs peut conduire à des résultats d'annotation incohérents. La zone d'annotation dans une image peut être plus grande que la suivante. L'image est relativement petite, les résultats d'annotation des grands modèles sont généralement plus cohérents.
Cependant, certains experts du secteur ont signalé qu'il existe encore des difficultés à mettre en œuvre l'annotation automatique de grands modèles dans des applications pratiques, en particulier dans la relation entre les sociétés de conduite autonome et les sociétés d'annotation - de nombreuses sociétés de conduite autonome étiquetteront une partie du le travail est sous-traité à des sociétés d'annotation, et certaines entreprises ne disposent pas d'équipe d'annotation interne, donc tout le travail d'annotation est externalisé.
Actuellement, les cibles annotées à l'aide de la méthode de pré-annotation du grand modèle sont principalement des cibles 3D dynamiques. L'entreprise de conduite autonome utilisera d'abord le grand modèle pour faire des inférences sur la vidéo qui doit être annotée, puis l'utilisera. le résultat de l'inférence - le modèle La boîte 3D générée est remise à l'entreprise d'étiquetage. Lors de la pré-annotation d'un grand modèle, puis de la transmission des résultats pré-annotés à une société d'annotation, deux problèmes principaux sont impliqués : l'un est que les plates-formes d'annotation de certaines sociétés d'annotation ne prennent pas nécessairement en charge le chargement de résultats pré-annotés ; est que la société d'annotation n'est pas nécessairement disposée à apporter des modifications aux résultats pré-annotés.
Si une société d'annotation souhaite charger des résultats pré-annotés, elle a besoin d'une plate-forme logicielle prenant en charge le chargement d'images 3D générées par de grands modèles. Cependant, certaines sociétés d'annotation peuvent principalement utiliser l'annotation manuelle et ne disposent pas d'une plate-forme logicielle prenant en charge le chargement des résultats de pré-annotation du modèle. Si elles obtiennent des résultats de modèle pré-annotés lors de la connexion avec les clients, elles n'ont aucun moyen de les accepter.
De plus, du point de vue des entreprises d'annotation, ce n'est que si l'effet de pré-annotation est suffisamment bon qu'elles peuvent véritablement « économiser des efforts », sinon elles risquent d'augmenter leur charge de travail.
Si l'effet de pré-étiquetage n'est pas assez bon, l'entreprise d'étiquetage devra encore faire beaucoup de travail à l'avenir, comme étiqueter les boîtes manquantes, supprimer les boîtes mal étiquetées, unifier la taille des boîtes, etc. . Ensuite, l’utilisation de la pré-annotation ne les aidera peut-être pas vraiment à réduire leur charge de travail.
Par conséquent, dans les applications pratiques, l'utilisation ou non de grands modèles pour la pré-annotation doit être évaluée par l'entreprise de conduite autonome et l'entreprise d'annotation.
Bien sûr, le coût actuel de l'annotation manuelle est relativement élevé - si l'entreprise d'annotation est autorisée à repartir de zéro, le coût de l'annotation manuelle de 1 000 images de données vidéo peut atteindre 10 000 yuans. Par conséquent, les entreprises de conduite autonome espèrent toujours améliorer autant que possible la précision du pré-étiquetage des grands modèles et réduire autant que possible la charge de travail de l'étiquetage manuel, réduisant ainsi les coûts d'étiquetage.
1.1.2 Exploration de données
Les grands modèles ont une forte généralisation et conviennent à l'extraction de données à longue traîne.
Un expert de WeRide a déclaré à l'auteur : Si la méthode traditionnelle basée sur les balises est utilisée pour exploiter les scènes à longue traîne, le modèle ne peut généralement distinguer que les catégories d'images connues. En 2021, OpenAI a publié le modèle CLIP (un modèle multimodal texte-image qui peut faire correspondre du texte et des images après un pré-entraînement non supervisé, classant ainsi les images en fonction du texte au lieu de s'appuyer uniquement sur les étiquettes des images) ), nous pouvons adoptez également un tel modèle multimodal texte-image et utilisez des descriptions textuelles pour récupérer les données d'image dans le journal de conduite. Par exemple, des scènes à longue traîne telles que « des véhicules de construction traînant des marchandises » et « des feux de circulation avec deux ampoules allumées en même temps ».
De plus, les grands modèles peuvent mieux extraire les caractéristiques des données, puis trouver des cibles présentant des caractéristiques similaires.
Supposons que nous souhaitions trouver des images contenant des agents d'assainissement à partir de nombreuses images. Nous n'avons pas besoin d'étiqueter spécifiquement les images au préalable. Nous pouvons pré-entraîner le grand modèle avec un grand nombre d'images contenant des agents d'assainissement, et le grand. Un modèle peut en être extrait. Caractéristiques de certains agents d’assainissement. Ensuite, des échantillons correspondant aux caractéristiques des agents d'assainissement sont trouvés à partir des images, éliminant ainsi presque toutes les images contenant des agents d'assainissement.
1.1.3 Utiliser la distillation des connaissances pour « enseigner » aux petits modèles
Les grands modèles peuvent également utiliser la distillation des connaissances pour « enseigner » les petits modèles.
Qu'est-ce que la distillation des connaissances ? Pour l'expliquer dans les termes les plus courants, le grand modèle apprend d'abord certaines connaissances à partir des données, ou extrait certaines informations, puis utilise les connaissances acquises pour « enseigner » le petit modèle.
En pratique, nous pouvons d'abord apprendre les images qui doivent être étiquetées par le grand modèle. Le grand modèle peut étiqueter ces images et utiliser ces images pour la formation. moyen le plus simple de distiller des connaissances.
Bien sûr, nous pouvons également utiliser des méthodes plus complexes, comme l'utilisation d'un grand modèle pour extraire des fonctionnalités à partir de données massives, et ces fonctionnalités extraites peuvent être utilisées pour entraîner de petits modèles. En d'autres termes, nous pouvons également concevoir un modèle plus complexe et ajouter un modèle moyen entre le grand modèle et le petit modèle. Les fonctionnalités extraites par le grand modèle entraînent d'abord le modèle moyen, puis utilisent le modèle moyen entraîné pour extraire les fonctionnalités et. donnez-les au petit modèle. Les ingénieurs peuvent choisir la méthode de conception en fonction de leurs propres besoins.
L'auteur a appris de Xiaomi.ai que la distillation et le réglage fin basés sur les caractéristiques extraites du grand modèle peuvent être utilisés pour obtenir de petits modèles tels que l'attention et la reconnaissance des intentions des piétons. De plus, puisqu'un grand modèle est partagé dans le. Lors de l'étape d'extraction des caractéristiques, la quantité de calcul peut être réduite.
1.1.4 Tester la limite supérieure de performance du modèle de voiture
Le grand modèle peut également être utilisé pour tester la limite supérieure de performance du modèle de voiture. Lorsque certaines entreprises réfléchissent au modèle à déployer dans la voiture, elles testent d'abord plusieurs modèles alternatifs dans le cloud pour voir quel modèle a le meilleur effet et dans quelle mesure les meilleures performances peuvent être obtenues après avoir augmenté le nombre de paramètres.
Ensuite, utilisez le modèle le plus performant comme modèle de base, puis personnalisez et optimisez le modèle de base avant de le déployer sur le véhicule.
1.1.5 Reconstruction et génération de données de scènes de conduite autonome
Haomo Zhixing a mentionné lors de l'AI DAY en janvier 2023 : « En utilisant la technologie NeRF, nous pouvons stocker implicitement la scène. Dans le réseau neuronal, le Les paramètres implicites de la scène sont appris grâce à l'apprentissage supervisé des images rendues, puis la scène de conduite autonome peut être reconstruite. »
Par exemple, nous pouvons saisir des images, des poses correspondantes et des nuages de points denses de scènes colorées dans le réseau, et en fonction du réseau de grille de points, les nuages de points colorés seront rastérisés à différentes résolutions en fonction de la pose de l'image d'entrée. isation, génèrent des descripteurs neuronaux à plusieurs échelles, puis fusionnent des fonctionnalités à différentes échelles via le réseau.
Ensuite, le descripteur, la position, les paramètres de caméra correspondants et les paramètres d'exposition de l'image du nuage de points dense généré sont entrés dans le réseau suivant pour un mappage de tonalité affiné, et une image avec une couleur et une exposition cohérentes peut être synthétisée.
De cette façon, nous pouvons réaliser la reconstruction de la scène. Ensuite, nous pouvons générer diverses données de haute réalité en changeant la perspective, en changeant l'éclairage et en changeant le matériau de texture. Par exemple, en changeant la perspective, nous pouvons simuler divers comportements principaux du véhicule tels que les changements de voie, les détours, les demi-tours. , etc., et même simuler certaines données de scénarios de collisions imminentes.
1.2 Application de grands modèles côté voiture
1.2.1 Fusion de petits modèles utilisés pour détecter différentes tâches
En utilisant de grands modèles côté voiture, la forme principale est de traiter différentes sous-tâches Les petits modèles sont fusionnés pour former un « grand modèle », puis une inférence conjointe est effectuée. Le « grand modèle » ne signifie pas ici un grand nombre de paramètres au sens traditionnel du terme – par exemple, un grand modèle avec plus de 100 millions de paramètres. Bien entendu, le modèle combiné sera beaucoup plus grand que le petit modèle qui gère différentes sous-tâches.
Dans le modèle traditionnel de perception côté voiture, les modèles qui gèrent différentes sous-tâches effectuent des inférences indépendamment. Par exemple, un modèle est responsable de la tâche de détection des lignes de voie et un autre modèle est responsable de la tâche de détection des feux de circulation. À mesure que les tâches de perception augmentent, les ingénieurs ajouteront en conséquence des modèles pour percevoir des cibles spécifiques dans le système.
Dans le passé, le système de conduite automatique avait moins de fonctions et les tâches de perception étaient relativement faciles. Cependant, avec la mise à niveau des fonctions du système de conduite automatique, il existe encore de plus en plus de tâches de perception. Utilisé séparément, les petits modèles responsables des tâches correspondantes sont utilisés séparément. Selon la méthode de raisonnement, le retard du système sera trop important et il y aura des risques de sécurité.
Le cadre de perception multitâche BEV de Juefei Technology combine de petits modèles de perception à tâche unique de différentes cibles pour former un système capable de produire des informations statiques en même temps - y compris les lignes de voie, les flèches au sol, les passages piétons aux intersections et les arrêts. lignes, etc., ainsi que des informations dynamiques - y compris l'emplacement, la taille, l'orientation, etc. des usagers de la route. Le cadre d'algorithme de perception multitâche BEV de Juefei Technology est présenté dans la figure ci-dessous :
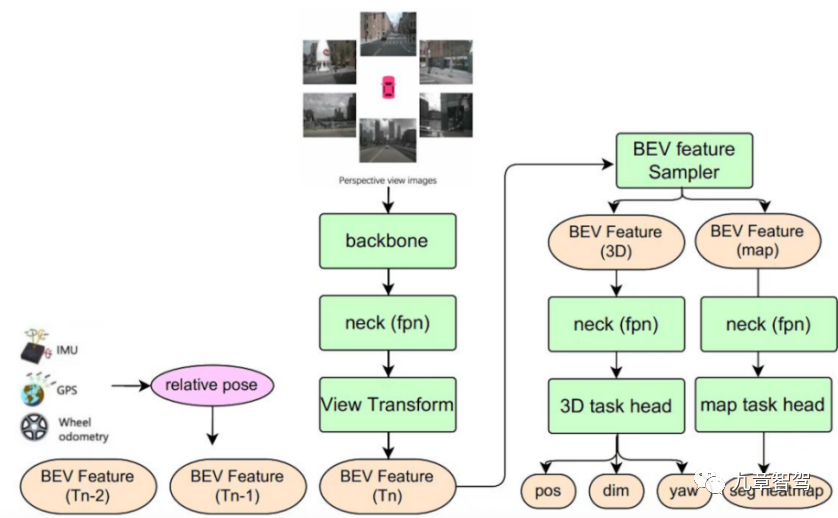
Diagramme schématique du cadre d'algorithme de perception multitâche BEV de Juefei Technology
Ce multi-tâche Le modèle de perception des tâches implémente la synchronisation des fonctionnalités Fusion - stockez les fonctionnalités BEV aux moments historiques dans la file d'attente des fonctionnalités. Dans la phase d'inférence, en fonction du système de coordonnées du véhicule au moment actuel, les fonctionnalités BEV aux moments historiques sont alignées spatio-temporellement ( y compris la rotation et la translation des caractéristiques) en fonction de l'état de mouvement du véhicule, puis associez les caractéristiques BEV alignées du moment historique avec les caractéristiques BEV du moment actuel.
Dans les scénarios de conduite autonome, la fusion temporelle peut améliorer la précision de l'algorithme de perception et compenser dans une certaine mesure les limites de la perception d'une seule image. En prenant comme exemple la sous-tâche de détection de cible 3D présentée dans la figure, avec la fusion temporelle, le modèle de perception peut détecter certaines cibles qui ne peuvent pas être détectées par le modèle de perception à image unique (telles que les cibles qui sont masquées à l'heure actuelle), et peut également juger la vitesse de déplacement de la cible avec plus de précision et aider les tâches en aval dans la prédiction de la trajectoire de la cible.
Le Dr Qi Yuhan, responsable de la technologie de détection BEV chez Juefei Technology, a déclaré à l'auteur : En utilisant une telle architecture modèle, lorsque les tâches de détection deviennent de plus en plus complexes, le cadre de détection conjointe multitâche peut assurer une détection en temps réel. et peut également produire des résultats de perception de plus en plus précis pour une utilisation en aval du système de conduite autonome.
Cependant, la fusion de petits modèles multitâches posera également quelques problèmes. D'un point de vue algorithmique, les performances du modèle fusionné sur différentes sous-tâches peuvent être « annulées », c'est-à-dire que les performances de détection du modèle sont inférieures à celles du modèle indépendant à tâche unique. Bien que la structure de réseau d'un grand modèle formé par la fusion de différents petits modèles puisse encore être très sophistiquée, le modèle combiné doit résoudre le problème de la formation conjointe multitâche.
Dans un entraînement conjoint multitâche, chaque sous-tâche peut ne pas être en mesure d'atteindre une convergence simultanée et synchrone, et les tâches seront affectées par un « transfert négatif », et le modèle combiné aura une mauvaise précision sur certaines tâches spécifiques. . "Retomber". L'équipe d'algorithmes doit optimiser autant que possible la structure du modèle fusionné, ajuster la stratégie de formation commune et réduire l'impact du phénomène de « transfert négatif ».
1.2.2 Détection d'objets
Un expert de l'industrie a déclaré à l'auteur : Certains objets avec des valeurs vraies relativement fixes conviennent à la détection avec de grands modèles.
Alors, qu'est-ce qu'un objet dont la vraie valeur est relativement fixe ?
Les soi-disant objets avec des valeurs de vérité fixes sont des objets dont la vraie valeur ne sera pas affectée par la météo, le temps et d'autres facteurs, tels que les lignes de voie, les piliers, les lampadaires, les feux de circulation, les passages piétons, le parking en sous-sol. lignes, places de stationnement, etc. L'existence et l'emplacement de ces objets sont fixes et ne changeront pas en raison de facteurs tels que la pluie ou l'obscurité. Tant que le véhicule traverse la zone correspondante, leurs positions sont fixes. De tels objets conviennent à la détection avec de grands modèles.
1.2.3 Prédiction de la topologie des voies
Une entreprise de conduite autonome mentionnée lors de l'AI DAY de l'entreprise : « Nous utilisons la carte standard comme informations de guidage basées sur la carte des fonctionnalités BEV, utilisons l'encodage autorégressif. et un réseau de décodage pour décoder les caractéristiques BEV en une séquence de points topologiques structurés pour réaliser une prédiction de topologie de voie "
02
Comment faire bon usage des grands modèles
Sous la tendance de l'open source dans l'industrie, le bases Le cadre du modèle n'est pas un secret. Souvent, ce qui détermine si une entreprise peut fabriquer un bon produit, ce sont ses capacités d’ingénierie.
Les capacités d'ingénierie déterminent si nous pouvons vérifier rapidement la faisabilité de l'idée lorsque nous pensons à certaines méthodes qui peuvent être efficaces pour améliorer les capacités du système. Le point commun entre Tesla et Open AI est que les deux sociétés disposent de solides capacités d’ingénierie. Elles peuvent tester la fiabilité d’une idée le plus rapidement possible, puis appliquer des données à grande échelle au modèle sélectionné.
Pour utiliser pleinement les capacités des grands modèles dans la pratique, les capacités d'ingénierie de l'entreprise sont très importantes. Ensuite, nous expliquerons quels types de capacités d'ingénierie sont nécessaires pour faire bon usage des grands modèles en fonction du processus de développement du modèle.
2.1 Mettre à niveau le système de stockage de données et de transfert de fichiers
Les paramètres des grands modèles sont importants et, par conséquent, la quantité de données utilisée pour entraîner les grands modèles est également importante. Par exemple, l’équipe d’algorithmes de Tesla a utilisé environ 1,4 milliard d’images pour entraîner le réseau d’occupation 3D dont l’équipe a parlé lors de l’AI Day l’année dernière.
En fait, la valeur initiale du nombre d'images sera probablement des dizaines ou des centaines de fois le nombre réel utilisé, car nous devons d'abord filtrer les données précieuses pour la formation du modèle à partir des données massives. puisqu'il est utilisé pour le modèle, le nombre d'images d'entraînement est de 1,4 milliard, le nombre d'images originales doit donc être bien supérieur à 1,4 milliard.
Alors, comment stocker des dizaines de milliards voire des centaines de milliards de données d'images ? Il s’agit d’un énorme défi tant pour les systèmes de lecture de fichiers que pour les systèmes de stockage de données. En particulier, les données actuelles de conduite autonome se présentent sous forme de clips et le nombre de fichiers est important, ce qui nécessite une grande efficacité dans le stockage immédiat des petits fichiers.
Afin de faire face à de tels défis, certaines entreprises du secteur adoptent une méthode de stockage par découpage pour les données, puis utilisent une architecture distribuée pour prendre en charge l'accès multi-utilisateurs et multi-simultané. La bande passante du débit de données peut atteindre 100 G/s. La latence d'E/S peut être aussi faible que 2 millisecondes. Le soi-disant multi-utilisateur fait référence à de nombreux utilisateurs accédant à un certain fichier de données en même temps ; la multi-accès simultané fait référence à la nécessité d'accéder à un certain fichier de données dans plusieurs threads. Par exemple, lorsque les ingénieurs entraînent un modèle, ils utilisent plusieurs. -threading. Chaque thread nécessite tous l'utilisation d'un certain fichier de données.
2.2 Trouver efficacement l'architecture réseau appropriée
Avec le big data, comment s'assurer que le modèle résume mieux les informations sur les données ? Cela nécessite que le modèle ait une architecture de réseau adaptée aux tâches correspondantes, afin que l'avantage du grand nombre de paramètres du modèle puisse être pleinement utilisé, de sorte que le modèle dispose de fortes capacités d'extraction d'informations.
Lucas, responsable principal de la R&D sur les grands modèles chez SenseTime, a déclaré à l'auteur : Nous disposons d'un système de conception de très grands modèles semi-automatique standardisé et de qualité industrielle. En nous appuyant sur ce système, nous pouvons utiliser un ensemble de réseaux de neurones lorsque. concevoir l'architecture réseau de très grands modèles. Rechercher le système comme base pour trouver l'architecture réseau la plus adaptée à l'apprentissage de données à grande échelle.
Lors de la conception de petits modèles, nous nous appuyons principalement sur la conception, le réglage et l'itération manuels, et obtenons finalement un modèle avec des résultats satisfaisants. Bien que ce modèle ne soit pas nécessairement optimal, après itération, il peut fondamentalement répondre aux exigences requises.
Face à de grands modèles, étant donné que la structure du réseau des grands modèles est très complexe, si la conception, le réglage et l'itération manuels sont utilisés, cela consommera beaucoup de puissance de calcul et le coût sera donc élevé. Ainsi, comment concevoir rapidement et efficacement une architecture réseau suffisamment performante pour une formation avec des ressources limitées est un problème qui doit être résolu.
Lucas a expliqué que nous disposons d'un ensemble de bibliothèques d'opérateurs et que la structure du réseau du modèle peut être considérée comme l'agencement et la combinaison de cet ensemble d'opérateurs. Ce système de recherche de qualité industrielle peut calculer comment organiser et combiner les opérateurs en définissant des paramètres de base, notamment le nombre de couches de réseaux et la taille des paramètres, pour obtenir de meilleurs effets de modèle.
L'effet du modèle peut être évalué en fonction de certains critères, notamment la précision de la prédiction pour certains ensembles de données, la mémoire utilisée par le modèle lors de son exécution et le temps requis pour l'exécution du modèle. En attribuant à ces mesures des pondérations appropriées, nous pouvons continuer à itérer jusqu'à ce que nous trouvions un modèle satisfaisant. Bien entendu, lors de la phase de recherche, nous essaierons d’abord d’utiliser quelques petites scènes pour évaluer dans un premier temps l’effet du modèle.
Lors de l'évaluation de l'effet du modèle, comment choisir des scènes plus représentatives ?
De manière générale, vous pouvez choisir quelques scénarios courants. L'architecture du réseau est conçue principalement pour garantir que le modèle a la capacité d'extraire des informations clés d'une grande quantité de données, plutôt que d'espérer que le modèle puisse apprendre les caractéristiques de certains scénarios spécifiques. Par conséquent, bien que l'architecture du modèle soit déterminée, le modèle sera utilisé pour accomplir certaines tâches de scénarios d'exploitation minière à longue traîne, mais lors de la sélection d'une architecture de modèle, des scénarios généraux seront utilisés pour évaluer les capacités du modèle.
Avec un système de recherche de réseau neuronal à haute efficacité et haute précision, l'efficacité et la précision du calcul sont suffisamment élevées pour que l'effet du modèle puisse rapidement converger et qu'une bonne architecture de réseau puisse être rapidement trouvée dans un immense espace .
2.3 Améliorer l'efficacité de la formation du modèle
Une fois le travail de base précédent effectué, nous arrivons au lien de formation. Il existe de nombreux domaines qui méritent d'être optimisés dans le lien de formation.
2.3.1 Opérateur d'optimisation
Le réseau de neurones peut être compris comme une combinaison de nombreux opérateurs de base Le calcul des opérateurs consomme des ressources informatiques d'une part, et d'autre part de la mémoire. Si l'opérateur peut être optimisé pour améliorer l'efficacité de calcul de l'opérateur, alors l'efficacité de la formation peut être améliorée.
Il existe déjà des frameworks de formation en IA sur le marché, tels que PyTorch, TensorFlow, etc. Ces frameworks de formation peuvent fournir des opérateurs de base que les ingénieurs en apprentissage automatique peuvent appeler pour créer leurs propres modèles. Certaines entreprises construiront leur propre cadre de formation et optimiseront les opérateurs sous-jacents afin d'améliorer l'efficacité de la formation.
PyTorch et TensorFlow doivent assurer autant que possible la polyvalence, les opérateurs fournis sont donc généralement très basiques. Les entreprises peuvent intégrer des opérateurs de base en fonction de leurs propres besoins, éliminant ainsi le besoin de stocker des résultats intermédiaires, économisant l'utilisation de la mémoire et évitant les pertes de performances.
De plus, afin de résoudre le problème selon lequel certains opérateurs spécifiques ne peuvent pas faire bon usage du parallélisme du GPU en raison de leur forte dépendance aux résultats intermédiaires lors du calcul, certaines entreprises du secteur ont construit leurs propres bibliothèques d'accélération pour réduire l'impact de ces opérateurs sur les résultats intermédiaires. La dépendance des résultats permet au processus de calcul de profiter pleinement des avantages du calcul parallèle du GPU et d'améliorer la vitesse d'entraînement.
Par exemple, sur quatre modèles Transformer grand public, LightSeq de ByteDance a atteint une accélération jusqu'à 8 fois basée sur PyTorch.
2.3.2 Faire bon usage des stratégies parallèles
L'informatique parallèle est une méthode "d'échange d'espace contre du temps", c'est-à-dire de paralléliser autant que possible les données sans dépendances informatiques et de diviser de gros lots en petits lots, réduisant ainsi le temps d'attente d'inactivité du GPU à chaque étape de calcul et améliorant le débit de calcul.
Actuellement, de nombreuses entreprises ont adopté le cadre de formation PyTorch. Ce cadre de formation inclut le mode DDP - en tant que mode de formation parallèle de données distribuées, le mode DDP conçoit un mécanisme de distribution de données pour prendre en charge plusieurs machines et plusieurs cartes de formation. Par exemple, si une entreprise dispose de 8 serveurs et que chaque serveur dispose de 8 cartes, alors nous pouvons utiliser 64 cartes pour la formation en même temps.
Sans ce mode, les ingénieurs ne peuvent utiliser qu'une seule machine avec plusieurs cartes pour entraîner le modèle. Supposons que nous utilisions maintenant 100 000 données d'image pour entraîner le modèle en mode multi-carte sur une seule machine, le temps d'entraînement sera supérieur à une semaine. Si nous voulons utiliser les résultats de la formation pour évaluer une certaine conjecture, ou si nous voulons sélectionner la meilleure parmi plusieurs modèles alternatifs, un tel temps de formation rendra très longue la période d'attente nécessaire pour vérifier rapidement la conjecture et tester rapidement l'effet du modèle. L’efficacité de la R&D sera alors très faible.
Avec la formation parallèle multi-machines et multi-cartes, la plupart des résultats expérimentaux peuvent être vus en 2-3 jours. De cette façon, le processus de vérification de l'effet du modèle est beaucoup plus rapide.
En termes de méthodes parallèles spécifiques, le parallélisme de modèle et le parallélisme de séquence peuvent être principalement utilisés.
Le parallélisme des modèles peut être divisé en parallélisme de pipeline et en parallélisme de tenseur, comme le montre la figure ci-dessous.
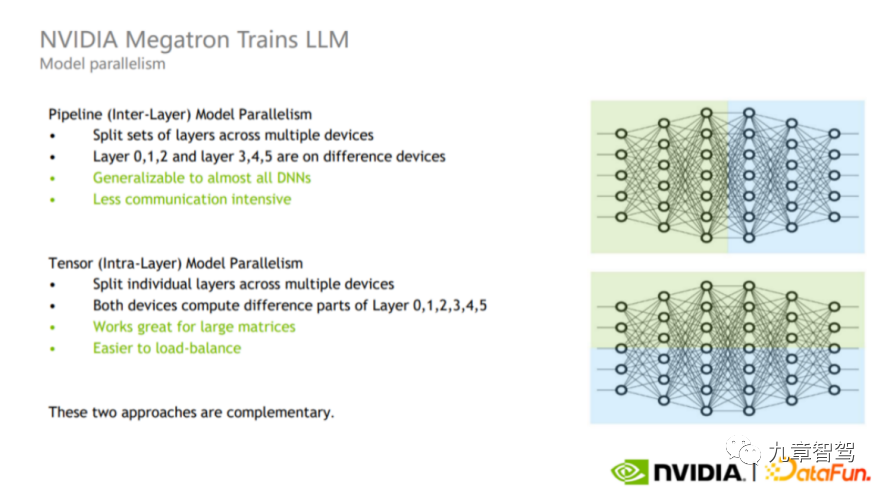
Schéma du parallélisme des pipelines et du parallélisme tenseur, image de NVIDIA
Le parallélisme des pipelines est également un parallélisme inter-couches (partie supérieure de l'image). processus de formation Différentes couches sont divisées en différents GPU pour le calcul. Par exemple, comme le montre la partie supérieure de la figure, la partie verte du calque et la partie bleue peuvent être calculées sur des GPU différents.
Le parallélisme tensoriel est un parallélisme intra-couche (partie inférieure de l'image). Les ingénieurs peuvent diviser le calcul d'une couche sur différents GPU. Ce mode est adapté au calcul de grandes matrices car il permet de réaliser un équilibrage de charge entre les GPU, mais le nombre de communications et la quantité de données sont relativement importants.
En plus du parallélisme de modèle, il existe également le parallélisme de séquence. Étant donné que le parallélisme tenseur ne divise pas la norme de couche et l'abandon, ces deux opérateurs seront calculés à plusieurs reprises entre chaque GPU, bien que la quantité de calcul ne soit pas importante, mais prend beaucoup de mémoire vidéo active.
Afin de résoudre ce problème, dans le processus réel, nous pouvons profiter du fait que Layer-norm et Dropout sont indépendants l'un de l'autre le long des dimensions de la séquence (c'est-à-dire Layer_norm et Dropout entre différentes couches ne s'affectent pas), divisez Layer-norm et Dropout, comme le montre la figure ci-dessous. L'avantage de cette répartition est qu'elle n'augmente pas le volume de communication et peut réduire considérablement l'utilisation de la mémoire.
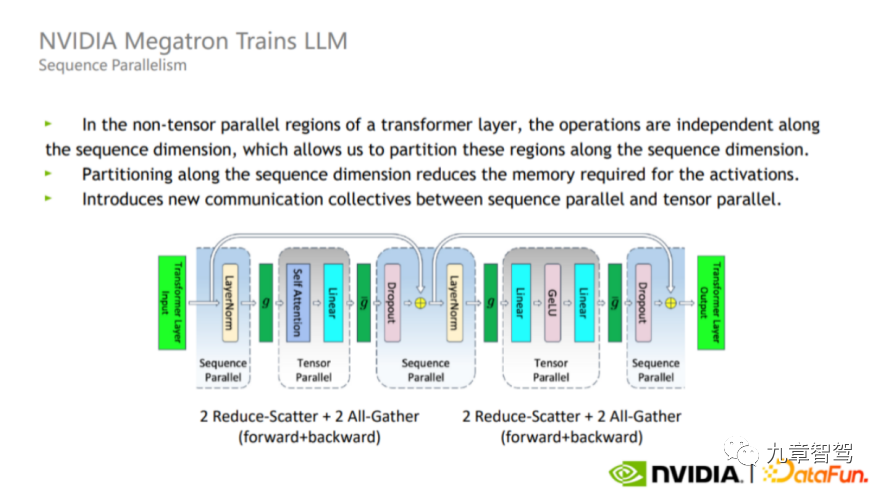
Diagramme schématique parallèle de séquence, l'image vient de NVIDIA
En pratique, les stratégies parallèles adaptées aux différents modèles sont différentes. Les ingénieurs doivent prendre en compte les caractéristiques du modèle et les caractéristiques. du matériel utilisé. En plus du processus de calcul intermédiaire, continuez le débogage avant de trouver la stratégie parallèle appropriée.
2.3.3 Faire bon usage de la propriété « clairsemée »
Lors de l'entraînement du modèle, vous devez également faire bon usage de la parcimonie, c'est-à-dire que tous les neurones ne doivent pas être "activés" - c'est-à-dire que lors de l'ajout de données d'entraînement, tous les paramètres du modèle ne doivent pas être basés sur les données nouvellement ajoutées. mise à jour, certains paramètres du modèle restent inchangés et certains paramètres du modèle sont mis à jour avec les données nouvellement ajoutées.
Un bon traitement clairsemé peut garantir la précision tout en améliorant l'efficacité de la formation des modèles.
Par exemple, dans une tâche de perception, lorsque de nouvelles images sont saisies, vous pouvez sélectionner les paramètres qui doivent être mis à jour en fonction de ces images pour effectuer une extraction de caractéristiques ciblée.
2.3.4 Traitement unifié des informations de base
De manière générale, plus d'un modèle sera utilisé au sein de l'entreprise, et ces modèles peuvent utiliser les mêmes données. Par exemple, la plupart des modèles utiliseront. données vidéo. Si chaque modèle charge et traite des données vidéo, de nombreux calculs seront répétés. Nous pouvons traiter uniformément diverses informations modales telles que des vidéos, des nuages de points, des cartes et des signaux CAN que la plupart des modèles doivent utiliser, afin que différents modèles puissent réutiliser les résultats du traitement.
2.3.5 Optimiser la configuration matérielle
Dans l'utilisation réelle de la formation distribuée, 1000 machines peuvent être utilisées Comment obtenir des résultats intermédiaires pendant le processus de formation à partir de différents serveurs qui stockent des données ——Par exemple. , gradient, puis faire une formation distribuée à très grande échelle est un grand défi.
Pour relever ce défi, vous devez d'abord réfléchir à la manière de configurer le CPU, le GPU, etc., à la manière de sélectionner la carte réseau et à la vitesse de la carte réseau afin que la transmission entre les machines puisse être rapide. .
Deuxièmement, il est nécessaire de synchroniser les paramètres et de sauvegarder les résultats intermédiaires, mais lorsque l'échelle est grande, cette question deviendra très difficile, ce qui impliquera un certain travail de communication réseau.
De plus, l'ensemble du processus de formation prend beaucoup de temps, la stabilité du cluster doit donc être très élevée.
03
Est-il significatif de continuer à augmenter les paramètres des modèles
Maintenant que les grands modèles peuvent déjà jouer un certain rôle dans le domaine de la conduite autonome, si nous continuons à augmenter les paramètres des modèles, nous pouvons nous attendre à ce que les grands modèles peut montrer des résultats étonnants. Efficace ?
Selon la communication de l’auteur avec des experts en algorithmes dans le domaine de la conduite autonome, la réponse actuelle est probablement non, car le phénomène « d’émergence » évoqué ci-dessus n’est pas encore apparu dans le domaine du CV (computer vision). Actuellement, le nombre de paramètres de modèle utilisés dans le domaine de la conduite autonome est bien inférieur à celui de ChatGPT. Car lorsqu’il n’y a pas d’effet « émergence », il existe une relation à peu près linéaire entre l’amélioration des performances du modèle et l’augmentation du nombre de paramètres. Compte tenu des contraintes de coûts, les entreprises n’ont pas encore maximisé le nombre de paramètres dans le modèle.
Pourquoi le phénomène « d’émergence » ne s’est-il pas encore produit dans le domaine de la vision par ordinateur ? L'explication d'un expert est la suivante :
Tout d'abord, bien qu'il y ait beaucoup plus de données visuelles dans le monde que de données textuelles, les données d'image sont rares, c'est-à-dire qu'il peut ne pas y avoir beaucoup d'informations efficaces dans la plupart des photos, et chaque photo La plupart les pixels de l’image ne fournissent aucune information utile. Si nous prenons un selfie, à l'exception du visage au milieu, il n'y a aucune information valable dans la zone d'arrière-plan.
Deuxièmement, les données d'image présentent des changements d'échelle importants et sont complètement non structurées. Le changement d'échelle signifie que les objets contenant la même sémantique peuvent être grands ou petits dans l'image correspondante. Par exemple, je prends d'abord un selfie, puis je demande à un ami éloigné de prendre une autre photo pour moi. Sur les deux photos, la proportion du visage sur la photo est très différente. Non structuré signifie que la relation entre chaque pixel est incertaine.
Mais dans le domaine du traitement du langage naturel, puisque le langage est un outil de communication entre les personnes, les contextes sont généralement liés, et la densité d'information de chaque phrase est généralement grande, et il n'y a pas de problème de changement d'échelle, car. Par exemple, dans n'importe quelle langue, le mot « pomme » n'est généralement pas trop long.
Par conséquent, la compréhension des données visuelles elles-mêmes sera plus difficile que le langage naturel.
Un expert du secteur a déclaré à l'auteur : Bien que nous puissions nous attendre à ce que les performances du modèle s'améliorent à mesure que le nombre de paramètres augmente, le rapport coût-efficacité actuel de la poursuite de l'augmentation du nombre de paramètres est faible.
Par exemple, si l'on multiplie par dix la capacité du modèle sur la base existante, son taux d'erreur relatif peut être réduit de 90 %. À l’heure actuelle, le modèle peut déjà effectuer certaines tâches de vision par ordinateur telles que la reconnaissance faciale. Si nous continuons à étendre la capacité du modèle dix fois à ce stade et que le taux d'erreur relatif continue de diminuer de 90 %, mais que la valeur qu'il peut atteindre n'augmente pas dix fois, alors nous n'avons pas besoin de continuer à nous développer. la capacité du modèle.
L'expansion de la capacité des modèles augmentera les coûts, car les modèles plus grands nécessitent plus de données d'entraînement et plus de puissance de calcul. Lorsque la précision du modèle atteint une plage acceptable, nous devons faire un compromis entre l'augmentation des coûts et l'amélioration de la précision, et réduire les coûts autant que possible avec une précision acceptable en fonction des besoins réels.
Bien qu'il reste encore certaines tâches à accomplir pour améliorer la précision, les grands modèles remplacent principalement certains travaux manuels dans le cloud, tels que l'annotation automatique, l'exploration de données, etc., qui peuvent être effectués par des humains. Si le coût est trop élevé, les comptes économiques ne seront pas calculés.
Mais certains experts de l'industrie ont déclaré à l'auteur : Bien qu'il n'ait pas encore atteint un point de changement qualitatif, à mesure que les paramètres du modèle augmentent et que la quantité de données augmente, nous pouvons en effet observer que la précision du modèle s'est améliorée. . Si la précision du modèle utilisé pour la tâche d'étiquetage est suffisamment élevée, le niveau d'étiquetage automatisé sera amélioré, réduisant ainsi considérablement les coûts de main-d'œuvre. À l’heure actuelle, même si le coût de la formation augmente à mesure que la taille du modèle augmente, il est à peu près linéairement lié au nombre de paramètres du modèle. Même si le coût de la formation augmentera, la réduction des effectifs peut compenser cette augmentation, donc l'augmentation du nombre de paramètres apportera toujours des avantages.
De plus, nous utiliserons également certaines techniques pour augmenter le nombre de paramètres du modèle tout en améliorant l'efficacité de la formation afin de minimiser les coûts de formation. Nous pouvons augmenter le nombre de paramètres du modèle et améliorer la précision du modèle tout en maintenant le coût constant dans le cadre de l'échelle du modèle existant. Cela équivaut à empêcher le coût du modèle d’augmenter de manière linéaire avec l’augmentation du nombre de paramètres du modèle. Nous pouvons obtenir une augmentation du coût quasiment nulle ou seulement une légère augmentation.
04
Autres applications possibles des grands modèles
En plus des applications évoquées ci-dessus, comment explorer la valeur des grands modèles ?
4.1 Dans le domaine de la perception
Le chercheur scientifique de la CMU, Max, a déclaré à l'auteur : L'essentiel de l'utilisation de grands modèles pour réaliser des tâches de perception n'est pas d'empiler des paramètres, mais de créer un cadre qui peut être une « boucle interne » . Si l'ensemble du modèle ne peut pas réaliser de boucle interne ou ne peut pas assurer une formation continue en ligne, il sera difficile d'obtenir de bons résultats.
Alors, comment implémenter la « boucle interne » du modèle ? On peut se référer au cadre de formation de ChatGPT, comme le montre la figure ci-dessous.
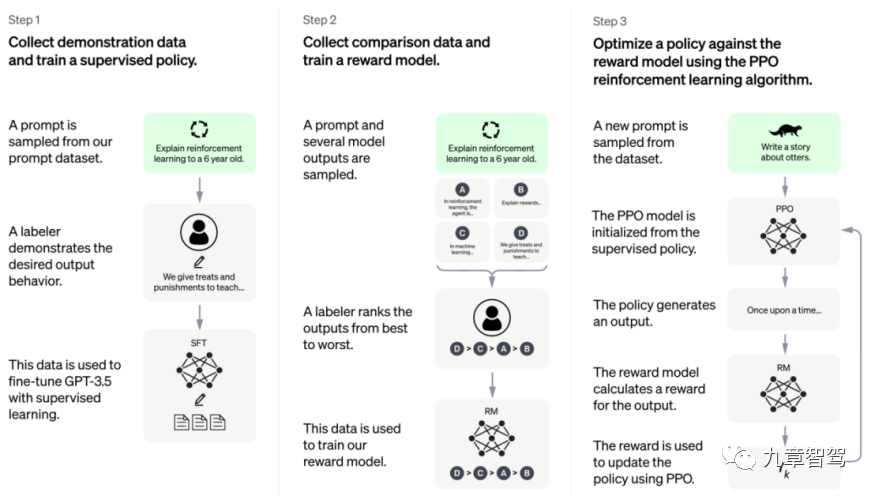
Cadre de formation ChatGPT, la photo est prise sur le site officiel d'Open AI
Le cadre modèle de ChatGPT peut être divisé en trois étapes : la première étape est l'apprentissage supervisé, l'ingénieur d'abord collecte et étiquete une partie des données, puis utilise cette partie des données pour entraîner le modèle ; la deuxième étape consiste à concevoir un modèle de récompense (modèle de récompense), le modèle peut produire lui-même certains résultats d'étiquetage dans la troisième étape, nous ; peut parvenir à l'auto-apprentissage grâce à un chemin similaire à l'apprentissage par renforcement. L'apprentissage supervisé, dans un langage plus populaire, est appelé « jouer avec soi-même » ou « boucle intérieure ».
Tant que la troisième étape est atteinte, le modèle n'exige plus que les ingénieurs ajoutent des données étiquetées, il peut calculer lui-même la perte après avoir obtenu les données non étiquetées, puis mettre à jour les paramètres. la formation est enfin terminée.
"Si nous pouvons concevoir une politique de récompense appropriée lors de l'exécution de tâches de perception afin que la formation du modèle ne repose plus sur des données étiquetées, nous pouvons dire que le modèle a atteint une « boucle interne » et peut être continuellement mis à jour sur la base de données non étiquetées. . Paramètres. »
4.2 Dans le domaine de la planification
Dans des domaines comme le Go, il est plus facile de juger de la qualité de chaque étape, car notre objectif n'inclut généralement que de gagner la partie au final.
Cependant, dans le domaine de la planification de la conduite autonome, le système d'évaluation du comportement affiché par le système de conduite autonome n'est pas clair. En plus d'assurer la sécurité, chacun a des sentiments différents concernant le confort, et nous pouvons également souhaiter atteindre notre destination le plus rapidement possible.
Passer à la scène de chat, que le retour du robot donne à chaque fois soit « bon » ou « mauvais » n'est pas en fait un système d'évaluation très clair comme Go. C'est similaire à cela avec la conduite autonome, chaque personne a des normes différentes sur ce qui est « bon » et « mauvais », et elle peut avoir des besoins difficiles à exprimer.
Dans la deuxième étape du cadre de formation ChatGPT, l'annotateur trie les résultats générés par le modèle, puis utilise ce résultat trié pour entraîner le modèle de récompense. Au début, ce modèle de récompense n’est pas parfait, mais grâce à une formation continue, nous pouvons faire en sorte que ce modèle de récompense continue à se rapprocher de l’effet souhaité.
Un expert d'une société d'intelligence artificielle a déclaré à l'auteur : Dans le domaine de la planification de la conduite autonome, nous pouvons collecter en continu des données sur la conduite automobile, puis indiquer au modèle dans quelles circonstances les gens prendront le relais (c'est-à-dire que les gens prendront le relais) sentir qu'il y a un danger) ), dans quelles circonstances il peut conduire normalement, puis à mesure que la quantité de données augmente, le modèle de récompense se rapprochera de plus en plus de la perfection.
En d'autres termes, nous pouvons envisager de renoncer à écrire explicitement un modèle de récompense parfait, et d'obtenir à la place une solution qui se rapproche constamment de la perfection en donnant continuellement des commentaires au modèle.
Par rapport à la pratique courante actuelle dans le domaine de la planification, qui consiste à essayer de trouver explicitement la solution optimale en s'appuyant sur des règles d'écriture manuelles, la méthode consistant à utiliser d'abord un modèle de récompense initial puis à optimiser continuellement en fonction des données est un changement de paradigme.
Après avoir adopté cette méthode, le module de planification d'optimisation peut adopter un processus relativement standard. Tout ce que nous avons à faire est de collecter en continu des données puis de former le modèle de récompense. Il ne repose plus sur un certain ingénieur pour analyser l'ensemble du processus. comme la méthode traditionnelle. Profondeur de compréhension du module de planification.
De plus, toutes les données historiques peuvent être utilisées pour la formation. Nous n'avons pas à nous en soucier après un certain changement de règle, même si certains problèmes actuels sont résolus, certains problèmes qui ont été résolus auparavant réapparaîtront. méthodes, nous pouvons être troublés par ce problème.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
