
 Périphériques technologiques
IA
Protection en temps réel contre les barrages de blocage de visage sur le Web (basée sur l'apprentissage automatique)
Périphériques technologiques
IA
Protection en temps réel contre les barrages de blocage de visage sur le Web (basée sur l'apprentissage automatique)
Protection en temps réel contre les barrages de blocage de visage sur le Web (basée sur l'apprentissage automatique)

Les barrages anti-visage, c'est-à-dire qu'un grand nombre de barrages flottent, mais ne bloquent pas les personnes sur l'écran vidéo. On dirait qu'ils flottent derrière les gens.
Le Machine Learning est populaire depuis plusieurs années, mais beaucoup de gens ne savent pas que ces fonctionnalités peuvent également être exécutées dans les navigateurs
Cet article présente l'optimisation pratique de la vidéo ; processus de barrages, la fin de l'article répertorie quelques scénarios applicables pour cette solution, dans l'espoir d'ouvrir quelques idées.
mediapipe Demo (https://google.github.io/mediapipe/) montre
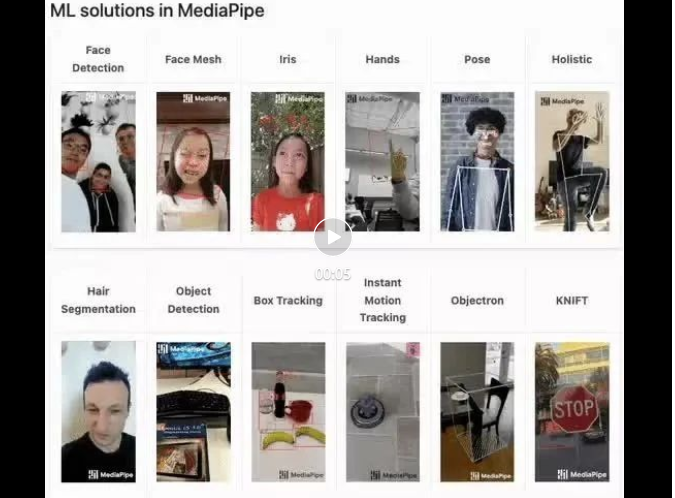
Balle anti-visage grand public Principe de mise en œuvre de l'écran
On-demand
up Télécharger la vidéo
Le calcul de l'arrière-plan du serveur extrait la zone du portrait dans l'écran vidéo et la convertit en svg pour le stockage
Pendant que le client lit la vidéo, le svg est téléchargé depuis le serveur et combiné avec le barrage. Le barrage n'est pas affiché dans la zone portrait. En même temps, en temps réel. (appareil hôte) extrait la zone de portrait de l'écran, la convertit en svg
Fusionnez les données svg dans le flux vidéo (SEI) et envoyez le flux au serveur
#🎜🎜 #Client Pendant la lecture de la vidéo, analysez le svg du flux vidéo (SEI)- Combinez le svg avec le barrage, et le barrage ne sera pas affiché dans la zone portrait #🎜🎜 #
- Le plan de mise en œuvre de cet article
- Pendant que le client lit la vidéo, les informations de la zone du portrait sont extraites de l'écran en temps réel, et les informations de la zone du portrait sont exportées dans une image et combiné avec le barrage Le barrage n'est pas affiché dans la zone du portrait.
- Principe de mise en œuvre
Utilisez des bibliothèques open source d'apprentissage automatique pour extraire les contours de portraits à partir d'images vidéo en temps réel, comme la segmentation corporelle (https://github. com/tensorflow/tfjs -models/blob/master/body-segmentation/README.md)
Exportez le contour du portrait dans une image et définissez l'image de masque du calque de barrage (https:/ /developer.mozilla.org /zh-CN/docs/Web/CSS/mask-image)
Par rapport à la solution traditionnelle (live SEI en temps réel)- #🎜 🎜#Avantages :
- # 🎜🎜# Facile à mettre en œuvre ; ne nécessite qu'un seul paramètre de balise vidéo, aucune coordination multi-extrémité n'est requise
- Aucune consommation de bande passante réseau
- Problèmes rencontrés
- Comme nous le savons tous, JavaScript a de mauvaises performances et n'est donc pas adapté aux tâches gourmandes en CPU. De la démo officielle à la pratique de l'ingénierie, le plus grand défi est la performance.
Cette pratique a finalement optimisé l'utilisation du processeur à environ 5 % (Macbook M1 2020), atteignant un état prêt pour la production.
- Processus de réglage pratique
- Sélectionnez un modèle d'apprentissage automatique
BodyPix (https://github.com/tensorflow/tfjs-models/blob/ master/body-segmentation/src/body_pix/README.md)
La précision est trop faible, le visage est étroit et il y a un chevauchement évident entre le barrage et les bords du visage du personnage
#🎜🎜 #BlazePose(https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)#🎜 🎜## 🎜🎜#Excellente précision et fournit des informations sur les points du corps, mais de mauvaises performances
Exemple de structure de données de retour[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]Excellente précision (avec le modèle BlazePose L'effet est cohérent), l'utilisation du processeur est réduite d'environ 15 % par rapport au modèle BlazePose et les performances sont supérieures, mais les informations sur les points du corps ne sont pas fournies dans les données renvoyées
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}Implémentation de la première version
Reportez-vous à l'implémentation officielle du modèle MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation /README.md#bodysegmentationdrawmask), sans optimisation Le CPU occupe environ 70%
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)Réduire la fréquence d'extraction et équilibrer l'expérience-performance
window.setTimeout(detect, 66) // 33 => 66
L'analyse du code source, combinée à l'impression des informations de segmentation, révèle que segmentation.mask.toCanvasImageSource peut obtenir l'objet ImageBitmap d'origine, qui correspond aux informations extraites par le modèle. Essayez d'écrire votre propre code pour convertir un ImageBitmap en masque au lieu d'utiliser l'implémentation par défaut fournie par la bibliothèque open source.
Principe de mise en œuvre
async function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl) context.clearRect(0, 0, canvas.width, canvas.height)// 1. 将`ImageBitmap`绘制到 Canvas 上context.drawImage(// 经验证 即使出现多人,也只有一个 segmentationawait segmentation[0].mask.toCanvasImageSource(),0, 0,canvas.width, canvas.height)// 2. 设置混合模式context.globalCompositeOperation = 'source-out'// 3. 反向填充黑色context.fillRect(0, 0, canvas.width, canvas.height)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 66)}Les étapes 2 et 3 sont équivalentes à remplir le contenu en dehors de la zone du portrait avec du noir (remplissage inversé ImageBitmap), afin de coopérer avec le css (masque- image), sinon il ne sera visible que lorsque le barrage flottera vers la zone du portrait (exactement à l'opposé de l'effet cible).
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)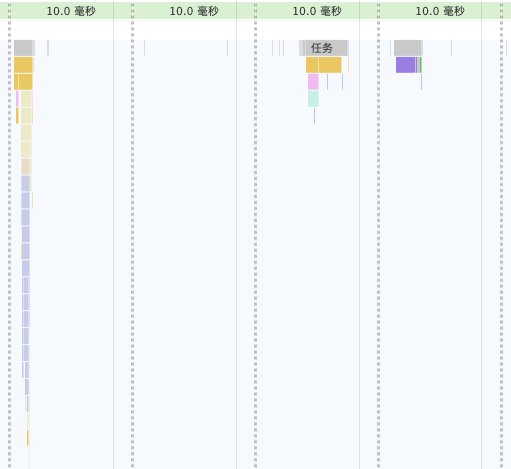
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
Ingénieur Développement Senior chez Bilibili
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
Comment personnaliser le symbole de redimensionnement via CSS et le rendre uniforme avec la couleur d'arrière-plan?
Apr 05, 2025 pm 02:30 PM
La méthode de personnalisation des symboles de redimension dans CSS est unifiée avec des couleurs d'arrière-plan. Dans le développement quotidien, nous rencontrons souvent des situations où nous devons personnaliser les détails de l'interface utilisateur, tels que l'ajustement ...
 Comment afficher correctement le 'Jingnan Mai Round Body' installé localement sur la page Web?
Apr 05, 2025 pm 10:33 PM
Comment afficher correctement le 'Jingnan Mai Round Body' installé localement sur la page Web?
Apr 05, 2025 pm 10:33 PM
En utilisant récemment des fichiers de police installés localement dans les pages Web, j'ai téléchargé une police gratuite à partir d'Internet et je l'ai installée avec succès dans mon système. Maintenant...
 Le texte sous la disposition Flex est omis mais le conteneur est ouvert? Comment le résoudre?
Apr 05, 2025 pm 11:00 PM
Le texte sous la disposition Flex est omis mais le conteneur est ouvert? Comment le résoudre?
Apr 05, 2025 pm 11:00 PM
Le problème de l'ouverture des conteneurs en raison d'une omission excessive du texte sous disposition flexible et de solutions est utilisé ...
 Pourquoi un élément div spécifique dans le navigateur Edge ne s'affiche-t-il pas? Comment résoudre ce problème?
Apr 05, 2025 pm 08:21 PM
Pourquoi un élément div spécifique dans le navigateur Edge ne s'affiche-t-il pas? Comment résoudre ce problème?
Apr 05, 2025 pm 08:21 PM
Comment résoudre le problème d'affichage causé par les feuilles de style d'agent utilisateur? Lorsque vous utilisez le navigateur Edge, un élément DIV du projet ne peut pas être affiché. Après avoir vérifié, j'ai posté ...
 Comment contrôler le haut et la fin des pages dans les paramètres d'impression du navigateur via JavaScript ou CSS?
Apr 05, 2025 pm 10:39 PM
Comment contrôler le haut et la fin des pages dans les paramètres d'impression du navigateur via JavaScript ou CSS?
Apr 05, 2025 pm 10:39 PM
Comment utiliser JavaScript ou CSS pour contrôler le haut et la fin de la page dans les paramètres d'impression du navigateur. Dans les paramètres d'impression du navigateur, il existe une option pour contrôler si l'écran est ...
 Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Comment résoudre ce problème?
Apr 05, 2025 pm 10:18 PM
Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Comment résoudre ce problème?
Apr 05, 2025 pm 10:18 PM
Pourquoi les marges négatives ne prennent-elles pas effet dans certains cas? Pendant la programmation, les marges négatives dans CSS (négatif ...
 Comment utiliser des fichiers de police installés localement sur les pages Web?
Apr 05, 2025 pm 10:57 PM
Comment utiliser des fichiers de police installés localement sur les pages Web?
Apr 05, 2025 pm 10:57 PM
Comment utiliser des fichiers de police installés localement sur les pages Web avez-vous rencontré cette situation dans le développement de pages Web: vous avez installé une police sur votre ordinateur ...
 Pourquoi les feuilles de style personnalisées peuvent-elles prendre effet sur les pages Web locales de Safari mais pas sur les pages Baidu?
Apr 05, 2025 pm 05:15 PM
Pourquoi les feuilles de style personnalisées peuvent-elles prendre effet sur les pages Web locales de Safari mais pas sur les pages Baidu?
Apr 05, 2025 pm 05:15 PM
Discussion sur l'utilisation de styles de style personnalisés dans Safari aujourd'hui, nous allons discuter d'une question sur l'application de feuilles de style personnalisées pour le navigateur Safari. Novice frontal ...
