
 Périphériques technologiques
IA
Le modèle d'appel d'API le plus puissant est ici ! Basé sur le réglage fin de LLaMA, les performances dépassent GPT-4
Périphériques technologiques
IA
Le modèle d'appel d'API le plus puissant est ici ! Basé sur le réglage fin de LLaMA, les performances dépassent GPT-4
Le modèle d'appel d'API le plus puissant est ici ! Basé sur le réglage fin de LLaMA, les performances dépassent GPT-4

Après l'alpaga, il existe un autre modèle nommé d'après un animal, cette fois-ci il s'agit du gorille.
Bien que LLM soit actuellement à l'honneur, fasse de nombreux progrès et que ses performances dans diverses tâches soient également remarquables, ces modèles utilisent efficacement les outils via des appels API. Le potentiel doit encore être exploité.
Même pour les LLM les plus avancés d'aujourd'hui, tels que GPT-4, les appels d'API sont une tâche difficile, principalement en raison de leur incapacité à générer des paramètres d'entrée précis, et LLM est sujet aux hallucinations dues à une utilisation incorrecte des appels API.
Non, les chercheurs ont créé Gorilla, un modèle affiné basé sur LLaMA qui surpasse même GPT-4 dans l'écriture d'appels API.
Lorsqu'il est combiné à un outil de récupération de documents, Gorilla démontre également des performances puissantes, rendant les mises à jour utilisateur ou les changements de version plus flexibles.
De plus, Gorilla atténue également grandement le problème d'hallucination que LLM rencontre souvent.
Pour évaluer les capacités du modèle, les chercheurs ont également introduit un benchmark API, un ensemble de données complet composé des API HuggingFace, TorchHub et TensorHub#🎜 🎜#
GorillaIl n'est pas nécessaire de présenter les puissantes capacités des LLM, notamment les capacités de conversation naturelle, les capacités de raisonnement mathématique et les capacités de synthèse de programmes.
Cependant, malgré ses puissantes performances, LLM souffre encore de certaines limites. De plus, les LLM doivent également être recyclés pour mettre à jour leur base de connaissances et leurs capacités de raisonnement en temps opportun.
En autorisant les outils disponibles au LLM, les chercheurs peuvent permettre au LLM d'accéder à une base de connaissances vaste et en constante évolution pour effectuer des tâches informatiques complexes.
En fournissant un accès aux technologies de recherche et aux bases de données, les chercheurs peuvent améliorer la capacité du LLM à gérer des espaces de connaissances plus vastes et plus dynamiques.
De même, en proposant l'utilisation d'outils de calcul, LLM peut également effectuer des tâches de calcul complexes.
Par conséquent, les géants de la technologie ont commencé à essayer d'intégrer divers plug-ins pour permettre à LLM d'appeler des outils externes via des API.
Le passage d'un outil plus petit et codé manuellement à un outil capable d'appeler un vaste espace d'API cloud en constante évolution peut transformer LLM en une infrastructure informatique, et le principales interfaces nécessaires au réseau. Les tâches allant de la réservation de vacances entières à l'organisation d'une conférence peuvent devenir simples comme parler à un LLM avec accès aux API Web pour les vols, la location de voitures, les hôtels, les restaurants et les divertissements.
Cependant, de nombreux travaux antérieurs intégrant des outils dans LLM considèrent un petit ensemble d'API bien documentées qui peuvent être facilement injectées dans des invites. Prendre en charge une collection à l’échelle du Web de millions d’API changeantes nécessite de repenser la manière dont les chercheurs intègrent les outils.
Il n'est plus possible de décrire toutes les API dans un seul environnement. De nombreuses API auront des fonctionnalités qui se chevauchent, avec des limitations et contraintes subtiles. La simple évaluation du LLM dans ce nouvel environnement nécessite de nouveaux repères.
Dans cet article, les chercheurs explorent l'utilisation de l'auto-réglage et de la récupération structurels pour permettre à LLM d'extraire avec précision des données à partir de grandes quantités de données exprimées à l'aide de son API. et la documentation de l'API. Ensembles d'outils qui se chevauchent et changent pour la sélection.
Les chercheurs ont construit API Bench en récupérant les API (modèles) ML des centres de modèles publics, un vaste corpus d'API aux fonctionnalités complexes et qui se chevauchent souvent.
Les chercheurs ont choisi trois centres modèles principaux pour construire l'ensemble de données : TorchHub, TensorHub et HuggingFace.
Les chercheurs ont inclus de manière exhaustive chaque appel d'API dans TorchHub (94 appels d'API) et TensorHub (696 appels d'API).
Pour HuggingFace, en raison du grand nombre de modèles, les chercheurs ont sélectionné les 20 modèles les plus téléchargés dans chaque catégorie de tâches (925 au total).
Les chercheurs ont également utilisé l'auto-instruction pour générer des invites pour 10 questions des utilisateurs pour chaque API.
Par conséquent, chaque entrée de l'ensemble de données devient une paire d'API de référence d'instruction. Les chercheurs ont utilisé des techniques courantes de correspondance de sous-arbres AST pour évaluer l'exactitude fonctionnelle des API générées.
Les chercheurs analysent d'abord le code généré dans un arbre AST, puis trouvent un sous-arbre dont le nœud racine est l'appel API qui intéresse le chercheur, puis l'utilisent pour indexer Ensemble de données des chercheurs.
Les chercheurs vérifient l'exactitude fonctionnelle et les problèmes d'hallucinations des LLM et fournissent des commentaires sur la précision correspondante. Les chercheurs ont ensuite affiné Gorilla, un modèle basé sur LLaMA-7B, pour effectuer des opérations de récupération de documents en utilisant l'ensemble de données des chercheurs.
Les chercheurs ont découvert que Gorilla surpassait considérablement GPT-4 en termes de précision des fonctionnalités de l'API et de réduction des erreurs illusoires.
Les chercheurs montrent un exemple dans la figure 1.

De plus, la formation des chercheurs axée sur la récupération sur Gorilla a permis de model Capacité à s'adapter aux changements dans la documentation de l'API.
Enfin, les chercheurs ont également démontré la capacité du Gorille à comprendre et à raisonner sur les contraintes.
De plus, Gorilla a également bien performé en termes d'illusions.
La figure suivante est une comparaison de la précision et des hallucinations dans quatre cas, zéro échantillon (c'est-à-dire sans aucun récupérateur) et utilisant des récupérateurs de BM25, GPT et Oracle.
Parmi eux, BM25 et GPT sont des récupérateurs couramment utilisés, tandis que le récupérateur Oracle renverra les documents pertinents avec une pertinence de 100 %, indiquant une limite supérieure.
Celui qui a une plus grande précision et moins d'illusions dans l'image a un meilleur effet.
Sur l'ensemble de l'ensemble de données, Gorilla améliore la précision tout en réduisant les hallucinations. Pour collecter l'ensemble de données, les chercheurs ont méticuleusement enregistré les modèles en ligne The All de HuggingFace pour les modèles Model Hub, PyTorch Hub et TensorFlow Hub.
La plateforme HuggingFace héberge et dessert un total de 203 681 modèles. 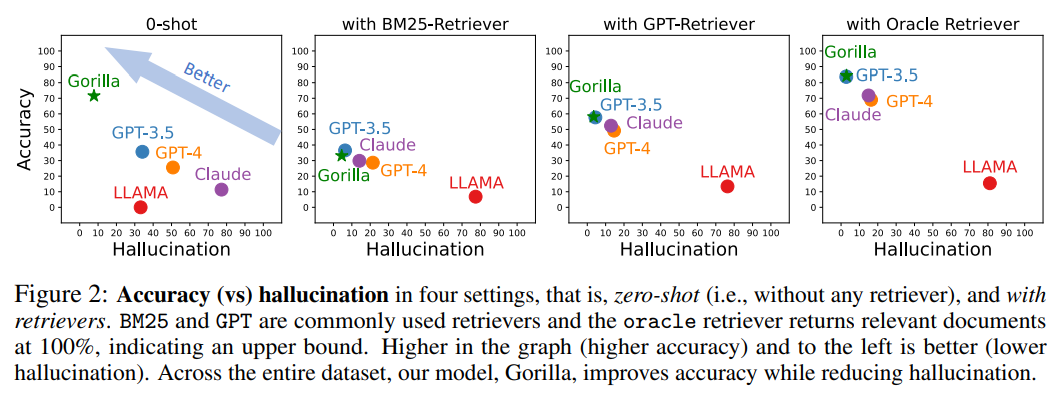
Cependant, la documentation de bon nombre de ces modèles est médiocre.
Pour filtrer ces modèles de mauvaise qualité, les chercheurs ont finalement sélectionné les 20 meilleurs modèles de chaque domaine.
Les chercheurs ont considéré 7 domaines de données multimodales, 8 domaines de CV, 12 domaines de PNL, 5 domaines d'audio et 2 domaines de données tabulaires et 2 domaines de apprentissage par renforcement.
Après filtrage, les chercheurs ont obtenu un total de 925 modèles de HuggingFace. Les versions de TensorFlow Hub sont divisées en v1 et v2.
La dernière version (v2) compte un total de 801 modèles, et les chercheurs ont traité tous les modèles. Après avoir filtré les modèles contenant peu d’informations, il restait 626 modèles.
Semblable à TensorFlow Hub, les chercheurs ont obtenu 95 modèles de Torch Hub.
Sous la direction du paradigme d'auto-instruction, les chercheurs ont adopté GPT-4 pour générer des données d'instruction synthétiques.
Les chercheurs ont fourni trois exemples en contexte, ainsi qu'un document API de référence, et ont chargé le modèle de générer des cas d'utilisation réels pour appeler l'API.
Les chercheurs ont spécifiquement demandé au modèle de ne pas utiliser de noms d'API ou d'indices lors de la création d'instructions. Les chercheurs ont construit six exemples (paires instruction-API) pour chacun des trois hubs modèles.
Ces 18 points sont les seules données générées ou modifiées manuellement.
Et Gorilla est un modèle LLaMA-7B prenant en charge la récupération, spécifiquement utilisé pour les appels API.
Comme le montre la figure 3, les chercheurs ont utilisé l'auto-construction pour générer des paires {instruction, API}.
Pour affiner LLaMA, les chercheurs l'ont converti en une conversation de type chat utilisateur-agent, où chaque point de données est une conversation et l'utilisateur et l'agent parlent à tour de rôle.
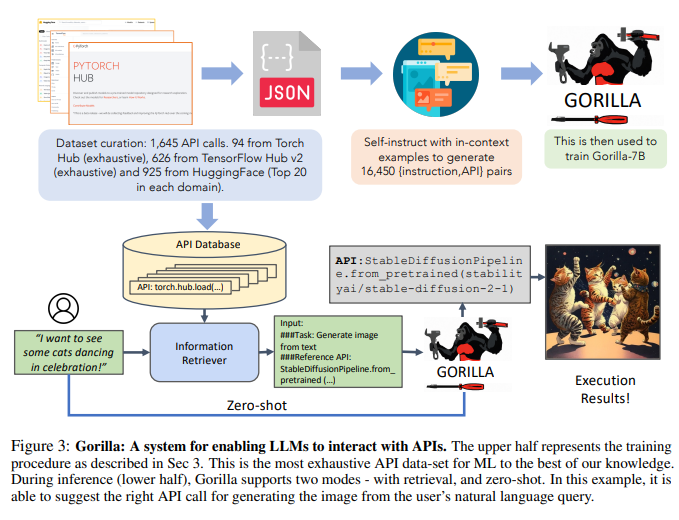
Ensuite, les chercheurs ont effectué un réglage fin des instructions standard sur le modèle de base LLaMA-7B. Lors d'expériences, les chercheurs ont entraîné des gorilles avec et sans retriever.
Dans l’étude, les chercheurs se sont concentrés sur des techniques conçues pour améliorer la capacité du LLM à identifier avec précision les API appropriées pour des tâches spécifiques – un aspect crucial, mais souvent négligé, du développement de la technologie.
Étant donné que l'API fonctionne comme un langage universel permettant une communication efficace entre différents systèmes, une utilisation appropriée de l'API peut améliorer la capacité de LLM à interagir avec une gamme plus large d'outils.
Gorilla a surpassé le LLM de pointe (GPT-4) sur trois ensembles de données à grande échelle collectés par les chercheurs. Gorilla produit des modèles ML fiables d'appels d'API sans hallucinations et satisfait aux contraintes lors de la sélection des API.
Cherchant à trouver un ensemble de données stimulant, les chercheurs ont choisi les API ML en raison de leurs fonctionnalités similaires. Un inconvénient potentiel des API axées sur le ML est que si elles sont formées sur des données biaisées, elles peuvent potentiellement produire des prédictions biaisées susceptibles de désavantager certains sous-groupes.
Pour apaiser cette inquiétude et promouvoir une compréhension plus approfondie de ces API, les chercheurs publient un ensemble de données plus complet comprenant plus de 11 000 paires instruction-API.
Dans l'exemple ci-dessous, les chercheurs utilisent la correspondance de sous-arbres Abstract Syntax Tree (AST) pour évaluer l'exactitude des appels d'API.
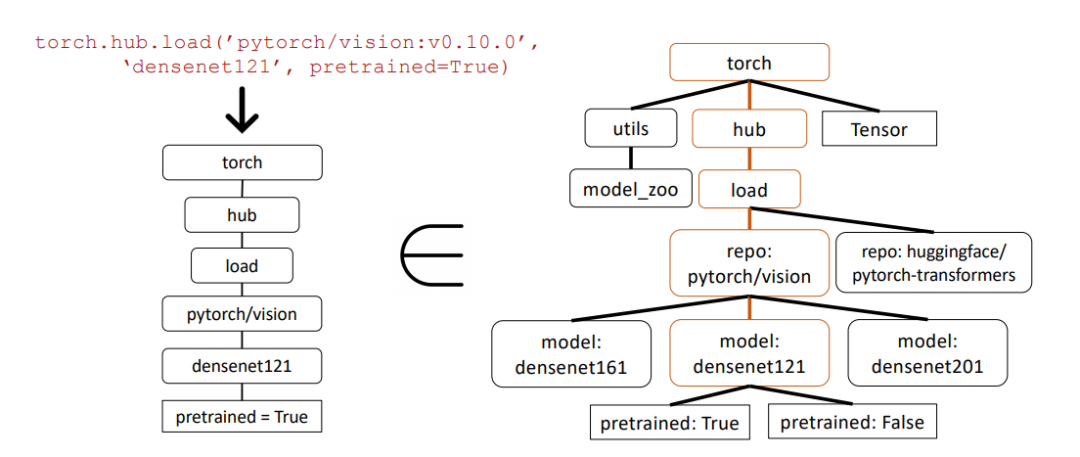
L'arbre de syntaxe abstraite est une représentation arborescente de la structure du code source, qui permet de mieux analyser et comprendre le code.
Tout d'abord, les chercheurs ont construit l'arborescence API pertinente à partir des appels API renvoyés par Gorilla (à gauche). Ceci est ensuite comparé à l'ensemble de données pour voir si l'ensemble de données API a une correspondance de sous-arbre.
Dans l'exemple ci-dessus, le sous-arbre correspondant est surligné en marron, indiquant que l'appel API est effectivement correct. Où Pretrained=True est un paramètre facultatif.
Cette ressource servira à la communauté au sens large en tant qu'outil précieux pour rechercher et mesurer les API existantes, contribuant ainsi à une utilisation plus équitable et optimale de l'apprentissage automatique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
La commande pour redémarrer le service SSH est: SystemCTL Redémarrer SSHD. Étapes détaillées: 1. Accédez au terminal et connectez-vous au serveur; 2. Entrez la commande: SystemCTL Restart SSHD; 3. Vérifiez l'état du service: SystemCTL Status Sshd.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
