
 Opération et maintenance
Sécurité
Uber Practice : Quelques expériences dans l'exploitation et la maintenance de systèmes distribués à grande échelle
Opération et maintenance
Sécurité
Uber Practice : Quelques expériences dans l'exploitation et la maintenance de systèmes distribués à grande échelle
Uber Practice : Quelques expériences dans l'exploitation et la maintenance de systèmes distribués à grande échelle

Depuis quelques années, je construis et exploite un grand système distribué : le système de paiement d'Uber. Au cours de cette période, j'ai beaucoup appris sur les concepts d'architecture distribuée et j'ai été témoin des défis liés à l'exécution de systèmes à charge élevée et à haute disponibilité (un système est loin d'être terminé lorsqu'il est développé, et les défis liés à son exécution en ligne sont en fait encore plus grand). Construire le système lui-même est une entreprise intéressante. Planifier la manière dont le système gérera les augmentations de trafic 10x/100x, garantir la durabilité des données, gérer les pannes matérielles, etc. nécessitent tous de la sagesse. Quoi qu’il en soit, l’exploitation de grands systèmes distribués a été pour moi une expérience révélatrice. Plus le système est grand, plus la loi de Murphy selon laquelle « ce qui peut mal tourner, tournera mal » sera reflétée. De nombreux développeurs déploient et déploient fréquemment du code, plusieurs centres de données sont impliqués et le système est utilisé par un grand nombre d'utilisateurs dans le monde, plus la probabilité de telles erreurs est grande. Au cours des dernières années, j'ai été confronté à diverses pannes de système, dont beaucoup m'ont surpris. Certaines proviennent de facteurs prévisibles, tels que des pannes matérielles ou des bugs apparemment inoffensifs, ainsi que des câbles de centres de données déterrés et de multiples pannes en cascade se produisant simultanément. J'ai connu des dizaines de pannes d'entreprise au cours desquelles une partie du système ne fonctionnait pas correctement, ce qui a eu un impact énorme sur l'entreprise. Cet article est un ensemble de pratiques que j'ai résumées lorsque je travaillais chez Uber et qui peuvent exploiter et entretenir efficacement de grands systèmes. Mon expérience n'est pas unique : les personnes travaillant sur des systèmes de taille similaire ont vécu des parcours similaires. J'ai parlé à des ingénieurs de Google, Facebook et Netflix, et ils ont partagé des expériences et des solutions similaires. La plupart des idées et des processus décrits ici devraient s'appliquer à des systèmes de taille similaire, qu'ils fonctionnent sur leurs propres centres de données (comme Uber le fait dans la plupart des cas) ou dans le cloud (Uber déploie parfois de manière élastique une partie de ses services dans le cloud). Toutefois, ces pratiques peuvent s'avérer trop strictes pour les systèmes plus petits ou moins critiques. Il y a beaucoup de choses à aborder - j'aborderai les sujets suivants :Cet article est rédigé par l'ingénieur Uber Gergely Orosz. L'adresse d'origine est : https://blog.pragmaticengineer.com/operating-a-high-scale-distributed-system/
#. 🎜 🎜#
- surveillance
- en service, détection d'anomalies et alerting#🎜🎜 #
- Processus de gestion des pannes et des incidents
- Analyse post-mortem, examen des incidents et culture d'amélioration continue
- Exercices de pannes, planification des capacités et tests en boîte noire #🎜 🎜#SLO, SLA et leurs rapports
- SRE en tant qu'équipe indépendante
- La fiabilité comme investissement continu
- Plus de lectures recommandées
- # 🎜🎜# Surveillance
- Pour savoir si un système est sain, il faut répondre à la question « Mon système fonctionne-t-il correctement ? Pour ce faire, la collecte de données sur les éléments clés du système est cruciale. Pour les systèmes distribués avec plusieurs services exécutés sur plusieurs ordinateurs et centres de données, il peut être difficile de déterminer quels sont les éléments clés à surveiller.
Surveillance de l'état de l'infrastructure Si un ou plusieurs ordinateurs/machines virtuelles sont surchargés, certaines parties du système distribué peuvent se dégrader. L'état de santé de la machine, l'utilisation du processeur et l'utilisation de la mémoire sont des contenus de base qui méritent d'être surveillés. Certaines plates-formes peuvent gérer ces instances de surveillance et de mise à l'échelle automatique dès le départ. Chez Uber, nous disposons d'une excellente équipe d'infrastructure de base qui assure la surveillance de l'infrastructure et des alertes prêtes à l'emploi. Quelle que soit la manière dont elle est mise en œuvre au niveau technique, lorsqu'il y a un problème avec l'instance ou l'infrastructure, la plateforme de surveillance doit fournir les informations nécessaires.
Surveillance de l'état des services : trafic, erreurs, latence. Nous devons souvent répondre à la question « Ce service backend est-il sain ? » L'observation d'éléments tels que le trafic de requêtes, les taux d'erreur et la latence des points de terminaison d'accès aux points de terminaison peuvent tous fournir des informations précieuses sur la santé de votre service. Je préfère que tout cela soit affiché sur le tableau de bord. Lors de la création d'un nouveau service, vous pouvez en apprendre beaucoup sur le système en utilisant le mappage de réponse HTTP correct et en surveillant le code correspondant. Par conséquent, s’assurer que 4XX est renvoyé en cas d’erreurs client et 5xx en cas d’erreurs serveur est facile à créer et à interpréter.
Les retards de surveillance méritent d'être reconsidérés. Pour les services de production, l’objectif est que la majorité des utilisateurs finaux vivent une bonne expérience. Il s’avère que mesurer la latence moyenne n’est pas une très bonne mesure car cette moyenne peut cacher un petit pourcentage de requêtes à latence élevée. Mesurer p95, p99 ou p999 – la latence rencontrée par les requêtes du 95e, 99e ou 99,9e centile – est une meilleure mesure. Ces chiffres aident à répondre à des questions telles que « À quelle vitesse sont traitées 99 % des demandes des gens ? » (p99). ou "Quelle est la lenteur d'un retard au moins une personne sur 1 000 ?" (p999). Pour ceux qui s’intéressent davantage à ce sujet, cet article d’introduction différé propose des lectures complémentaires.
Il ressort clairement de la figure que les différences de délai moyen, p95 et p99 sont assez importantes. La latence moyenne peut donc masquer certains problèmes.
Il existe un contenu beaucoup plus approfondi sur la surveillance et l’observabilité. Deux ressources qui valent la peine d'être lues sont le livre SRE de Google et la section sur les quatre indicateurs d'or de la surveillance des systèmes distribués. Ils recommandent que si vous ne pouvez mesurer que quatre métriques pour votre système destiné aux utilisateurs, concentrez-vous sur le trafic, les erreurs, la latence et la saturation. Pour des documents plus courts, je recommande le livre électronique Distributed Systems Observability de Cindy Sridharan, qui couvre d'autres outils utiles tels que la journalisation des événements, les métriques et les meilleures pratiques de traçage.
Suivi des indicateurs métiers. La surveillance du module de service peut nous indiquer comment le module de service fonctionne normalement, mais elle ne peut pas nous dire si l'entreprise fonctionne comme prévu et si elle continue son activité comme d'habitude. Dans les systèmes de paiement, une question clé est la suivante : « Les gens peuvent-ils utiliser un mode de paiement spécifique pour effectuer des paiements ? L'identification des événements commerciaux et leur suivi constituent l'une des étapes de surveillance les plus importantes.
Bien que nous ayons mis en place divers suivis, certains problèmes d'affaires sont restés indétectables, ce qui nous a causé beaucoup de peine et a finalement mis en place un suivi des indicateurs d'affaires. Parfois, tous nos services semblent fonctionner normalement, mais les fonctionnalités clés du produit ne sont pas disponibles ! Ce type de suivi est très utile pour notre organisation et notre terrain. Par conséquent, nous avons dû consacrer beaucoup de réflexion et d’efforts à personnaliser nous-mêmes ce type de surveillance, sur la base de la pile technologique d’observabilité d’Uber.
Note du traducteur : Nous ressentons vraiment la même chose concernant le suivi des indicateurs commerciaux Dans le passé, nous constations parfois que tous les services étaient normaux à Didi, mais que l'entreprise ne fonctionnait pas bien. Le système Polaris que nous construisons actuellement pour démarrer une entreprise est spécialement conçu pour résoudre ce problème. Les amis intéressés peuvent me laisser un message en arrière-plan du compte officiel, ou ajouter mon ami picobyte pour communiquer et l'essayer.
Appel, détection d'anomalies et alertes
La surveillance est un excellent outil pour avoir un aperçu de l'état actuel de votre système. Mais il ne s’agit là que d’un tremplin pour détecter automatiquement les problèmes et déclencher des alertes incitant les utilisateurs à agir.
Oncall est en soi un vaste sujet – Increment Magazine couvre de nombreux aspects dans son « On-Call Issue ». Mon opinion est que si vous avez une mentalité « vous le construisez, vous le possédez », OnCall suivra. L'équipe qui construit les services en est propriétaire et est responsable de leur disponibilité. Notre équipe est en service pour les services de paiement. Ainsi, chaque fois qu'une alarme se produit, l'ingénieur de service répond et examine les détails. Mais comment passer de la surveillance à l’alerte ?
La détection des anomalies à partir des données de surveillance est un défi difficile et un domaine dans lequel l'apprentissage automatique peut briller. Il existe de nombreux services tiers permettant la détection des anomalies. Heureusement encore une fois, notre équipe disposait d'une équipe interne d'apprentissage automatique avec laquelle travailler, et elle a adapté la solution à l'utilisation d'Uber. L’équipe Observability basée à New York a écrit un article utile expliquant comment fonctionne la détection des anomalies d’Uber. Du point de vue de mon équipe, nous transmettons les données de surveillance au pipeline de cette équipe et recevons des alertes avec des niveaux de confiance respectifs. Nous décidons ensuite si nous devons faire appel à un ingénieur.
Quand déclencher une alarme est une question intéressante. Trop peu d’alertes peuvent signifier manquer une panne importante. Trop de choses peuvent conduire à des nuits blanches et à l’épuisement. Le suivi et la classification des alarmes ainsi que la mesure du rapport signal/bruit sont essentiels au réglage des systèmes d'alarme. Examiner les alertes et les signaler comme étant exploitables, puis prendre des mesures pour réduire les alertes qui ne sont pas exploitables, est une bonne étape vers une rotation d'astreinte durable.
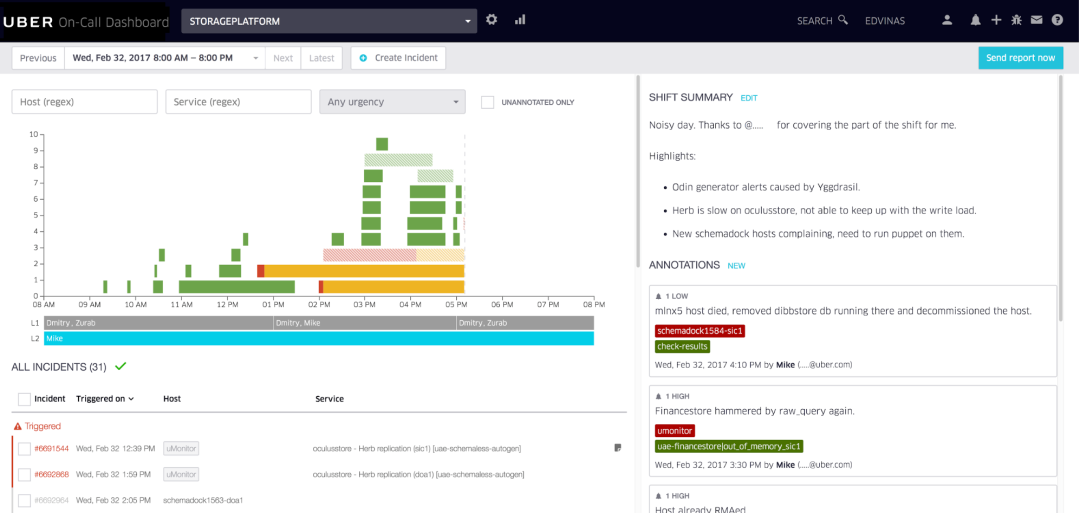
Exemple de tableau de bord de garde interne utilisé par Uber, construit par l'équipe Uber Developer Experience de Vilnius.
L'équipe Uber Dev Tools de Vilnius a créé un outil d'appel soigné que nous utilisons pour annoter les alertes et visualiser les changements d'appel. Notre équipe effectue des examens hebdomadaires du dernier quart de travail de garde, analyse les points faibles et consacre du temps à améliorer l'expérience de garde, semaine après semaine.
Note du traducteur : l'agrégation d'événements d'alarme, la réduction du bruit, la planification, la réclamation, la mise à niveau, la collaboration, la stratégie push flexible, le push multicanal et la connexion IM sont des besoins très courants. Vous pouvez vous référer à l'adresse du produit FlashDuty pour en faire l'expérience. : https://console.flashcat.cloud/
Processus de gestion des pannes et des incidents
Imaginez ceci : vous êtes l'ingénieur de service cette semaine. Au milieu de la nuit, une alarme vous réveille. Vous recherchez si une interruption de production s'est produite. Oups, il semble qu'il y ait un problème avec une partie du système. Et maintenant ? La surveillance et les alertes se produisent réellement.
Pour les petits systèmes, les pannes peuvent ne pas être un gros problème et l'ingénieur de service peut comprendre ce qui se passe et pourquoi. Ils sont généralement faciles à comprendre et à atténuer. Pour les systèmes complexes comportant plusieurs (micro)services et de nombreux ingénieurs poussant le code en production, le simple fait d'identifier les problèmes potentiels peut s'avérer déjà assez difficile. Disposer de processus standard pour aider à résoudre ce problème peut faire une énorme différence.
Un runbook joint à l'alerte décrivant des étapes d'atténuation simples comme première ligne de défense. Pour les équipes disposant de bons runbooks, même si l’ingénieur de service n’a pas une compréhension approfondie du système, cela posera rarement un problème. Les runbooks doivent être tenus à jour, mis à jour et utiliser de nouvelles atténuations pour gérer les échecs lorsqu'ils se produisent.
Note du traducteur : la configuration des règles d'alarme de Nightingale et Grafana peut prendre en charge des champs personnalisés, mais certains champs supplémentaires sont fournis par défaut, tels que RunbookUrl. L'essentiel est de transmettre l'importance du manuel SOP. De plus, dans le système de gestion de la stabilité, le fait que les règles d'alarme aient un RunbookUrl prédéfini est un indicateur très important de l'état de santé de l'alarme.
Une fois que plusieurs équipes déploient des services, la communication des erreurs au sein de l'organisation devient critique. Je travaille dans un environnement où des milliers d'ingénieurs déploient des services qu'ils développent en production à leur propre discrétion, potentiellement des centaines de déploiements par heure. Un déploiement de service apparemment sans rapport peut avoir un impact sur un autre service. Dans ce cas, les canaux de diffusion et de communication standardisés des défauts peuvent être très utiles. J'avais rencontré divers messages d'alerte rares et réalisé que des membres d'autres équipes étaient témoins de phénomènes étranges similaires. En rejoignant un groupe de discussion centralisé pour gérer les pannes, nous avons rapidement identifié le service à l'origine de la panne et résolu le problème. Nous l’avons fait plus rapidement que quiconque ne le pourrait.
Soulager maintenant, enquêter demain. Lors d'une panne, j'éprouve souvent cette « montée d'adrénaline » de vouloir réparer ce qui n'a pas fonctionné. La cause première est souvent un mauvais déploiement du code, avec des bogues évidents dans les modifications du code. Dans le passé, j'intervenais directement et corrigeais le bogue, poussais le correctif et fermais le bogue au lieu d'annuler les modifications du code. Cependant, corriger la cause profonde d’une panne est une très mauvaise idée. Il y a peu de gains et beaucoup de pertes à utiliser la restauration avancée. Étant donné que les nouveaux correctifs doivent être effectués rapidement, ils doivent être testés en production. C'est pourquoi une deuxième erreur - ou un problème s'ajoutant à une erreur existante - est introduite. J'ai vu des problèmes comme celui-ci s'aggraver. Concentrez-vous d’abord sur l’atténuation et résistez à l’envie de réparer ou d’enquêter sur la cause profonde. Une enquête appropriée peut attendre le jour ouvrable suivant.
Note du traducteur : les pilotes expérimentés doivent également en être profondément conscients. Ne déboguez pas en ligne si un problème survient, revenez immédiatement en arrière au lieu d'essayer de publier une version de correctif pour le résoudre !
Analyse post-mortem, examen des incidents et culture d'amélioration continue
Il s'agit de la façon dont une équipe gère les conséquences d'un échec. Vont-ils continuer à travailler ? Vont-ils faire une petite enquête ? Vont-ils consacrer une quantité surprenante d’efforts à l’avenir, en arrêtant le travail sur le produit pour apporter une solution au niveau du système ?
Une analyse post-mortem correctement effectuée est la pierre angulaire de la construction d’un système solide. Une bonne autopsie est à la fois non accusatrice et approfondie. Le modèle post-mortem d'Uber continue d'évoluer avec la technologie d'ingénierie et comprend des sections telles que l'aperçu des incidents, l'aperçu de l'impact, la chronologie, l'analyse des causes profondes, les leçons apprises et une liste de contrôle de suivi détaillée.
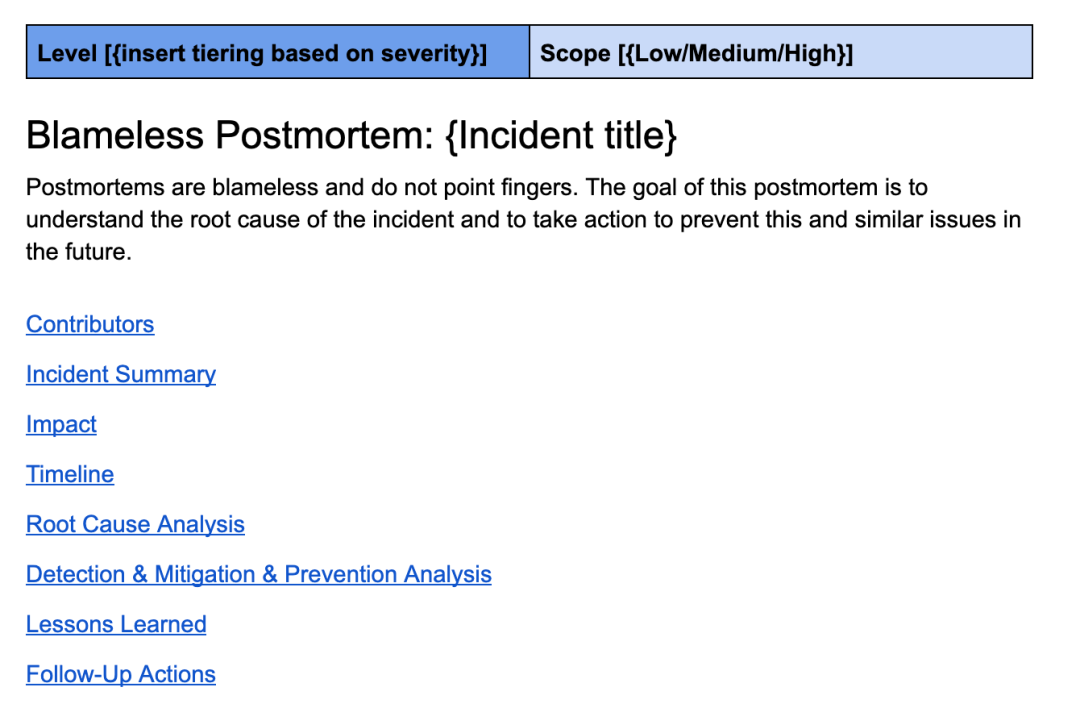
Il s'agit d'un modèle d'avis similaire à celui que j'utilise chez Uber.
Une bonne autopsie approfondit les causes profondes et suggère des améliorations pour prévenir, détecter ou atténuer plus rapidement toutes les pannes similaires. Quand je dis de creuser plus profondément, je veux dire qu'ils ne s'arrêtent pas à la cause première, à savoir le mauvais changement de code et le fait que le réviseur de code n'a pas détecté le bogue.
Ils utilisent la méthode d’exploration des « 5pourquoi » pour creuser plus profondément et parvenir à des conclusions plus significatives. Par exemple :
- Pourquoi ce problème se produit-il ? –> Parce qu'un bug a été introduit dans le code.
- Pourquoi personne d'autre n'a-t-il attrapé ce bug ? –> Les modifications de code non remarquées par les réviseurs de code peuvent provoquer de tels problèmes.
- Pourquoi comptons-nous uniquement sur les réviseurs de code pour détecter cette erreur ? –> Parce que nous n’avons pas de tests automatisés pour ce cas d’utilisation.
- "Pourquoi n'avons-nous pas de tests automatisés pour ce cas d'utilisation ?" –> Parce qu'il est difficile de tester sans compte de test.
- Pourquoi n'avons-nous pas de compte test ? –> Parce que le système ne les prend pas encore en charge
- Conclusion : ce problème indique un problème systémique lié au manque de comptes de test. Il est recommandé d'ajouter la prise en charge des comptes de test au système. Ensuite, écrivez des tests automatisés pour toutes les futures modifications de code similaires.
L'examen des événements est un outil de support important pour l'analyse post-événement. Alors que de nombreuses équipes sont approfondies dans leur analyse post-mortem, d’autres peuvent bénéficier d’apports et de défis supplémentaires pour des améliorations préventives. Il est également important que les équipes se sentent responsables et habilitées à mettre en œuvre les améliorations au niveau du système qu’elles proposent.
Pour les organisations qui prennent la fiabilité au sérieux, les pannes les plus graves sont examinées et contestées par des ingénieurs expérimentés. La direction de l'ingénierie au niveau organisationnel doit également être présente pour donner l'autorité nécessaire pour effectuer les réparations, surtout si ces réparations prennent du temps et entravent d'autres travaux. Les systèmes robustes ne se créent pas du jour au lendemain : ils sont construits par itérations constantes. Comment pouvons-nous continuer à itérer ? Cela nécessite une culture d’amélioration continue et d’apprentissage des échecs au niveau organisationnel.
Analyses de pannes, planification des capacités et tests de boîte noire
Certaines activités de routine nécessitent un investissement important, mais sont essentielles au maintien du fonctionnement des grands systèmes distribués. Ce sont des concepts auxquels j’ai été exposé pour la première fois chez Uber : dans les entreprises précédentes, nous n’avions pas besoin de les utiliser car notre taille et notre infrastructure ne nous poussaient pas à le faire.
Un exercice de panne de centre de données était quelque chose que je trouvais ennuyeux jusqu'à ce que j'en observe quelques-uns en action. Ma pensée initiale était que concevoir des systèmes distribués robustes, c'est justement pouvoir rester résilients en cas d'effondrement d'un data center. Si cela fonctionne bien en théorie, pourquoi le tester si souvent ? La réponse est liée à l'échelle et à la nécessité de tester si le service peut gérer efficacement l'augmentation soudaine du trafic dans le nouveau centre de données.
Le scénario de défaillance le plus courant que j'observe est lorsqu'un basculement se produit et que le service du nouveau centre de données ne dispose pas de suffisamment de ressources pour gérer le trafic mondial. Supposons que ServiceA et ServiceB fonctionnent respectivement à partir de deux centres de données. Supposons que l'utilisation des ressources est de 60 %, avec des dizaines ou des centaines de machines virtuelles exécutées dans chaque centre de données, et définissez une alarme pour qu'elle se déclenche à 70 %. Faisons maintenant un basculement et redirigeons tout le trafic de DataCenterA vers DataCenterB. Sans provisionner une nouvelle machine, DataCenterB ne pouvait soudainement plus gérer la charge. Le provisionnement d’une nouvelle machine peut prendre suffisamment de temps pour que les demandes s’accumulent et commencent à être abandonnées. Ce blocage peut commencer à affecter d'autres services, provoquant des pannes en cascade d'autres systèmes qui ne font même pas partie de ce basculement.
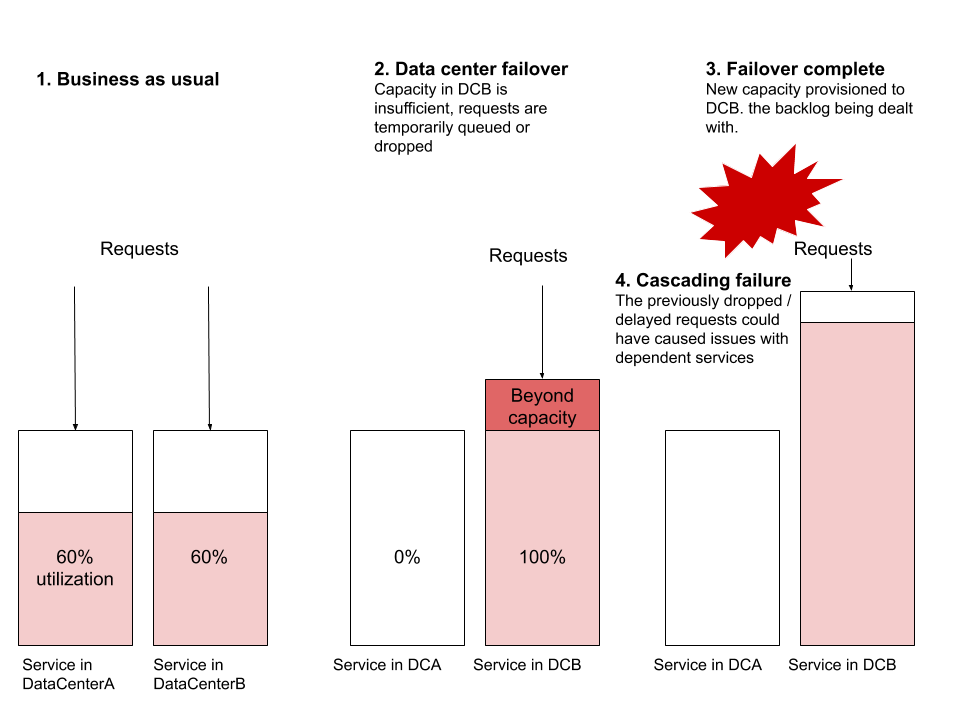
D'autres scénarios de défaillance courants incluent des problèmes de niveau de routage, des problèmes de capacité du réseau ou des problèmes de contre-pression. Le basculement du centre de données est un exercice que tout système distribué fiable devrait être capable d’effectuer sans aucun impact sur l’utilisateur. J'insiste sur "devrait" - cet exercice est l'un des exercices les plus utiles pour tester la fiabilité des systèmes distribués.
Note du traducteur : La réduction du trafic est à l'origine l'un des « trois axes » du plan. En cas de problème, pour s'assurer que le plan est disponible, des exercices sont indispensables. Faites attention, les amis.
Les exercices de planification des temps d'arrêt des services sont un excellent moyen de tester la résilience de l'ensemble de votre système. C'est également un excellent moyen de découvrir des dépendances cachées ou des utilisations inappropriées/involontaires d'un système spécifique. Bien que cet exercice soit relativement facile à réaliser pour les services orientés client avec peu de dépendances, il n'est pas aussi simple pour les systèmes critiques qui nécessitent une haute disponibilité ou sur lesquels s'appuient de nombreux autres systèmes. Mais que se passe-t-il lorsque ce système critique devient un jour indisponible ? Il est préférable de valider les réponses par le biais d'un exercice contrôlé où toutes les équipes sont conscientes et préparées aux perturbations inattendues.
Le test en boîte noire est une méthode permettant de mesurer l'exactitude d'un système aussi proche que possible des conditions vues par l'utilisateur final. Ce type de test est similaire aux tests de bout en bout, mais pour la plupart des produits, disposer de tests en boîte noire appropriés nécessite un investissement distinct. Les processus utilisateur clés et les scénarios de test orientés utilisateur les plus courants sont des exemples de bonne testabilité en boîte noire : configurés de manière à pouvoir être déclenchés à tout moment pour vérifier que le système fonctionne correctement.
En prenant Uber comme exemple, un test évident de la boîte noire consiste à vérifier si le processus passager-chauffeur fonctionne correctement au niveau de la ville. Autrement dit, un passager dans une ville spécifique peut-il demander un Uber, travailler avec le chauffeur et terminer le trajet ? Une fois cette situation automatisée, ce test pourra être exécuté régulièrement, en simulant différentes villes. Disposer d’un puissant système de test en boîte noire permet de vérifier plus facilement qu’un système, ou une partie d’un système, fonctionne correctement. C'est également très utile pour les exercices de basculement : le moyen le plus rapide d'obtenir des commentaires sur le basculement est d'exécuter des tests en boîte noire.
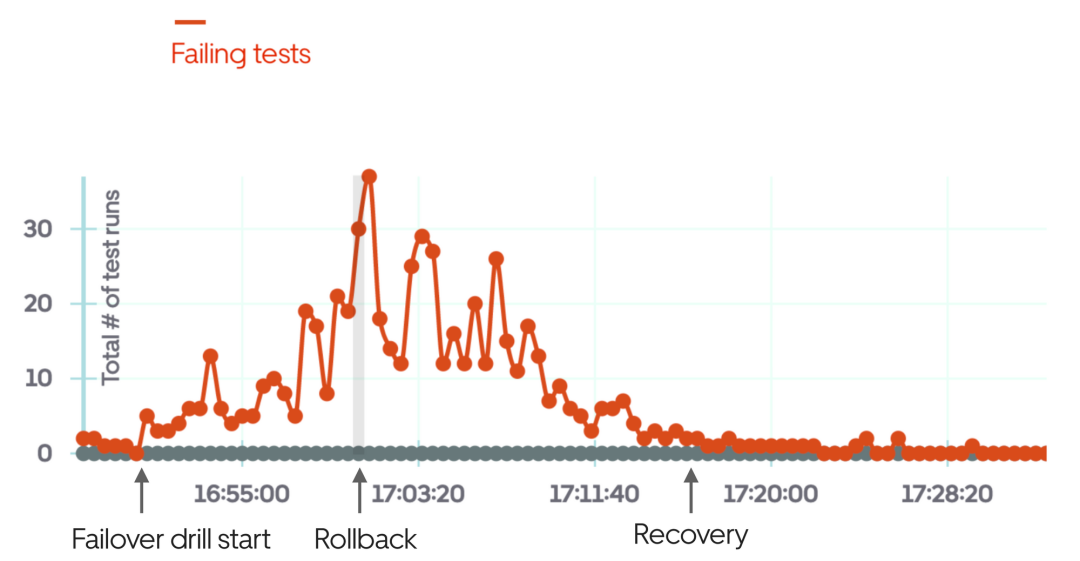
L'image ci-dessus est un exemple d'utilisation de tests de boîte noire lorsque l'exercice de basculement échoue et revient manuellement en arrière après quelques minutes d'exercice.
La planification de la capacité est tout aussi importante pour les grands systèmes distribués. En gros, je veux dire que les coûts de calcul et de stockage atteignent des dizaines, voire des centaines de milliers de dollars par mois. À cette échelle, l’utilisation d’un nombre fixe de déploiements peut s’avérer moins coûteuse que l’utilisation d’une solution cloud à mise à l’échelle automatique. Au minimum, les déploiements fixes doivent gérer le trafic « comme d'habitude » et évoluer automatiquement pendant les pics de charge. Mais combien d’instances minimales devez-vous exécuter au cours du mois prochain, des trois prochains mois et de l’année prochaine ?
Prédire les futurs modèles de trafic pour un système mature avec de bonnes données historiques n'est pas difficile. Ceci est important pour la budgétisation, le choix d’un fournisseur ou l’obtention d’une remise auprès d’un fournisseur de cloud. Si vos services sont coûteux et que vous ne pensez pas à la planification des capacités, vous passez à côté de moyens simples de réduire et de contrôler les coûts.
SLO, SLA et rapports associés
SLO signifie Service Level Objective - un objectif numérique pour la disponibilité du système. Il est recommandé de définir des SLO de niveau de service (tels que des objectifs de capacité, de latence, de précision et de disponibilité) pour chaque service individuel. Ces SLO peuvent ensuite servir de déclencheurs d’alertes. Un exemple de SLO de niveau de service pourrait ressembler à ceci :
SLO Metric |
Subcategory |
Value for Service |
Capacité |
Débit minimum |
500 req/sec |
Débit maximum attendu |
2 500 req/sec |
|
|
Latence |
Précision |
|
|
|
Disponibilité |
|
|
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Architecture et pratique du système distribué PHP
May 04, 2024 am 10:33 AM
Architecture et pratique du système distribué PHP
May 04, 2024 am 10:33 AM
L'architecture système distribuée PHP atteint l'évolutivité, les performances et la tolérance aux pannes en distribuant différents composants sur les machines connectées au réseau. L'architecture comprend des serveurs d'applications, des files d'attente de messages, des bases de données, des caches et des équilibreurs de charge. Les étapes de migration des applications PHP vers une architecture distribuée comprennent : Identifier les limites des services Sélectionner un système de file d'attente de messages Adopter un cadre de microservices Déploiement vers la gestion de conteneurs Découverte de services
 À quels pièges devons-nous prêter attention lors de la conception de systèmes distribués avec la technologie Golang ?
May 07, 2024 pm 12:39 PM
À quels pièges devons-nous prêter attention lors de la conception de systèmes distribués avec la technologie Golang ?
May 07, 2024 pm 12:39 PM
Pièges du langage Go lors de la conception de systèmes distribués Go est un langage populaire utilisé pour développer des systèmes distribués. Cependant, il existe certains pièges à prendre en compte lors de l'utilisation de Go qui peuvent nuire à la robustesse, aux performances et à l'exactitude de votre système. Cet article explorera quelques pièges courants et fournira des exemples pratiques sur la façon de les éviter. 1. Surutilisation de la concurrence Go est un langage de concurrence qui encourage les développeurs à utiliser des goroutines pour augmenter le parallélisme. Cependant, une utilisation excessive de la concurrence peut entraîner une instabilité du système, car trop de goroutines se disputent les ressources et entraînent une surcharge de changement de contexte. Cas pratique : une utilisation excessive de la concurrence entraîne des retards de réponse des services et une concurrence entre les ressources, qui se manifestent par une utilisation élevée du processeur et une surcharge importante de garbage collection.
 Conseils : Uber s'associe à Tesla pour promouvoir l'adoption des véhicules électriques, en offrant jusqu'à 2 000 $ de subventions aux conducteurs de Model 3/Y
Jan 17, 2024 am 09:42 AM
Conseils : Uber s'associe à Tesla pour promouvoir l'adoption des véhicules électriques, en offrant jusqu'à 2 000 $ de subventions aux conducteurs de Model 3/Y
Jan 17, 2024 am 09:42 AM
Selon des informations publiées sur ce site le 17 janvier, Uber a annoncé qu'elle coopère avec Tesla pour promouvoir l'adoption des véhicules électriques par davantage de conducteurs américains, dans le but d'atteindre l'objectif « zéro émission » des villes américaines et canadiennes d'ici 2030. Uber a annoncé qu'en plus du crédit d'impôt fédéral existant (jusqu'à 7 500 $), il offrirait aux conducteurs des incitations à l'achat de voiture allant jusqu'à 2 000 $ pour l'achat du modèle 3 et du modèle Y. Cette incitation à l'achat d'une voiture équivaut à environ 14 400 yuans. Les données montrent qu'à la fin de l'année dernière, Uber comptait au total 74 000 conducteurs actifs de véhicules électriques aux États-Unis, au Canada et en Europe. Andrew Macdonald, vice-président senior de la mobilité et des opérations commerciales d'Uber, a déclaré avoir appris grâce à la communication avec les chauffeurs Uber que le coût de possession du véhicule et la base de recharge
 Comment utiliser la mise en cache dans le système distribué Golang ?
Jun 01, 2024 pm 09:27 PM
Comment utiliser la mise en cache dans le système distribué Golang ?
Jun 01, 2024 pm 09:27 PM
Dans le système distribué Go, la mise en cache peut être implémentée à l'aide du package groupcache. Ce package fournit une interface de mise en cache générale et prend en charge plusieurs stratégies de mise en cache, telles que LRU, LFU, ARC et FIFO. L'exploitation du cache de groupe peut améliorer considérablement les performances des applications, réduire la charge du backend et améliorer la fiabilité du système. La méthode d'implémentation spécifique est la suivante : importez les packages nécessaires, définissez la taille du pool de cache, définissez le pool de cache, définissez le délai d'expiration du cache, définissez le nombre de demandes de valeur simultanées et traitez les résultats de la demande de valeur.
 Utilisez les fonctions Golang pour créer des architectures basées sur les messages dans les systèmes distribués
Apr 19, 2024 pm 01:33 PM
Utilisez les fonctions Golang pour créer des architectures basées sur les messages dans les systèmes distribués
Apr 19, 2024 pm 01:33 PM
La création d'une architecture basée sur les messages à l'aide des fonctions Golang comprend les étapes suivantes : création d'une source d'événements et génération d'événements. Sélectionnez une file d'attente de messages pour stocker et transférer les événements. Déployez une fonction Go en tant qu'abonné pour vous abonner et traiter les événements de la file d'attente des messages.
 Créez des systèmes distribués à l'aide du framework de microservices Golang
Jun 05, 2024 pm 06:36 PM
Créez des systèmes distribués à l'aide du framework de microservices Golang
Jun 05, 2024 pm 06:36 PM
Créez un système distribué à l'aide du framework de microservices Golang : installez Golang, sélectionnez un framework de microservices (tel que Gin), créez un microservice Gin, ajoutez des points de terminaison pour déployer le microservice, créez et exécutez l'application, créez un microservice de commande et d'inventaire, utilisez le point final pour traiter les commandes et l'inventaire Utiliser des systèmes de messagerie tels que Kafka pour connecter des microservices Utiliser la bibliothèque sarama pour produire et consommer des informations sur les commandes
 Solution Golang pour la mise en œuvre de systèmes distribués hautement disponibles
Jan 16, 2024 am 08:17 AM
Solution Golang pour la mise en œuvre de systèmes distribués hautement disponibles
Jan 16, 2024 am 08:17 AM
Golang est un langage de programmation efficace, concis et sûr qui peut aider les développeurs à mettre en œuvre des systèmes distribués hautement disponibles. Dans cet article, nous explorerons comment Golang implémente des systèmes distribués hautement disponibles et fournirons quelques exemples de code spécifiques. Défis des systèmes distribués Un système distribué est un système dans lequel plusieurs participants collaborent. Les participants à un système distribué peuvent être différents nœuds répartis sous plusieurs aspects tels que l'emplacement géographique, le réseau et la structure organisationnelle. Lors de la mise en œuvre d'un système distribué, de nombreux défis doivent être relevés, tels que :
 Quels sont les scénarios d'application courants de Golang dans le développement de logiciels ?
Dec 28, 2023 am 08:39 AM
Quels sont les scénarios d'application courants de Golang dans le développement de logiciels ?
Dec 28, 2023 am 08:39 AM
En tant que langage de développement, Golang présente les caractéristiques de simplicité, d'efficacité et de fortes performances de concurrence, il propose donc un large éventail de scénarios d'application dans le développement de logiciels. Certains scénarios d’application courants sont présentés ci-dessous. Programmation réseau Golang est excellent en programmation réseau et est particulièrement adapté à la création de serveurs à haute concurrence et hautes performances. Il fournit une riche bibliothèque réseau et les développeurs peuvent facilement programmer TCP, HTTP, WebSocket et d'autres protocoles. Le mécanisme Goroutine de Golang permet aux développeurs de programmer facilement
