
 Périphériques technologiques
IA
5 millions de monstres symboliques, lisez l'intégralité de 'Harry Potter' d'un seul coup ! Plus de 1000 fois plus long que ChatGPT
Périphériques technologiques
IA
5 millions de monstres symboliques, lisez l'intégralité de 'Harry Potter' d'un seul coup ! Plus de 1000 fois plus long que ChatGPT
5 millions de monstres symboliques, lisez l'intégralité de 'Harry Potter' d'un seul coup ! Plus de 1000 fois plus long que ChatGPT

Une mauvaise mémoire est le principal problème des modèles linguistiques à grande échelle actuels. Par exemple, ChatGPT ne peut saisir que 4 096 jetons (environ 3 000 mots). J'oublie souvent ce que j'ai dit auparavant en discutant, et ce n'est même pas suffisant. lire une courte histoire de.
La fenêtre de saisie courte limite également les scénarios d'application du modèle linguistique. Par exemple, lors de la synthèse d'un article scientifique (environ 10 000 mots), vous devez segmenter manuellement l'article puis le saisir dans le modèle en différents chapitres. Les informations associées sont perdues.
Bien que GPT-4 puisse prendre en charge jusqu'à 32 000 jetons et que Claude mis à niveau puisse prendre en charge jusqu'à 100 000 jetons, ils ne peuvent que atténuer le problème de la capacité cérébrale insuffisante.
Récemment, une équipe entrepreneuriale Magic a annoncé qu'elle lancerait bientôt le Modèle LTM-1, qui prend en charge jusqu'à 5 millions de jetons, soit environ 500 000 lignes de code ou 5 000 fichiers, soit 50 fois plus élevé que Claude. C'est fondamentalement ok. Couvre la plupart des besoins de stockage, cela fait vraiment une différence en quantité et en qualité !
Le principal scénario d'application de LTM-1 est la complétion de code, par exemple, il peut générer des suggestions de code plus longues et plus complexes.
Vous pouvez également réutiliser et synthétiser des informations dans plusieurs fichiers.
La mauvaise nouvelle est que Magic, le développeur de LTM-1, n'a pas publié les principes techniques spécifiques, mais a seulement déclaré avoir conçu une toute nouvelle méthode, le réseau de mémoire à long terme (LTM Net).
Mais il y a aussi une bonne nouvelle. En septembre 2021, des chercheurs de DeepMind et d'autres institutions ont proposé un modèle appelé ∞-former, qui inclut un mécanisme de mémoire à long terme (LTM). La théorie peut rendre le modèle Transformer infini. mémoire, mais il n'est pas clair s'il s'agit de la même technologie ou d'une version améliorée. LTM Nets peut voir plus de contexte que GPT, LTM Le nombre de LTM Nets peut voir plus de contexte que GPT, LTM Le nombre de Les paramètres du modèle -1 sont beaucoup plus petits que ceux du modèle sota actuel, donc le niveau d'intelligence est également inférieur. Cependant, continuer à augmenter la taille du modèle devrait améliorer les performances des LTM Nets.
Actuellement, LTM-1 a ouvert des applications de test alpha. LTM -1 développeur Magic a été fondé en 2022 et développe principalement des GitHub Copilot similaires Le produit peut aider les ingénieurs logiciels à écrire, réviser, déboguer et modifier le code. L'objectif est de créer un collègue IA pour les programmeurs. Son principal avantage concurrentiel est que le modèle peut lire du code plus long.

En février de cette année, Magic a reçu un financement de série A de 23 millions de dollars dirigé par CapitalG, une filiale d'Alphabet. Les investisseurs comprennent également l'ancien PDG de GitHub et coproducteur de Copilot, Nat Friedman, qui est actuellement le directeur de la société. président, le montant des fonds a atteint 28 millions de dollars américains.
Eric Steinberger, PDG et co-fondateur de Magic, est diplômé de l'Université de Cambridge avec un baccalauréat en informatique et a effectué des recherches sur l'apprentissage automatique au FAIR.

Avant de fonder Magic, Steinberger a également fondé ClimateScience pour aider les enfants du monde entier à découvrir les impacts du changement climatique. La conception du mécanisme d'attention dans le composant central du modèle de langage, Transformer, entraînera à chaque fois la longueur de la séquence d’entrée est augmentée, la complexité temporelle augmentera quadratiquement. Bien qu'il existe déjà quelques variantes du mécanisme d'attention, comme l'attention éparse, etc. pour réduire la complexité de l'algorithme, sa complexité est toujours liée à l'entrée longueur et ne peut pas être étendu à l’infini. ∞-former La clé du modèle de transformateur à mémoire à long terme (LTM) qui peut étendre la séquence d'entrée à l'infini est un cadre d'attention spatiale continue qui utilise des Cette manière de représenter la granularité augmente le nombre d’unités d’informations mémoire (fonctions de base). Dans le cadre, la séquence d'entrée est représentée comme un "signal continu", représente une combinaison linéaire de N fonctions de base radiales (RBF). De cette manière, la complexité d'attention de ∞-former est réduite à O(L^2 + L). × N), tandis que la complexité d'attention du transformateur d'origine est O (L×(L+L_LTM)), où L et L_LTM correspondent respectivement à la taille d'entrée du transformateur et à la longueur de la mémoire à long terme. Cette méthode de représentation présente deux avantages principaux : Infinite Memory Transformer
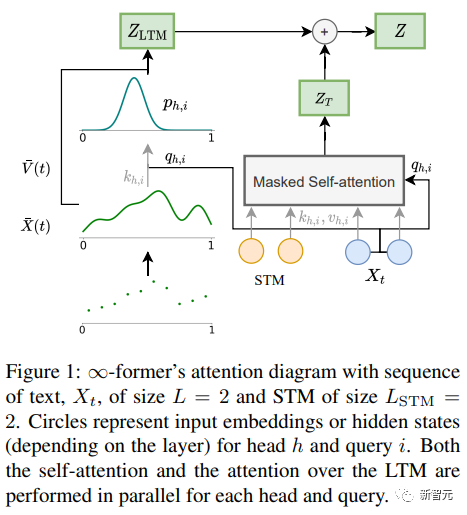
1. de jetons Il est représenté par la fonction de base N, qui réduit le coût de calcul de l'attention ; n'augmente pas la complexité du mécanisme d'attention.
Bien sûr, il n'y a pas de repas gratuit au monde, le prix est la réduction de la résolution : l'utilisation d'un plus petit nombre de fonctions de base entraîne une précision réduite lors de la représentation de la séquence d'entrée sous forme de signal continu.
Pour atténuer le problème de réduction de résolution, les chercheurs ont introduit le concept de « mémoires collantes » pour attribuer des espaces plus grands dans le signal LTM à des zones mémoire plus fréquentes. de « permanence » dans LTM, permettant au modèle de mieux capturer le contexte à long terme sans perdre les informations pertinentes. Il s'inspire également du potentiel à long terme et de la plasticité du cerveau.
 Partie expérimentale
Partie expérimentale
Afin de vérifier si ∞-ancien Pour modéliser des contextes longs, les chercheurs ont d'abord expérimenté une tâche de synthèse, qui consiste à trier les jetons par fréquence dans une longue séquence ; puis ils ont expérimenté la modélisation du langage et la génération de dialogues basés sur des documents en affinant les modèles de langage pré-entraînés.
Trier
Fr ter Comprend une séquence de jetons échantillonnés selon une distribution de probabilité (inconnue du système), dans le but de générer des jetons par ordre décroissant de fréquence dans la séquence 🎜#Pour étudier si la mémoire à long terme est efficace utilisés et si le Transformer trie simplement en modélisant les balises les plus récentes, les chercheurs ont conçu la distribution de probabilité des balises pour qu'elle change au fil du temps.
Il y a 20 jetons dans le vocabulaire. Des expériences ont été menées avec des séquences de longueurs de 4 000, 8 000 et 16 000 respectivement et un transformateur compressif a été utilisé comme modèle de base. pour comparaison.
Les résultats expérimentaux montrent que dans le cas d'une longueur de séquence courte (4 000), le Transformer-XL atteint une précision légèrement supérieure à celle des autres modèles, mais lorsque la longueur de la séquence augmente, sa précision diminue également rapidement. mais pour ∞-ancien, cette diminution n’est pas évidente, ce qui indique qu’elle présente plus d’avantages lors de la modélisation de longues séquences.
Modélisation du langage
#🎜 🎜 # Pour comprendre si la mémoire à long terme peut être utilisée pour mettre à l'échelle des modèles de langage pré-entraînés, les chercheurs ont affiné GPT-2 sur un sous-ensemble de Wikitext103 et PG-19, comprenant environ 200 millions de jetons.
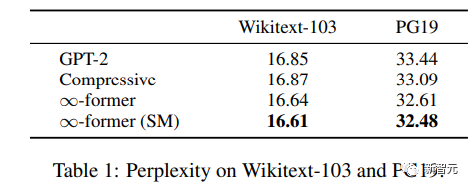
Les résultats expérimentaux montrent que ∞-former peut réduire Wikitext- 103 et PG19, et le premier ∞ permet d'obtenir de plus grandes améliorations sur l'ensemble de données PG19 car les livres s'appuient davantage sur la mémoire à long terme que les articles Wikipédia. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Conversation basée sur Doc # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #Dans la génération de dialogue basée sur des documents, en plus de l'historique du dialogue, le modèle peut également obtenir des documents sur le sujet de la conversation.
Dans l'ensemble de données CMU Document Grounded Conversation (CMU-DoG), la conversation porte sur le film, et un résumé du film est donné comme document à l'appui ; que la conversation contient plusieurs discours continus différents, les documents auxiliaires sont divisés en plusieurs parties. Pour évaluer l’utilité de la mémoire à long terme, les chercheurs n’ont donné accès au fichier au modèle qu’avant le début de la conversation, ce qui a rendu la tâche plus difficile. Après avoir affiné GPT-2 small, afin de permettre au modèle de garder l'intégralité du document en mémoire, un LTM continu avec N=512 fonctions de base (∞ - ancien) étend GPT-2.
Afin d'évaluer l'effet de modèle, les indicateurs de perplexité, de score F1, Rouge-1 et Rouge-L, et Meteor sont utilisés.
À partir des résultats, le ∞-former et le Transformer compressif peuvent générer plus de For bon corpus, même si la perplexité des deux est fondamentalement la même, ∞-former obtient de meilleurs scores sur d’autres indicateurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Une surveillance efficace des bases de données MySQL et MARIADB est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Prometheus Mysql Exportateur est un outil puissant qui fournit des informations détaillées sur les mesures de base de données qui sont essentielles pour la gestion et le dépannage proactifs.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Master la clause Order Order by dans SQL: Trier efficacement les données
Apr 08, 2025 pm 07:03 PM
Explication détaillée de la clause SqlorderBy: le tri efficace de la clause de données d'ordre de données est une déclaration clé de SQL utilisée pour trier les ensembles de résultats de requête. Il peut être organisé en ordre ascendant (ASC) ou ordre décroissant (DESC) dans des colonnes uniques ou plusieurs colonnes, améliorant considérablement la lisibilité des données et l'efficacité de l'analyse. OrderBy Syntax selectColumn1, Column2, ... FromTable_NameOrderByColumn_Name [ASC | DESC]; Column_name: Triez par colonne. ASC: Ascendance Order Sort (par défaut). DESC: Trier en ordre décroissant. ORDERBY Fonctionnalités principales: Tri multi-colonnes: prend en charge le tri de plusieurs colonnes et l'ordre des colonnes détermine la priorité du tri. depuis
