
 Périphériques technologiques
IA
La nouvelle méthode d'analyse et de génération de données multimodales de l'équipe UW-chinoise JAMIE améliore considérablement les capacités de prédiction du type de cellule et de sa fonction
Périphériques technologiques
IA
La nouvelle méthode d'analyse et de génération de données multimodales de l'équipe UW-chinoise JAMIE améliore considérablement les capacités de prédiction du type de cellule et de sa fonction
La nouvelle méthode d'analyse et de génération de données multimodales de l'équipe UW-chinoise JAMIE améliore considérablement les capacités de prédiction du type de cellule et de sa fonction

Ces dernières années, avec le développement rapide de la technologie unicellulaire, nous avons pu mesurer diverses caractéristiques de cellules uniques pour obtenir des données multimodales unicellulaires (telles que scRNA-seq, scATAC-seq, Patch-seq ).
Ces données nous aident à mieux comprendre les fonctions cellulaires et les mécanismes moléculaires. Par exemple, les chercheurs ont récemment utilisé des méthodes d’apprentissage automatique pour analyser la relation entre les données multimodales unicellulaires afin de comprendre les mécanismes biologiques impliqués dans les types de cellules et les maladies.
Cependant, l'acquisition de données multimodales unicellulaires est souvent coûteuse et une perte modale se produit souvent. Les méthodes d'apprentissage automatique existantes nécessitent généralement des données multimodales entièrement adaptées pour le remplissage et l'intégration des données, et ne conviennent pas aux situations dans lesquelles les modalités manquent.
Afin de résoudre ce problème, le laboratoire de Wang Daifeng de l'Université du Wisconsin-Madison a développé une méthode d'apprentissage automatique open source basée sur des auto-encodeurs variationnels conjoints - Joint Variational Autoencoders for Multimodal Imputation and Embedding (JAMIE).
JAMIE peut être utilisé pour l'analyse intégrée de données multimodales unicellulaires, telles que l'alignement des données, l'intégration et le remplissage des données manquantes afin de mieux prédire les types et les fonctions des cellules.
Ce travail a été récemment publié dans "Nature Machine Intelligence".

Adresse papier : https://www.nature.com/articles/s42256-023-00663-z
Adresse du projet : https://github.com/daifengwanglab /JAMIE
Introduction à la méthode JAMIE
JAMIE entraîne un modèle d'auto-encodeur variationnel conjoint réutilisable pour améliorer la modalité unique en projetant les données multimodales disponibles séparément dans des espaces latents similaires. Capacité à déduire des modèles d'état.
Comme le montre la figure 1, pour effectuer une imputation multimodale, JAMIE alimente les données dans un encodeur puis traite les résultats de l'espace latent via le décodeur opposé.
JAMIE combine la génération d'espace latent réutilisable et flexible d'auto-encodeurs avec l'estimation automatique de la correspondance des méthodes d'alignement, permettant le traitement de données multimodales avec une correspondance incomplète.
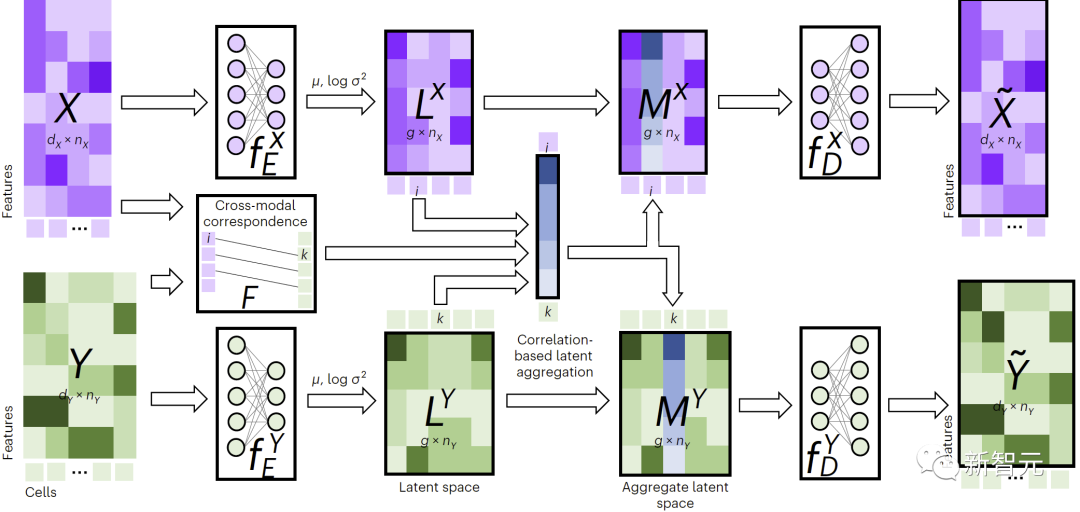
Figure 1. Présentation de la méthode JAMIE
Plus précisément, JAMIE peut être divisé en deux étapes suivantes :
- Prétraitement des données d'entrée. En prenant le mode bimodal comme exemple, supposons que les matrices de données correspondant aux modes sont et respectivement. Notez que les dimensions et la somme des caractéristiques peuvent être différentes, ainsi que le nombre d'échantillons. Le prétraitement normalise chaque ligne de chaque matrice pour avoir une moyenne de 0 et une variance de 1. S'il existe des données correspondantes, l'utilisateur peut fournir une matrice de corrélation modale pour améliorer les performances, ce qui signifie que le ème échantillon du modal correspond complètement au ème échantillon du modal, signifie qu'il n'y a pas de correspondance connue et signifie qu'il y a une partie. correspondance.
- Utilisez l'auto-encodeur variationnel conjoint pour connaître l'espace latent de similarité de chaque modalité : et , où (par défaut, réglable par l'utilisateur) est la dimension de l'espace latent. Pendant le processus de formation, JAMIE minimise la fonction de perte suivante :
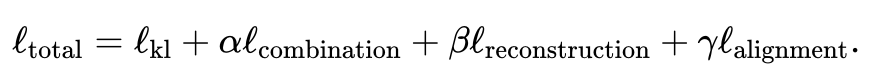
La fonction de perte totale contient quatre éléments.
Le premier élément calcule la divergence Kullback-Leibler (KL) entre la distribution déduite par l'auto-encodeur variationnel et la distribution normale standard multivariée, ce qui aide à maintenir la continuité de l'espace latent ; les échantillons correspondants ; le troisième terme est la somme des erreurs quadratiques moyennes entre la matrice de données reconstruite et la matrice de données d'origine ; le quatrième terme utilise la correspondance intermodale déduite pour ajuster l'espace latent généré ;
Pour les expressions spécifiques de chaque élément, veuillez consulter le texte original de l'article. Les poids des deuxième, troisième et quatrième éléments par rapport au premier élément peuvent être ajustés par l'utilisateur. JAMIE fournit également des poids par défaut adaptés aux situations courantes.
Le tableau suivant montre la comparaison du modèle et de la portée applicable de JAMIE avec les méthodes de pointe actuelles. JAMIE unifie les fonctionnalités de plusieurs méthodes d'intégration et d'interpolation différentes dans une seule architecture, permettant ainsi l'interpolation des modalités manquantes, permettant la compatibilité des données non omiques et la capacité de gérer des données multimodales avec seulement des avantages de correspondance partielle.
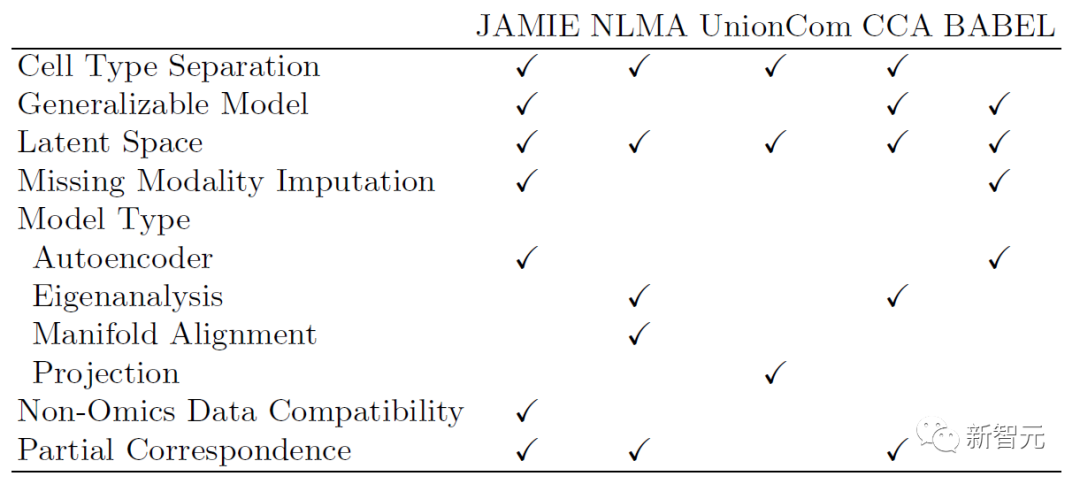
Tableau 1. Comparaison des différentes méthodes d'intégration multimodale et de remplissage modal manquant. Grâce à une architecture unique, JAMIE intègre des fonctionnalités de plusieurs méthodes d'intégration et d'interpolation différentes. NLMA : Nonlinear Manifold Alignment [15], UnionCom [7], CCA : Canonical Correlation Analysis [15, 16], BABEL [5].
Principales applications de JAMIE
Intégration et prédiction phénotypique de données multimodales
L'intégration de données multimodales peut améliorer les performances de classification, améliorer la connaissance phénotypique et la compréhension de mécanismes biologiques complexes.
Étant donné deux ensembles de données et les relations correspondantes, JAMIE peut générer des données spatiales latentes, basées sur l'encodeur formé et, et effectuer un clustering ou une classification basée sur .
Le clustering basé sur des données d'espace latent présente plusieurs avantages, tels que l'intégration des deux modalités dans la génération de fonctionnalités. JAMIE peut alors prédire les correspondances d'échantillons, telles que la prédiction du type de cellule.
Pour les ensembles de données partiellement étiquetés, les cellules du même cluster doivent avoir des types similaires.
JAMIE sépare les caractéristiques des différents types de données dans le processus de génération de données spatiales latentes, de sorte que des algorithmes de clustering ou de classification complexes ne sont généralement pas nécessaires pour obtenir de meilleurs résultats.
Pour les données de grande dimension, JAMIE utilise UMAP [32] pour la visualisation du regroupement de types de cellules.
Imputation de données multimodales
De nombreuses méthodes d'imputation multimodales actuelles ne peuvent pas démontrer qu'elles ont appris les mécanismes biologiques sous-jacents à des fins d'imputation.
Par rapport aux réseaux de rétroaction ou aux méthodes de régression linéaire, JAMIE peut mieux apprendre les mécanismes biologiques sous-jacents pour prédire les données manquantes sur la base de fondements mathématiques plus rigoureux.
La figure 2 montre le processus de JAMIE pour le remplissage de données intermodales. JAMIE entraîne d'abord les modèles d'encodage et de décodage sur les données d'entraînement.
Pour les nouvelles données, JAMIE utilise d'abord l'encodeur appris à partir des données pour les projeter dans l'espace latent pour obtenir, puis les obtient en agrégeant les caractéristiques de l'espace latent, et enfin les décode en données de motif manquantes via le décodeur correspondant.
JAMIE utilise l'espace latent pour prédire la correspondance entre les cellules, ce qui peut aider à comprendre la relation entre les caractéristiques des données et les phénotypes.
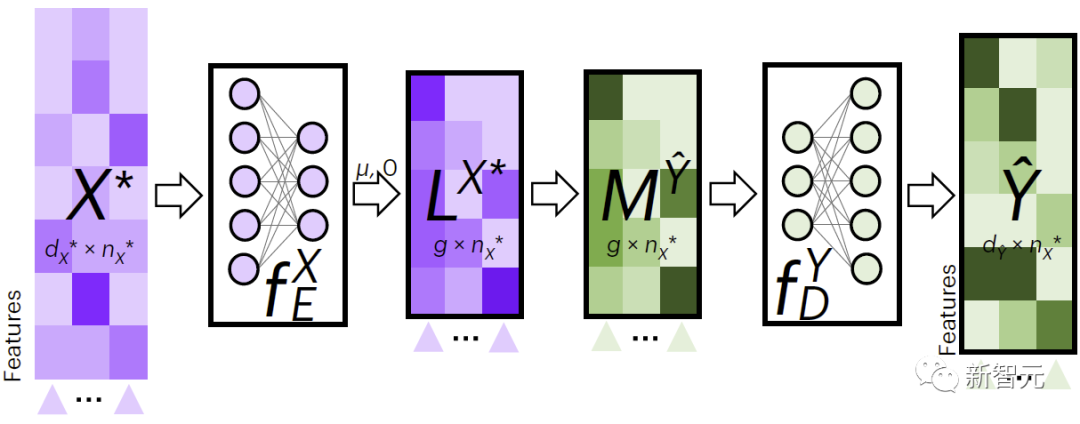
Figure 2. Interpolation multimodale JAMIE
Explication des caractéristiques de l'espace latent et des caractéristiques de remplissage
Pour expliquer le modèle formé , JAMIE adopte SHAP (SHapley Explications additives)[18].
SHAP évalue l'importance des caractéristiques d'entrée individuelles en modulant par échantillonnage les prédictions individuelles générées par le modèle. Cela peut être utilisé pour une variété d’applications intéressantes.
Si la variable cible peut être facilement séparée par phénotype, SHAP peut identifier les caractéristiques pertinentes pour une étude plus approfondie. De plus, si nous effectuons une imputation, SHAP peut révéler les connexions intermodales apprises par le modèle.
À partir d'un modèle et d'un échantillon, apprenez la valeur SHAP telle que où se trouve le vecteur de caractéristique d'arrière-plan.
Si , alors la somme des valeurs SHAP et de la sortie en arrière-plan sera égale à , chacune étant proportionnelle à l'impact sur la sortie du modèle.
Une autre technique utile consiste à sélectionner une métrique clé pour la classification (par exemple, LTA [7, 19]) ou l'imputation (par exemple, correspondance entre les caractéristiques imputées et les caractéristiques mesurées) et à l'utiliser une par une dans le modèle. évalué en supprimant (en remplaçant) chaque fonctionnalité par une valeur d'arrière-plan.
Ensuite, si la métrique clé s'aggrave, cela indique que les fonctionnalités supprimées sont plus importantes pour les résultats du modèle.
Résultats expérimentaux
JAMIE a utilisé quatre ensembles de données multimodales unicellulaires couramment utilisés pour la vérification.
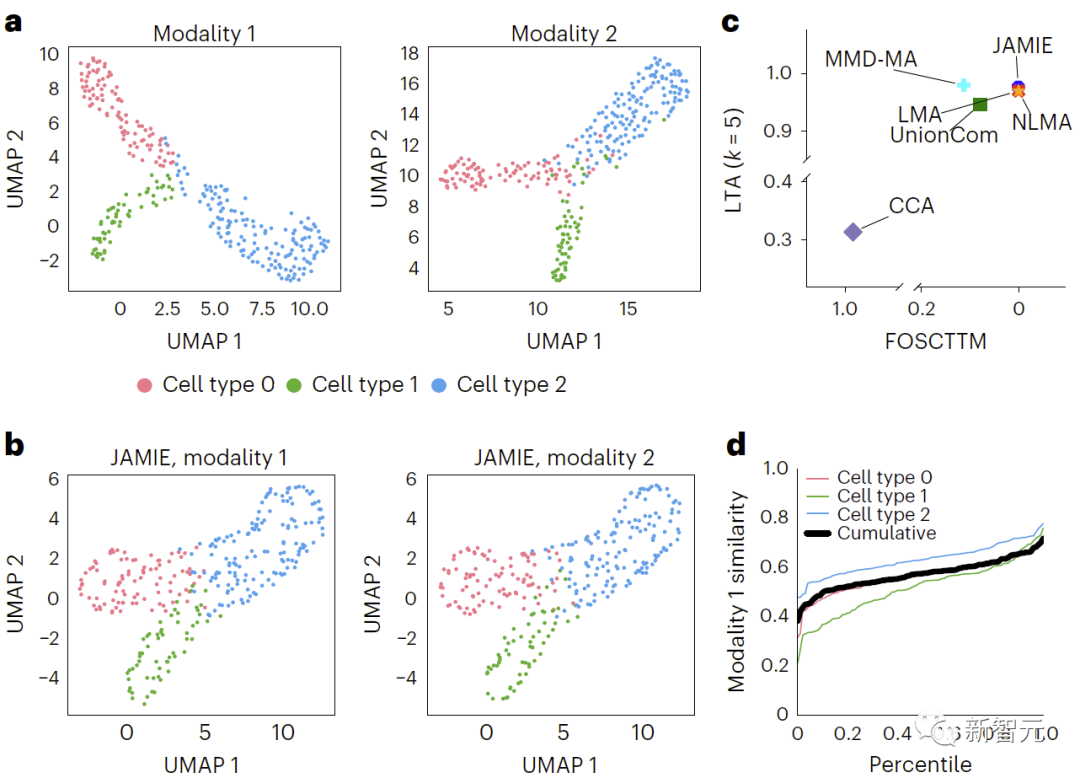
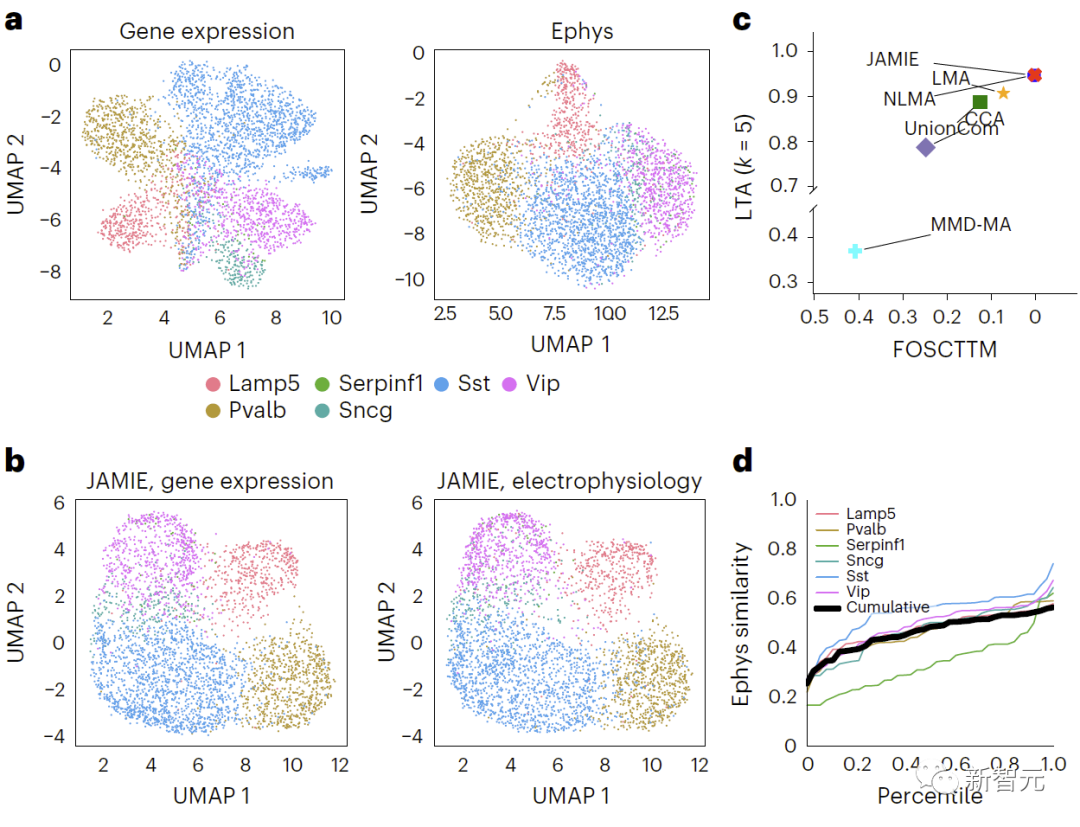
(1) Données multimodales simulées (300 échantillons, 3 types de cellules) générées par échantillonnage de distribution gaussienne de variétés ramifiées de MMD-MA ; (2) à partir du cortex visuel de souris (expression du gène Patch-seq et électrophysiologique) données de caractérisation de cellules neuronales uniques dans le cortex moteur de souris (1 208 échantillons, 9 types de cellules) et le cortex moteur de souris (1 208 échantillons, 9 types de cellules
(3) à partir de 10 fois l'expression de gènes multi-omiques unicellulaires et la chromatine ; données d'accessibilité pour 8 981 échantillons dans le cerveau humain en développement (21 semaines de gestation, couvrant 7 types de cellules majeurs du cortex cérébral humain
(4) expression du gène scRNA-seq et données d'accessibilité de la chromatine scATAC-seq de 4 301 cellules de la lignée cellulaire d'adénocarcinome du côlon COLO-320DM.
L'évaluation a révélé que JAMIE est nettement meilleur que les autres méthodes (comparaison des résultats des données de simulation de collecteurs de branches de MMD-MA dans la figure 3 et comparaison des résultats des données du cortex visuel de la souris dans la figure 4) et donne la priorité au multimodal. remplissage de fonctionnalités importantes tout en fournissant potentiellement de nouvelles informations mécanistiques à résolution cellulaire.
Résumé
En résumé, JAMIE est un nouveau modèle de réseau neuronal profond pour la prédiction intégrée de données multimodales unicellulaires.Il convient aux données multimodales complexes, mixtes ou partiellement correspondantes, mises en œuvre via une nouvelle méthode d'agrégation d'intégration latente qui repose sur une structure d'auto-encodeur variationnel conjoint (VAE). En plus des performances supérieures mentionnées ci-dessus, JAMIE dispose également de capacités informatiques efficaces et d'une faible utilisation de la mémoire. De plus, les modèles pré-entraînés et les intégrations latentes multimodales apprises peuvent être réutilisés dans les analyses en aval.
Bien sûr, pour des ensembles de données plus volumineux, la formation des auto-encodeurs variationnels (VAE) prend beaucoup de temps. Par conséquent, les méthodes de sélection de fonctionnalités précédentes, telles que la PCA automatique dans JAMIE, contribuent à réduire les délais. Étant donné que la VAE utilise la perte de reconstruction, le prétraitement des données est également crucial pour éviter que des fonctionnalités volumineuses ou répétées n'affectent de manière disproportionnée les fonctionnalités intégrées de faible dimension. Pour une imputation multimodale spécifique, la diversité de l'ensemble de données de formation doit être soigneusement prise en compte pour éviter de biaiser le modèle final et d'avoir un impact négatif sur sa capacité de généralisation. JAMIE peut également potentiellement être étendu pour aligner des ensembles de données provenant de différentes sources plutôt que de différentes modalités, telles que les données d'expression génique dans différentes conditions.
Introduction aux auteurs
Les auteurs de l'article sont Noah Cohen Kalafut (étudiant au doctorat au Département d'informatique), Huang Xiang (chercheur principal) et Wang Daifeng (PI) sont affiliés au Département de biostatistique et d'informatique médicale, Département d'informatique, Université du Wisconsin-Madison et Weisman Research Center. L'auteur correspondant est le professeur Wang Daifeng.
Fondé en 1973, le Centre Weisman fait progresser la recherche sur le développement humain, les troubles neurodéveloppementaux et les maladies neurodégénératives depuis un demi-siècle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Les principaux échanges comprennent: 1. Binance, le plus grand volume de trading au monde, prend en charge 600 devises et les frais de gestion des points sont de 0,1%; 2. Okx, une plate-forme équilibrée, prend en charge 708 paires de trading, et les frais de traitement des contrats perpétuels sont de 0,05%; 3. Gate.io, couvre 2700 petites monnaies, et les frais de traitement des points sont de 0,1% à 0,3%; 4. Coinbase, la référence de conformité américaine, les frais de traitement des points sont de 0,5%; 5. Kraken, la haute sécurité et l'audit de réserve régulière.
 'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
Le plongeon sur le marché des crypto-monnaies a provoqué la panique parmi les investisseurs, et Dogecoin (Doge) est devenu l'une des zones les plus difficiles. Son prix a fortement chuté et le verrouillage de la valeur totale de la finance décentralisée (DEFI) (TVL) a également connu une baisse significative. La vague de vente de "Black Monday" a balayé le marché des crypto-monnaies, et Dogecoin a été le premier à être touché. Son Defitvl a chuté aux niveaux de 2023 et le prix de la devise a chuté de 23,78% au cours du dernier mois. Le Defitvl de Dogecoin est tombé à un minimum de 2,72 millions de dollars, principalement en raison d'une baisse de 26,37% de l'indice de valeur SOSO. D'autres plates-formes de Defi majeures, telles que le Dao et Thorchain ennuyeux, TVL ont également chuté de 24,04% et 20, respectivement.
 Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Les échanges jouent un rôle essentiel sur le marché des crypto-monnaies d'aujourd'hui. Ce ne sont pas seulement des plateformes pour les investisseurs pour négocier, mais aussi des sources importantes de liquidité du marché et la découverte des prix. Les plus grands échanges de devises virtuels au monde se classent parmi les dix premiers, et ces échanges sont non seulement bien en avance dans le volume des échanges, mais présentent également leurs propres avantages dans l'expérience utilisateur, la sécurité et les services innovants. Les échanges qui dépassent la liste ont généralement une grande base d'utilisateurs et une influence approfondie du marché, et leur volume de trading et leurs types d'actifs sont souvent difficiles à atteindre par d'autres échanges.
 Rexas Finance (RXS) peut dépasser Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) en 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) peut dépasser Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) en 2025
Apr 21, 2025 pm 02:30 PM
Sur le marché volatil des crypto-monnaies, les investisseurs recherchent des alternatives qui vont au-delà des devises populaires. Bien que les crypto-monnaies bien connues telles que Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) sont également confrontées à des défis tels que le sentiment du marché, l'incertitude réglementaire et l'évolutivité. Cependant, un nouveau projet émergent, la rexasfinance (RXS), est en émergence. Il ne s'appuie pas sur les effets de célébrités ou le battage médiatique, mais se concentre sur la combinaison des actifs du monde réel (RWA) avec la technologie de la blockchain pour offrir aux investisseurs une façon innovante d'investir. Cette stratégie le fait espérer être l'un des projets les plus réussis de 2025. Rexasfi
 La plate-forme de médias sociaux Web3 Tox collabore avec Omni Labs pour intégrer l'infrastructure d'IA
Apr 21, 2025 pm 07:06 PM
La plate-forme de médias sociaux Web3 Tox collabore avec Omni Labs pour intégrer l'infrastructure d'IA
Apr 21, 2025 pm 07:06 PM
La plate-forme décentralisée de médias sociaux Tox a atteint un partenariat stratégique avec Omnilabs, un leader des solutions d'intelligence artificielle, pour intégrer les capacités d'intelligence artificielle dans l'écosystème web3. Ce partenariat est publié par le compte officiel de Tox Officiel de Tox et vise à créer un environnement en ligne plus juste et plus intelligent. Omnilabs est connu pour ses systèmes autonomes intelligents, avec sa capacité AI-AS-A-Service (AIAAS) soutenant de nombreux protocoles Defi et NFT. Son infrastructure utilise des agents d'IA pour la prise de décision en temps réel, les processus automatisés et l'analyse approfondie des données, visant à s'intégrer de manière transparente dans l'écosystème décentralisé pour autonomiser la plate-forme blockchain. La collaboration avec Tox rendra les outils d'IA d'Omnilabs plus étendus, en les intégrant dans les réseaux sociaux décentralisés,
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
 WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
Binance est le suzerain de l'écosystème mondial de trading d'actifs numériques, et ses caractéristiques comprennent: 1. Le volume de négociation quotidien moyen dépasse 150 milliards de dollars, prend en charge 500 paires de négociation, couvrant 98% des monnaies grand public; 2. La matrice d'innovation couvre le marché des dérivés, la mise en page Web3 et le système éducatif; 3. Les avantages techniques sont des moteurs de correspondance d'une milliseconde, avec des volumes de traitement de pointe de 1,4 million de transactions par seconde; 4. Conformité Progress détient des licences de 15 pays et établit des entités conformes en Europe et aux États-Unis.
 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
