

Comprendre l'évolution des communautés d'information en ligne est crucial pour concevoir des systèmes de recommandation d'actualités plus efficaces, mais les recherches existantes sont limitées dans la compréhension de la manière dont les systèmes de recommandation influencent l'évolution des communautés en raison du manque d'ensembles de données et de plates-formes appropriées. à des conceptions de système sous-optimales qui peuvent affecter l’utilité à long terme.
En réponse à ce problème, l'équipe de recherche CISL de l'École d'informatique de l'Université de Fudan a développé SimuLine, une plateforme de simulation d'évolution de l'écosystème de recommandations d'actualités.
SimuLine construit un espace latent reflétant le comportement humain à partir de données réelles basées sur des modèles linguistiques pré-entraînés et un score de propension inverse. Ensuite, la dynamique évolutive de l'écosystème de recommandation d'actualités est simulée via un agent. -modélisation basée.
SimuLine prend en charge plus de 100 cycles de création pour plus de 10 000 lecteurs et plus de 1 000 créateurs sur un seul serveur (mémoire 256 Go, carte graphique grand public) - recommandé -Simulation interactive tout en fournissant un cadre d'analyse complet comprenant des indicateurs quantitatifs, des visualisations et des explications textuelles.
Des expériences de simulation approfondies montrent que SimuLine a un grand potentiel pour comprendre les processus d'évolution de la communauté et tester les algorithmes de recommandation.

Auteur : Zhang Guangping, Li Dongsheng, Gu Hansu , Lu Xun, Shang Li, Gu Ning
Adresse papier : https://arxiv.org/abs/2305.14103#🎜🎜 #
News Recommendation Ecosystem Evolution Simulation PlatformAvec la popularité des médias sociaux (médias sociaux), les gens s'appuient de plus en plus sur les communautés d'information en ligne sont utilisés pour publier et obtenir des informations. Chaque jour, des millions d'informations sont publiées par des créateurs de contenu sur différents types de communautés d'information en ligne et lues par des utilisateurs massifs dans le cadre de la distribution de systèmes de recommandation.
Avec la production et la consommation de contenu d'actualité, les communautés d'information en ligne sont dans un processus d'évolution dynamique continue.
Comme d'autres types de communautés en ligne, le développement des communautés d'information en ligne est également conforme à la fameuse théorie du cycle de vie, c'est-à-dire qu'il passe par des "start-up" - "croissance" - " "Maturité" - le stade du "déclin".
Dans la perspective de la théorie du cycle de vie, de nombreux travaux de recherche ont exploré le modèle d'évolution des communautés en ligne et formulé des suggestions pour le fonctionnement de chaque étape de la vie. faire du vélo.
Cependant, l'impact des systèmes de recommandation, l'une des infrastructures techniques les plus importantes des communautés d'information en ligne, sur l'évolution des communautés d'information en ligne reste encore entouré de mystère.
Afin de résoudre ce mystère, l'équipe de recherche CISL de l'École d'informatique de l'Université de Fudan s'est concentrée sur les trois questions de recherche suivantes et a essayé de trouver leurs réponses à travers expériences de simulation Réponse :
1) Quelles sont les caractéristiques de chaque étape du cycle de vie des écosystèmes de recommandation d'actualités (NRE) ?
2) Quels sont les facteurs clés à l'origine de l'évolution des NRE, et comment ces facteurs interagissent-ils les uns avec les autres pour affecter le processus évolutif ?
3) Comment obtenir une meilleure utilité multipartite à long terme grâce à la stratégie de conception du système de recommandation, évitant ainsi que la communauté ne tombe dans le « déclin » ?
Afin de répondre à ces trois questions de recherche, l'équipe de recherche du CISL a développé SimuLine, une plateforme de simulation d'évolution de l'écosystème de recommandations d'actualités.
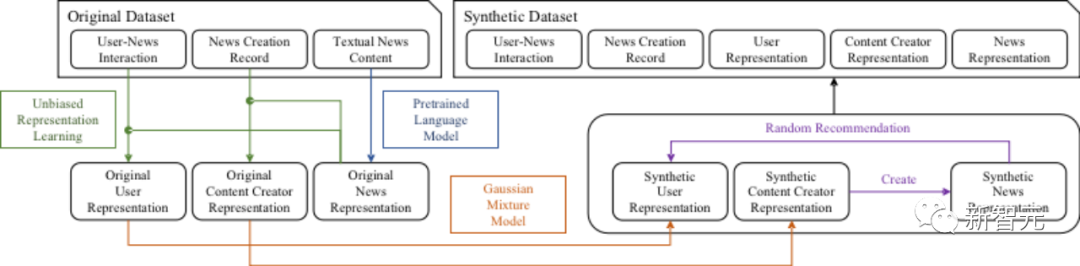
SimuLine génère d'abord des données synthétiques basées sur des ensembles de données du monde réel. Afin de résoudre le problème de biais d'exposition inhérent à l'ensemble de données d'origine (Biais d'exposition), SimuLine a introduit le score de propension inverse (Inverse Propensity Score) pour éliminer le biais.
Afin de construire un espace latent proche du processus de prise de décision humaine, SimuLine introduit des modèles de langage pré-entraînés (Pretrained Language Models) basés sur des corpus à grande échelle pour construire l'espace latent. SimuLine utilise un modèle basé sur des agents pour construire l'espace latent. La modélisation basée sur des agents simule le comportement et les interactions des utilisateurs, des créateurs de contenu et des systèmes de recommandation dans l'écosystème de recommandation d'actualités.
Lorsque vous essayez de construire un simulateur qui représente un utilisateur, la première question qui vient à l'esprit est "Utilisateur". Comment devrait les différents comportements de (Latent Space), puis mapper les intérêts et le contenu d'actualité de l'utilisateur à cet espace.
De cette façon, il est très pratique de mesurer l'amour de l'utilisateur pour l'actualité à travers la similitude des vecteurs dans l'espace latent, puis de définir une série de comportements logiques et règles.
# 🎜🎜#Alors comment construire cet espace caché ?
Certains étudiants ont dit : « Pourquoi est-ce si difficile !? L'algorithme de recommandation n'est-il pas utilisé pour faire ce travail ? Ne pouvez-vous pas simplement en apprendre un en utilisant le algorithme de recommandation ? Est-ce bien ?
Le plus déroutant pour l'équipe de recherche du CISC est une vulnérabilité logique appelée "Algorithm Confounding". C'est-à-dire si l'algorithme recommandé A est utilisé pour construire un Espace caché et cartographier les utilisateurs et les actualités comme base de leur véritable prise de décision comportementale, alors l'algorithme B utilisé dans le processus de simulation ultérieur deviendra l'algorithme A approprié (sera-t-il familier aux étudiants qui connaissent un certain apprentissage par distillation) ?
De plus, la plupart des algorithmes de recommandation actuels sont toujours des modèles de boîte noire. Même si vous fermez les yeux et laissez tomber Algorithm Confounding, vous devrez effectuer une simulation. data Vous serez également confus lors de l'analyse (cette dimension s'agrandit, mais que représente cette dimension ???).
Juste au moment où l'équipe de recherche était perdue, un éclair de lumière blanche l'a traversé : il me semble avoir vu un article avant de dire qu'un modèle de langage formé sur la base de un corpus à grande échelle (à cette époque, c'était encore le monde de Bert, et ChatGPT n'était pas encore né) pourrait montrer certaines cognitions humaines de base (c'est-à-dire le fameux Roi – mâle + Femelle = Reine).
Cette chose ne serait-elle pas très appropriée pour construire un espace latent :
1. Utilisateurs et actualités codés ;
2. En apprenant des représentations textuelles globales à partir de corpus à grande échelle, la cognition humaine qu'elle incarne devrait être basique et universelle, contournant ainsi le problème de confusion d'algorithmes. ;
3. Bien qu'il ne soit pas clair ce que représente chaque dimension dans son espace latent, cela n'affecte pas la compréhensibilité de cet espace. explication approximative du texte pour chaque point de l'espace grâce à une récupération vectorielle similaire.
C'est tout simplement merveilleux ! La décision vous appartient !
MAP
# 🎜🎜# résout le problème de la construction de l'espace latent. L'étape suivante consiste à mapper les utilisateurs et les actualités sur cet espace. Les actualités sont faciles à dire. À l'origine, les actualités doivent contenir des informations textuelles riches, qui peuvent être directement codées, mais comment les utilisateurs doivent-ils les gérer ? Est-il possible de trouver une moyenne en utilisant les actualités que l'utilisateur aime dans l'historique ?
L’abominable Algorithm Confounding est de retour avec un nom différent cette fois-ci, il s’appelle Exposure Bias, ce qui signifie que l’enregistrement « J’aime » de l’utilisateur ne reflète pas nécessairement pleinement l’intérêt de l’utilisateur, car les nouvelles que l’utilisateur aime doivent être vues par l’utilisateur. Les nouvelles que voient les utilisateurs ont été filtrées par le système de recommandation. Il est possible que l'utilisateur ne les ait pas aimées parce qu'il ne les a pas vues. Heureusement, après tant d'années de progrès rapides, l'arsenal dans le domaine des systèmes de recommandation est suffisant. L'équipe de recherche a trouvé une arme pratique pour résoudre ce problème à partir de l'entrepôt de recommandation impartiale : l'Inverse Propensity Score (IPS). Pour faire simple, il s'agit de pondérer les échantillons recommandés en estimant leur densité d'exposition, compensant ainsi le biais qu'elle apporte lors du processus d'apprentissage du modèle, résolvant ainsi le problème de codage de l'utilisateur. Quant aux créateurs de contenu finaux, leur comportement de publication de contenu n'est pas perturbé par le biais d'exposition et leurs enregistrements historiques sont directement pondérés. En fait, après l'opération ci-dessus, le travail de préparation des données est pratiquement terminé, mais il reste encore deux lacunes : · Premièrement, l'échelle des données n'a pas été ajustée et elle peut ne pas être adaptée aux ressources informatiques ( petit âne tire gros broyage/gros broyage) Donkey Mo Yangong); · Deuxièmement, la vie privée de l'utilisateur n'est pas respectée. Par conséquent, l’équipe de recherche a ajouté une couche de modèle génératif basée sur le codage utilisateur de l’ensemble de données d’origine. Considérant que les plateformes d'information sont toujours conçues avec une navigation par partition (finance, sports, technologie, etc.), et que le regroupement des utilisateurs dans diverses partitions est également évident, l'équipe de recherche a promu le modèle de mélange gaussien (GMM) comme étant responsable de cette tâche. Après avoir terminé le travail préliminaire de préparation des données, vous pouvez commencer à modéliser le comportement des utilisateurs. L'équipe de recherche a adopté la méthode Agent-based Modeling, qui consiste à modéliser le comportement des individus et les interactions entre individus, puis à simuler la dynamique du groupe en déployant un grand nombre d'Agents. Modélisation d'agent
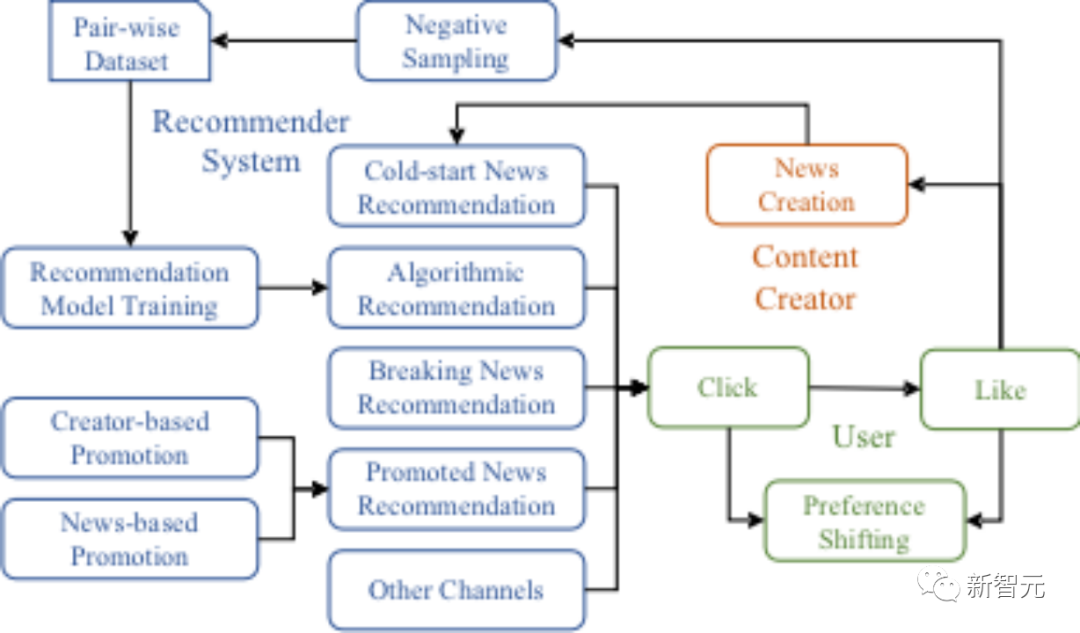
Rappelez-vous simplement le processus de lecture des actualités en ligne de l'utilisateur (par exemple, lorsque vous lisez Toutiao aujourd'hui), l'utilisateur verra d'abord une série d'actualités recommandées par le système de recommandation sur une certaine page, puis l'utilisateur parcourt simplement les titres, les images et les résumés de chaque actualité. Si une certaine actualité suscite l'intérêt de l'utilisateur, il cliquera pour voir ce qui est spécifiquement dit après avoir lu l'actualité, si l'utilisateur estime que cela l'intéresse. les nouvelles sont bonnes, méritent d'être lues ou correspondent à leurs propres opinions, les utilisateurs exprimeront leur accord avec les nouvelles par le biais de likes et d'autres méthodes.
Définition
Dans ce processus, l'interaction entre les utilisateurs et les actualités peut être divisée en trois niveaux (exposition, clics et likes), parmi lesquels les clics et les likes sont les comportements actifs des utilisateurs. être défini dans l'agent utilisateur.
Ici, l'équipe de recherche résume le comportement de clic de l'utilisateur comme un comportement de sélection probabiliste, c'est-à-dire basé sur la correspondance entre l'utilisateur et l'actualité (qui peut être mesurée par la similitude dans l'espace caché des deux), le l'utilisateur a une certaine probabilité. Sélectionnez des nouvelles qui vous intéressent dans la liste et cliquez pour lire.
Cette définition est plus flexible que de cliquer directement sur l'actualité la plus correspondante, c'est-à-dire qu'elle ne signifie pas nécessairement qu'un degré de correspondance élevé sera lu, et elle est plus conforme à la situation réelle.
En ce qui concerne le comportement des likes, nous ne pouvons pas simplement considérer le degré de correspondance de l'actualité. Après tout, comme nous le savons tous, le phénomène de gros titres est encore courant dans l'actualité.
Par conséquent, l'équipe de recherche a introduit un concept abstrait de « qualité des informations » pour représenter généralement la valeur d'un reportage d'actualité. De cette manière, le comportement similaire de l'utilisateur peut être caractérisé par un intérêt subjectif et une qualité objective.
L'équipe de recherche a adopté le modèle d'attente pour contrôler le comportement similaire de l'agent. Plus précisément, elle a d'abord calculé l'utilité (Utilité) d'un utilisateur lisant une certaine actualité en fonction du degré de correspondance d'intérêt et de la qualité de l'actualité. Si cet effet dépasse les attentes de l'utilisateur (l'équipe de recherche utilise un seuil d'hyperparamètre pour représenter la valeur spécifique de cette attente), ce qui déclenche le même comportement.
L'explication intuitive de ce design est que si une nouvelle me rend heureux, que ce soit parce qu'elle me plaît ou que le rapport lui-même est très objectif et complet , je le ferai, je le féliciterai sans hésitation.
De plus, lors du processus de lecture de l'actualité, les intérêts ou les opinions de l'utilisateur ne sont évidemment pas statiques.
Par exemple, si un utilisateur voit un reportage qu'il aime beaucoup, cela peut stimuler le désir de l'utilisateur d'approfondir l'actualité connexe. Au contraire, si. un reportage Le rapport donne aux utilisateurs le sentiment qu'il est complètement ridicule. Lorsque les utilisateurs verront des rapports similaires à l'avenir, ils seront moins susceptibles de cliquer dessus pour voir les détails du rapport.
Ce phénomène a été modélisé par l'équipe de recherche comme un modèle de dérive des préférences des utilisateurs (User-drift Model).
modélisation du comportement créatif#🎜 🎜 #
Ensuite, modélisez le comportement créatif des créateurs de nouvelles.
La création de nouvelles dans le monde réel sera affectée par divers facteurs. L'équipe de recherche la simplifie ici en un processus gourmand, ce que l'auteur espère toujours créer. Les nouvelles peuvent être reconnues par davantage de lecteurs.
L'équipe de recherche spécifique sur le contrôle du comportement des agents adopte un schéma similaire aux clics des utilisateurs. Les créateurs effectuent un échantillonnage probabiliste en fonction des goûts des actualités qu'ils ont créées lors du tour précédent. sélectionnez le thème pour un nouveau cycle de création, puis créez des actualités autour du thème. Le processus de création de nouvelles est modélisé de la même manière comme un processus d'échantillonnage à partir d'une distribution gaussienne thématique centrée dans l'espace latent.
En plus du contenu de l'actualité (représentation de l'espace latent), la qualité de l'actualité doit également être modélisée. Ceci est basé sur deux hypothèses de base qui sont conformes aux lois de la réalité :
1 Il existe une corrélation positive légèrement décroissante entre le nombre de likes qu'un auteur reçoit. et ses revenus, c'est-à-dire que l'auteur reçoit Plus vous recevez de likes, plus vous gagnez de lecture, mais à mesure que le nombre de likes augmente, les revenus d'un seul like diminueront progressivement ; Sur cette base, une fonction de cartographie du nombre de likes lors du tour précédent à la qualité des actualités du tour suivant peut être construite pour contrôler la qualité de la création d'actualités.
Modélisation du système de recommandation
#🎜 🎜 #Enfin, modélisez le comportement du système de recommandation.
La recommandation d'algorithme et la recommandation de démarrage à froid sont les deux composants de base du système de recommandation d'actualités. Afin de fournir des recommandations d'algorithmes personnalisées, le système de recommandation utilise d'abord des algorithmes de recommandation, tels que BPR, etc., pour apprendre la représentation des utilisateurs et des actualités dans l'espace d'intégration à partir des données d'interaction historiques (l'équipe de recherche utilise l'espace latent pour se référer au codage de modèle de langage à grande échelle Espace d'intérêt réel de l'utilisateur, utilisant l'espace d'intégration pour faire référence à l'espace appris par l'algorithme de recommandation et utilisé pour générer la liste de recommandations).Cependant, en raison de l'incertitude du comportement des utilisateurs et de la limitation de la fenêtre de validité des actualités, la recommandation de l'algorithme ne peut pas garantir de couvrir tous les utilisateurs pour cette partie du site. écart, vous pouvez simplement compléter avec des recommandations aléatoires.
En raison du manque d'enregistrements d'interactions historiques, les nouvelles nouvellement créées ne peuvent pas participer aux recommandations d'algorithmes. SimuLine applique des recommandations aléatoires et des algorithmes de recommandation heuristiques (tels que les créations historiquement appréciées Recommander à froid). lancer l'actualité à travers des stratégies telles que les nouveaux reportages de l'auteur).
De plus, SimuLine prend également en charge d'autres stratégies heuristiques de recommandation d'actualités, telles que les dernières nouvelles, la promotion basée sur les créateurs de contenu et la promotion basée sur des sujets, etc.
Toutes les stratégies de recommandation ont des quotas push indépendants, et le système de recommandation combine les recommandations d'actualités de toutes les chaînes pour former la liste de recommandations finale.
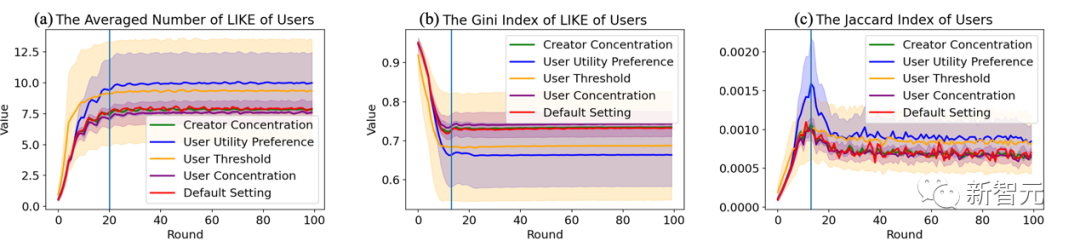
Les données sont en place ! Le modèle est construit ! Ce qui suit est une expérience passionnante ! L'équipe de recherche a sélectionné l'ensemble de données Adressa, largement utilisé dans le domaine de la recommandation d'actualités. Cet ensemble de données fournit les journaux Web complets du site d'information norvégien www.adressa.no pour une certaine semaine de février 2017. ainsi que d'excellentes données de recommandation d'actualités. Comparé à d'autres collections d'actualités (telles que MIND de Microsoft), il fournit de manière native des informations très critiques sur les auteurs d'actualités. En conséquence, le modèle linguistique utilise BPEmb, qui prend en charge nativement le norvégien. Pour plus de détails sur le déploiement, vous pouvez vous référer à la première section du chapitre 4 du document. Alors comment analyser les résultats de simulation de SimuLine ? SimuLine fournit un cadre d'analyse complet sous plusieurs perspectives pour votre référence. Le premier est le système d'évaluation d'indicateurs quantitatifs le plus couramment utilisé. Afin de refléter pleinement le processus d'évolution de l'écosystème de recommandation d'actualités, l'équipe de recherche a résumé les indicateurs quantitatifs apparus dans la littérature existante et a construit un système d'évaluation relativement complet à partir des cinq aspects suivants : 1 ) L'interactivité, y compris le nombre de likes et son indice Gini. Un indice Gini inférieur représente une meilleure équité 2) La couverture, y compris le nombre d'utilisateurs et l'actualité couverte par les recommandations de l'algorithme ; la qualité moyenne des actualités pendant le délai, la qualité moyenne des actualités pendant le délai pondérée par le nombre de likes, et le coefficient de corrélation de Pearson entre la qualité de l'actualité et le nombre de likes 4) Homogénéisation, dont Jaccard ; indice entre les utilisateurs, plus la valeur est élevée, plus le degré de chevauchement dans la lecture des actualités entre les utilisateurs est élevé ; 5) Degré de correspondance, y compris la similarité cosinusoïdale de représentation de l'espace latent entre les utilisateurs et leurs actualités préférées. 1. Cycle de vie Les trois images suivantes montrent respectivement les résultats de l'évaluation quantitative des utilisateurs, des créateurs et des systèmes de recommandation dans différentes conditions d'hyperparamètres d'agent. On peut voir que le processus de simulation et les résultats sont relativement stables sous divers hyper-paramètres, et approximativement au dixième tour et au vingtième Le tour est la ligne de démarcation (différents indicateurs fluctuent dans une certaine mesure), et l'évolution du système montre des étapes évidentes (les tours dans lesquels les transitions d'étape se produisent sont tracés avec des lignes verticales bleues sur la figure), ce qui est cohérent avec le théorie bien connue du cycle de vie. La première découverte a été faite à partir de ceci : Les communautés d'information en ligne pilotées par des systèmes de recommandation montrent naturellement un cycle de vie de "startup" - "croissance" - "maturité et déclin" sous différents groupes d'utilisateurs. 2. Différenciation des utilisateursExpérience de simulation
En plus des indicateurs quantitatifs, la visualisation est également un outil important pour aider à comprendre le processus d'évolution de la communauté. 
L'équipe de recherche a obtenu l'ensemble suivant d'instantanés du processus d'évolution du système grâce à la visualisation de réduction de dimensionnalité PCA (les nouvelles sont marquées en bleu, les utilisateurs avec des enregistrements similaires sont marqués en vert et les utilisateurs sans enregistrements similaires sont marqués en rouge. Nœud size Représente le nombre de likes/j'aime).

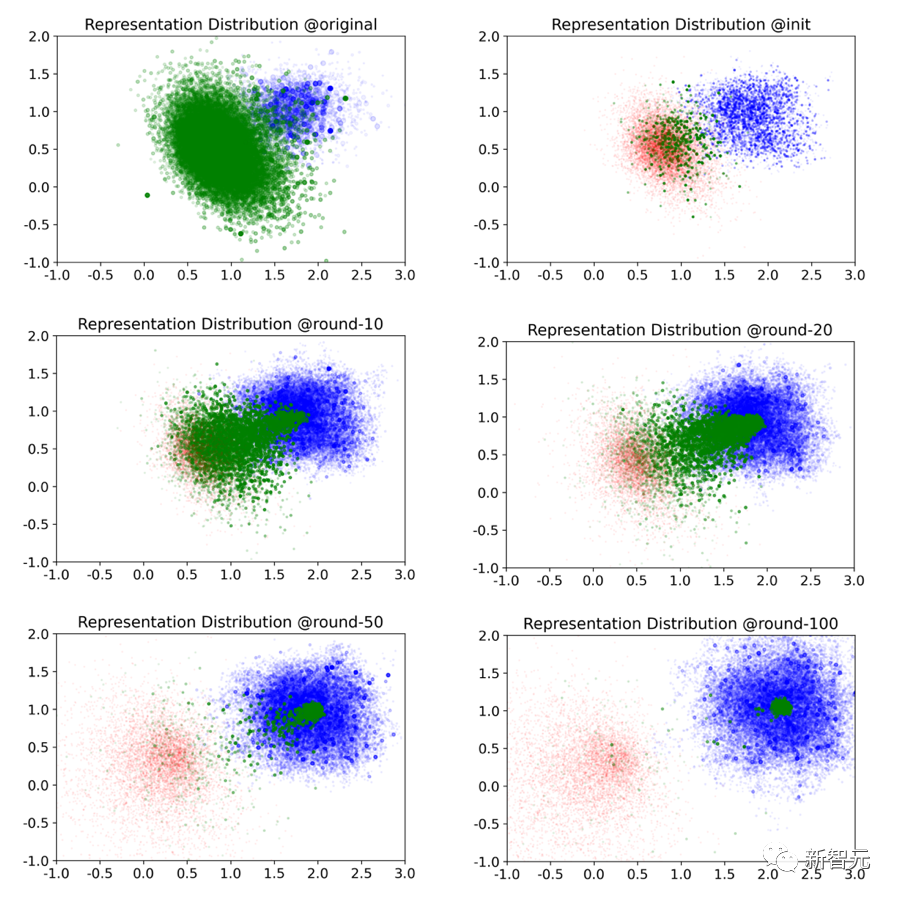
On peut constater que bien que les indicateurs quantitatifs montrent un modèle en plusieurs étapes, la tendance évolutive de la représentation de l'espace latent est cohérente, c'est-à-dire que les utilisateurs se différencient progressivement en utilisateurs du cercle (dans le - utilisateurs en boucle) et utilisateurs hors boucle.
Les utilisateurs du cercle forment une communauté stable avec des intérêts convergents, tandis que les utilisateurs en dehors du cercle présentent des intérêts dispersés.
Dans le processus d'évolution entre le 10e et le 20e tour, les utilisateurs ont pratiquement terminé la différenciation, ce qui montre que l'étape de croissance joue un rôle décisif dans la participation des utilisateurs.
Cela nous amène à la deuxième découverte : La communauté d'information en ligne pilotée par le système de recommandation produira inévitablement la convergence des sujets communautaires et conduira à la différenciation des utilisateurs. La période critique qui détermine la participation des utilisateurs est la phase de croissance.
3. Assimilation des intérêts
Comme mentionné ci-dessus, puisque SimuLine construit l'espace latent grâce à des modèles de langage de pré-formation à grande échelle, chaque vecteur dans l'espace peut être transmis grâce à la récupération de mots similaires pour l'interprétation de texte, qui permet de comprendre l'évolution des utilisateurs individuels à travers des études de cas.
L'équipe de recherche a sélectionné au hasard 3 utilisateurs respectivement parmi les utilisateurs du cercle et les utilisateurs hors cercle. Le tableau ci-dessous montre l'évolution de leurs intérêts.
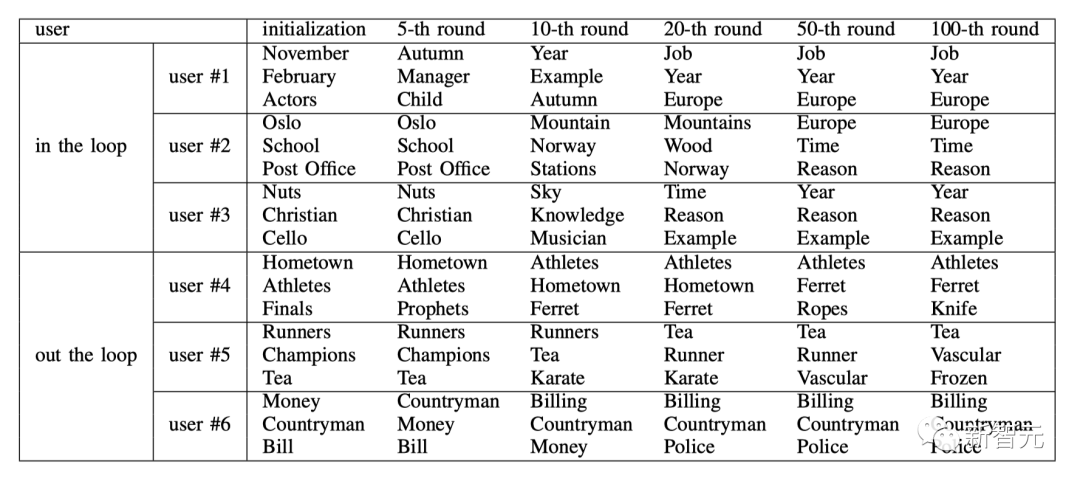
Pour les utilisateurs du cercle, leurs intérêts deviennent plus abstraits, larges et généraux, allant des "acteurs" au "travail", d'"Oslo" à la "Norvège" en passant par "l'Europe". " ». Les vitesses d'évolution des différents utilisateurs varient, mais elles convergent toutes vers le 50ème tour. Ce phénomène reflète la migration progressive des préférences des utilisateurs de sujets de niche personnalisés vers des sujets d'actualité largement discutés sur la plateforme grâce à une interaction continue avec le système de recommandation.
Pour les utilisateurs extérieurs au cercle, leurs intérêts changent légèrement, mais ils sont toujours concentrés sur des sujets précis et personnalisés. Par exemple, les utilisateurs n°4 et n°6 sont restés respectivement intéressés par « athlètes », « thé » et « factures » tout au long du processus de simulation.
Cela nous amène à la troisième découverte : Dans une communauté d'information en ligne pilotée par un système de recommandation, les intérêts personnalisés des utilisateurs sont assimilés au cours de l'interaction continue avec le système de recommandation.
4. Phase de démarrage
Avec l'aide des trois puissants outils ci-dessus d'indicateurs quantitatifs, de visualisation et de traduction de texte, SimuLine peut effectuer un examen physique complet du processus d'évolution du système. .
Étant donné que le processus d'évolution de la communauté d'information en ligne piloté par le système de recommandation est conforme à la théorie du cycle de vie, analysons comment la communauté évolue à chaque étape de la vie du point de vue du cycle de vie.
Tout d’abord, analysons la phase de démarrage qui correspond grosso modo aux 10 premiers tours.
Étant donné que le système est construit à partir de zéro, le système de recommandation manque de données pour entraîner l'algorithme de recommandation dans la phase initiale. En conséquence, à ce stade, l'utilisation de recommandations aléatoires et de recommandations heuristiques pour résoudre le problème de démarrage à froid de l'utilisateur est la priorité absolue.
En raison de l'incapacité d'utiliser des recommandations d'algorithmes plus précises, les résultats des recommandations à ce stade sont souvent insatisfaisants en termes de correspondance des intérêts. Par conséquent, le comportement similaire à ce stade est principalement dû à la qualité des informations, qui se reflète. dans les indicateurs quantitatifs. C'est la qualité. Forte corrélation positive avec la chaleur.
En allant plus loin, nous pouvons localiser les deux principaux moteurs de l'évolution d'une communauté au stade du démarrage :
1) Boucles de rétroaction de qualité (boucles de rétroaction de qualité), c'est-à-dire que la qualité et la popularité se favorisent mutuellement sur la base d'une corrélation positive. Autrement dit, plus la chose est bonne, plus les gens l'aimeront, et. plus les gens l'apprécieront. Plus les revenus de plusieurs auteurs sont élevés, plus les revenus de l'auteur sont élevés, plus ils sont motivés à produire des reportages de meilleure qualité ; jusqu'à ce que la quantité de données soit disponible pour estimer avec précision les intérêts des utilisateurs, les algorithmes de recommandation créeront de la confusion ; un comportement axé sur la qualité comme un comportement déclenché par l'intérêt de l'utilisateur. Ces deux forces motrices se favorisent mutuellement, permettant aux créateurs de contenu populaire d'obtenir une surexposition progressivement croissante (reflétée par la hausse de l'indice Gini des créateurs et des informations), et de réduire davantage la satisfaction des intérêts personnalisés des utilisateurs (reflétée par la diminution de l'utilisateur). la similarité spatiale latente entre ses actualités appréciées). Mais la plupart des utilisateurs peuvent toujours bénéficier d’une qualité d’information améliorée (reflétée par la diminution de l’indice Gini du comportement des utilisateurs).
Pour résumer, nous pouvons obtenir le quatrième résultat : Dans la phase de démarrage, le système accumule des informations pour estimer les intérêts des utilisateurs à partir de recommandations aléatoires et de haute qualité données d'actualités, résolvant ainsi le problème des utilisateurs de démarrage à froid. Les boucles de rétroaction sur la qualité et la confusion entre intérêts et qualité contribuent à l’émergence de créateurs de contenu extrêmement populaires par surexposition.
5. 🎜#
Avec l'accumulation de données, l'algorithme de recommandation estime les intérêts des utilisateurs de plus en plus précisément, et le comportement similaire passe progressivement d'un comportement axé sur la qualité à un comportement axé sur les intérêts, qualité et popularité La corrélation entre les diplômes s'affaiblit progressivement. À mesure que le nombre de tours de simulation augmente, les nouvelles créées pendant la période de démarrage expirent progressivement et se retirent des candidats à la recommandation. La confusion intérêt-qualité commence d'abord à se dissiper et conduit progressivement à la fin finale de la boucle de rétroaction sur la qualité.
En phase de croissance, la densité de l'actualité dans la zone utilisateur de chaque cercle est inégale. La densité est plus élevée dans le sens des sujets d'actualité grand public, tandis que la densité dans les autres directions est relativement faible.
Le résultat est que les actualités que les utilisateurs aiment sont statistiquement plus susceptibles d'être plus proches des sujets d'actualité grand public. Cette déviation subtile du comportement similaire continue d'apparaître et l'intérêt des utilisateurs. Sous l'effet de renforcement continu, il se rapproche progressivement des thèmes d'actualité dominants.
Au contraire, les utilisateurs en dehors du cercle sont tombés dans une impasse de "pas de likes - les recommandations de l'algorithme ne peuvent pas couvrir - une faible précision des recommandations - et encore moins de likes" . Ils apprécieront parfois l’actualité en raison de sa qualité, mais l’algorithme de recommandation ne peut pas accumuler suffisamment de données dans le délai imparti pour estimer leur intérêt. L'amélioration de la qualité des informations a été stimulée par des comportements de like plus fréquents et équilibrés, mais la qualité des informations pondérée par le nombre de likes est restée généralement stable à mesure que la popularité des informations de haute qualité diminuait.
Avec la fin de la boucle de rétroaction sur la qualité, les créateurs de contenu ne peuvent plus recevoir une attention excessive, ce qui entraîne une baisse de la qualité du journalisme. Les utilisateurs sensibles à la qualité peuvent cesser de l’apprécier, ce qui entraînera une baisse de la couverture utilisateur.
Pour résumer, on peut tirer le cinquième constat : En phase de croissance, les utilisateurs du cercle évoluent vers des sujets communs sous l'influence de l'écart de distribution , tandis que le cercle des utilisateurs externes est dans une impasse, conduisant à une différenciation des utilisateurs. Des recommandations d’algorithmes de plus en plus précises conduisent à la fin de la boucle de rétroaction sur la qualité, et la communauté perd ainsi certains utilisateurs sensibles à la qualité.
6. Étapes de maturité et de déclin.
Vers le tour 20, la communauté entre dans les étapes de maturité et de déclin, lorsque la plupart des indicateurs clés ont tendance à se stabiliser.
À ce stade, les utilisateurs du cercle restent dynamiquement dans la bulle de sujets communs, bien que leurs intérêts puissent se déplacer vers la bulle en cliquant sur différents bords d'actualité, mais ils reviennent rapidement au centre en raison des différences de densité.
L'indice Gini des likes pour les actualités est plus élevé, tandis que l'indice Gini des likes pour les créateurs de contenu est plus faible, ce qui indique que même les actualités créées par le même créateur sont plus populaires Il existe également de grandes différences de degré.
En plus du mécanisme de création gourmand, le processus de création de nouvelles lui-même est hautement aléatoire, de sorte que les bulles montrent également une tendance naturelle à se dilater.
La bulle en expansion amène des candidats à l'actualité plus diversifiés, et amène également certains utilisateurs sensibles au sujet à se retirer progressivement.
De là, nous pouvons tirer la sixième découverte : Dans les étapes de maturité et de déclin, les utilisateurs du cercle partagent des sujets communs et les créateurs de contenu publient autour de ceux-ci. sujets Actualités diverses. La communauté a maintenu une expansion stable et lente, mais en même temps elle a également perdu certains utilisateurs sensibles aux intérêts.
7. Comment se produit l'évolution ?
De découverte un à découverte six a répondu à la première question que l'équipe de recherche a payée attention à la question de recherche : quelles sont les caractéristiques de chaque étape du cycle de vie des écosystèmes de recommandation d'actualités (NRE) ?
Rassemblons toutes les connaissances et essayons de répondre à la deuxième question de recherche : Quels sont les facteurs clés à l'origine de l'évolution des NRE, et comment ces facteurs interagissent-ils avec chacun d'entre eux ? autre ? Influencer le processus évolutif ?
La figure suivante résume les facteurs clés et les mécanismes d'influence de l'évolution des communautés d'information en ligne. On peut en déduire la réémergence des biais d'exposition et des mécanismes d'influence. Les impasses sont les principaux facteurs qui conduisent les utilisateurs à entrer dans le cercle. C'est la raison directe des différentes tendances d'évolution des utilisateurs en dehors du cercle, et cela conduit en outre à la différenciation des utilisateurs et à la convergence des sujets.
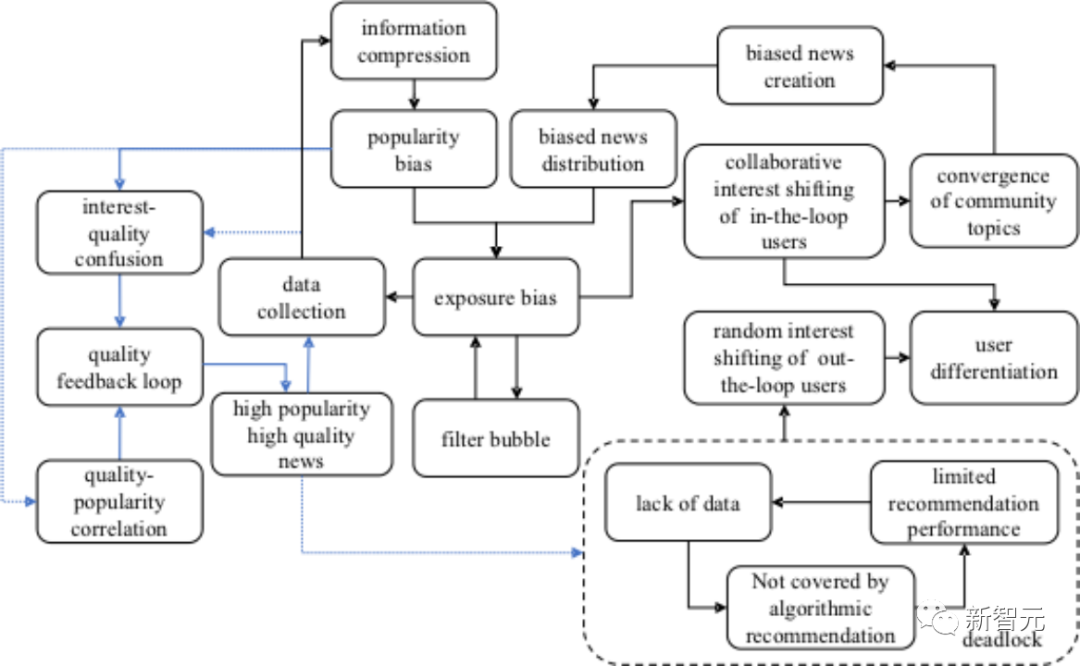
Le biais d'exposition réémergent est causé par une combinaison de facteurs.
Tout d'abord, du point de vue de la théorie de l'information, l'algorithme de recommandation peut être expliqué comme un processus de compression de l'information, qui conduit inévitablement à un biais de popularité, dans lequel un fréquence dans l'ensemble de données. Les actualités qui apparaissent (c'est-à-dire les actualités avec le plus de likes) sont codées plus efficacement pour améliorer les performances des recommandations. Reflété dans le processus d'évolution de la communauté, il se reflète que des sujets communs largement discutés saisiront les ressources d'exposition de sujets personnalisés sur les canaux de recommandation d'algorithmes.
Deuxièmement, en raison de la nature à but lucratif des créateurs de contenu, ils sont plus motivés à créer des actualités autour de sujets d'intérêt public, ce qui entraînera naturellement un changement dans la densité des communiqués du public Le sujet est réduit à un sujet personnalisé. En ce sens, même si des recommandations aléatoires sont utilisées tout au long du processus, la communauté peut évoluer dans le sens d’une convergence thématique en raison des écarts de distribution.
Enfin, les bulles de filtre et les biais d'exposition se favorisent mutuellement, ce qui conduit ensemble à un changement subtil dans l'intérêt des utilisateurs. L'algorithme recommande des rapports similaires basés sur les actualités que les utilisateurs ont appréciées dans l'histoire. L'exposition limitée aux actualités rend le biais d'exposition plus difficile à percevoir pour les utilisateurs.
De plus, le biais du système de recommandation en faveur des informations populaires montre des impacts différents selon les stades d'évolution.
Au stade du démarrage, il existe une confusion entre l'intérêt et la qualité, il existe une forte corrélation entre la qualité de l'information et la popularité, et le biais de popularité se reflète spécifiquement dans l'exposition de nouvelles d'amélioration de haute qualité.
Avec l'accumulation de données et l'amélioration des performances de recommandation des algorithmes, le comportement est de plus en plus motivé par l'intérêt plutôt que par la qualité, affaiblissant ainsi l'intérêt-qualité Confusion et qualité -corrélations de popularité. Le biais de popularité a également progressivement évolué, passant de la recommandation d’informations de haute qualité à la simple recommandation d’informations très populaires.
Dans ce processus de conversion de l'ancien et du nouvel élan, cultiver des sujets d'actualité très populaires et de haute qualité joue un rôle important dans la promotion de la participation des utilisateurs.
Pour résumer, nous pouvons obtenir le septième résultat : Les biais populaires, les biais de distribution d'informations et les bulles de filtrage conduisent conjointement à un biais d'exposition, qui affecte les différences entre les utilisateurs . isation et convergence thématique. Des informations de haute qualité et très populaires sont essentielles pour sortir de l’impasse parmi les utilisateurs extérieurs au cercle.
8.
Enfin, explorez davantage à l'aide des puissantes capacités de simulation et d'analyse de SimuLine. Troisième question de recherche d'Ichiban : Comment obtenir une meilleure efficacité multipartite à long terme grâce à la stratégie de conception du système de recommandation, évitant ainsi que la communauté ne tombe dans le « déclin » ?
L'équipe de recherche a testé quatre des méthodes de recommandation heuristiques les plus élémentaires et les plus courantes : démarrage à froid des actualités par abonnement, liste de recherche rapide, promotion de sujets et promotion de créateurs. Les trois figures suivantes présentent les résultats de l'évolution de la communauté suite à l'application des quatre méthodes ci-dessus sur le système de recommandation de base.
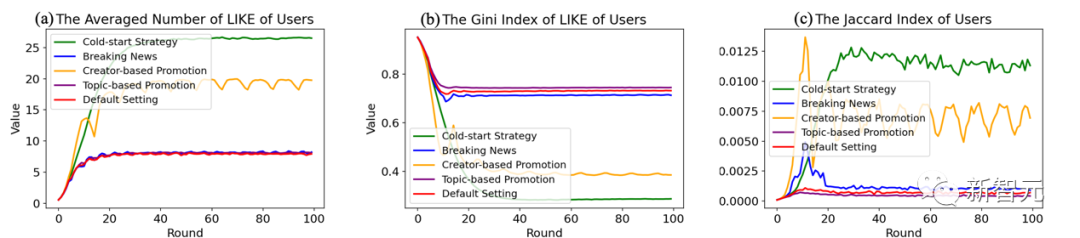


(1) Le démarrage à froid des informations par abonnement tente de former une roue croisée stable entre les utilisateurs et les créateurs de contenu Expose relations, améliorant ainsi la boucle de rétroaction sur la qualité qui se produit pendant la phase de démarrage.
Mais cette approche conduit à un sérieux monopole, et les créateurs de contenu qui ne bénéficient pas des avantages du premier arrivé sont supprimés par des boucles de rétroaction de qualité, détruisant la couverture des algorithmes et l'actualité. La qualité moyenne de l’environnement a gravement mis à rude épreuve la diversité écologique de l’ensemble de la communauté.
(2) La liste de recherche dynamique est le composant de communauté en ligne le plus courant. Elle repose sur la corrélation positive entre la qualité des informations et la popularité. Cette méthode peut offrir aux utilisateurs une qualité supérieure. recommandations de nouvelles. Dans le même temps, du point de vue de l'exploitation et de l'exploration, la lecture des dernières nouvelles peut également être considérée comme une sorte d'exploration de l'utilisateur qui dépasse les limites des intérêts existants de l'utilisateur, ce qui contribue à réduire l'impact négatif des bulles de filtre.
Cependant, cette approche ne peut empêcher l'effondrement de la corrélation entre popularité et qualité évoquée dans l'article précédent, ce qui entraînera une diminution de l'efficacité de la recommandation des dernières nouvelles. .
(3) Enfin, il y a la promotion de la plateforme en offrant une visibilité supplémentaire à des sujets ou à des auteurs spécifiques, la plateforme peut également réguler activement le contenu recommandé. La promotion des créateurs de contenu peut établir une relation d'exposition stable, puis utiliser une boucle de rétroaction de qualité pour cultiver des informations de haute qualité avec une grande popularité.
Mais contrairement à la stratégie de démarrage à froid des informations par abonnement, la promotion peut être activement interrompue avant que la boucle de rétroaction actuelle sur la qualité ne cultive un monopole néfaste, protégeant ainsi l'expérience des utilisateurs et la créativité du créateur. . En tant que canal de diffusion d’informations indépendant de la correspondance des intérêts, il peut également atténuer les effets négatifs des bulles de filtrage. De plus, en reconstruisant la boucle de rétroaction sur la qualité, cela oriente également le biais du système de recommandation en faveur des informations populaires vers des recommandations bénéfiques vers des informations de haute qualité.
SimuLine sélectionne au hasard des sujets dans des expériences ciblant la promotion d'un sujet spécifique, ce qui signifie que les sujets populaires et les sujets personnalisés ont la même chance d'être promus, donc l'exposition est relativement inférieure sujets personnalisés, l'impact de la promotion est relativement plus important.
Cette méthode peut théoriquement être utilisée pour augmenter la participation des utilisateurs en dehors du cercle, mais comme la qualité des informations promues ne peut être garantie, le degré d'exposition est difficile à déterminer convertir en nombre de likes. Cela se traduit par une efficacité limitée de la méthode.
Pour résumer, nous pouvons obtenir le huitième résultat : Parmi les stratégies courantes de conception de systèmes de recommandation, la promotion périodique pour les créateurs de contenu est la plus efficace. En créant activement une boucle de rétroaction de qualité, elle peut créer des vagues de sujets d'actualité populaires et de haute qualité dans toute la communauté, tandis que la plateforme peut contrôler le monopole grâce à des réinitialisations régulières.
RésuméDans cet article, l'équipe de recherche du CISL a conçu et développé une méthode d'analyse de l'évolution de la recommandation d'actualité SimuLine, une plateforme de simulation de processus, et a mené une analyse détaillée du processus d'évolution des communautés d'information en ligne basées sur SimuLine.
SimuLine construit un espace latent compréhensible qui reflète bien le comportement humain et, sur cette base, effectue une modélisation basée sur des agents sur l'écosystème de recommandation d'actualités.
L'équipe de recherche a analysé l'ensemble du cycle de vie de l'évolution des communautés d'information en ligne, y compris les étapes de démarrage, de croissance, de maturité et de déclin, et a analysé les caractéristiques de chaque étape, tout en proposant un diagramme de relations pour illustrer le facteurs clés du processus d’évolution et mécanismes d’influence.
Enfin, l'équipe de recherche a exploré l'impact des stratégies de conception de systèmes de recommandation sur l'évolution de la communauté, y compris l'utilisation du démarrage à froid des actualités par abonnement, des actualités brûlantes et de la promotion de la plateforme.
À l'avenir, l'équipe de recherche du CISL envisagera la génération de contenu textuel d'actualités et la modélisation comportementale des activités des réseaux sociaux pour mener des simulations plus puissantes et plus réalistes.
L'équipe de recherche estime que SimuLine peut également être utilisé comme un excellent outil d'évaluation du système de recommandation, offrant une troisième option en plus des expériences utilisateur en ligne et des expériences hors ligne basées sur des ensembles de données. (C'est aussi la principale raison pour laquelle il a été nommé SimuLine).
L'équipe de recherche a également remarqué que la récente communauté de recherche sur les systèmes de recommandation a également proposé une série d'algorithmes de recommandation de correction des biais, visant à résoudre le problème du biais d'exposition dans les recommandations. , ce qui est également une différenciation des utilisateurs et la cause directe de la convergence des sujets.
Étant donné que cet article se concentre sur la conception du système de recommandation plutôt que sur l'algorithme de recommandation spécifique, l'équipe de recherche laisse cette question comme un sujet ouvert et espère que SimuLine peut faciliter les recherches futures dans cette direction.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 La différence entre le langage C et Python
La différence entre le langage C et Python
 Le numéro virtuel reçoit le code de vérification
Le numéro virtuel reçoit le code de vérification
 utilisation de la commande telnet
utilisation de la commande telnet
 Quels sont les opérateurs en langage Go ?
Quels sont les opérateurs en langage Go ?
 JAXB
JAXB
 Comment laisser deux espaces vides dans un paragraphe en HTML
Comment laisser deux espaces vides dans un paragraphe en HTML
 Que signifie généralement une extension de fichier ?
Que signifie généralement une extension de fichier ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



