
 Opération et maintenance
Sécurité
Les affaires connaissent une croissance exponentielle, la construction de convivialité peut-elle être aussi stable ?
Opération et maintenance
Sécurité
Les affaires connaissent une croissance exponentielle, la construction de convivialité peut-elle être aussi stable ?
Les affaires connaissent une croissance exponentielle, la construction de convivialité peut-elle être aussi stable ?

1. Problèmes et défis
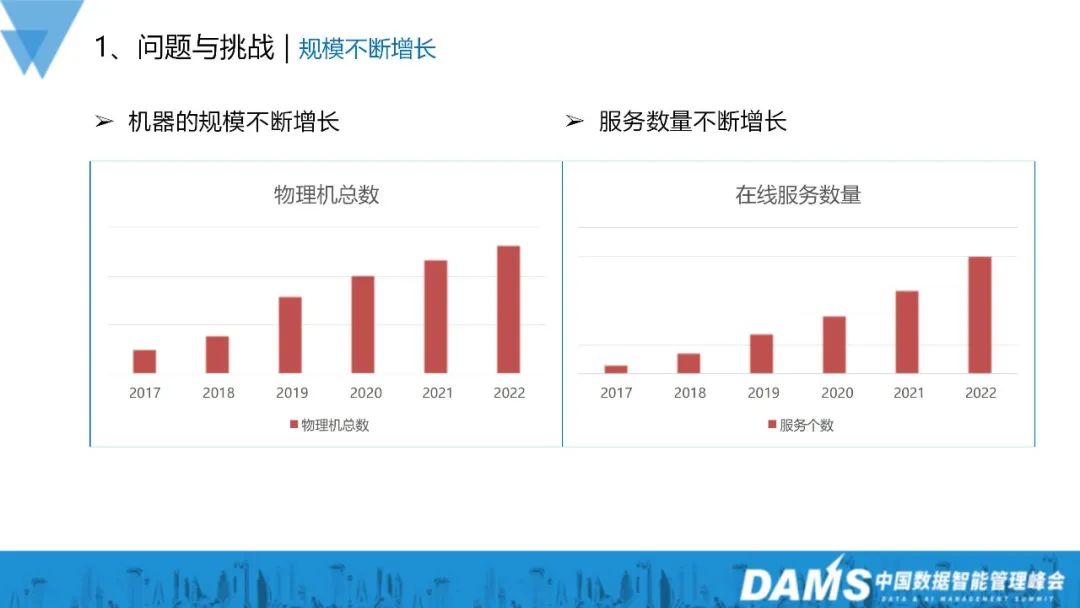
Depuis 2017, la taille des machines et le nombre de services de Vivo ont considérablement augmenté, comme le montre le graphique. La taille de la machine a été multipliée par cinq environ et le nombre de services a été multiplié par plus de dix. La période s'étend de 2017 à 2022.

À mesure que l'échelle grandit, les défis et la complexité vont certainement augmenter. Les défis typiques in vivo sont principalement divisés en défis de changement et en défis d'échec.
1. Défis liés au changement
Il existe encore des scénarios de changement plus ou moins manuels
Notre délai de publication unique est relativement long
Il existe de nombreux scénarios de migration d'entreprise à grande échelle ; Google SRE a un tel concept : 70 % des échecs sont causés par des changements. Cette situation existe également in vivo, et les changements auront un grand impact sur la stabilité en ligne.
2. Défis de panne
Risque de panne au niveau de la salle d'équipement (les grandes et petites entreprises seront confrontées à des fouilles de fibre ou à des pannes de salle d'équipement interne, etc.) ; exigences.- Dans le cadre de ce défi, nous avons divisé la construction en deux dimensions : la capacité de disponibilité et l'étape de disponibilité pour assurer la stabilité de l'entreprise.
2. Renforcement des capacités de disponibilité
1. Développement du cycle de vie complet basé sur les pannes
Notre renforcement des capacités de disponibilité est basé sur la gestion des pannes du cycle de vie complet, couvrant les pannes occurrence, détection, réponse, récupération, examen et mesures préventives. Le temps entre l'apparition d'un défaut et la récupération est appelé MTTR ; le temps entre la récupération et l'apparition d'un défaut, de stable à instable, est appelé MTTF ; le temps entre les occurrences de défaut est appelé MTBF, avec un total de 3 ; indicateurs. 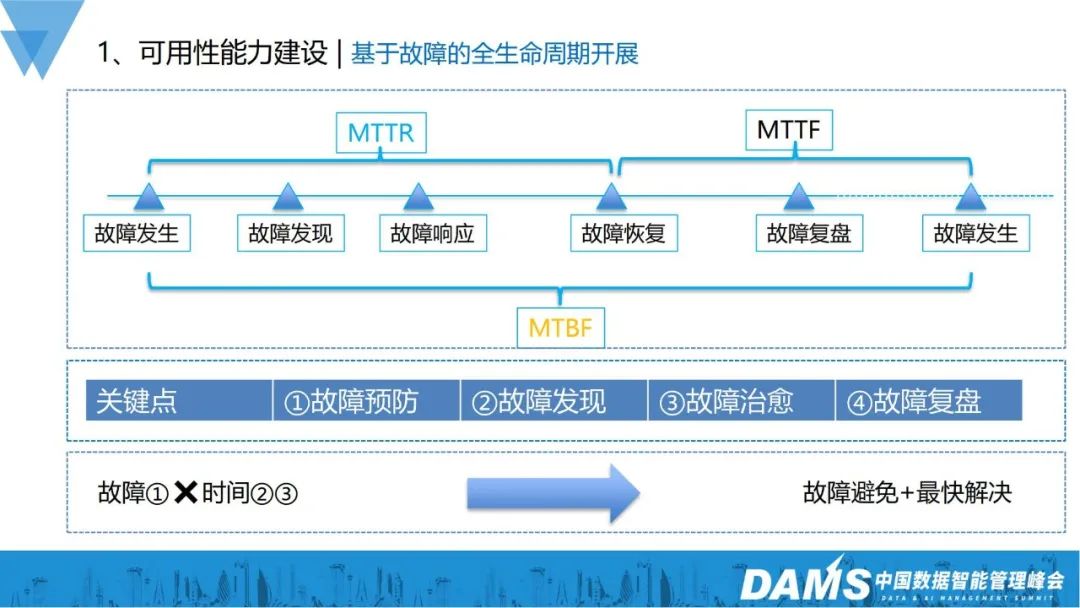
La gestion des pannes n'est rien de plus que ces 4 points :
Comment prévenir l'apparition des pannes ? Comment détecter la panne au plus vite ? Comment remédier rapidement à la panne ?- Une fois le défaut rétabli, comment faire le suivi ?
- Considérant principalement la disponibilité de l'entreprise, vous devez faire attention à la fréquence des pannes et au temps d'impact sur l'entreprise. Par conséquent, réduire la fréquence des défauts, localiser rapidement les défauts, raccourcir la durée des défauts et parvenir à une réparation rapide des défauts sont les idées générales de l'ensemble de notre construction de capacités à haute disponibilité. Nous vous présentons les mesures que nous avons mises en place :
2. Analyse d'occurrence de panne
Tout d'abord, pour parvenir à la prévention des pannes, il faut d'abord comprendre pourquoi la panne se produit, ce qui peut être fait à partir de une perspective de service et une perspective de lien complet.
1) Perspective du service
Un service n'est rien de plus qu'une entrée demandée, et normalement il n'a besoin que d'une sortie correspondante. Dans des situations réelles, de nombreux aspects affectent la réponse correcte du service. Dans certains scénarios classiques, les facteurs d'influence ont été résumés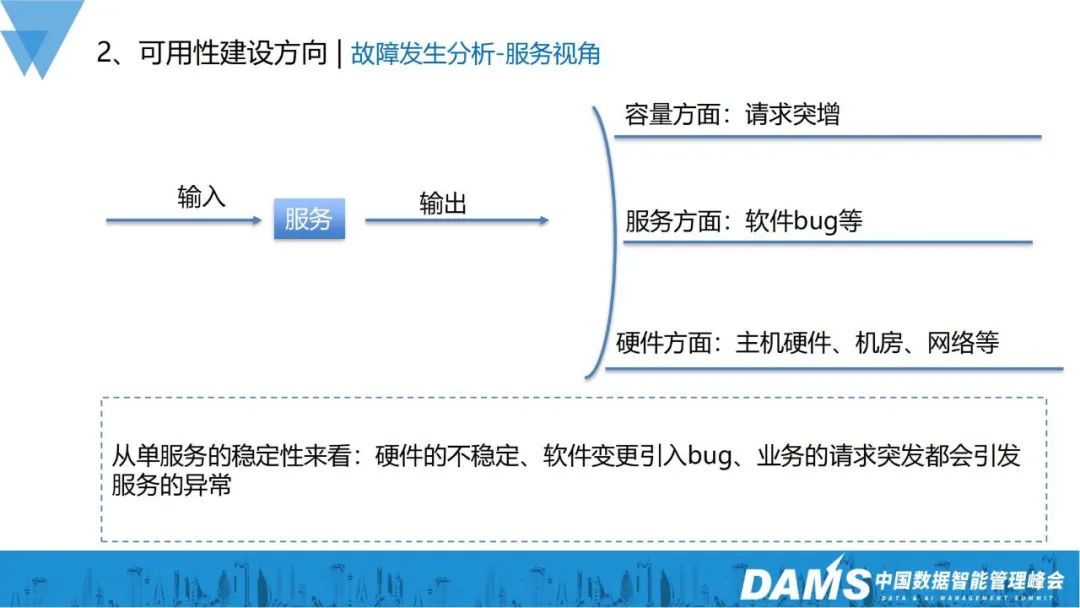
- 2) Perspective du lien complet
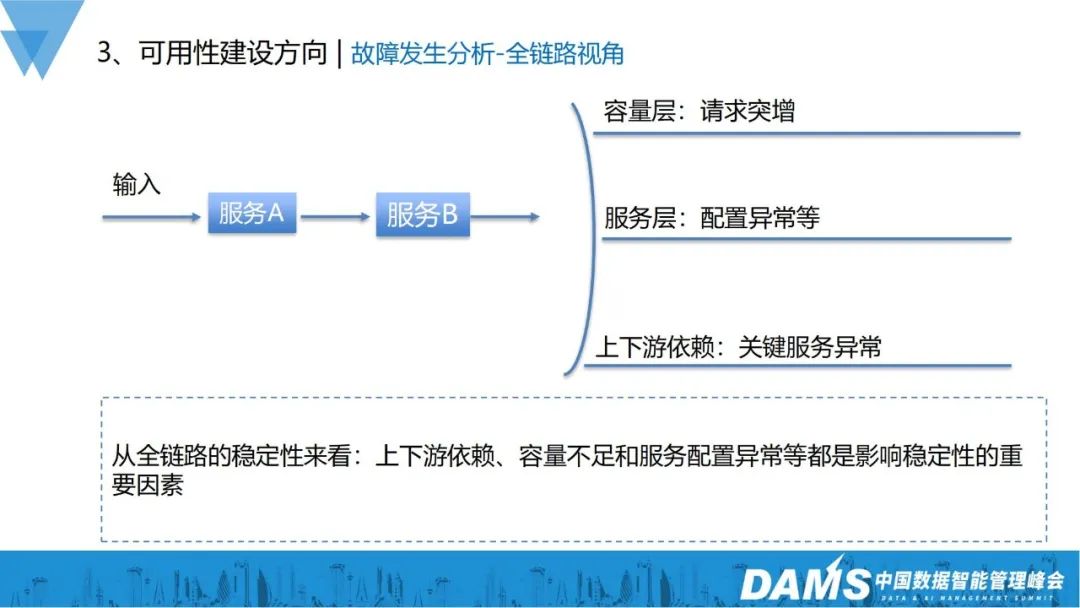 Couche de capacité : augmentation soudaine des requêtes, capacité insuffisante de l'ensemble du lien, entraînant des anomalies de service
Couche de capacité : augmentation soudaine des requêtes, capacité insuffisante de l'ensemble du lien, entraînant des anomalies de service
- Du point de vue de la stabilité de l'ensemble du lien : les dépendances en amont et en aval, la capacité insuffisante et les configurations de service anormales sont autant de facteurs importants affectant la stabilité.
3. Construction de prévention des pannes
Après avoir analysé les facteurs de panne des deux perspectives du service et du lien complet, la construction de prévention des pannes a des idées correspondantes :
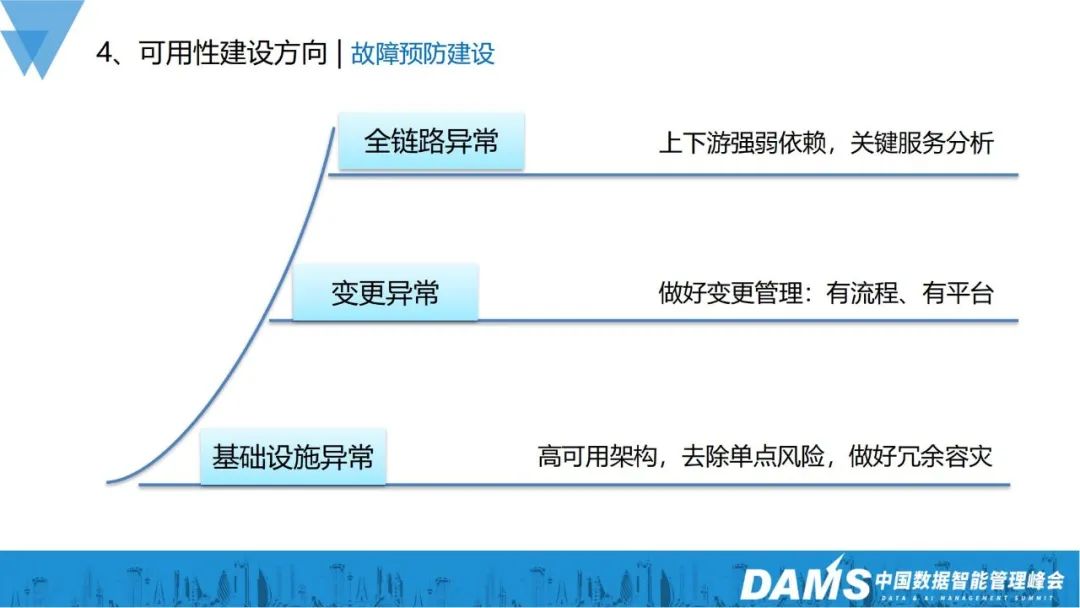
- Anomalie de lien complet : il est nécessaire d'analyser la force et la faiblesse de l'amont et de l'aval, et de fournir une protection spéciale aux serveurs clés pour assurer la stabilité de l'ensemble du lien
- Exception de modification : créer des modifications ; Plateforme de spécification des processus et de gestion des changements ;
- Exception d'infrastructure : s'appuyer sur une architecture à haute disponibilité pour supprimer les points de risque uniques et mettre en œuvre une reprise après sinistre redondante.
4. Prévention des pannes

J'ai déjà parlé de l'analyse globale et des idées de construction, mais comment vivo le fait-il réellement ?
Nous avons fourni une garantie de construction basée sur le lien complet. L'ensemble du lien est construit à partir de la couche d'accès, de la couche de logique métier, de la couche middleware, de la couche de stockage et de la couche d'infrastructure :
1) Unitisation : réduire les appels de service. dans les salles informatiques, évitez que la panne d'une seule salle informatique n'affecte tous les services de la salle informatique ;
2) Entrées multiples : dans le passé, de nombreuses entreprises n'avaient qu'une seule entrée de couche d'accès après avoir développé les capacités multi-entrées d'IDC. et le cloud public, un seul L'impact des exceptions d'entrée sur l'accès global au service sera plus faible
3) Protection contre les surcharges : lorsque la capacité de l'entreprise augmente soudainement, le service de la couche d'accès peut rejeter activement certaines demandes de rafale en fonction des paramètres ; pour éviter des demandes excessives. Le trafic met hors service les services suivants ;
4) Disjoncteur et déclassement : le déclassement monopolistique des services dépendants peut protéger l'impact des services anormaux et éviter l'effet d'avalanche.
5. Découverte des défauts
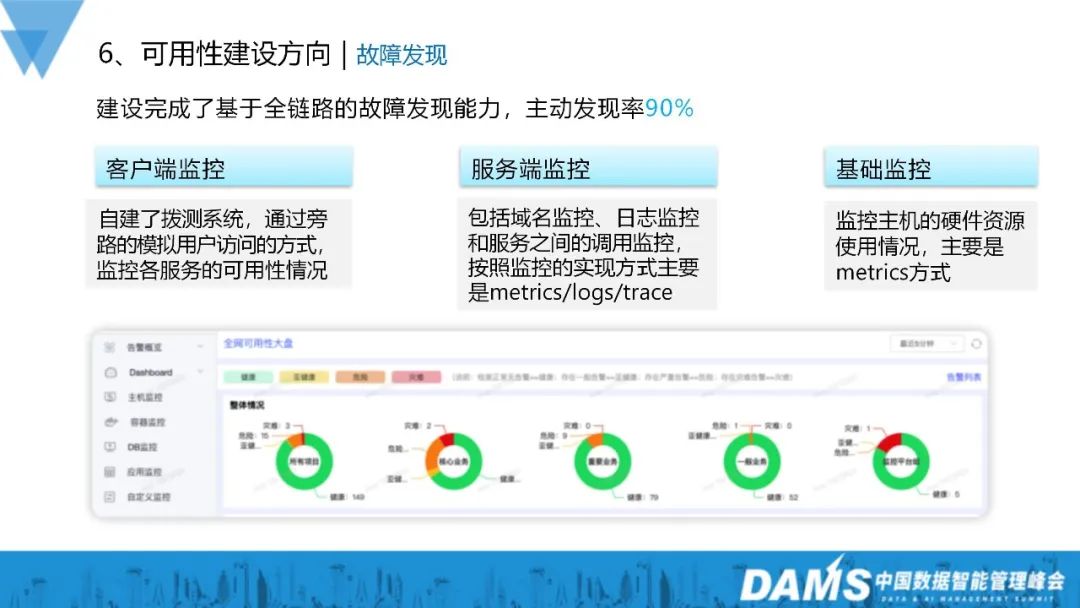
Nous avons construit une capacité de détection des défauts basée sur l'ensemble du lien. À l'heure actuelle, le taux de détection proactive des défauts peut atteindre 90 %, ce qui inclut le client. surveillance, surveillance du serveur et surveillance de base :
1) Surveillance des clients : système de test de numérotation auto-construit, surveillant la disponibilité de chaque service via un accès utilisateur simulé de contournement
2) Surveillance du serveur : y compris la surveillance des noms de domaine, surveillance des journaux et surveillance des appels entre les services. Selon la méthode de mise en œuvre de la surveillance, il s'agit principalement de métriques/journaux/traces
3) Surveillance de base : surveillez l'utilisation des ressources matérielles de l'hôte, principalement de manière métrique.
6. Le dépannage
comprend principalement l'analyse et la gestion des pannes.

- Analyse des pannes : liée au système de surveillance pour prendre en charge l'analyse des pannes de service de base, l'analyse de la disponibilité des noms de domaine, etc. ; etc.
7. Examen des défauts
L'examen des défauts est une partie très importante de l'ensemble du cycle de construction à haute disponibilité.

Nous garantissons la stabilité de l'entreprise grâce à une classification SLA basée sur l'entreprise, et enregistrons chaque échec de l'entreprise, améliorons et vérifions le renforcement des capacités :
1) Classification de l'entreprise : Exploitation et les ressources de maintenance sont très limitées. Il est nécessaire de s'assurer que toutes les entreprises ont le même SLA. Par conséquent, la garantie hiérarchique est très nécessaire en fonction de la réputation et des revenus de l'entreprise, nous la divisons en quatre niveaux d'activité : principal, important, général. , et autres. Utilisez-le pour guider l'investissement dans la main-d'œuvre et le support d'exploitation et de maintenance pour chaque entreprise
2) Enregistrements de défauts : améliorez l'efficacité des examens, tout en suivant les défauts commerciaux en ligne pour une analyse de suivi afin de guider l'optimisation de l'entreprise ;
3) Amélioration des défauts : effectuez une vérification en amont basée sur l'ingénierie du chaos pour déterminer si les mesures d'amélioration ont pris effet. C'est notre pratique en matière d'examen des pannes. Nous avons également implémenté ces capacités et pratiques dans la plateforme et géré le travail d'examen des pannes via la plateforme. 8. Gestion de la capacité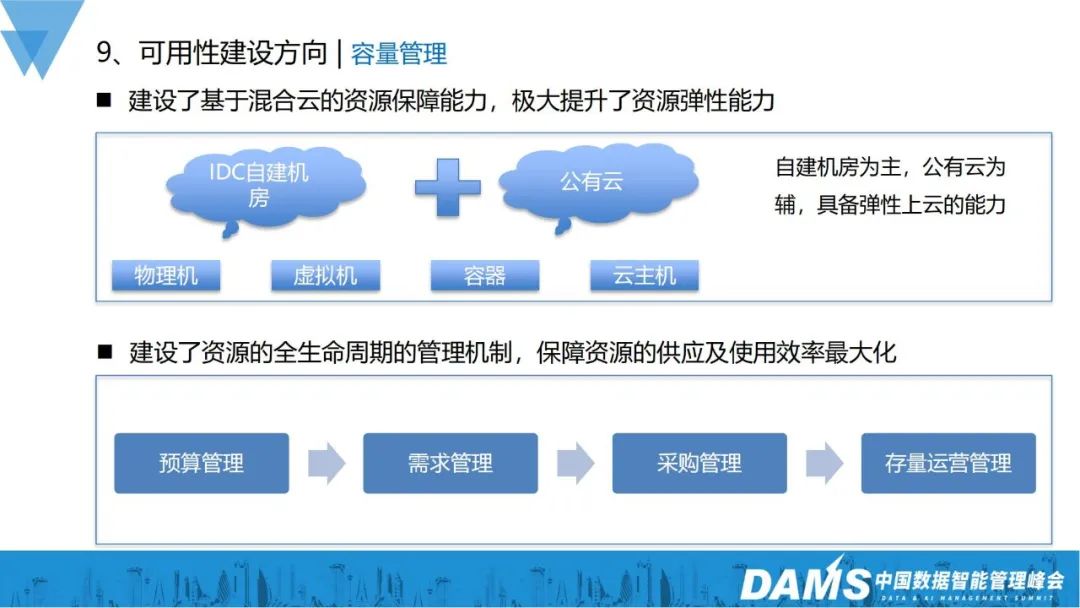
- Évolutivité élastique des ressources : créer des capacités de garantie de ressources hybrides basées sur le cloud pour améliorer considérablement l'élasticité des ressources
- Capacités de fourniture et de gestion des opérations des ressources : créer un mécanisme de gestion du cycle de vie complet des ressources afin d'assurer l'approvisionnement et le suivi des ressources ; L'efficacité de l'utilisation est maximisée, y compris la gestion du budget, la gestion de la demande, la gestion des achats et la gestion des opérations de stock.
3. Construction de la phase d'utilisabilité
Après le renforcement des capacités d'utilisabilité, nous le divisons en trois étapes pour renforcer l'utilisabilité : l'étape de standardisation, l'étape de processus et l'étape de plate-forme.
1. Étape de normalisation
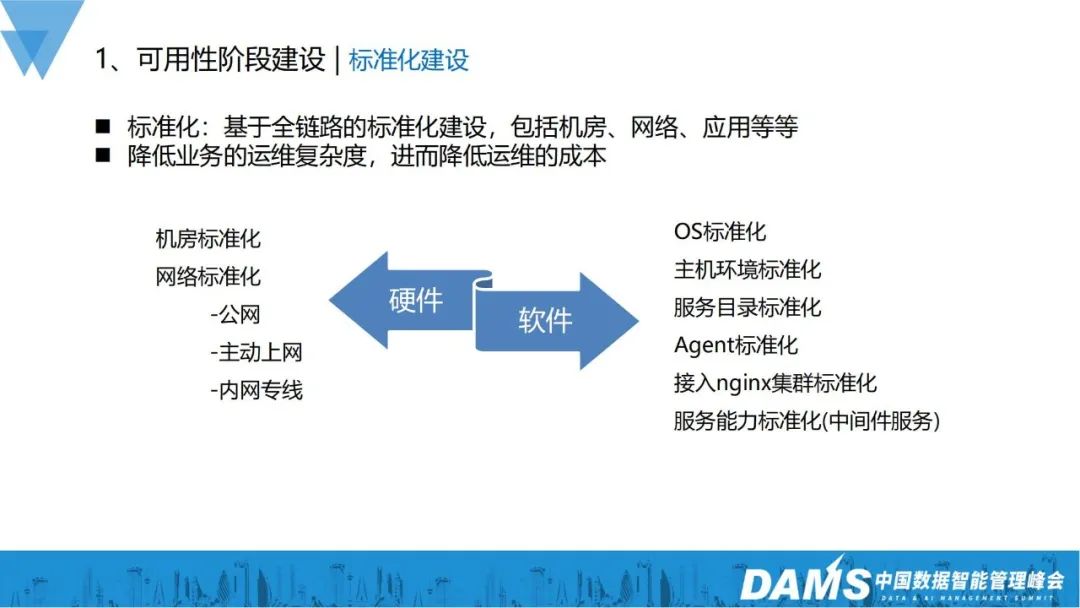
Pourquoi devrions-nous construire une normalisation ?
La normalisation peut réduire considérablement la complexité de l'exploitation et de la maintenance des entreprises, réduisant ainsi les coûts d'exploitation et de maintenance. Nous avons réalisé un gros travail de standardisation tant au niveau matériel que logiciel.
- Niveau matériel : standardisation de la salle informatique, standardisation du réseau (réseau public, accès Internet actif, ligne dédiée intranet) ;
- Niveau logiciel : standardisation de l'OS, standardisation de l'environnement hôte, standardisation de l'annuaire de services, standardisation des agents, accès au cluster nginx ; normalisation, normalisation des capacités des services (services middleware).
2. Processus et construction standardisée

Tout d'abord, nous précipiterons les meilleures pratiques et méthodes dans le processus d'exploitation et de maintenance dans les mécanismes et spécifications de processus, afin que La garantie de stabilité de l'entreprise est ordonnée et contrôlable, y compris les réglementations militaires d'exploitation et de maintenance, les mécanismes de réponse aux pannes, les réglementations des affaires publiques, les réglementations de garantie des événements à grande échelle, etc.
Par exemple, lorsque les spécifications de garantie pour les événements à grande échelle ne sont pas établies, il est facile que des pannes en ligne se produisent en cas d'activités opérationnelles à grande échelle ou d'activités de distribution d'enveloppes rouges de la Fête du Printemps. Des événements à grande échelle ont été créés en 2018, la Fête du Printemps et d'autres assurances lourdes peuvent assurer le bon fonctionnement.
3. Construction de plate-forme et de système
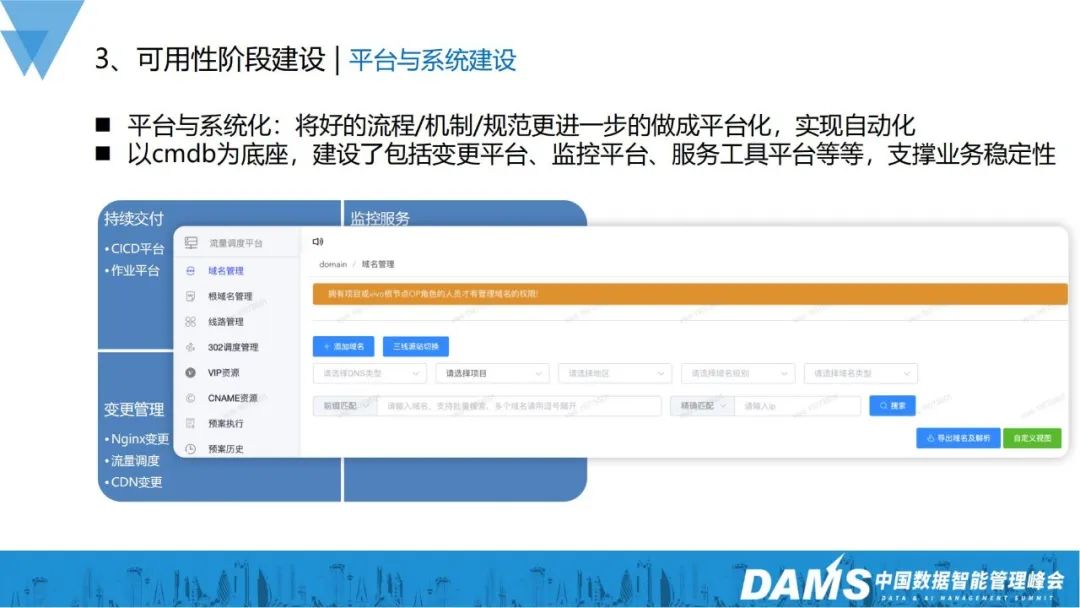
En termes de construction de plate-forme et de système, en utilisant CMDB comme base, le meilleur mécanisme de processus habituel est développé en une plate-forme, telle que en tant que plate-forme de modifications, plate-forme de surveillance, plate-forme d'outils de service, etc. pour soutenir la stabilité de l'entreprise.
4. Résultats et perspectives de disponibilité
D'ici 2022, l'exploitation et la maintenance globales de la stabilité de l'entreprise seront ordonnées et efficaces, et la disponibilité de l'entreprise passera des 3 9 précédentes aux 4 9 actuelles, et le nombre de les entreprises qui répondent aux normes augmenteront également de 8 avant à 24 maintenant.
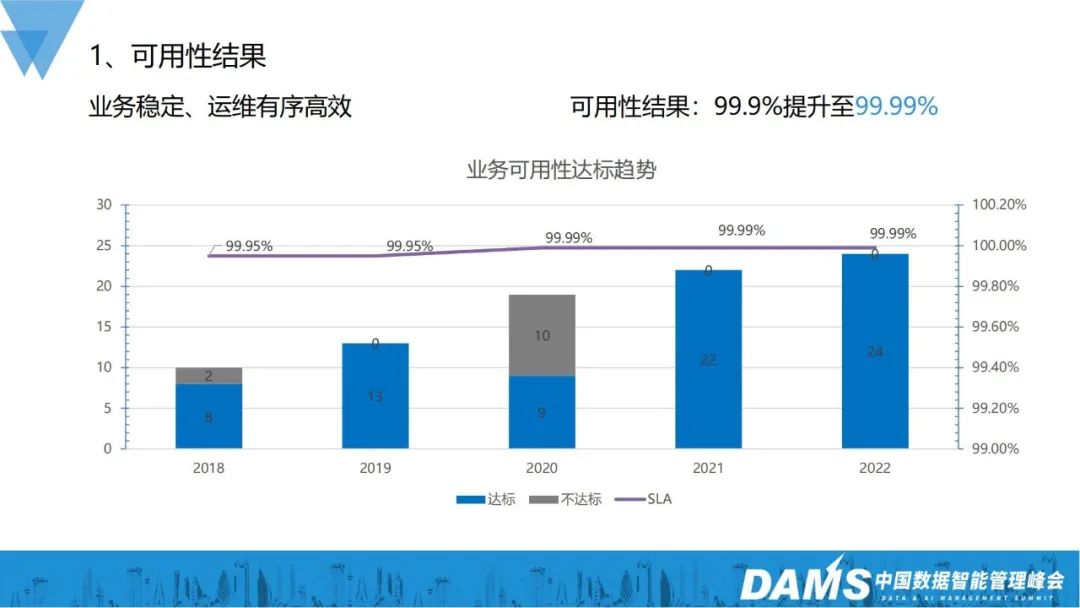
L'obtention de ce résultat de disponibilité passe principalement par le renforcement des capacités de disponibilité et la construction de l'étape de disponibilité :
- Développement des capacités de disponibilité : prévention des pannes, découverte des pannes, correction des pannes, examen des pannes
- Phase de disponibilité construction : standardisation, processus/normalisation, plateforme/automatisation

À l'avenir, nous nous concentrerons sur la garantie de disponibilité des multi-actifs distants et conteneurs/cloud natifs.
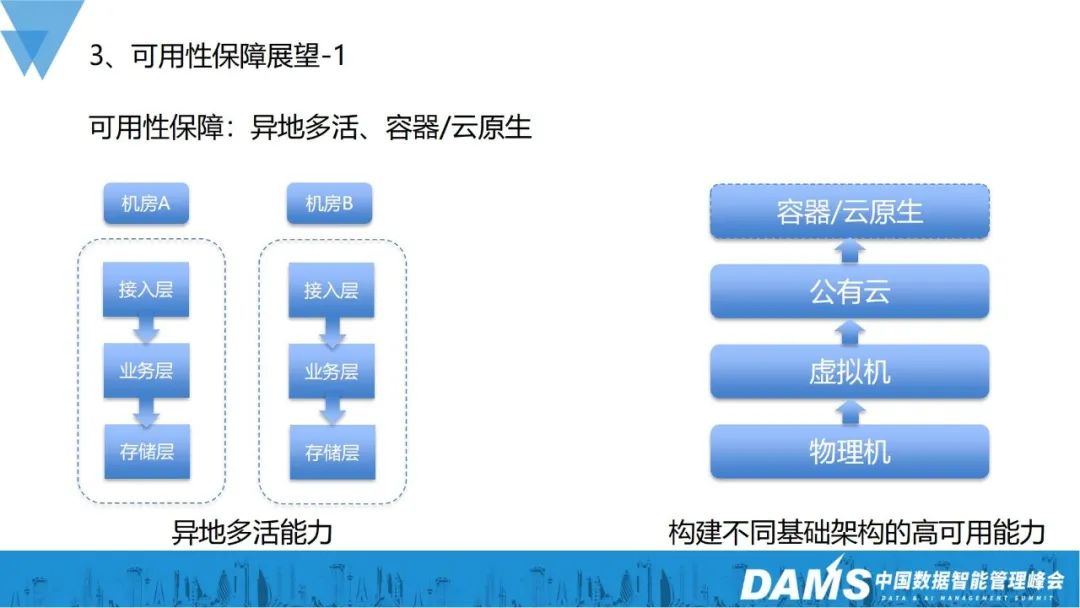
Prenons l'exemple de la garantie de disponibilité des conteneurs et du cloud natif. Nous avions l'habitude d'utiliser davantage de machines physiques pures, puis d'ajouter des machines virtuelles, puis d'ajouter des cloud publics, réduisant encore davantage le coût direct. dépendance à l'égard de l'infrastructure sous-jacente. Dans le même temps, nous travaillons également sur les conteneurs et le cloud natif pour unifier les ressources et les planifier de manière flexible afin de réduire la dépendance directe aux ressources matérielles physiques. Par conséquent, nous devons créer des capacités de haute disponibilité pour différentes infrastructures.
Que peut-on faire d'autre avec la création d'utilisabilité ?
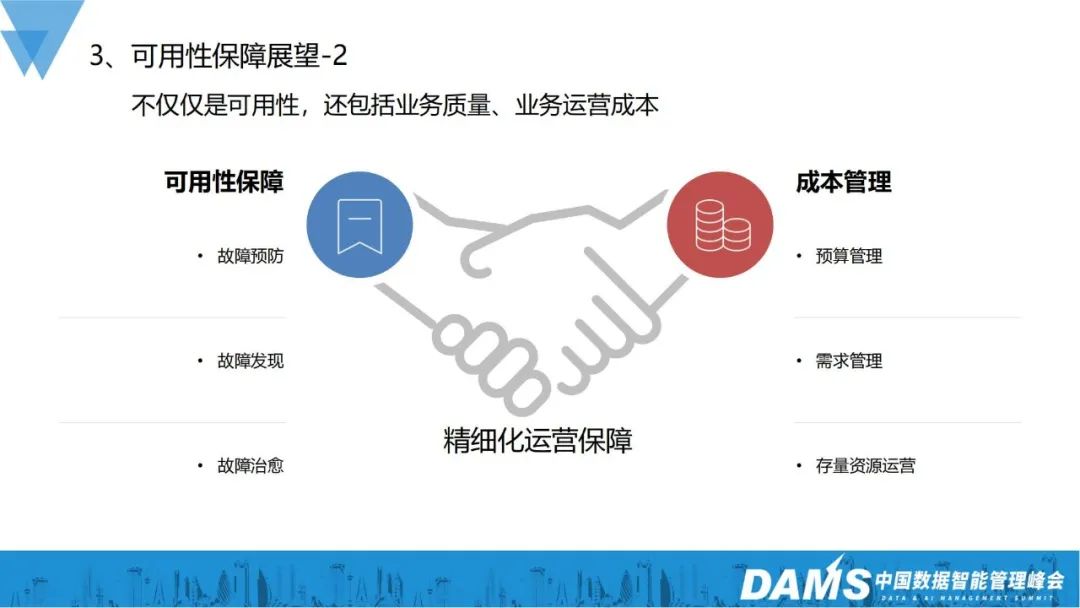
Je crois personnellement que l'on considère non seulement la disponibilité, mais aussi la qualité et les coûts d'exploitation de l'entreprise. La garantie d'exploitation et d'entretien de l'entreprise entrera par la suite dans l'étape de garantie d'exploitation affinée.
Q&A
Q1 : Quelles sont les plus grandes difficultés rencontrées lors de la mise en œuvre de la construction d'utilisabilité ?
A1 : Le premier point concerne les spécifications de construction des capacités techniques sous-jacentes. Le non-respect de ces spécifications entraînera une grande incertitude dans les résultats de la disponibilité commerciale, donc certaines spécifications doivent être formulées pour l'équipe, et il doit également y en avoir. soyez certain Le mécanisme de maintien du bas ;
Le deuxième point est la reconnaissance du niveau supérieur. Chaque entreprise a des exigences différentes à différentes étapes. Si la stabilité n'est pas bien faite, cela affectera l'entreprise, la réputation et les revenus. Après avoir obtenu l'approbation du niveau supérieur, la construction de la convivialité est également plus facile à promouvoir.
Q2 : Lors de la mise en œuvre de CMDB, en plus du responsable du développement, de l'hébergeur et d'autres informations, quelles autres informations votre entreprise a-t-elle associées dans le processus réel ? Par exemple, est-ce lié aux informations sur le middleware ?
A2 : Beaucoup de nos systèmes sont actuellement basés sur CMDB. Non seulement le système d'exploitation et de maintenance, de nombreux systèmes sont construits sur la base de CMDB. Les services middleware seront également construits en association avec CMDB, comme dans les microservices. également basé sur CMDB pour la découverte et la gouvernance des services.
Présentation de l'instructeur
Zhou Jiali est désormais le directeur de l'exploitation et de la maintenance de vivo, responsable de l'exploitation et de la maintenance des activités Internet de vivo. Cette personne qui a travaillé chez Baidu et Tencent possède de l'expérience dans l'exploitation et la maintenance d'entreprises hors ligne telles que les algorithmes client, d'internationalisation et de Big Data. Après avoir rejoint Vivo, j'ai dirigé la construction de la haute disponibilité de l'entreprise et amélioré la disponibilité de l'entreprise jusqu'à un niveau de 99,99 %.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Correctif : code d'erreur Microsoft Teams 80090016 Le module de plateforme approuvée de votre ordinateur a échoué
Apr 19, 2023 pm 09:28 PM
Correctif : code d'erreur Microsoft Teams 80090016 Le module de plateforme approuvée de votre ordinateur a échoué
Apr 19, 2023 pm 09:28 PM
<p>MSTeams est la plateforme de confiance pour communiquer, discuter ou appeler avec des coéquipiers et des collègues. Le code d'erreur 80090016 sur MSTeams et le message <strong>Le module de plateforme sécurisée de votre ordinateur a échoué</strong> peuvent entraîner des difficultés de connexion. L'application ne vous permettra pas de vous connecter tant que le code d'erreur n'est pas résolu. Si vous rencontrez de tels messages lors de l'ouverture de MS Teams ou de toute autre application Microsoft, cet article peut vous guider pour résoudre le problème. </p><h2&
 Que signifie l'erreur 0x0000004e ?
Feb 18, 2024 pm 01:54 PM
Que signifie l'erreur 0x0000004e ?
Feb 18, 2024 pm 01:54 PM
Qu’est-ce que l’échec 0x0000004e ? L’échec est un problème courant dans les systèmes informatiques. Lorsqu'un ordinateur rencontre une panne, le système s'arrête généralement, plante ou affiche des messages d'erreur car il ne peut pas fonctionner correctement. Dans les systèmes Windows, il existe un code d'erreur spécifique 0x0000004e, qui est un code d'erreur sur écran bleu indiquant que le système a rencontré une erreur grave. L'erreur d'écran bleu 0x0000004e est causée par des problèmes de noyau ou de pilote du système. Cette erreur provoque généralement le système informatique
 Que dois-je faire si mon téléphone Black Shark ne peut pas être allumé ? Apprenez-vous à vous sauver !
Mar 23, 2024 pm 04:06 PM
Que dois-je faire si mon téléphone Black Shark ne peut pas être allumé ? Apprenez-vous à vous sauver !
Mar 23, 2024 pm 04:06 PM
Que dois-je faire si mon téléphone Black Shark ne peut pas être allumé ? Apprenez-vous à vous sauver ! Dans notre vie quotidienne, les téléphones portables sont devenus un élément indispensable de nous. Pour de nombreuses personnes, le téléphone mobile Black Shark est un téléphone de jeu apprécié. Mais il est inévitable que vous rencontriez divers problèmes, dont l’impossibilité d’allumer le téléphone. Lorsque vous rencontrez une telle situation, ne paniquez pas. Voici quelques solutions, j'espère qu'elles pourront vous aider. Tout d'abord, lorsque le téléphone Black Shark ne peut pas être allumé, vérifiez d'abord si le téléphone est suffisamment alimenté. Il se peut que le téléphone ne puisse pas être allumé en raison d'une batterie épuisée.
 Que faire si la solution de défaut de l'imprimante partagée Win10 0x0000011b Solution de défaut de l'imprimante partagée Win10 0x0000011b
Jul 18, 2023 am 08:33 AM
Que faire si la solution de défaut de l'imprimante partagée Win10 0x0000011b Solution de défaut de l'imprimante partagée Win10 0x0000011b
Jul 18, 2023 am 08:33 AM
Les utilisateurs qui ont partagé des imprimantes ont constaté que leurs ordinateurs Win10 ne pouvaient pas se connecter aux imprimantes partagées après la mise à niveau du correctif de septembre 2021. Alors, que doivent-ils faire s'ils rencontrent l'échec de l'imprimante partagée Win10 0x0000011b ? Ce problème est rencontré par de nombreux utilisateurs. vous donne le contenu spécifique de la solution de panne de l'imprimante partagée Win10 0x0000011b. La méthode est très simple et les clients peuvent l'apprendre en un coup d'œil. Que faire si l'imprimante partagée Win10 0x0000011b échoue 1. Ouvrez le panneau de configuration, entrez le programme et les fonctions, puis vérifiez la mise à niveau installée 2. Désinstallez les correctifs suivants : KB5005569/KB5005573/KB5005568/KB ;
 Comment réparer l'erreur d'écran bleu 0x00000001
Feb 19, 2024 pm 11:12 PM
Comment réparer l'erreur d'écran bleu 0x00000001
Feb 19, 2024 pm 11:12 PM
Que faire à propos de l'écran bleu 0x00000001 ? Le problème de l'écran bleu est un casse-tête que de nombreux utilisateurs d'ordinateurs rencontrent souvent. Lorsque notre ordinateur rencontre un écran bleu, il s'arrête soudainement de fonctionner et affiche une interface à écran bleu avec un code d'erreur. Parmi eux, 0x00000001 est un code d’erreur d’écran bleu courant. Les problèmes d'écran bleu peuvent être causés par diverses raisons, notamment des erreurs logicielles, des pannes matérielles, des problèmes de pilotes, etc. Même si ce problème peut être frustrant, nous pouvons prendre certaines mesures pour le résoudre. Ci-dessous, je présenterai quelques solutions à l'écran bleu
 Mar 22, 2024 pm 09:03 PM
Mar 22, 2024 pm 09:03 PM
Black Shark est une marque de smartphones connue pour ses performances puissantes et son excellente expérience de jeu. Elle est appréciée des joueurs et des passionnés de technologie. Cependant, tout comme les autres smartphones, les téléphones Black Shark rencontreront divers problèmes, parmi lesquels les pannes de charge sont courantes. Une panne de charge affectera non seulement l'utilisation normale du téléphone mobile, mais peut également causer des problèmes plus graves. Il est donc très important de résoudre le problème de charge à temps. Cet article commencera par les causes courantes des échecs de chargement des téléphones mobiles Black Shark et présentera des méthodes pour dépanner et résoudre les problèmes de charge. J'espère qu'il pourra aider les lecteurs à résoudre les problèmes de chargement des téléphones Black Shark.
 Raisons et solutions au blocage du ventilateur de la carte graphique
Dec 26, 2023 pm 05:49 PM
Raisons et solutions au blocage du ventilateur de la carte graphique
Dec 26, 2023 pm 05:49 PM
De nombreux amis viennent d'acheter une nouvelle carte graphique. Après l'avoir installée pendant quelques jours, le ventilateur a soudainement cessé de tourner. Quelle est la raison ? Cela doit être un problème. les câbles mémoire et disque dur sont connectés et il n'y a pas d'alimentation. Est-ce normal ? Y a-t-il une instabilité de tension ? Voyons les raisons spécifiques avec l'éditeur. Réponses aux raisons pour lesquelles le ventilateur de la carte graphique ne tourne pas : 1. Une alimentation électrique insuffisante empêche le ventilateur de tourner. L'une des raisons les plus courantes est que lorsque l'énergie fournie par votre alimentation ne peut pas répondre aux exigences de la carte graphique, afin de maintenir le fonctionnement normal du programme informatique. les cartes graphiques arrêteront leurs ventilateurs de refroidissement pour garantir que le cœur du GPU puisse continuer à effectuer des calculs. Lorsque vous rencontrez cette situation, ne blâmez pas la carte graphique de ne pas être puissante ! C'est évidemment très prévenant, d'accord ?
 MySQL vs TiDB : quel est le meilleur pour votre entreprise ?
Jul 13, 2023 pm 03:09 PM
MySQL vs TiDB : quel est le meilleur pour votre entreprise ?
Jul 13, 2023 pm 03:09 PM
MySQL vs TiDB : quel est le meilleur pour votre entreprise ? Avec le développement rapide d’Internet et du Big Data, le stockage et la gestion des données sont devenus une partie importante des activités des entreprises. Lors du choix d'une solution de base de données appropriée, de nombreuses entreprises se retrouvent entre MySQL et TiDB. Cet article comparera les fonctionnalités et les avantages de MySQL et TiDB pour vous aider à déterminer lequel est le plus adapté à votre entreprise. MySQL est un système de gestion de bases de données relationnelles open source né dès 1995
