
 Opération et maintenance
Nginx
Cinq minutes de plaisir technique | Une brève analyse des règles hiérarchiques du groupe Linux
Opération et maintenance
Nginx
Cinq minutes de plaisir technique | Une brève analyse des règles hiérarchiques du groupe Linux
Cinq minutes de plaisir technique | Une brève analyse des règles hiérarchiques du groupe Linux


Partie 01 Présentation de cgroup
cgroup est l'abréviation de Control Groups. Il s'agit d'une sorte de ressources physiques (telles que : CPU, mémoire, périphérique IO) fournies par le noyau Linux. (peut contrôler des processus ou des groupes de processus, etc.) des mécanismes de restriction, d'isolement et de statistiques. La gestion de l'espace utilisateur de cgroup est réalisée via le système de fichiers cgroup. Grâce au système de fichiers virtuel de Linux, les détails du système de fichiers sont masqués et l'utilisateur réalise l'utilisation de cette fonction via les fichiers de contrôle correspondants.
cgroup a été introduit par Google pendant la période du noyau 2.6. Il constitue la base technique de la virtualisation des ressources dans le noyau Linux et la pierre angulaire technique des conteneurs LXC (Linux Containers) et Docker. Il existe les concepts associés suivants dans cgroup :
- Tâche : Un alias pour le processus
- Groupe de contrôle : ; Suivez un certain ensemble A de processus divisés par une norme. Le contrôle des ressources dans Cgroup est implémenté dans les unités des groupes de contrôle. Un processus peut être ajouté à un groupe de contrôle ou migré d'un groupe de processus à un autre. Les processus d'un groupe de processus peuvent utiliser les ressources allouées par les groupes de contrôle dans les unités des groupes de contrôle et sont soumis aux limites de ressources définies par le groupe de contrôle dans les unités des groupes de contrôle.
- Hiérarchie : La relation hiérarchique du groupe de contrôle est organisée dans une structure arborescente. Le groupe de contrôle du nœud enfant hérite des attributs de configuration des ressources du nœud parent.
- Sous-système (sous-système) : Un sous-système est un contrôleur de ressources. Par exemple, le sous-système CPU peut contrôler l'allocation du temps d'utilisation du processeur, comme le montre la figure 1. Un sous-système doit être attaché à un niveau pour fonctionner. Une fois qu'un sous-système est attaché à un certain niveau, tous les groupes de contrôle de ce niveau sont contrôlés par ce sous-système.
Partie 02 cgroup sous-système
Le sous-système est liées à la version du noyau Au fur et à mesure que le noyau itère, les ressources qui peuvent être limité Il y en a aussi de plus en plus, incluant généralement les sous-systèmes suivants.
➤ blkio : Définissez des restrictions sur l'accès aux entrées/sorties pour bloquer les périphériques, tels que les périphériques physiques (disque, SSD, USB, etc.).
➤ cpu : Limiter l'utilisation du processeur du processus, impliquant l'allocation de tranches de temps de planification du processeur.
➤ cpuacct : Génère automatiquement un rapport CPU utilisé par les tâches du groupe de contrôle.
➤ cpuset : Allouez un processeur indépendant (système multicœur) et des nœuds de mémoire aux tâches du groupe de contrôle.
➤ appareils : Autoriser ou refuser aux tâches du groupe de contrôle l'accès à l'appareil.
➤ freezer : Suspendre ou reprendre des tâches dans un groupe de contrôle.
➤ mémoire : Définissez la limite de mémoire utilisée par les tâches dans un groupe de contrôle et générez automatiquement un rapport sur les ressources mémoire utilisées par ces tâches.
➤ net_cls : Le marquage des paquets réseau avec des identifiants de classe permet au programme de contrôle d'errance Linux d'identifier les paquets générés à partir de groupes de contrôle spécifiques.
➤ ns : sous-système d'espace de noms.
Partie 03 Règles de hiérarchie cgroup
Combiné avec la hiérarchie cgroup (hiérarchie), il peut être compris comme un arbre. Chaque nœud de l'arborescence est un groupe de processus, et chacun. L'arbre sera associé à un associé à plusieurs sous-systèmes. Dans une arborescence, tous les processus du système Linux seront inclus, mais chaque processus ne peut appartenir qu'à un seul nœud (groupe de processus). Il peut y avoir de nombreuses arborescences de groupes de contrôle dans le système, et chaque arborescence est associée à un sous-système différent. Un processus peut appartenir à plusieurs arborescences, c'est-à-dire qu'un processus peut appartenir à plusieurs groupes de processus, mais ces groupes de processus sont associés à différents sous-systèmes. Actuellement, Linux peut créer jusqu'à douze arborescences de groupes de contrôle, et chaque arborescence est associée à un sous-système. Bien entendu, vous pouvez également créer une seule arborescence, puis associer cette arborescence à tous les sous-systèmes. Lorsqu'une arborescence de groupe de contrôle n'est associée à aucun sous-système, cela signifie que l'arborescence regroupe uniquement les processus. Quant à ce qu'il faut faire en fonction du regroupement, cela sera décidé par l'application elle-même. Systemd en est un exemple.
Il existe quatre règles de composition pour la hiérarchie, qui sont décrites comme suit :
Règle 1 : Une seule hiérarchie peut avoir un ou plusieurs sous-systèmes. Comme le montre la figure 1, le niveau /cpu_memory_cg configure deux sous-systèmes, processeur et mémoire, pour cgroup1 et cgroup2.
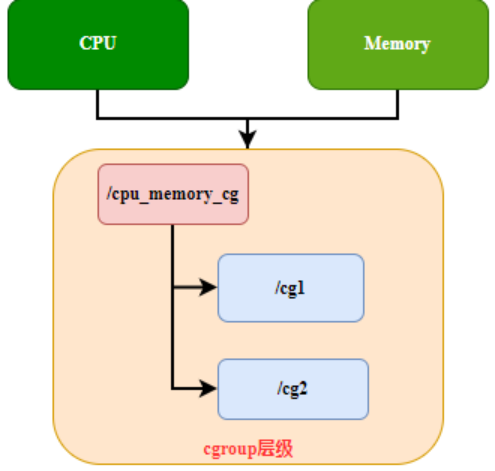
Figure 1 Règle de hiérarchie 1
Règle 2 : Si un sous-système est déjà attaché à un niveau, il ne peut pas être attaché à la structure d'un autre niveau. Comme le montre la figure 2, cpu_cg au niveau A gère d'abord le sous-système CPU, puis cpu_mem_cg au niveau B ne peut pas gérer le sous-système CPU.
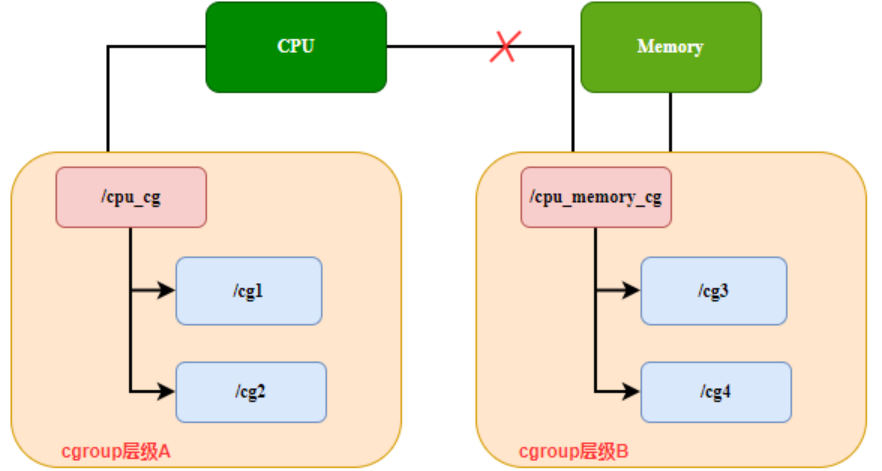
Figure 2, règle de hiérarchie de groupe de contrôle 2
Règle 3 : Chaque fois qu'une nouvelle hiérarchie est créée sur un système, toutes les tâches du système sont initialement membres du groupe de contrôle par défaut (appelé groupe de contrôle racine) de cette hiérarchie. Pour toute hiérarchie unique créée, chaque tâche du système peut être un membre du groupe de contrôle dans cette hiérarchie. Une tâche peut appartenir à plusieurs groupes de contrôle, à condition que chacun de ces groupes de contrôle se trouve dans une hiérarchie de sous-système différente. Une fois qu'une tâche devient membre du deuxième groupe de contrôle dans la même hiérarchie, elle sera supprimée du premier groupe de contrôle de la hiérarchie, c'est-à-dire que deux groupes de contrôle non liés dans la même hiérarchie n'auront jamais la même tâche. ne peut être qu'un moyen de restreindre un certain type de sous-système de groupe de contrôle pour un certain processus. Lorsque vous créez la première hiérarchie, chaque tâche du système est membre d'au moins un groupe de contrôle (le groupe de contrôle racine). Ainsi, lorsque vous utilisez des groupes de contrôle, chaque tâche système se trouve toujours dans au moins un groupe de contrôle, comme le montre la figure 3.
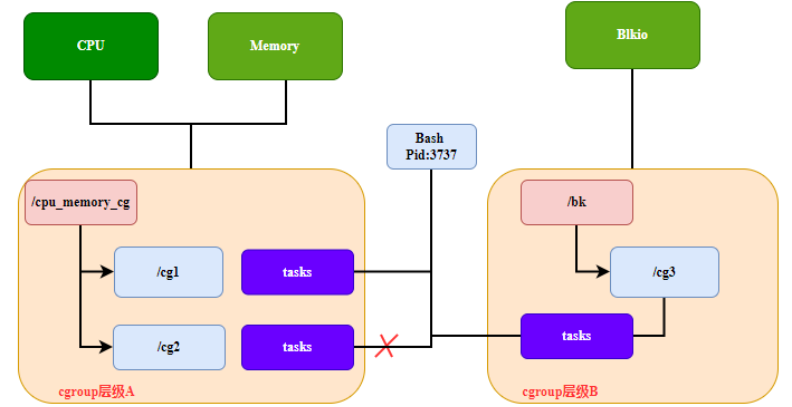
Figure 3, règle 3 de la hiérarchie cgroup
Règle 4 : Tout processus dérivé sur le système créera un processus enfant (ou thread). Le processus enfant hérite automatiquement de l'appartenance au groupe de contrôle de son parent, mais peut être déplacé vers d'autres groupes de contrôle si nécessaire. Après le déplacement, les processus parent et enfant sont complètement indépendants, comme le montre la figure 4.
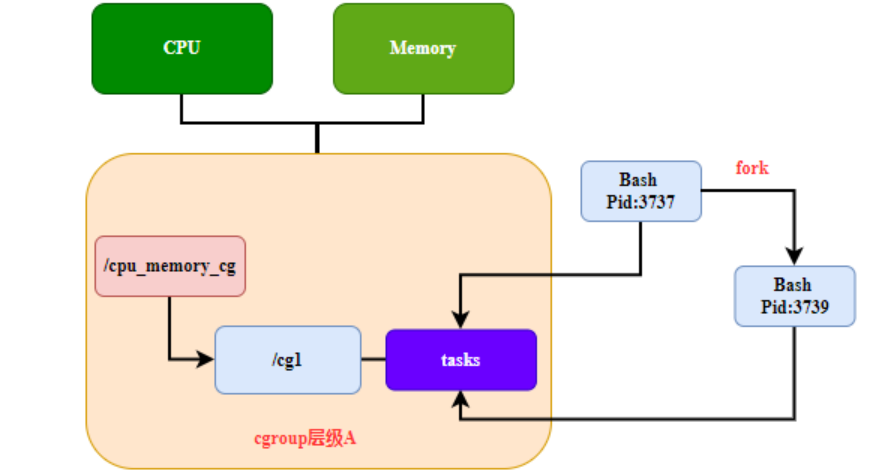
Figure 4 règle de hiérarchie de cgroup 4
Partie 04analyse de la relation hiérarchique de cgroup
Nous partons du point de vue du processus et combiner La structure des données dans le code source est utilisée pour analyser la relation entre les données liées aux groupes de contrôle. Tout d'abord, sous Linux, la structure de données du processus de gestion est task_struct, dans laquelle les membres liés aux cgroups sont les suivants :
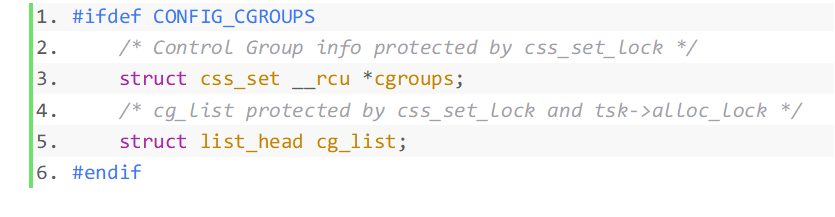
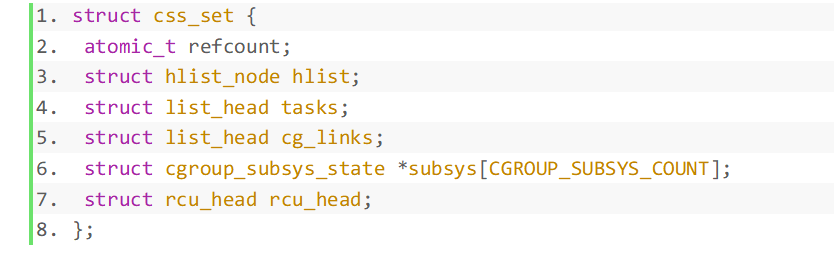
- refcount est le nombre de références de css _set, qui peut être partagé par plusieurs processus À utiliser, à condition que les informations de groupe de contrôle de ces processus soient les mêmes. Par exemple, les processus dans le même groupe de contrôle dans toutes les hiérarchies créées.
- hlist est utilisé pour construire tous les css_sets dans une table de hachage, et le noyau peut rapidement trouver des css_sets spécifiques.
- tasks relie tous les processus qui font référence à ce css_set dans une liste chaînée.
- cg_links pointe vers une liste chaînée composée de struct cg_group_link
- subsys est un tableau de pointeurs, stockant un ensemble de pointeurs vers cgroup_subsys_state. Un cgroup_subsys_state est une information relative à un processus et à un sous-système spécifique. Grâce à ce pointeur, le processus peut obtenir les informations de contrôle des groupes de contrôle correspondants.
Le pointeur cgroup dans la structure pointe vers une structure cgroup. Le processus est contrôlé par les ressources du sous-système. Ceci est en fait réalisé en rejoignant un sous-système cgroup spécifique, car cgroup est à. un niveau spécifique. Les sous-systèmes sont rattachés à la hiérarchie. Jetons un coup d'œil à la structure du groupe de contrôle, Afin de clarifier la relation entre css_set et cgroup, nous devons également analyser la structure cg_cgroup_link de la couche intermédiaire. Les données de structure sont les suivantes : Les données dans la structure sont décrites comme suit : cgrp_link_list est liée à la liste chaînée pointée par cgroup->css_sets. cgrp pointe vers le groupe lié à ce cg_cgroup_link. cg_link_list est lié à la liste chaînée pointée par css_set->cg_links. cg pointe vers le css_set lié à cg_cgroup_link. On peut voir que cgroup et css_set sont en fait une relation plusieurs-à-plusieurs. Une structure intermédiaire doit être ajoutée pour combiner les deux. Les éléments cgrp et cg dans cg_group_link sont les parties combinées. Les listes chaînées de cgrp_link_list et cg_link_list sont C'est l'entité cgroup et css_set attachée pour faciliter l'interrogation. Il ressort des règles hiérarchiques des groupes de contrôle qu'un groupe de processus peut appartenir à des groupes de contrôle qui ne sont pas au même niveau. Compréhension combinée, un css_set stocke les informations relatives à chaque sous-système d'un groupe de racines de processus. . Les sous-systèmes proviennent de différents niveaux de groupe de contrôle, donc le cgroup_subsys_state stocké dans un css_set peut correspondre à plusieurs groupes de contrôle. D'un autre côté, le niveau cgroup stocke également un ensemble de cgroup_subsys_state, qui est obtenu à partir du sous-système attaché au niveau où se trouve le cgroup. Un cgroup peut avoir plusieurs processus, et le css_set du processus n'est pas nécessairement le même. car le processus peut utiliser plusieurs niveaux. Par conséquent, un groupe de contrôle doit également correspondre à plusieurs css_sets. La figure 5 décrit en détail la relation d'accrochage plusieurs-à-plusieurs. 
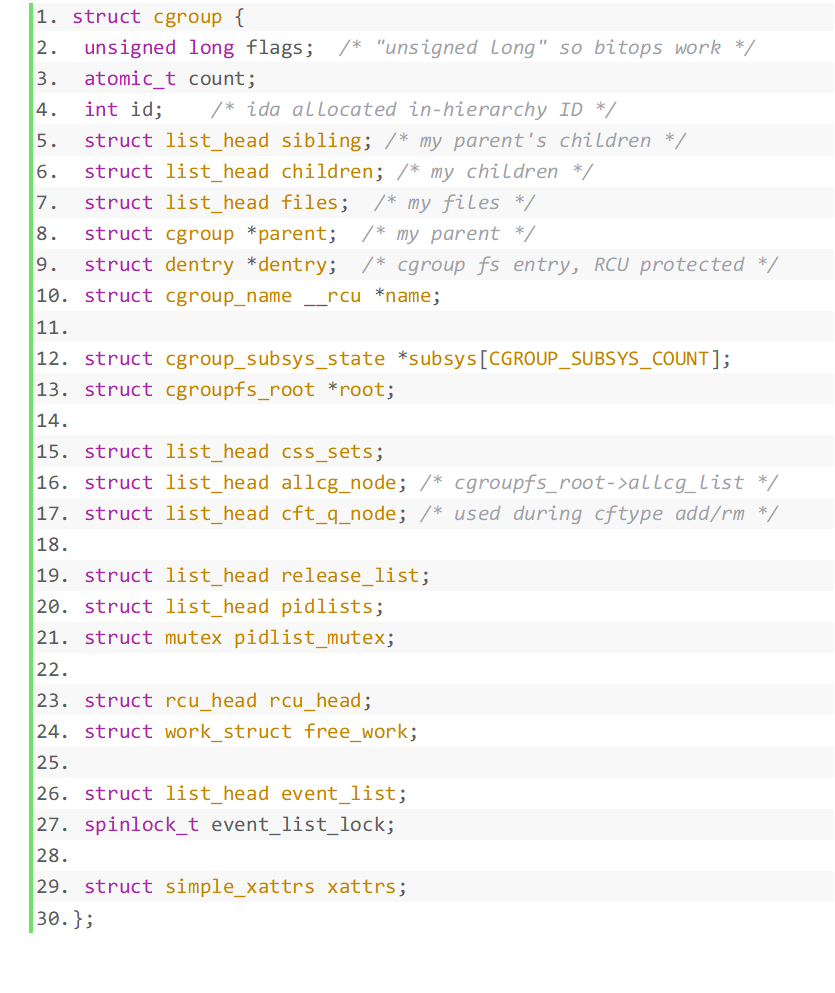
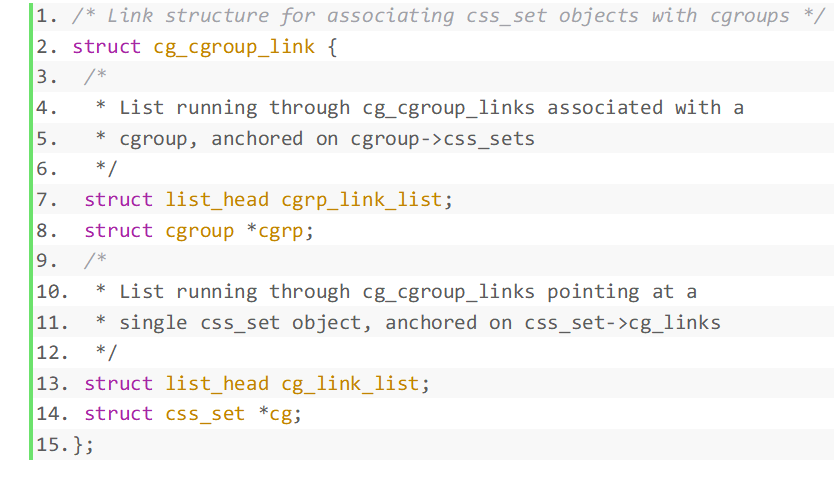
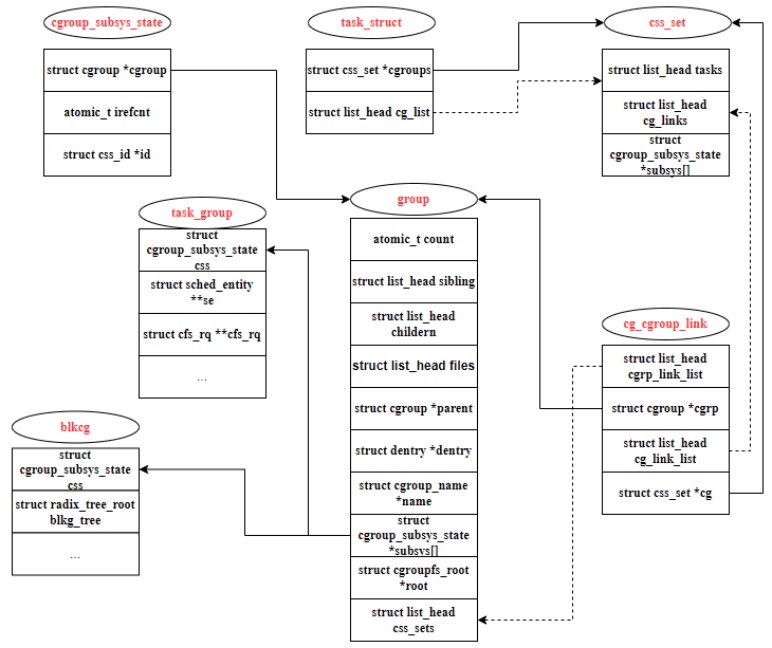
Figure 5 Processus et diagramme de relation plusieurs-à-plusieurs de groupe de contrôle
Partie 05 Conclusion
Basé sur le concept de groupe de contrôle, cet article démonte la relation plusieurs-à-plusieurs entre celui-ci et le processus, et l'analyse à partir de l'accrochage de variables dans le processus pertinent. La structure spécifique du code devrait aider les lecteurs à mieux comprendre la relation hiérarchique et l'utilisation des groupes de contrôle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Les étapes pour démarrer Apache sont les suivantes: Installez Apache (Commande: Sudo apt-get install Apache2 ou téléchargez-le à partir du site officiel) Start Apache (Linux: Sudo SystemCTL Démarrer Apache2; Windows: Cliquez avec le bouton droit sur le service "APACHE2.4" et SELECT ") Vérifiez si elle a été lancée (Linux: SUDO SYSTEMCTL STATURE APACHE2; (Facultatif, Linux: Sudo SystemCTL
 Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Que faire si le port Apache80 est occupé
Apr 13, 2025 pm 01:24 PM
Lorsque le port Apache 80 est occupé, la solution est la suivante: découvrez le processus qui occupe le port et fermez-le. Vérifiez les paramètres du pare-feu pour vous assurer qu'Apache n'est pas bloqué. Si la méthode ci-dessus ne fonctionne pas, veuillez reconfigurer Apache pour utiliser un port différent. Redémarrez le service Apache.
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
 Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Comment configurer un bac de recyclage dans le système Debian
Apr 12, 2025 pm 10:51 PM
Cet article présente deux méthodes de configuration d'un bac de recyclage dans un système Debian: une interface graphique et une ligne de commande. Méthode 1: Utilisez l'interface graphique Nautilus pour ouvrir le gestionnaire de fichiers: Recherchez et démarrez le gestionnaire de fichiers Nautilus (généralement appelé "fichier") dans le menu de bureau ou d'application. Trouvez le bac de recyclage: recherchez le dossier de bac de recyclage dans la barre de navigation gauche. S'il n'est pas trouvé, essayez de cliquer sur "Autre emplacement" ou "ordinateur" pour rechercher. Configurer les propriétés du bac de recyclage: cliquez avec le bouton droit sur "Recycler le bac" et sélectionnez "Propriétés". Dans la fenêtre Propriétés, vous pouvez ajuster les paramètres suivants: Taille maximale: Limitez l'espace disque disponible dans le bac de recyclage. Temps de rétention: définissez la préservation avant que le fichier ne soit automatiquement supprimé dans le bac de recyclage
 L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
L'importance de Debian Sniffer dans la surveillance du réseau
Apr 12, 2025 pm 11:03 PM
Bien que les résultats de la recherche ne mentionnent pas directement "Debiansniffer" et son application spécifique dans la surveillance du réseau, nous pouvons en déduire que "Sniffer" se réfère à un outil d'analyse de capture de paquets de réseau, et son application dans le système Debian n'est pas essentiellement différente des autres distributions Linux. La surveillance du réseau est cruciale pour maintenir la stabilité du réseau et l'optimisation des performances, et les outils d'analyse de capture de paquets jouent un rôle clé. Ce qui suit explique le rôle important des outils de surveillance du réseau (tels que Sniffer Running dans Debian Systems): La valeur des outils de surveillance du réseau: Faute-défaut Emplacement: surveillance en temps réel des métriques du réseau, telles que l'utilisation de la bande passante, la latence, le taux de perte de paquets, etc.
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Comment redémarrer le serveur Apache
Apr 13, 2025 pm 01:12 PM
Pour redémarrer le serveur Apache, suivez ces étapes: Linux / MacOS: Exécutez Sudo SystemCTL Restart Apache2. Windows: Exécutez net stop apache2.4 puis net start apache2.4. Exécuter netstat -a | Findstr 80 pour vérifier l'état du serveur.
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
