
 Périphériques technologiques
IA
L'IA réécrit l'algorithme de tri et est 70 % plus rapide : DeepMind AlphaDev innove en matière de base informatique et appelle des milliards de mises à jour de bibliothèques chaque jour
Périphériques technologiques
IA
L'IA réécrit l'algorithme de tri et est 70 % plus rapide : DeepMind AlphaDev innove en matière de base informatique et appelle des milliards de mises à jour de bibliothèques chaque jour
L'IA réécrit l'algorithme de tri et est 70 % plus rapide : DeepMind AlphaDev innove en matière de base informatique et appelle des milliards de mises à jour de bibliothèques chaque jour

"En échangeant et en copiant, AlphaDev saute une étape, connectant les projets d'une manière qui semble erronée mais qui est en fait un raccourci. " C'est sans précédent et contre-intuitif. printemps 2016.
Il y a sept ans, AlphaGo battait le champion du monde humain au Go, et maintenant l'IA nous a appris une autre leçon de programmation.
Tôt ce matin, deux phrases du PDG de Google DeepMind, Hassabis, ont fait exploser le domaine informatique : « AlphaDev a découvert un nouvel algorithme de tri plus rapide. principale bibliothèque C++ que les développeurs peuvent utiliser. Ce n'est que le début des progrès de l'IA dans l'amélioration de l'efficacité du code 🎜🎜#
Cette fois, le nouveau système d'apprentissage par renforcement de Google DeepMind, AlphaDev, a découvert un algorithme de hachage plus rapide que celui-ci. jamais auparavant. Il s'agit d'un algorithme de base dans le domaine de l'informatique, résultat de l'IA. Il a été inclus dans la bibliothèque C++ standard LLVM Abseil et est open source.
Ces algorithmes améliorent la bibliothèque de tri LLVM libc++, rendant la bibliothèque de tri 70 % plus rapide pour les séquences plus courtes et pour les séquences de plus de 250 000 éléments, la vitesse peut également être augmenté d'environ 1,7%. Google DeepMind affirme qu'il s'agit du premier changement apporté à cette partie de la bibliothèque de séquençage depuis plus d'une décennie. Il semble que désormais l’IA puisse non seulement aider les gens à écrire du code, mais aussi nous aider à écrire un meilleur code.
Dans le dernier blog, les auteurs du nouveau système ont présenté AlphaDev en détail.
De nouveaux algorithmes vont changer les fondements de l'informatique
Cette recherche de Google DeepMind est née de cela. L'article correspondant a été publié dans "Nature". AlphaDev est un système d'IA qui utilise l'apprentissage par renforcement pour découvrir des algorithmes. . , dépassant même les réalisations des scientifiques et des ingénieurs depuis des décennies. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # :https://www.nature.com/articles/s41586-023-06004-9
Dans l'ensemble, AlphaDev a découvert un algorithme de tri plus rapide. Bien que des milliards de personnes utilisent ces algorithmes chaque jour, personne ne réalise qu’il existe une marge d’optimisation. Les algorithmes de tri sont utilisés dans un large éventail d'applications, depuis les résultats de recherche en ligne, le tri des publications sociales jusqu'à divers traitements de données sur ordinateurs et téléphones mobiles, qui sont tous indissociables des algorithmes de tri. L’utilisation de l’IA pour générer de meilleurs algorithmes changera la façon dont les humains programment les ordinateurs et aura un impact significatif sur une société de plus en plus numérique.
En open source le nouvel algorithme de tri dans une bibliothèque C++ majeure, des millions de développeurs et d'entreprises à travers le monde peuvent désormais l'utiliser dans des secteurs allant du cloud computing à l'Internet. des achats à la gestion de la chaîne d’approvisionnement. Il est utilisé dans les applications d’intelligence artificielle dans tous les secteurs. Il s’agit du premier changement apporté à la bibliothèque de classement depuis plus d’une décennie, et c’est la première fois que des algorithmes conçus avec l’apprentissage par renforcement sont ajoutés à la bibliothèque. Considérez cela comme une étape importante dans l’utilisation de l’intelligence artificielle pour optimiser progressivement le code mondial.
À propos du tri
Un algorithme de tri est une méthode permettant d'organiser certaines tâches dans un ordre spécifique. Par exemple, triez trois lettres par ordre alphabétique, organisez cinq nombres du plus grand au plus petit ou triez une base de données contenant des millions d'enregistrements.
Cet algorithme existe depuis longtemps et a bien évolué. L’un des premiers exemples de classement remonte aux IIe et IIIe siècles après J.-C., lorsque les érudits classèrent à la main par ordre alphabétique des milliers de livres sur les étagères de la Bibliothèque d’Alexandrie. Avec l'avènement de la révolution industrielle sont apparues des machines qui pourraient aider les gens à trier, avec des machines à tabuler stockant les informations à l'aide de cartes perforées qui ont été utilisées pour collecter les résultats du recensement américain de 1890.
Avec l'essor des ordinateurs commerciaux dans les années 1950, les premiers algorithmes informatiques pour les algorithmes de tri ont commencé à se développer. Aujourd’hui, il existe de nombreuses techniques de tri et algorithmes différents utilisés dans les bases de code du monde entier pour traiter d’énormes quantités de données en ligne.
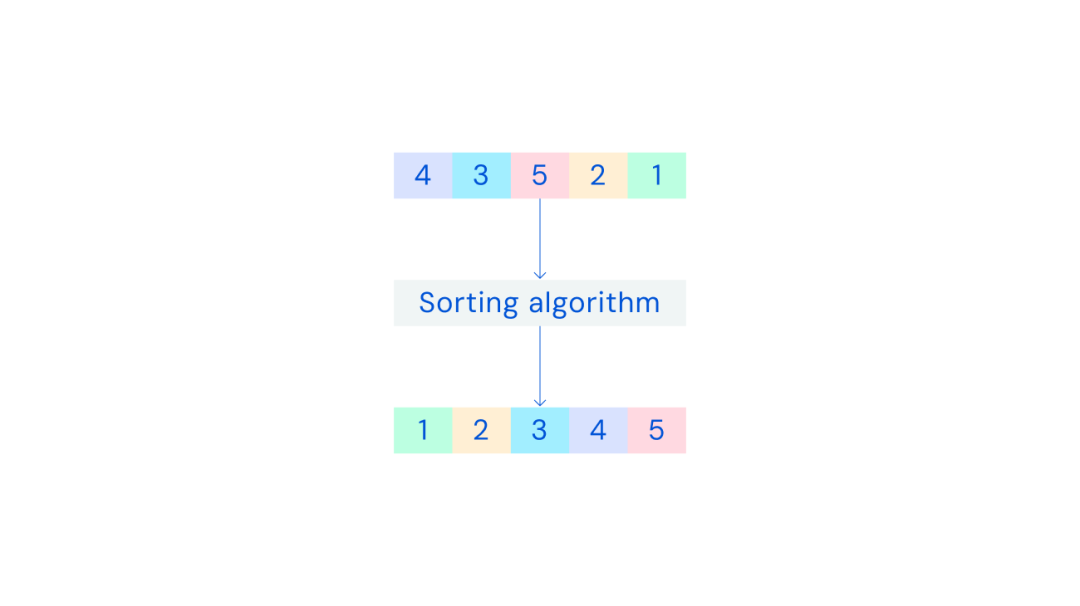
Entrez une série de nombres non triés dans l'algorithme et produisez des nombres triés.
Après des décennies de recherche menée par des informaticiens et des programmeurs, l'algorithme de tri actuel est déjà si efficace qu'il est difficile d'obtenir de nouvelles améliorations. C'est un peu comme essayer de trouver une nouvelle façon d'économiser de l'énergie ou une mathématique plus efficace. méthodes, et ces algorithmes sont également la pierre angulaire de l’informatique.
Explorez de nouveaux algorithmes : instructions d'assemblage
AlphaDev explore des algorithmes plus rapides à partir de zéro plutôt que de se baser sur des algorithmes existants. De plus, AlphaDev peut également être utilisé pour trouver des domaines dans lesquels la plupart des gens ne sont pas impliqués : les instructions d'assemblage des ordinateurs.
Les instructions d'assemblage peuvent être utilisées pour créer du code binaire qu'un ordinateur exécute. Les développeurs écrivent du code dans un langage de haut niveau tel que C++, mais doivent le convertir en instructions d'assemblage de « bas niveau » compréhensibles par l'ordinateur.
Google DeepMind estime qu'il existe de nombreuses possibilités d'amélioration à ce niveau, ce qui pourrait être difficile à repérer dans les langages de programmation de niveau supérieur. À ce niveau, les ordinateurs sont plus flexibles dans leur stockage et leurs opérations, ce qui signifie qu'il existe davantage de possibilités d'améliorations susceptibles d'avoir un impact plus important sur la vitesse et la consommation d'énergie.
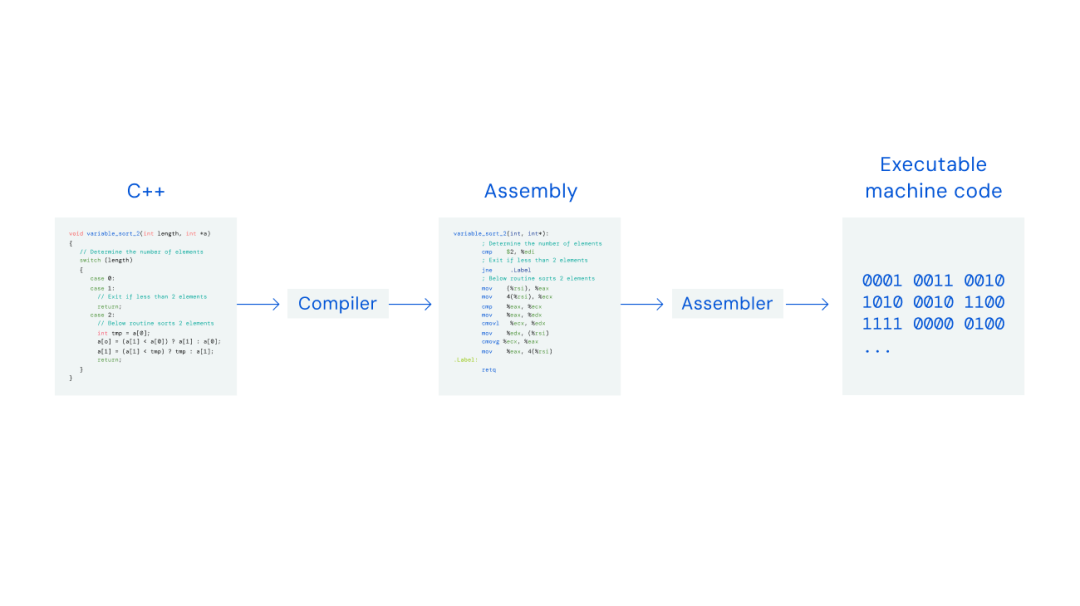
Le code est généralement écrit dans un langage de programmation de haut niveau tel que C++. Le compilateur convertit ensuite cela en instructions CPU de bas niveau, appelées instructions d'assemblage. Un assembleur convertit les instructions d'assemblage en code machine exécutable afin que l'ordinateur puisse l'exécuter.

Figure A : Exemple d'un algorithme C++ qui trie jusqu'à deux éléments Figure B : Représentation de l'assembly correspondant ;
Utilisation de la méthode AlphaGo pour trouver le meilleur algorithme
AlphaDev est basé sur un résultat précédent de Google DeepMind : AlphaZero, un modèle d'apprentissage par renforcement qui a vaincu le champion du monde dans des jeux tels que le Go, les échecs et les échecs. Et AlphaDev montre comment ce modèle passe des jeux aux défis scientifiques, et des simulations aux applications du monde réel.
Pour entraîner AlphaDev à découvrir de nouveaux algorithmes, l'équipe a transformé le tri en un "jeu d'assemblage" solo. À chaque tour, AlphaDev observe l'algorithme qu'il a produit et les informations contenues dans le CPU, puis effectue son prochain mouvement en sélectionnant une instruction à ajouter à l'algorithme.
Les jeux d'assemblage sont très difficiles car AlphaDev doit rechercher efficacement parmi un grand nombre de combinaisons possibles d'instructions pour trouver un algorithme capable de trier et d'être plus rapide que le meilleur algorithme actuel. Le nombre de combinaisons possibles d'instructions est similaire au nombre de particules dans l'univers, ou au nombre de combinaisons possibles de coups aux échecs (10 ^ 120 parties) et au Go (10 ^ 700 parties), et un mauvais coup peut faire tomber l'ensemble de l'algorithme.
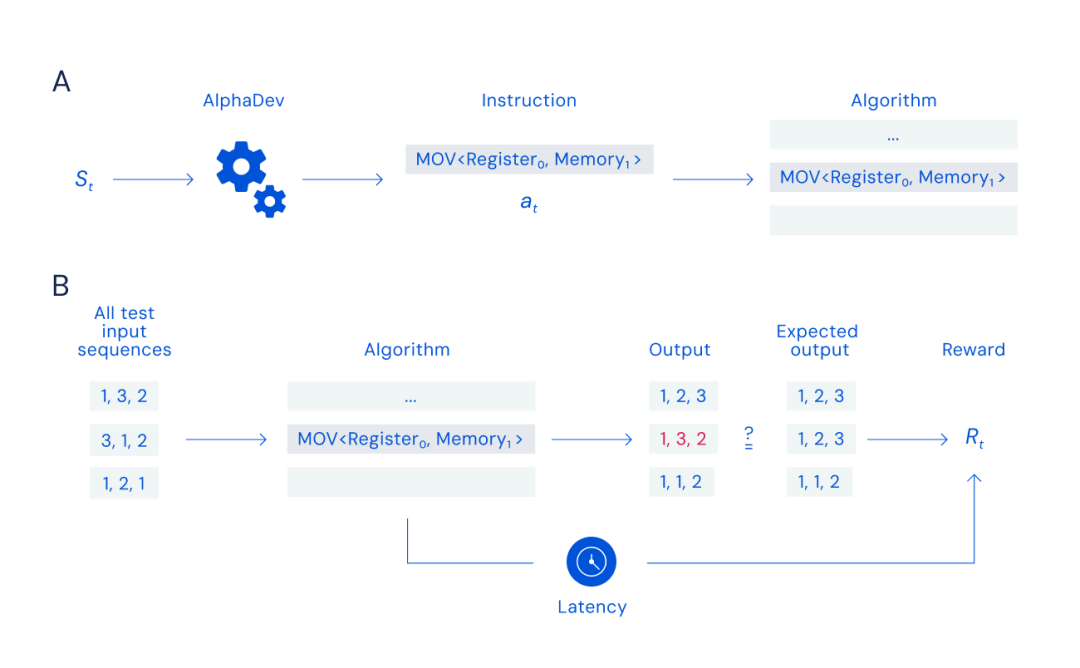
Image A : Jeu d'assemblage. Le joueur AlphaDev reçoit en entrée l'état du système st et joue aux échecs en sélectionnant une instruction d'assemblage à ajouter à l'algorithme actuellement généré. Figure B : Calcul de la récompense. Après chaque mouvement, l'algorithme résultant reçoit une séquence d'entrée de test ; pour sort3, cela correspond à toutes les combinaisons de trois séquences d'éléments. L'algorithme produit ensuite une sortie qui est comparée à la sortie attendue de la séquence triée compte tenu de la situation de tri. Les agents sont récompensés en fonction de l'exactitude et de la latence de l'algorithme.
Lors de la construction d'un algorithme, une instruction à la fois, AlphaDev vérifie que la sortie de l'algorithme est correcte en la comparant au résultat attendu. Pour un algorithme de tri, cela signifie que les nombres non ordonnés entrent et que les nombres correctement triés en ressortent. L'équipe récompense AlphaDev pour le tri correct des nombres et pour la rapidité et l'efficacité du tri, et AlphaDev remporte ensuite la partie en découvrant le programme correct et plus rapide.
Il a découvert des algorithmes de tri plus rapides
AlphaDev a découvert de nouveaux algorithmes de tri qui ont abouti à des améliorations de la bibliothèque de tri LLVM libc++ : Pour les séquences plus courtes, la bibliothèque de tri est 70 % plus rapide, pour les séquences de plus de 250 000 éléments, la vitesse est augmentée d'environ 1,7 %.
Parmi eux, l'équipe de Google DeepMind se concentre davantage sur l'amélioration de l'algorithme de tri de séquences courtes de trois à cinq éléments. Ces algorithmes sont parmi les plus largement utilisés car ils sont souvent appelés plusieurs fois dans le cadre d'une fonction de tri plus large, et l'amélioration de ces algorithmes peut augmenter la vitesse globale de tri d'un nombre quelconque d'éléments.
Pour rendre les nouveaux algorithmes de tri plus utiles aux utilisateurs, l'équipe a procédé à une ingénierie inverse des algorithmes et les a traduits en C++, l'un des langages de programmation les plus populaires utilisés par les développeurs.
Actuellement, ces algorithmes sont fournis dans la bibliothèque de tri standard LLVM libc++ (https://reviews.llvm.org/D118029) et sont utilisés par des millions de développeurs et d'entreprises à travers le monde.
"Actions d'échange et de copie", la main de Dieu réapparaît ?
En fait, AlphaDev a non seulement découvert des algorithmes plus rapides, mais aussi de nouvelles méthodes. Son algorithme de tri consiste en une nouvelle séquence d'instructions qui enregistre une instruction à chaque fois qu'elle est appliquée - ce qui a évidemment un impact énorme, puisque ces algorithmes sont utilisés des milliards de fois chaque jour. Ils appellent cela « actions d'échange et de copie AlphaDev ».
Cette nouvelle approche n'est pas sans rappeler l'"étape 37" d'AlphaGo - un mouvement contre-intuitif qui a stupéfié les spectateurs et a conduit à la défaite du légendaire joueur de Go Lee Sedol. En échangeant et en copiant des actions, AlphaDev saute une étape, connectant les éléments d'une manière qui ressemble à une erreur mais qui est en réalité un raccourci. Cela démontre la capacité d’AlphaDev à découvrir des solutions originales et à remettre en question la façon dont les humains réfléchissent à la manière d’améliorer les algorithmes informatiques.
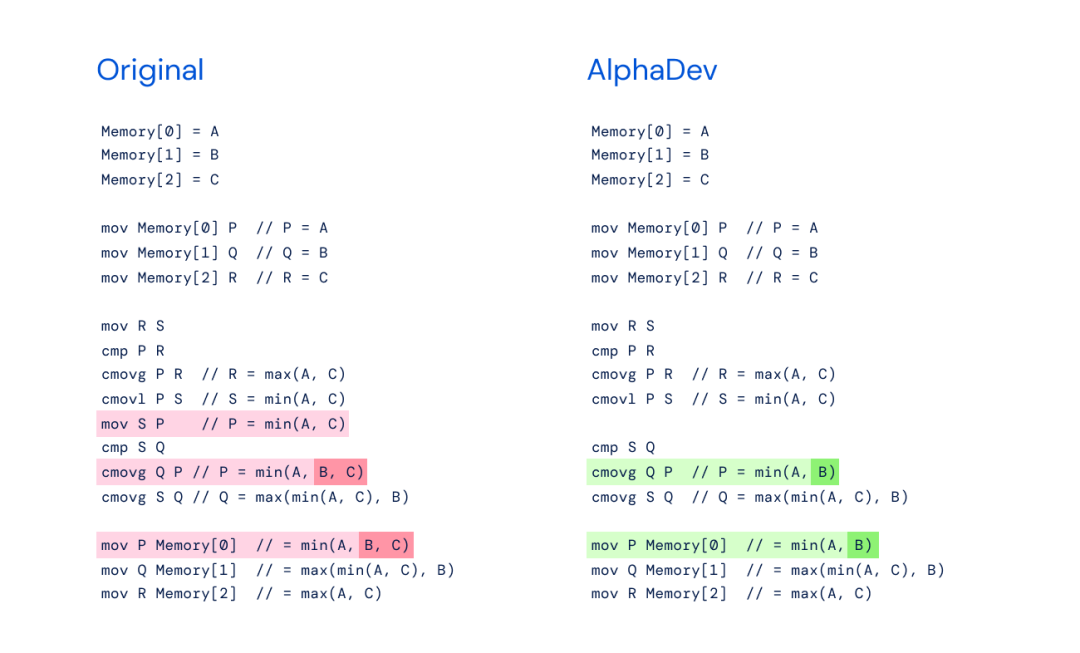
Gauche : implémentation originale du sort3 min (A,B,C) ; droite : mouvement d'échange AlphaDev - AlphaDev a découvert que vous n'aviez besoin que de min (A,B).

Gauche : implémentation originale utilisant max(B,min(A,C,D)) dans un algorithme de tri plus grand pour trier huit éléments ; Droite : AlphaDev a constaté que lors de l'utilisation de son action de copie, seul max(B,min(A ,C)) est requis.
Test de capacité de mise à l'échelle : du « tri » au « hachage »
Après avoir découvert un algorithme de tri plus rapide, l'équipe a testé si AlphaDev pouvait généraliser et améliorer un algorithme informatique différent : le hachage.
Le hachage est un algorithme de base utilisé en informatique pour récupérer, stocker et compresser des données. Tout comme un bibliothécaire qui utilise un système de classification pour localiser un livre particulier, les algorithmes de hachage aident les utilisateurs à savoir ce qu'ils recherchent et où le trouver. Ces algorithmes prennent les données pour une clé spécifique (par exemple, le nom d'utilisateur « Jane Doe ») et les hachent – un processus qui convertit les données brutes en une chaîne unique (par exemple 1234ghfty). L'ordinateur utilise ce hachage pour récupérer rapidement les données liées à la clé au lieu de rechercher dans toutes les données.
L'équipe a appliqué AlphaDev à l'un des algorithmes de hachage les plus couramment utilisés dans les structures de données dans le but de découvrir un algorithme plus rapide. Lorsqu'il est appliqué à des fonctions de hachage dans la plage de 9 à 16 octets, AlphaDev a constaté une amélioration de 30 % de la vitesse de l'algorithme.
Cette année, le nouvel algorithme de hachage d'AlphaDev a été publié dans la bibliothèque open source Abseil, le rendant disponible à des millions de développeurs à travers le monde, où il est désormais utilisé probablement des milliards de fois par jour.
Adresse Open source : https://github.com/abseil/abseil-cpp/commit/74eee2aff683cc7dcd2dbaa69b2c654596d8024e
Conclusion
Google DeepMind améliore le tri et haha en optimisant et en lançant l'algorithme de Hash, disponible à travers le monde Utilisé par les développeurs, AlphaDev démontre sa capacité à généraliser et à découvrir de nouveaux algorithmes ayant un impact réel. AlphaDev peut être considéré comme une étape vers le développement d’outils d’IA à usage général qui peuvent aider à optimiser l’ensemble de l’écosystème informatique et à résoudre d’autres problèmes au profit de la société.
Bien que l'optimisation dans l'espace d'instructions d'assemblage de bas niveau soit très puissante, AlphaDev a encore des limites à mesure que les algorithmes se développent, et l'équipe explore actuellement sa capacité à optimiser les algorithmes directement dans des langages de haut niveau tels que C++, qui est utile pour Plus utile pour les développeurs.
Les découvertes d’AlphaDev, telles que les actions d’échange et de copie, montrent non seulement qu’il peut améliorer les algorithmes mais aussi trouver de nouvelles solutions. Ces résultats pourraient inciter les chercheurs et les développeurs à créer des technologies et des méthodes capables d’optimiser davantage les algorithmes sous-jacents afin de créer un écosystème informatique plus robuste et plus durable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Un guide complet pour consulter les journaux GitLab sous Centos System Cet article vous guidera comment afficher divers journaux GitLab dans le système CentOS, y compris les journaux principaux, les journaux d'exception et d'autres journaux connexes. Veuillez noter que le chemin du fichier journal peut varier en fonction de la version Gitlab et de la méthode d'installation. Si le chemin suivant n'existe pas, veuillez vérifier le répertoire d'installation et les fichiers de configuration de GitLab. 1. Afficher le journal GitLab principal Utilisez la commande suivante pour afficher le fichier journal principal de l'application GitLabRails: Commande: sudocat / var / log / gitlab / gitlab-rails / production.log Cette commande affichera le produit
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
