
 Périphériques technologiques
IA
L'algorithme vidéo « suivre tout » qui suit chaque pixel à tout moment, n'importe où, et n'a même pas peur des obstacles, est là.
Périphériques technologiques
IA
L'algorithme vidéo « suivre tout » qui suit chaque pixel à tout moment, n'importe où, et n'a même pas peur des obstacles, est là.
L'algorithme vidéo « suivre tout » qui suit chaque pixel à tout moment, n'importe où, et n'a même pas peur des obstacles, est là.

Il y a quelque temps, Meta a publié le modèle d'IA "Segment Everything (SAM)", qui peut générer un masque pour n'importe quel objet dans n'importe quelle image ou vidéo, provoquant des chercheurs dans le domaine de la vision par ordinateur (CV) s'exclamer : "Le CV n'existe plus." Ensuite, il y a eu une vague de « création secondaire » dans le domaine du CV. Certains travaux ont successivement combiné des fonctions telles que la détection de cibles et la génération d'images sur la base de la segmentation, mais l'essentiel des recherches s'est basé sur des images statiques. Aujourd'hui, une nouvelle étude intitulée « Tracking Everything » propose une nouvelle méthode d'estimation du mouvement dans les vidéos dynamiques, qui permet de suivre avec précision et complètement le mouvement des objets. L'étude Il a été réalisé par des chercheurs de l'Université Cornell, de Google Research et de l'UC Berkeley. Ils ont proposé conjointement OmniMotion, une représentation de mouvement complète et globalement cohérente, et ont proposé une nouvelle méthode d'optimisation du temps de test pour effectuer une estimation précise et complète du mouvement pour chaque pixel de la vidéo.

Page d'accueil du projet : https://omnimotion.github.io/
# 🎜🎜#
- À en juger par la démo publiée par l'étude, l'effet du suivi de mouvement est très efficace, par exemple, pour suivre la trajectoire de mouvement d'un kangourou sauteur : : #🎜🎜 #
Vous pouvez également visualiser de manière interactive l'état du suivi sportif : #🎜🎜 #

La piste de mouvement peut être suivie même si l'objet est bloqué, comme un chien être bloqué par un arbre en courant :

Dans le domaine de la vision par ordinateur, il existe deux estimations de mouvement couramment utilisées méthodes : suivi de caractéristiques clairsemées et flux optique dense. Cependant, les deux méthodes ont leurs propres inconvénients. Le suivi de caractéristiques éparses ne peut pas modéliser le mouvement de tous les pixels ; un flux optique dense ne peut pas capturer les trajectoires de mouvement pendant une longue période.
L'OmniMotion proposé dans cette étude utilise un volume canonique quasi-3D pour représenter la vidéo, et pour chaque pixel à travers une bijection entre espace local et espace canonique de suivi. Cette représentation permet une cohérence globale, permet le suivi de mouvement même lorsque les objets sont masqués et modélise toute combinaison de mouvement de caméra et d'objet. Cette étude démontre expérimentalement que la méthode proposée surpasse considérablement les méthodes SOTA existantes.

Présentation de la méthode
Cette étude prend en entrée une collection d'images avec des estimations de mouvement bruyantes appariées (par exemple, des champs de flux optique) pour former une représentation de mouvement complète et globalement cohérente de l'ensemble de la vidéo. L'étude a ensuite ajouté un processus d'optimisation qui lui a permis d'interroger la représentation avec n'importe quel pixel dans n'importe quelle image pour produire des trajectoires de mouvement fluides et précises tout au long de la vidéo. Notamment, cette méthode peut identifier quand des points du cadre sont obscurcis et peut même suivre des points via des occlusions.
Caractérisation OmniMotion
Les méthodes traditionnelles d'estimation de mouvement (telles que le flux optique par paire) perdront le suivi des objets lorsqu'ils sont obstrués. Afin de fournir des trajectoires de mouvement précises et cohérentes même sous occlusion, cette étude propose une représentation globale du mouvement OmniMotion.
Cette recherche tente de suivre avec précision le mouvement du monde réel sans reconstruction 3D dynamique explicite. La représentation OmniMotion représente la scène dans la vidéo sous la forme d'un volume 3D canonique, qui est mappé à un volume local dans chaque image via une bijection canonique locale. Les bijections canoniques locales sont paramétrées comme des réseaux de neurones et capturent le mouvement de la caméra et de la scène sans séparer les deux. Sur la base de cette approche, la vidéo peut être visualisée comme le résultat du rendu à partir du volume local d'une caméra statique fixe.
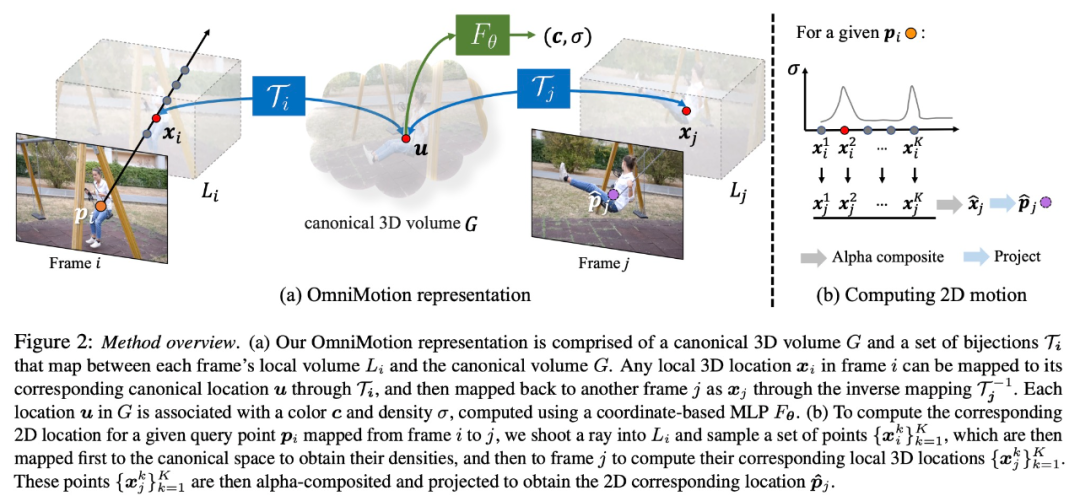
Comme OmniMotion ne fait pas clairement la distinction entre le mouvement de la caméra et celui de la scène, la représentation formée n'est pas une reconstruction de scène 3D physiquement précise. C’est pourquoi l’étude parle de caractérisation quasi-3D.
OmniMotion conserve des informations sur tous les points de la scène projetés sur chaque pixel, ainsi que leur ordre de profondeur relatif, ce qui permet de suivre les points du cadre même s'ils sont temporairement masqués.

Expériences et résultats
Comparaison quantitative
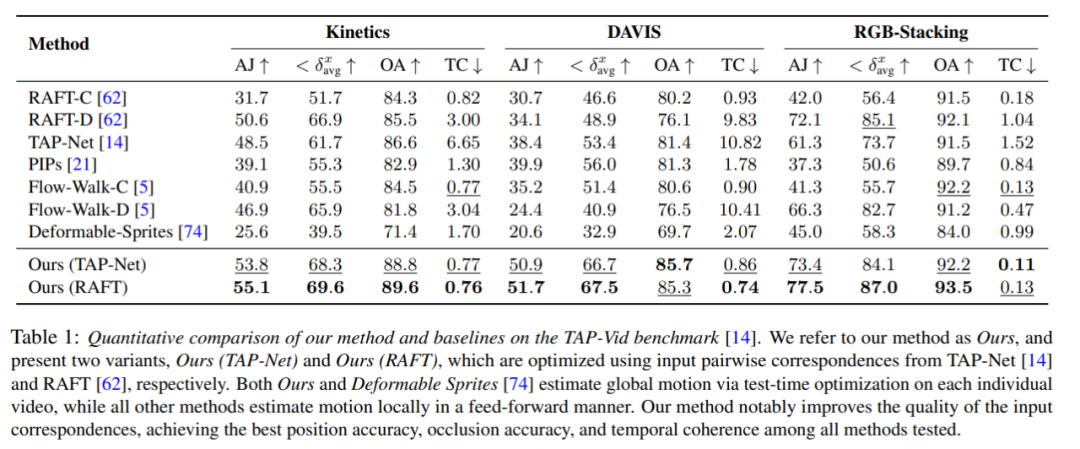
Les chercheurs ont comparé la méthode proposée avec le benchmark TAP-Vid, et les résultats sont présentés dans le tableau 1. On peut constater que sur différents ensembles de données, leur méthode permet toujours d’obtenir la meilleure précision de position, d’occlusion et de cohérence temporelle. Leur méthode gère bien les différentes entrées de correspondance par paire de RAFT et TAP-Net et apporte des améliorations cohérentes par rapport aux deux méthodes de base.
Comparaison qualitative
Comme le montre la figure 3, les chercheurs ont effectué une comparaison qualitative entre leur méthode et la méthode de base. La nouvelle méthode présente d'excellentes capacités de reconnaissance et de suivi lors d'événements d'occlusion (longs), tout en fournissant des positions raisonnables pour les points pendant les occlusions et en gérant une grande parallaxe de mouvement de caméra.

Expériences et analyses d'ablation
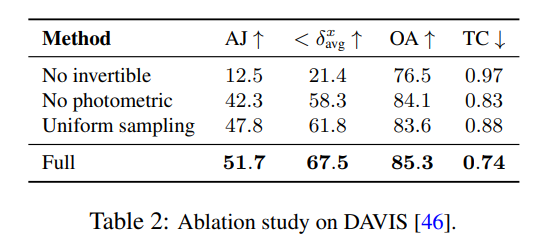
Les chercheurs ont utilisé des expériences d'ablation pour vérifier l'efficacité de leurs décisions de conception, et les résultats sont présentés dans le tableau 2.
Dans la figure 4, ils montrent des cartes de pseudo-profondeur générées par leur modèle pour démontrer le classement de profondeur appris.

Il est important de noter que ces chiffres ne correspondent pas à la profondeur physique, mais ils démontrent que la nouvelle méthode est capable de déterminer efficacement l'ordre relatif entre différentes surfaces en utilisant uniquement des signaux de flux photométriques et optiques, ce qui est utile pour le suivi dans occlusions Cruciales. D’autres expériences d’ablation et des résultats analytiques peuvent être trouvés dans le matériel supplémentaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Où sont stockés les fichiers vidéo dans le cache du navigateur ?
Feb 19, 2024 pm 05:09 PM
Dans quel dossier le navigateur met-il la vidéo en cache ? Lorsque nous utilisons le navigateur Internet quotidiennement, nous regardons souvent diverses vidéos en ligne, comme regarder des clips vidéo sur YouTube ou regarder des films sur Netflix. Ces vidéos seront mises en cache par le navigateur pendant le processus de chargement afin qu'elles puissent être chargées rapidement lors d'une nouvelle lecture ultérieure. La question est donc de savoir dans quel dossier ces vidéos mises en cache sont réellement stockées ? Différents navigateurs stockent les dossiers vidéo mis en cache à différents emplacements. Ci-dessous, nous présenterons plusieurs navigateurs courants et leurs
 Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Avec l'essor des plateformes de vidéos courtes, Douyin est devenu un élément indispensable de la vie quotidienne de chacun. Sur TikTok, nous pouvons voir des vidéos intéressantes du monde entier. Certaines personnes aiment publier les vidéos d’autres personnes, ce qui soulève une question : Douyin enfreint-il la publication de vidéos d’autres personnes ? Cet article abordera ce problème et vous expliquera comment éditer des vidéos sans infraction et comment éviter les problèmes d'infraction. 1. Cela porte-t-il atteinte à la publication par Douyin de vidéos d'autres personnes ? Selon les dispositions de la loi sur le droit d'auteur de mon pays, l'utilisation non autorisée des œuvres du titulaire du droit d'auteur sans l'autorisation du titulaire du droit d'auteur constitue une infraction. Par conséquent, publier des vidéos d’autres personnes sur Douyin sans l’autorisation de l’auteur original ou du titulaire des droits d’auteur constitue une infraction. 2. Comment monter une vidéo sans contrefaçon ? 1. Utilisation de contenu du domaine public ou sous licence : Public
 Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer le filigrane vidéo dans Wink
Feb 23, 2024 pm 07:22 PM
Comment supprimer les filigranes des vidéos dans Wink ? Il existe un outil pour supprimer les filigranes des vidéos dans winkAPP, mais la plupart des amis ne savent pas comment supprimer les filigranes des vidéos dans Wink. Voici ensuite l'image de la façon de supprimer les filigranes des vidéos dans Wink. apporté par l'éditeur Tutoriel texte, les utilisateurs intéressés viennent y jeter un oeil ! Comment supprimer le filigrane vidéo dans Wink 1. Ouvrez d'abord l'application Wink et sélectionnez la fonction [Supprimer le filigrane] dans la zone de la page d'accueil ; 2. Sélectionnez ensuite la vidéo dont vous souhaitez supprimer le filigrane dans l'album ; dans le coin supérieur droit après avoir édité la vidéo [√] ; 4. Enfin, cliquez sur [Imprimer en un clic] comme indiqué dans la figure ci-dessous, puis cliquez sur [Traiter].
 Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Douyin, la plateforme nationale de courtes vidéos, nous permet non seulement de profiter d'une variété de courtes vidéos intéressantes et originales pendant notre temps libre, mais nous donne également une scène pour nous montrer et réaliser nos valeurs. Alors, comment gagner de l’argent en postant des vidéos sur Douyin ? Cet article répondra à cette question en détail et vous aidera à gagner plus d’argent sur TikTok. 1. Comment gagner de l’argent en publiant des vidéos sur Douyin ? Après avoir posté une vidéo et obtenu un certain nombre de vues sur Douyin, vous aurez la possibilité de participer au plan de partage publicitaire. Cette méthode de revenus est l’une des plus connues des utilisateurs de Douyin et constitue également la principale source de revenus pour de nombreux créateurs. Douyin décide d'offrir ou non des opportunités de partage de publicités en fonction de divers facteurs tels que le poids du compte, le contenu vidéo et les commentaires du public. La plateforme TikTok permet aux téléspectateurs de soutenir leurs créateurs préférés en envoyant des cadeaux,
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
 2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
Sur les appareils iOS, l'application Appareil photo vous permet de filmer des vidéos au ralenti, voire à 240 images par seconde si vous possédez le dernier iPhone. Cette capacité vous permet de capturer une action à grande vitesse avec des détails riches. Mais parfois, vous souhaiterez peut-être lire des vidéos au ralenti à vitesse normale afin de mieux apprécier les détails et l'action de la vidéo. Dans cet article, nous expliquerons toutes les méthodes pour supprimer le ralenti des vidéos existantes sur iPhone. Comment supprimer le ralenti des vidéos sur iPhone [2 méthodes] Vous pouvez utiliser l'application Photos ou l'application iMovie pour supprimer le ralenti des vidéos sur votre appareil. Méthode 1 : ouvrir sur iPhone à l’aide de l’application Photos
 Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Avec l'essor des plateformes de vidéos courtes, Xiaohongshu est devenue une plateforme permettant à de nombreuses personnes de partager leur vie, de s'exprimer et de gagner du trafic. Sur cette plateforme, la publication d’œuvres vidéo est un moyen d’interaction très prisé. Alors, comment publier les œuvres vidéo de Xiaohongshu ? 1. Comment publier les œuvres vidéo de Xiaohongshu ? Tout d’abord, assurez-vous d’avoir un contenu vidéo prêt à partager. Vous pouvez utiliser votre téléphone portable ou un autre équipement photo pour prendre des photos, mais vous devez faire attention à la qualité de l'image et à la clarté du son. 2. Editer la vidéo : Afin de rendre le travail plus attrayant, vous pouvez éditer la vidéo. Vous pouvez utiliser un logiciel de montage vidéo professionnel, tel que Douyin, Kuaishou, etc., pour ajouter des filtres, de la musique, des sous-titres et d'autres éléments. 3. Choisissez une couverture : La couverture est la clé pour inciter les utilisateurs à cliquer. Choisissez une image claire et intéressante comme couverture pour inciter les utilisateurs à cliquer dessus.
 Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment convertir des vidéos téléchargées par le navigateur UC en vidéos locales
Feb 29, 2024 pm 10:19 PM
Comment transformer les vidéos téléchargées par le navigateur UC en vidéos locales ? De nombreux utilisateurs de téléphones mobiles aiment utiliser UC Browser. Ils peuvent non seulement naviguer sur le Web, mais également regarder diverses vidéos et programmes télévisés en ligne et télécharger leurs vidéos préférées sur leurs téléphones mobiles. En fait, nous pouvons convertir des vidéos téléchargées en vidéos locales, mais beaucoup de gens ne savent pas comment le faire. Par conséquent, l'éditeur vous propose spécialement une méthode pour convertir les vidéos mises en cache par le navigateur UC en vidéos locales. J'espère que cela pourra vous aider. Méthode pour convertir les vidéos mises en cache du navigateur uc en vidéos locales 1. Ouvrez le navigateur uc et cliquez sur l'option "Menu". 2. Cliquez sur « Télécharger/Vidéo ». 3. Cliquez sur « Vidéo mise en cache ». 4. Appuyez longuement sur n'importe quelle vidéo, lorsque les options apparaissent, cliquez sur « Ouvrir le répertoire ». 5. Cochez ceux que vous souhaitez télécharger
