

Une formation de mise au point d'une durée de 220 heures s'est achevée hier. La tâche principale consistait à peaufiner un modèle de dialogue sur CHATGLM-6B qui permet de diagnostiquer plus précisément les informations d'erreur de la base de données.
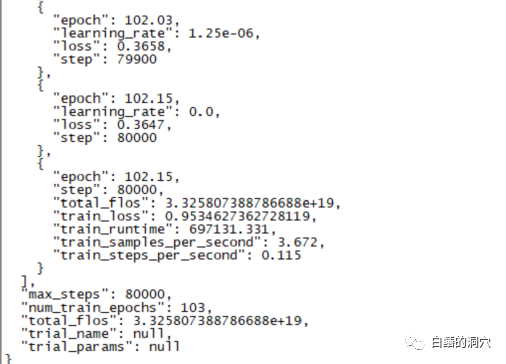
Cependant, le résultat final de cette formation que j'attendais depuis près de dix jours était décevant Par rapport à la formation que j'avais faite auparavant avec une couverture d'échantillon plus petite, la différence était assez grande.
Ce résultat est quand même un peu décevant. Ce modèle n'a fondamentalement aucune valeur pratique. Il semble que les paramètres et l'ensemble de formation doivent être réajustés et la formation est à nouveau effectuée. La formation de grands modèles linguistiques est une course aux armements, et il est impossible de jouer sans un bon équipement. Il semble qu'il faille également moderniser le matériel de laboratoire, sinon il y aura quelques dizaines de jours à perdre.
À en juger par les récents échecs des formations de mise au point, la formation de mise au point n'est pas un chemin facile à parcourir. Différents objectifs de tâche sont mélangés pour la formation. Différents objectifs de tâche peuvent nécessiter différents paramètres de formation, ce qui rend l'ensemble de formation final incapable de répondre aux besoins de certaines tâches. Par conséquent, PTUNING n'est adapté qu'à une tâche très spécifique et n'est pas nécessairement adapté aux tâches mixtes. Les modèles destinés à des tâches mixtes peuvent devoir utiliser FINETUNE. C'est similaire à ce que tout le monde a dit lorsque je communiquais avec un ami il y a quelques jours.
En fait, comme l'entraînement du modèle est relativement difficile, certaines personnes ont renoncé à entraîner le modèle par elles-mêmes et ont plutôt vectorisé la base de connaissances locale pour une récupération plus précise, puis utilisé AUTOPROMPT pour générer des invites automatiques à partir des résultats de la récupération. . Renseignez-vous sur le modèle de discours. Cet objectif est facilement atteint en utilisant langchain.
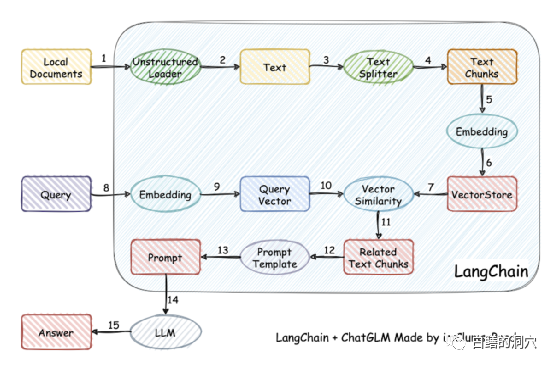
Le principe de fonctionnement est de charger le document local sous forme de texte via le chargeur, puis de diviser le texte en fragments de texte et de les écrire dans le stockage vectoriel après encodage pour une utilisation dans les requêtes. Une fois les résultats de la requête publiés, des invites pour poser des questions sont automatiquement formées via le modèle d'invite pour demander à LLM, et LLM génère la réponse finale.
Il y a un autre point important dans ce travail. L'un est de rechercher plus précisément les connaissances dans la base de connaissances locale. Ceci est réalisé en stockant des vecteurs dans la recherche. Les anglais sont Il existe de nombreuses solutions, vous pouvez en choisir une qui est la plus conviviale pour votre base de connaissances.
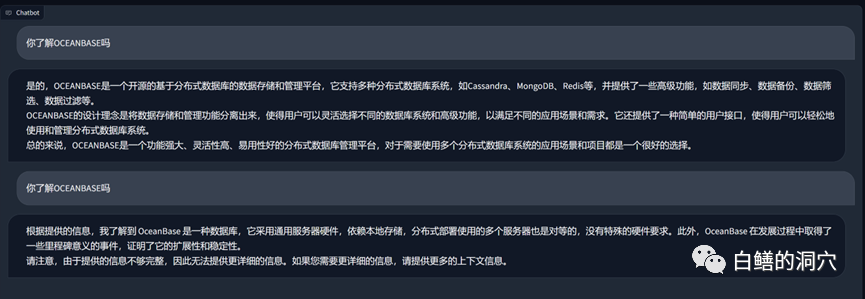
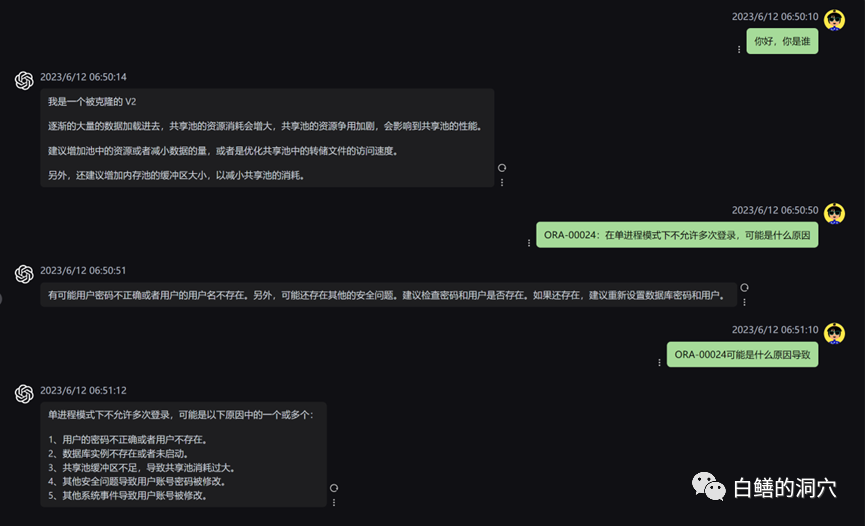
Ce qui précède est une question et une réponse menée sur Vicuna-13b via la base de connaissances sur OB. Ce qui précède est la réponse à la possibilité d'utiliser directement LLM sans utiliser la base de connaissances locale. Voici la réponse au chargement après avoir accédé à la base de connaissances locale. On peut constater que l’amélioration des performances est assez évidente.
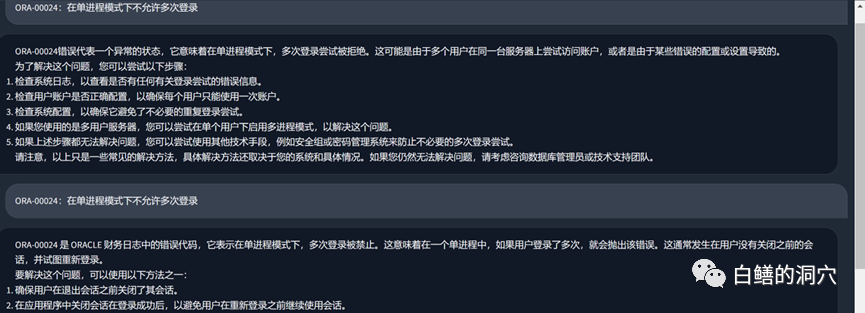
Jetons un coup d'œil au problème d'erreur ORA tout à l'heure. Avant d'utiliser la base de connaissances locale, LLM était fondamentalement absurde. Après avoir chargé la base de connaissances locale, la réponse est toujours assez satisfaisante. le texte sont également des erreurs dans notre base de connaissances. En fait, l'ensemble de formation utilisé par PTUNING est également généré à partir de cette base de connaissances locale.
Nous pouvons acquérir une certaine expérience des pièges sur lesquels nous avons marché récemment. Tout d'abord, la difficulté du réglage est bien plus élevée que nous le pensions. Bien que le réglage nécessite moins d'équipement que le réglage fin, la difficulté de l'entraînement n'est pas du tout faible. Deuxièmement, il est bon d'utiliser la base de connaissances locale via Langchain et l'invite automatique pour améliorer les capacités LLM. Pour la plupart des applications d'entreprise, tant que la base de connaissances locale est triée et qu'une solution de vectorisation appropriée est sélectionnée, vous devriez pouvoir obtenir des résultats satisfaisants. ne sont pas pires que l'effet PTUNING/FINETUNE. Troisièmement, et encore une fois comme mentionné la dernière fois, la capacité du LLM est cruciale. Un LLM puissant doit être sélectionné comme modèle de base à utiliser. Tout modèle embarqué ne peut améliorer que partiellement les capacités et ne peut jouer un rôle décisif. Quatrièmement, en ce qui concerne les connaissances liées aux bases de données, la vigogne-13b possède de très bonnes capacités.
Je dois me rendre chez le client pour communiquer tôt ce matin. Le temps est limité le matin, je vais donc juste écrire quelques phrases. Si vous avez des idées à ce sujet, veuillez laisser un message pour en discuter (la discussion n'est visible que par vous et moi). Je marche également seul sur cette route, j'espère qu'il y a d'autres voyageurs qui pourront me donner des conseils.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 qu'est-ce que l'optimisation
qu'est-ce que l'optimisation
 Logiciel d'optimisation de mots clés Baidu
Logiciel d'optimisation de mots clés Baidu
 Méthode d'optimisation du classement des mots clés Baidu SEO
Méthode d'optimisation du classement des mots clés Baidu SEO
 Quelles sont les performances de php8 ?
Quelles sont les performances de php8 ?
 Quelles sont les performances de thinkphp ?
Quelles sont les performances de thinkphp ?
 Comment modifier les autorisations du dossier 777
Comment modifier les autorisations du dossier 777
 Comment utiliser des vidéos en Java
Comment utiliser des vidéos en Java
 Outils de test de logiciels
Outils de test de logiciels
 Pourquoi l'activation de Win10 échoue-t-elle ?
Pourquoi l'activation de Win10 échoue-t-elle ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



