
 Périphériques technologiques
IA
Démystifier certaines des techniques d'amélioration de la voix basées sur l'IA utilisées dans les appels en temps réel
Périphériques technologiques
IA
Démystifier certaines des techniques d'amélioration de la voix basées sur l'IA utilisées dans les appels en temps réel
Démystifier certaines des techniques d'amélioration de la voix basées sur l'IA utilisées dans les appels en temps réel


Introduction au contexte
Après que la communication audio et vidéo en temps réel RTC soit devenue une infrastructure indispensable dans la vie et le travail des gens, les différentes technologies impliquées évoluent également constamment pour traiter des problèmes multi-scènes complexes, tels que les scènes audio Comment pour offrir aux utilisateurs une expérience auditive claire et réelle dans des scénarios impliquant plusieurs appareils, plusieurs personnes et plusieurs bruits.
En tant que conférence internationale phare dans le domaine de la recherche sur le traitement du signal vocal, l'ICASSP (International Conference on Acoustics, Speech and Signal Processing) a toujours représenté l'orientation de recherche la plus avant-gardiste dans le domaine de l'acoustique. ICASSP 2023 a inclus un certain nombre d'articles liés aux algorithmes d'amélioration de la parole du signal audio, parmi lesquels Volcano Engine RTC L'équipe audio compte un total de 4 articles de recherche acceptés par la conférence. amélioration de la parole spécifique au locuteur, annulation de l'écho, amélioration de la voix multicanal, thèmes de réparation de la qualité sonore . Cet article présentera les principaux problèmes de scène et les solutions techniques résolues par ces quatre articles, et partagera la réflexion et la pratique de l'équipe audio Volcano Engine RTC dans les domaines de la réduction du bruit vocal, de l'annulation de l'écho et de l'élimination des interférences de la voix humaine.
"Amélioration spécifique au haut-parleur basée sur le réseau neuronal récurrent de segmentation de bande"
Adresse papier :
https://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
Spécifique au haut-parleur en temps réel voix De nombreuses questions doivent être résolues dans le cadre de la mission de renforcement. Premièrement, la collecte de la bande passante complète du son augmente la difficulté de traitement du modèle. Deuxièmement, par rapport aux scénarios non temps réel, il est plus difficile pour les modèles de scénarios en temps réel de localiser le locuteur cible. Comment améliorer l'interaction des informations entre le vecteur d'intégration du locuteur et le modèle d'amélioration de la parole est une difficulté réelle. traitement du temps. Inspiré par l'attention auditive humaine, Volcano Engine propose un module d'écoute du locuteur (SAM) qui introduit les informations du locuteur et les combine avec une fusion de réseau neuronal récurrent de segmentation de bande de modèle d'amélioration de la parole monocanal (Band-Split Recurrent Neural Network, BSRNN), construire un système spécifique d'amélioration de la parole humaine comme module de post-traitement du modèle d'annulation d'écho et optimiser la cascade des deux modèles.
Structure du cadre du modèle
Réseau neuronal récurrent à division de bande (BSRNN)

Le RNN à division de bande (BSRNN) est un modèle SOTA pour l'amélioration de la parole en bande complète et la séparation musicale. Sa structure est comme indiqué sur la figure. ci-dessus Afficher. BSRNN se compose de trois modules, à savoir le module Band-Split, le module Band and Sequence Modeling et le module Band-Merge. Le module de segmentation de bandes de fréquences divise d'abord le spectre en K bandes de fréquences. Une fois les caractéristiques de chaque bande de fréquences normalisées par lots (BN), elles sont compressées à la même dimension de caractéristiques C par K couches entièrement connectées (FC). Par la suite, les caractéristiques de toutes les bandes de fréquences sont concaténées dans un tenseur tridimensionnel et traitées ultérieurement par le module de modélisation de séquence de bandes de fréquences, qui utilise GRU pour modéliser alternativement les dimensions de bande de temps et de fréquence du tenseur de caractéristiques. Les caractéristiques traitées sont finalement transmises via le module de fusion de bandes de fréquences pour obtenir la fonction de masquage de spectre finale en sortie. La parole améliorée peut être obtenue en multipliant le masque de spectre et le spectre d'entrée. Afin de construire un modèle d'amélioration de la parole spécifique au locuteur, nous ajoutons un module d'attention du locuteur après le module de modélisation de chaque séquence de bandes de fréquences.
Module d'écoute du haut-parleur (SAM)

La structure du module d'écoute du haut-parleur est celle indiquée dans la figure ci-dessus. L'idée principale est d'utiliser le vecteur d'intégration du locuteur e comme attracteur de la caractéristique intermédiaire du modèle d'amélioration de la parole, et de calculer la corrélation s entre celui-ci et la caractéristique intermédiaire à tout moment et dans toutes les bandes de fréquences, appelée le valeur d'attention. Cette valeur d'attention sera utilisée pour mettre à l'échelle et régulariser les fonctionnalités intermédiaires h. La formule spécifique est la suivante :
Transformez d'abord e et h en k et q par connexion complète et convolution :
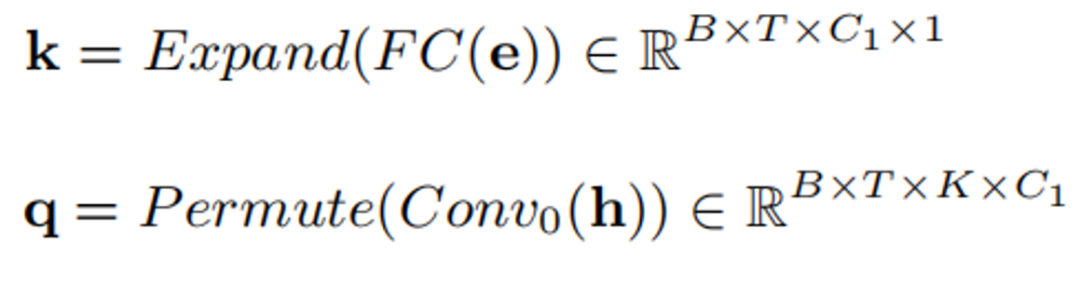
k et q sont multipliés pour obtenir la valeur d'attention :
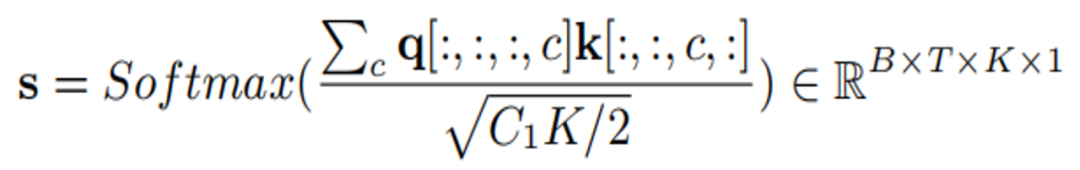
Enfin, la valeur d'attention est passé à l'échelle des fonctionnalités originales :
Données de formation du modèle
Concernant les données de formation du modèle, nous avons utilisé les données de la 5ème piste d'amélioration de la parole du locuteur spécifique au locuteur DNS et les données vocales de haute qualité de DiDispeech. Grâce au nettoyage des données, nous avons obtenu des données vocales claires d'environ 3 500 locuteurs. . En termes de nettoyage des données, nous avons utilisé le modèle pré-entraîné basé sur la reconnaissance du locuteur ECAPA-TDNN [1] pour supprimer la parole résiduelle du locuteur interférent dans les données vocales, et avons également utilisé le modèle pré-entraîné qui a remporté la première place dans l'étude. 4ème défi DNS pour supprimer le bruit résiduel des données vocales. Au cours de la phase de formation, nous avons généré plus de 100 000 données vocales 4s, ajouté de la réverbération à ces audios pour simuler différents canaux et les avons mélangés de manière aléatoire avec du bruit et des interférences vocales, les définissant en un type de bruit, deux types de bruit, bruit et interférence. parole Il existe 4 scénarios d'interférence : des locuteurs humains et uniquement des locuteurs interférents. Dans le même temps, les niveaux de parole bruitée et de parole cible sont mis à l'échelle de manière aléatoire pour simuler des entrées de différentes tailles.
"Solution technique pour la fusion de l'extraction de haut-parleurs spécifiques et de l'annulation de l'écho"
Adresse papier
https://www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
L'annulation du son de réponse est toujours fait en externe Une question extrêmement complexe et cruciale dans le scénario. Afin d'extraire des signaux vocaux clairs de haute qualité, Volcano Engine propose un système léger d'annulation d'écho qui combine le traitement du signal et la technologie d'apprentissage en profondeur. Sur la base de la suppression personnalisée du bruit profond (pDNS), nous avons en outre construit un système d'annulation personnalisée de l'écho acoustique (pAEC), qui comprend un module de prétraitement basé sur le traitement du signal numérique, un modèle en deux étapes de réseau neuronal profond et un haut-parleur. module d'extraction de parole spécifique basé sur BSRNN et SAM.

Cadre général de l'annulation d'écho spécifique au locuteur
Module de pré-traitement basé sur l'annulation d'écho linéaire par traitement numérique du signal
Le module de pré-traitement se compose principalement de deux parties : la compensation de retard (TDC) et annulation d'écho linéaire (LAEC), ce module est réalisé sur des fonctionnalités de sous-bande.

Basé sur un cadre d'algorithme d'annulation d'écho linéaire de sous-bande de traitement du signal
Compensation de retard
TDC est basé sur la corrélation croisée de sous-bande, qui estime d'abord un retard dans chaque sous-bande séparément, puis utilise la méthode de vote pour déterminer le délai final.
Annulation de l'écho linéaire
LAEC est une méthode de filtrage adaptatif de sous-bande basée sur NLMS. Elle se compose de deux filtres : un pré-filtre (Pré-filtre) et un post-filtre (Post-filtre). mettre à jour les paramètres de manière adaptative, et le pré-filtre est la sauvegarde du post-filtre stable. Sur la base de la comparaison de l'énergie résiduelle produite par le pré-filtre et le post-filtre, quel signal d'erreur est finalement décidé à utiliser.

Organigramme de traitement LAEC
Modèle à deux étages basé sur un réseau neuronal convolutionnel-cyclique (CRN) à plusieurs étages
Nous recommandons de découpler la tâche pAEC et de la diviser en "suppression d'écho" " et des tâches « d'extraction de locuteurs spécifiques » pour réduire la pression de modélisation du modèle. Par conséquent, le réseau de post-traitement se compose principalement de deux modules de réseau neuronal : un module léger basé sur CRN pour l'annulation préliminaire de l'écho et la suppression du bruit, et un module de post-traitement basé sur pDNS pour une meilleure reconstruction du signal vocal proche.
Phase 1 : module léger basé sur CRN
Le module léger basé sur CRN se compose d'un module de compression de bande, d'un encodeur, de deux GRU à double chemin, d'un décodeur et d'un module de décomposition de bande. Dans le même temps, nous avons également introduit un module de détection d'activité vocale (VAD) pour l'apprentissage multitâche, qui contribue à améliorer la perception de la parole proche. CRN prend l'amplitude de compression en entrée et génère un masque de rapport idéal complexe préliminaire (cIRM) et une probabilité VAD en champ proche du signal cible.
Deuxième étape : module de post-traitement basé sur pDNS
Le module pDNS à ce stade comprend le réseau neuronal récurrent de segmentation de bande BSRNN et le module de mécanisme d'attention du locuteur SAM introduit ci-dessus. Le module cascade est connecté en série au niveau léger CRN. module. Étant donné que notre système pDNS a atteint des performances relativement excellentes dans la tâche d'amélioration de la parole caractéristique du locuteur, nous utilisons un paramètre de modèle pDNS pré-entraîné comme paramètre d'initialisation de la deuxième étape du modèle pour traiter davantage la sortie de l'étape précédente.
Fonction de perte d'optimisation de la formation du système en cascade
Nous améliorons le modèle en deux étapes grâce à l'optimisation en cascade afin qu'il puisse prédire la parole proche dans la première étape et prédire la parole proche d'un locuteur spécifique dans la deuxième étape. Nous incluons également une pénalité de détection d'activité vocale pour la proximité du locuteur afin d'améliorer la capacité du modèle à reconnaître la parole à courte distance. La fonction de perte spécifique est définie comme suit :

où,
correspond respectivement aux caractéristiques STFT prédites dans la première et la deuxième étapes du modèle, représente respectivement les caractéristiques STFT de la parole proche et spécifiques à l'extrémité proche discours du locuteur,
représente respectivement les prédictions du modèle et les états VAD cibles.
Modèle de données d'entraînement
Afin de permettre au système d'annulation d'écho de gérer l'écho de scènes de collecte multi-appareils, multi-réverbérations et multi-bruit, nous avons obtenu plus de 2000 heures de données d'entraînement en mélangeant écho et parole claire. Parmi eux, les données d'écho utilisent les données vocales uniques à distance de l'AEC Challenge 2023, la parole propre provient de DNS Challenge 2023 et de LibriSpeech, et l'ensemble RIR utilisé pour simuler la réverbération proche provient de DNS Challenge. Étant donné que l'écho dans les données de conversation unique à l'extrémité distante de l'AEC Challenge 2023 contient une petite quantité de données de bruit, l'utilisation directe de ces données comme écho peut facilement conduire à une distorsion de la parole à l'extrémité proche. Afin d'atténuer ce problème, nous avons adopté une solution simple. mais une stratégie de nettoyage des données efficace, utilisant le prétraitement. Un modèle AEC formé traite les données monocanal distantes, identifie les données avec une énergie résiduelle plus élevée comme données de bruit et itère à plusieurs reprises le processus de nettoyage illustré ci-dessous.
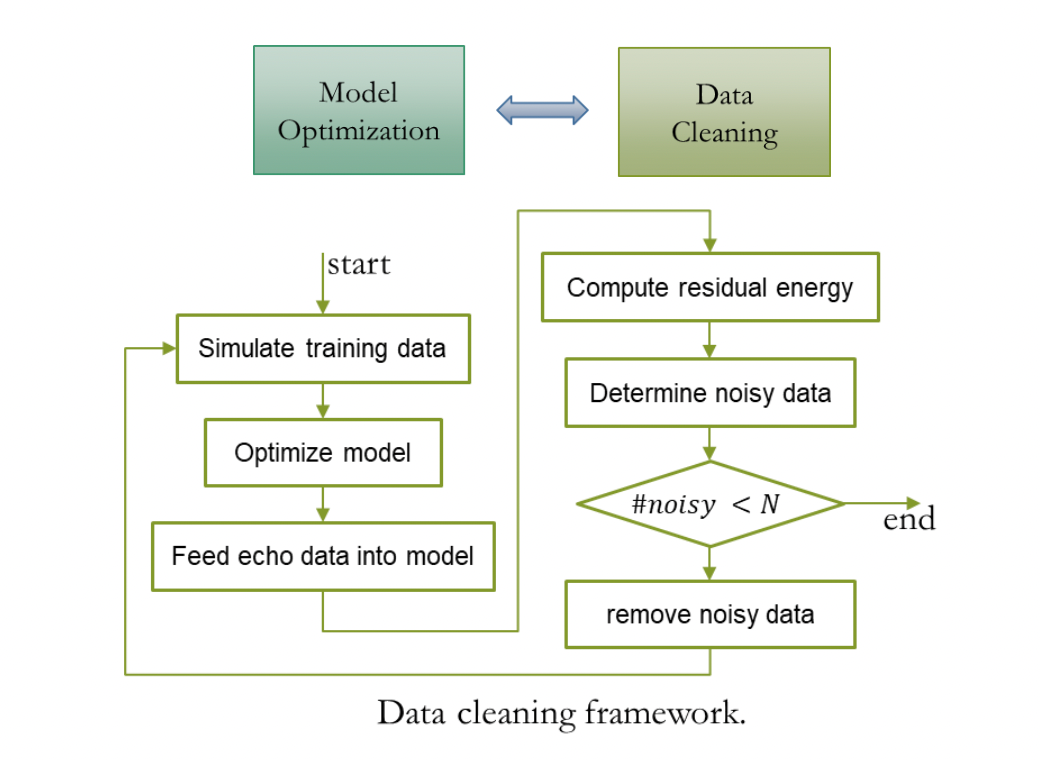
Effet du système de schéma d'optimisation en cascade
Un tel système d'amélioration de la parole basé sur l'annulation de l'écho fusionné et l'extraction de locuteurs spécifiques a été vérifié sur l'ensemble de tests aveugles ICASSP 2023 AEC Challenge [2] sur des indicateurs subjectifs et objectifs. Avantages - obtenu un score subjectif score d'opinion de 4,44 (Subjective-MOS) et un taux de précision de la reconnaissance vocale de 82,2 % (WAcc).

"Amélioration de la parole multicanal basée sur le mécanisme d'attention par convolution de Fourier"
Adresse papier :
https://www.php.cn/link/373cb8cd58 f1309b31c56e2d5a83
L'estimation du poids des faisceaux basée sur l'apprentissage profond est actuellement l'une des méthodes courantes pour résoudre les tâches d'amélioration de la parole multicanal, c'est-à-dire filtrer les signaux multicanaux en résolvant les poids des faisceaux via le réseau pour obtenir une parole pure. Dans l'estimation des poids des faisceaux, le rôle des informations spectrales et des informations spatiales est similaire au principe de résolution de la matrice de covariance spatiale dans l'algorithme traditionnel de formation de faisceaux. Cependant, de nombreux formateurs de faisceaux neuronaux existants ne sont pas en mesure d'estimer de manière optimale le poids des faisceaux. Pour relever ce défi, Volcano Engine propose un codeur d'attention convolutif de Fourier (FCAE), qui peut fournir un champ récepteur global sur l'axe des caractéristiques de fréquence et améliorer les caractéristiques contextuelles de l'axe de fréquence d'extraction. Dans le même temps, nous avons également proposé une structure de codeur-décodeur convolutif récurrent (CRED) basée sur FCAE pour capturer les caractéristiques contextuelles spectrales et les informations spatiales à partir des caractéristiques d'entrée.
Structure du cadre du modèle
Réseau d'estimation du poids des poutres

Ce réseau utilise le paradigme structurel du réseau d'intégration et de formation de faisceaux (EaBNet) pour diviser le réseau en deux parties : le module d'intégration et le module de poutre. est utilisé pour extraire le vecteur d'intégration qui regroupe les informations spectrales et spatiales, et envoie le vecteur d'intégration à la partie faisceau pour en dériver le poids du faisceau. Ici, une structure CRED est utilisée pour apprendre le tenseur d'intégration. Une fois le signal d'entrée multicanal transformé par STFT, il est envoyé à une structure CRED pour extraire le tenseur d'intégration. Le tenseur d'intégration est similaire à la matrice de covariance spatiale traditionnelle. formation de faisceaux et contient des paroles et des caractéristiques distinctes du bruit. Le tenseur d'intégration passe à travers la structure LayerNorm2d, puis à travers deux réseaux LSTM empilés, et enfin les poids des faisceaux sont dérivés à travers une couche linéaire. Nous appliquons le poids du faisceau aux caractéristiques du spectre d'entrée multicanal, effectuons des opérations de filtrage et de sommation, et obtenons enfin le spectre de parole pur. Après la transformation ISTFT, la forme d'onde cible dans le domaine temporel peut être obtenue.
Structure CRED
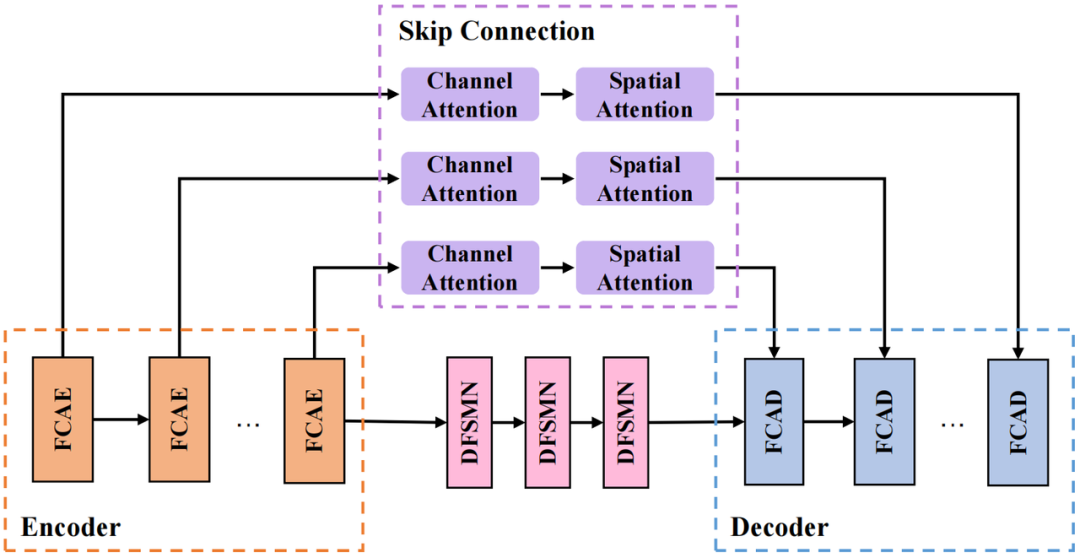
La structure CRED que nous adoptons est présentée dans l'image ci-dessus. Parmi eux, FCAE est l'encodeur d'attention convolutionnelle de Fourier et FCAD est le décodeur symétrique avec FCAE ; le module de boucle utilise le réseau de mémoire séquentielle Deep Feedward (DFSMN) pour modéliser la dépendance temporelle de la séquence. Réduire la taille du modèle sans affecter le modèle. performances ; la partie de connexion de saut utilise des modules d'attention de canal série (Channel Attention) et d'attention spatiale (Spatial Attention) pour extraire davantage les informations spatiales inter-canaux et connecter les couches profondes et les fonctionnalités superficielles facilitent la transmission des informations dans le réseau.
Structure FCAE
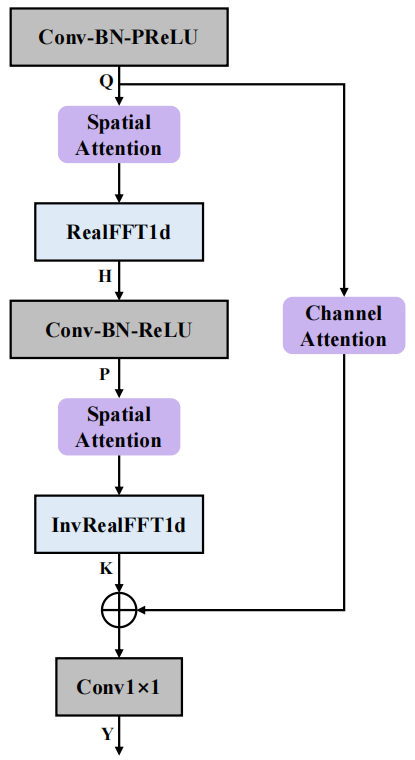
La structure du codeur d'attention convolutionnel de Fourier (FCAE) est illustrée dans la figure ci-dessus. Inspiré de l'opérateur de convolution de Fourier [3], ce module profite du fait que la mise à jour de la transformée de Fourier discrète en tout point du domaine de transformation aura un impact global sur le signal dans le domaine d'origine, et effectue une sur- analyse de fréquence des caractéristiques de l'axe des fréquences. Grâce à la transformation FFT dimensionnelle, le champ récepteur global peut être obtenu sur l'axe des fréquences, améliorant ainsi l'extraction des caractéristiques de contexte sur l'axe des fréquences. En outre, nous avons introduit un module d'attention spatiale et un module d'attention de canal pour améliorer encore la capacité d'expression convolutionnelle, extraire des informations conjointes spectrales et spatiales bénéfiques et améliorer l'apprentissage par le réseau des caractéristiques distinctives de la parole pure et du bruit. En termes de performances finales, le réseau a obtenu une excellente amélioration de la parole multicanal avec seulement 0,74 million de paramètres.
Modèle de données de formation
En termes d'ensemble de données, nous avons utilisé l'ensemble de données open source fourni par le concours ConferencingSpeech 2021. Les données vocales pures comprennent AISHELL-1, AISHELL-3, VCTK et LibriSpeech (train-clean-360). , et sélectionné les données signal-bruit parmi elles. Les données avec un rapport supérieur à 15 dB sont utilisées pour générer une parole mixte multicanal, et l'ensemble de données de bruit utilise MUSAN et AudioSet. Dans le même temps, afin de simuler de véritables scénarios de réverbération dans plusieurs pièces, les données open source ont été combinées avec plus de 5 000 réponses impulsionnelles de pièce en simulant les changements de taille de la pièce, de temps de réverbération, de sources sonores, d'emplacements de sources de bruit, etc., et a finalement généré plus de 60 000 échantillons de formation multicanaux.
"Système de restauration de la qualité sonore basé sur un modèle de réseau neuronal en deux étapes"
Adresse papier :
https://www.php.cn/link/e614f646836aaed9f89ce58e837e2310
Volcan Le moteur est la qualité sonore est toujours en cours de réparation Plusieurs tentatives ont été faites pour améliorer la parole de certains locuteurs, éliminer les échos et améliorer l'audio multicanal. Au cours du processus de communication en temps réel, différentes formes de distorsion affecteront la qualité du signal vocal, entraînant une diminution de la clarté et de l'intelligibilité du signal vocal. Volcano Engine propose un modèle en deux étapes qui utilise une stratégie de division pour régner par étapes pour réparer diverses distorsions qui affectent la qualité de la parole.
Structure du cadre du modèle
L'image ci-dessous montre la composition globale du cadre du modèle à deux étages. Parmi eux, le modèle du premier étage répare principalement les parties manquantes du spectre, et le modèle du deuxième étage supprime principalement le bruit et la réverbération. , et les artefacts qui peuvent être générés par le modèle de première étape.

Modèle de première étape : Réparation du réseau
Le modèle global adopte l'architecture du réseau récurrent à convolution complexe profond (DCCRN) [4], comprenant trois parties : encodeur, module de modélisation temporelle et décodeur. Inspirés par la réparation d'images, nous introduisons la convolution à valeurs complexes Gate et la convolution transposée à valeurs complexes Gate pour remplacer la convolution à valeurs complexes et la convolution transposée à valeurs complexes dans Encoder et Decoder. Afin d'améliorer encore le naturel de la partie réparation audio, nous avons introduit le discriminateur multi-périodes et le discriminateur multi-échelles pour la formation auxiliaire.
Modèle de deuxième étape : Denoising Net
L'architecture globale S-DCCRN est adoptée, y compris l'encodeur, deux sous-modules DCCRN légers et le décodeur. Les deux sous-modules DCCRN légers effectuent un traitement en sous-bande et à grande échelle. respectivement. Avec modélisation. Afin d'améliorer la capacité du modèle en matière de modélisation dans le domaine temporel, nous avons remplacé le LSTM dans le sous-module DCCRN par le module convolutionnel temporel compressé (STCM).
Données d'entraînement du modèle
L'audio clair, le bruit et la réverbération utilisés pour l'entraînement à la restauration de la qualité sonore proviennent tous de l'ensemble de données du concours DNS 2023, dans lequel la durée totale de l'audio propre est de 750 heures et la durée totale du bruit est de 170 heures. Lors de l'augmentation des données du modèle de première étape, nous avons utilisé l'audio pleine bande pour convoluer avec des filtres générés aléatoirement, avec une durée de fenêtre de 20 ms pour définir aléatoirement les points d'échantillonnage audio à zéro et sous-échantillonner aléatoirement l'audio pour simuler la perte de spectre. D'autre part, la fréquence d'amplitude audio et les points de collecte audio sont respectivement multipliés par des échelles aléatoires ; dans la deuxième étape d'augmentation des données, nous utilisons les données déjà générées dans la première étape pour convoluer divers types d'impulsions de pièce. La réponse est d'obtenir des données audio. avec différents niveaux de réverbération.
Effet de traitement audio
Dans le défi ICASSP 2023 AEC, l'équipe audio Volcano Engine RTC a remporté le championnat dans deux titres : Annulation universelle de l'écho (AEC non personnalisé) et annulation spécifique de l'écho du haut-parleur (AEC personnalisé), et a remporté le Suppression de l'écho en double conversation, protection de la voix en conversation proche, suppression du bruit de fond en conversation unique, notation complète de la qualité audio subjective et précision de la reconnaissance vocale finale
sont nettement meilleurs que les autres équipes participantes et ont atteint le niveau international. niveau leader. Jetons un coup d'œil aux effets de traitement d'amélioration de la voix de Volcano Engine RTC dans différents scénarios après les solutions techniques ci-dessus. Annulation d'écho dans différents scénarios de rapport signal/bruit-échoLes deux exemples suivants montrent les effets comparatifs de l'algorithme d'annulation d'écho avant et après traitement dans différents scénarios de rapport signal/énergie écho.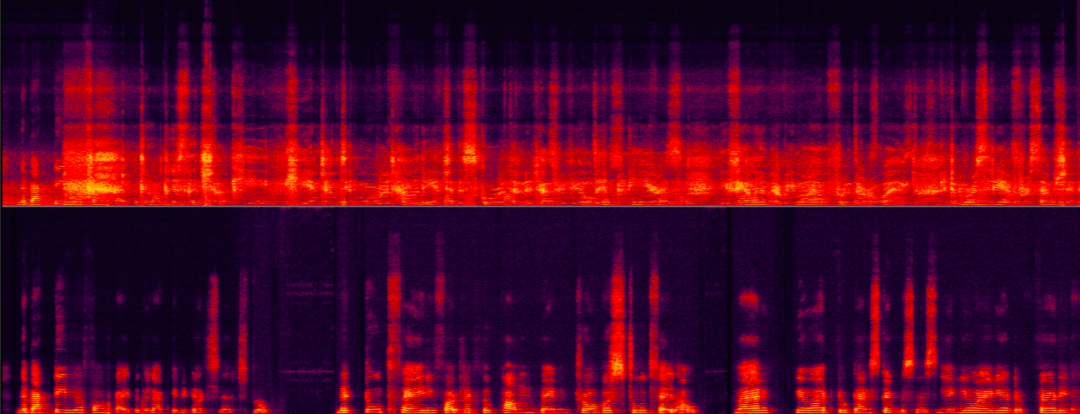
Les scènes à rapport signal/écho moyen
Les scènes à rapport signal/écho ultra faible sont les plus difficiles pour l'annulation de l'écho. élimine efficacement les échos à haute énergie, mais maximise également simultanément la préservation de la parole cible faible. La voix (écho) du locuteur non ciblé éclipse presque complètement la voix (féminine) du locuteur cible, ce qui la rend difficile à identifier.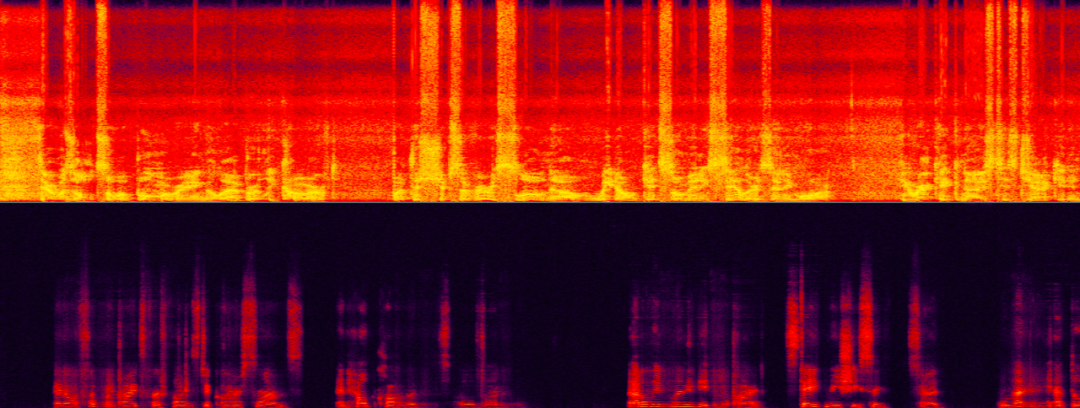
Scène à rapport signal/écho ultra faible
Extraction du haut-parleur dans des scénarios où différents arrière-plans interfèrent avec le haut-parleurLes deux exemples suivants démontrent respectivement les performances d'une extraction de haut-parleur spécifique algorithmes dans le bruit et le fond Effets comparatifs avant et après traitement dans des scènes d'interférence humaine. Dans l'exemple suivant, le haut-parleur spécifique présente à la fois des interférences sonores de type sonnette et des interférences de bruit de fond. L'utilisation seule de la réduction du bruit par l'IA ne peut supprimer que le bruit de la sonnette, la voix du haut-parleur spécifique doit donc être éliminée.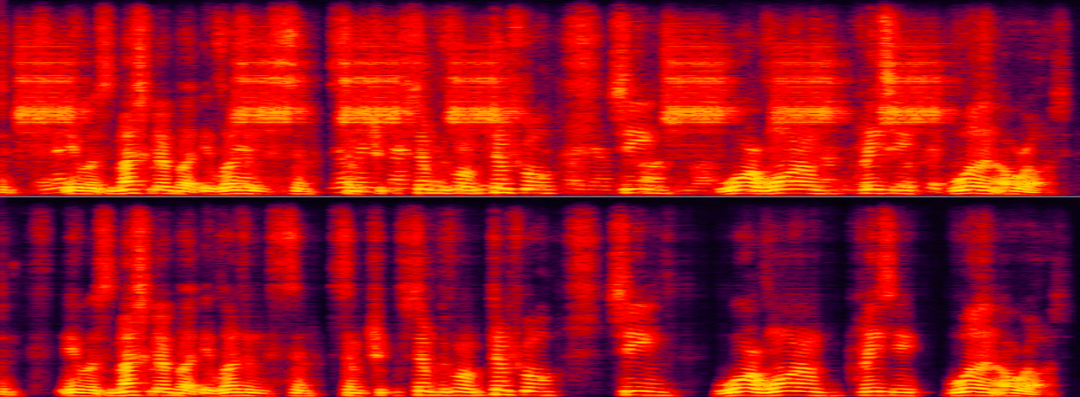
Lorsque les caractéristiques de l'empreinte vocale du locuteur cible et la voix d'interférence de fond sont très proches, le locuteur spécifique est extrait. Le défi de l'algorithme est plus grande et peut tester la robustesse de l'algorithme d'extraction de locuteur spécifique. Dans l’exemple suivant, le locuteur cible et la voix interférente de fond sont deux voix féminines similaires.
Mélange de voix féminine cible et de voix féminine d'interférence

Résumé et perspectives
Ce qui précède présente l'équipe audio Volcano Engine RTC basée sur l'apprentissage en profondeur dans la réduction du bruit spécifique au locuteur, l'écho annulation et parole multicanal Bien que certaines solutions et effets aient été apportés dans le sens de l'amélioration, les scénarios futurs sont encore confrontés à des défis dans de nombreuses directions, comme comment adapter la réduction du bruit vocal aux scènes de bruit, comment effectuer une réparation multi-type de signaux audio dans une gamme plus large de réparations de qualité sonore, et comment effectuer différents types de réparations sur les signaux audio dans une gamme plus large. Exécutant des modèles légers et de faible complexité sur des terminaux similaires, ces défis seront également au centre de nos orientations de recherche ultérieures.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
