

Le guide d'utilisation officiel de GPT-4 est maintenant disponible !
Vous avez bien entendu, vous n'avez pas besoin de prendre des notes vous-même cette fois, OpenAI en a personnellement organisé une pour vous.
On dit que les 6 mois d'expérience d'utilisation de chacun ont été rassemblés et que les trucs et astuces de vous, moi et lui y sont tous intégrés.
Bien qu'en résumé il n'y ait que six stratégies majeures, les détails ne doivent pas être vagues.
Non seulement les utilisateurs ordinaires de GPT-4 peuvent obtenir des trucs et astuces dans ce livre de triche, mais peut-être que les développeurs d'applications peuvent également trouver de l'inspiration.
Les internautes ont commenté les uns après les autres et ont donné leurs propres "réflexions après lecture" :
Tellement intéressant ! En résumé, les idées fondamentales de ces techniques comprennent deux points principaux. Tout d’abord, nous devons écrire plus précisément et donner quelques conseils détaillés. Deuxièmement, pour ces tâches complexes, nous pouvons les diviser en petites invites à accomplir.

OpenAI a déclaré que ce guide concerne actuellement uniquement GPT-4. (Bien sûr, vous pouvez également l'essayer sur d'autres modèles GPT ?)
Dépêchez-vous et jetez un œil pour voir quelles sont les bonnes choses de cette aide-mémoire.

Vous devez savoir que le modèle ne peut pas « lire dans les pensées », vous devez donc écrire clairement vos exigences.
Lorsque le résultat du modèle devient trop verbeux, vous pouvez lui demander de répondre de manière concise et claire. À l’inverse, si le résultat est trop simple, vous pouvez sans aucune hésitation demander qu’il soit rédigé à un niveau professionnel.
Si vous n'êtes pas satisfait du format de sortie GPT, montrez-lui d'abord le format que vous attendez et demandez-lui de sortir de la même manière.
En bref, essayez de ne pas laisser le modèle GPT deviner par lui-même vos intentions, afin que les résultats que vous obtenez soient plus susceptibles de répondre à vos attentes.
Conseils pratiques :
1. Ce n'est qu'avec des détails que vous pouvez obtenir des réponses plus pertinentes
Afin que la sortie et l'entrée aient une forte corrélation, toutes les informations détaillées importantes peuvent être transmises au modèle.
Par exemple, si vous souhaitez que GPT-4 : résume le procès-verbal de la réunion
, vous pouvez ajouter autant de détails que possible à la déclaration :
Résumez le procès-verbal de la réunion dans un paragraphe de texte. Rédigez ensuite une liste Markdown répertoriant les participants et leurs principaux points. Enfin, si les participants ont des suggestions sur les prochaines étapes, énumérez-les.
2. Demandez au modèle de jouer un rôle spécifique
En modifiant le message système, GPT-4 jouera plus facilement un rôle spécifique et le prendra plus au sérieux que de le demander dans une conversation.
S'il est spécifié de répondre à un fichier, chaque paragraphe du fichier doit contenir des commentaires intéressants :
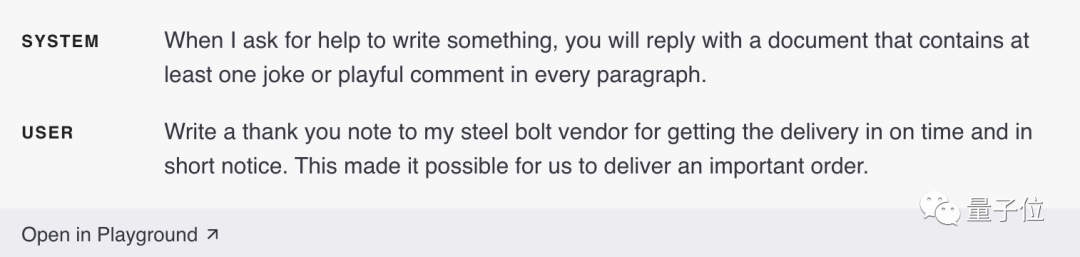
3. Utilisez des séparateurs pour marquer clairement les différentes parties de l'entrée
Utilisez des délimiteurs "" tels que car les "guillemets triples""",

4. Précisez clairement les étapes requises pour terminer la tâche
Certaines tâches sont plus efficaces si elles sont effectuées étape par étape. Par conséquent, il est préférable de spécifier clairement une série d’étapes afin que le modèle puisse les suivre plus facilement et produire les résultats souhaités. Par exemple, définissez les étapes à suivre pour répondre dans le message système.
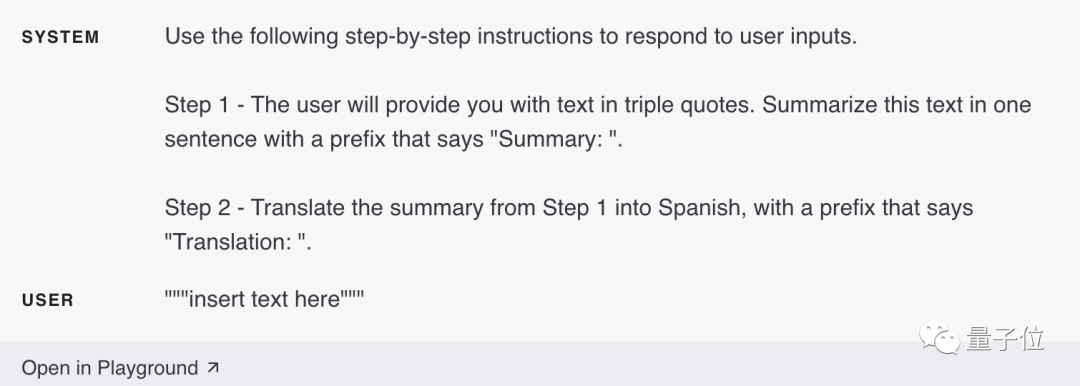
5. Fournissez des exemples
Si vous souhaitez que la sortie du modèle suive un style spécifique qui n'est pas bien décrit, vous pouvez fournir des exemples. Par exemple, après avoir fourni un exemple, il vous suffit de lui dire « apprenez-moi la patience » et il le décrira de manière vivante selon le style de l'exemple.
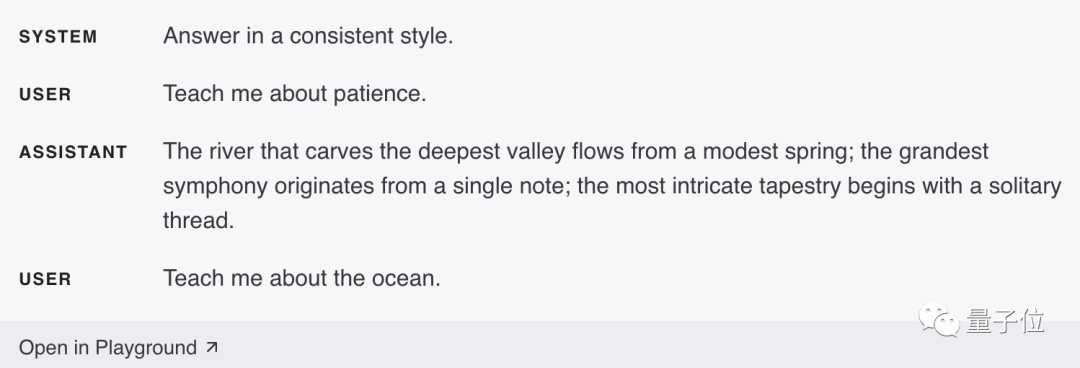
6. Spécifiez la longueur de sortie requise
Vous pouvez également demander au modèle de générer spécifiquement le nombre de mots, de phrases, de paragraphes, de puces, etc. Cependant, lorsqu'il est demandé au modèle de générer un nombre spécifique de mots/caractères, il peut ne pas être aussi précis.
Quand il s'agit de sujets ésotériques, de citations, d'URL, etc., le modèle GPT peut sérieusement dire des bêtises.
Fournissez un texte de référence pour GPT-4, ce qui peut réduire l'apparition de réponses fictives et rendre le contenu des réponses plus fiable.
Conseils pratiques :
1. Laissez le modèle répondre en référence aux matériaux de référence
#🎜 🎜#Si nous pouvons fournir au modèle des informations crédibles liées à la question, nous pouvons lui demander d'utiliser les informations fournies pour organiser la réponse.
2. 🎜🎜#Si des informations pertinentes ont été complétées dans la saisie de dialogue ci-dessus, nous pouvons également demander directement au modèle de citer les informations fournies dans la réponse. Il est à noter ici que le modèle peut être programmé pour vérifier les pièces référencées dans la sortie.
Stratégie 3 : Diviser les tâches complexes 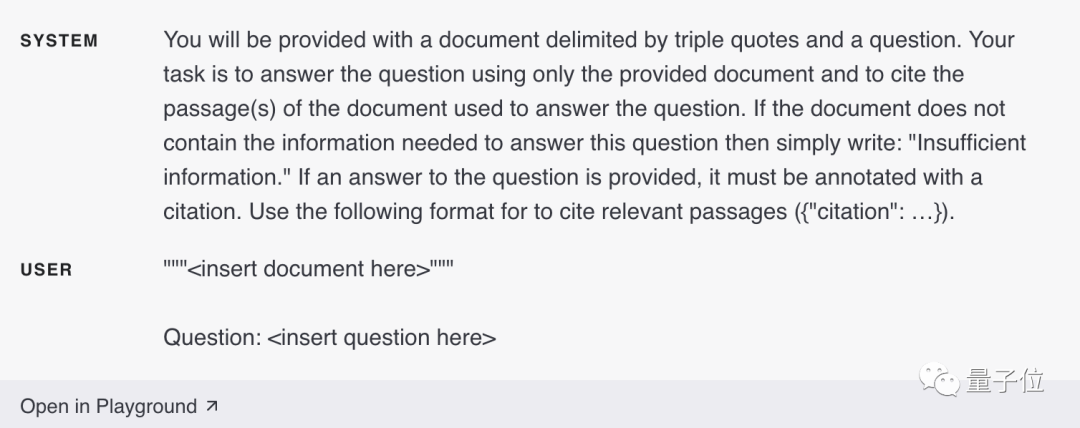
En revanche, GPT-4 a un taux d'erreur plus élevé lorsqu'il s'agit de tâches complexes.
 Cependant, nous pouvons adopter une stratégie intelligente pour re-diviser ces tâches complexes en un flux de travail composé d'une série de tâches simples.
Cependant, nous pouvons adopter une stratégie intelligente pour re-diviser ces tâches complexes en un flux de travail composé d'une série de tâches simples.
Conseils pratiques :
1. besoins Pour faire face à un grand nombre de tâches indépendantes dans différentes situations, ces tâches peuvent être classées en premier. Ensuite, déterminez les instructions requises en fonction de la classification.
Par exemple, pour une application de service client, les requêtes peuvent être catégorisées (facturation, support technique, gestion de compte, requêtes générales, etc.). Quand un utilisateur a demandé :
Je dois remettre mon Internet en marche.Selon la classification des requêtes des utilisateurs, les demandes spécifiques de l'utilisateur peuvent être verrouillées et un ensemble d'instructions plus spécifiques peuvent être fournies à GPT-4 pour l'étape suivante.
Par exemple, disons qu'un utilisateur a besoin d'aide pour le « dépannage ».
Vous pouvez définir l'étape suivante :Demander à l'utilisateur de vérifier si tous les câbles du routeur sont connectés...
#🎜🎜 ## 🎜🎜#
2. Résumer ou filtrer les conversations précédentesEn raison de GPT La fenêtre de dialogue de -4 est limitée. Le contexte ne peut pas être trop long et ne peut pas se poursuivre indéfiniment dans une fenêtre de dialogue.
Mais il n'y a pas de solution. 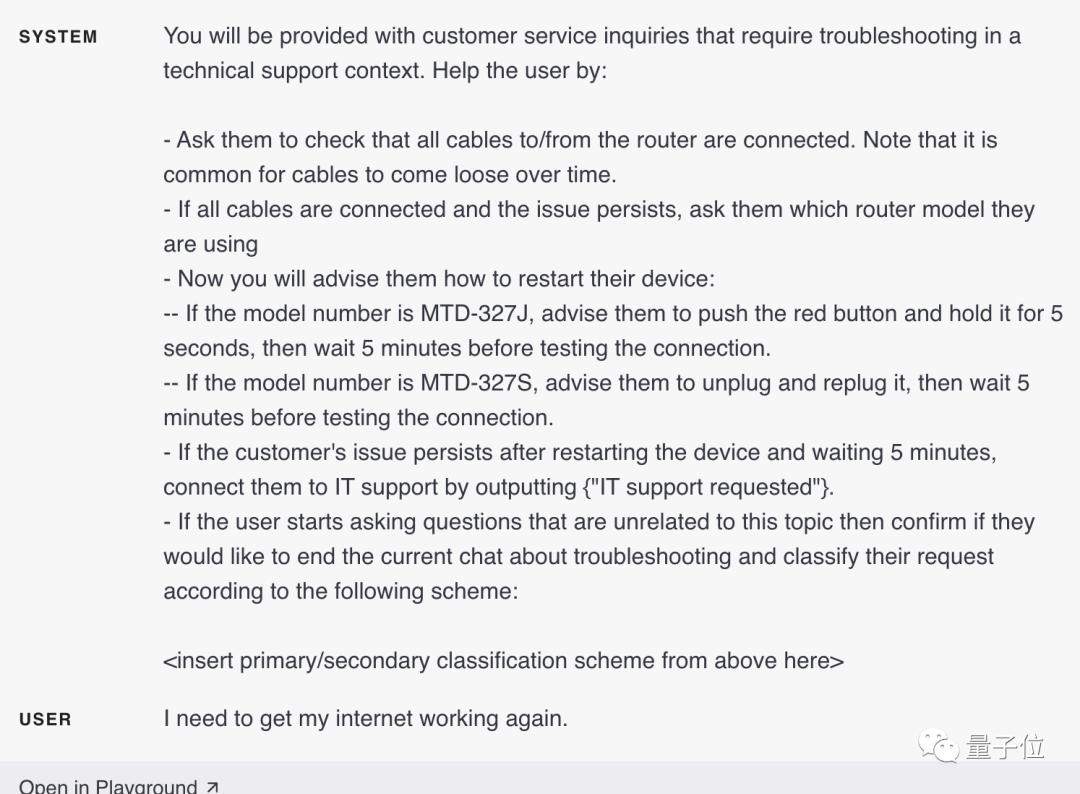
De plus, les conversations précédentes peuvent être résumées en arrière-plan pendant la conversation. Une autre approche consiste à récupérer les conversations précédentes, en utilisant la recherche basée sur l'intégration pour une récupération efficace des connaissances.
3. Résumez les longs documents paragraphe par paragraphe, et construisez de manière récursive un résumé completReste que le problème est que le texte est trop long.
Par exemple, si vous souhaitez que GPT-4 résume un livre, vous pouvez utiliser une série de requêtes pour résumer chaque partie du livre.
Connectez ensuite les aperçus partiels pour résumer et former une réponse générale.
Ce processus peut être effectué de manière récursive jusqu'à ce que l'intégralité du livre soit résumée. Mais certaines parties peuvent avoir besoin d'emprunter des informations à la partie précédente pour comprendre les parties suivantes. Voici une astuce :
.Lorsque vous résumez le contenu actuel, résumez ensemble le contenu avant le contenu actuel dans le texte pour faire un résumé.
En termes simples, utilisez le "résumé" de la partie précédente + la partie actuelle, puis résumez.
OpenAI a également déjà utilisé un modèle formé sur la base de GPT-3 pour étudier l'effet du résumé de livres.
De la même manière, lorsque GPT-4 reçoit une question, il ne prend pas le temps de bien réfléchir, mais essaie de donner une réponse immédiatement, ce qui peut conduire à des erreurs de raisonnement.
 Par conséquent, avant de demander au modèle de donner une réponse, vous pouvez d'abord lui demander d'effectuer une série de processus de raisonnement pour l'aider à arriver à la bonne réponse grâce au raisonnement.
Par conséquent, avant de demander au modèle de donner une réponse, vous pouvez d'abord lui demander d'effectuer une série de processus de raisonnement pour l'aider à arriver à la bonne réponse grâce au raisonnement.
Conseils pratiques :
1. Laissez le modèle formuler la solution
#🎜🎜 # Vous constaterez parfois que nous obtenons de meilleurs résultats lorsque nous demandons explicitement au modèle de raisonner à partir des premiers principes avant de tirer des conclusions. Par exemple, disons que nous voulons que le modèle évalue la solution d'un élève à un problème de mathématiques.
La manière la plus directe est simplement de demander au modèle si la réponse de l'élève est correcte.
Dans l'image ci-dessus, GPT-4 pense que la solution de l'étudiant est correcte. Mais en fait le projet de l'étudiant est faux.À ce stade, vous pouvez inviter le modèle à générer sa propre solution pour que le modèle le remarque avec succès. 
2. Processus de raisonnement caché

Mais dans certaines applications, le processus de raisonnement par lequel le modèle atteint la réponse finale n'est pas adapté au partage avec les utilisateurs.
Par exemple, dans le tutorat aux devoirs, nous espérons toujours encourager les élèves à formuler leurs propres solutions aux problèmes et à arriver ensuite aux bonnes réponses. Mais le raisonnement du modèle sur la solution de l'étudiant peut révéler la réponse à l'étudiant. À l'heure actuelle, nous avons besoin que le modèle mette en œuvre une stratégie de « monologue interne », permettant au modèle de mettre les parties de la sortie qui sont cachées à l'utilisateur dans un format structuré.
Ensuite, la sortie est analysée et seule une partie de celle-ci est rendue visible avant d'être présentée à l'utilisateur.
Comme l'exemple suivant :
Laissez d'abord le modèle formuler sa propre solution (car celle de l'élève peut se tromper), puis comparez-la avec la solution de l'élève.
Si un élève fait une erreur à n'importe quelle étape de sa réponse, laissez le modèle donner un indice pour cette étape au lieu de donner directement à l'élève la bonne solution complète.
Si l'élève se trompe toujours, alors passez à l'étape précédente.
Vous pouvez également utiliser la stratégie « requête », dans laquelle la sortie de toutes les requêtes sauf la dernière étape de la requête est correcte. Utilisateur masqué. Premièrement, on peut demander au modèle de résoudre le problème tout seul. Puisque cette requête initiale ne nécessite pas de solution étudiante, elle peut être omise. Cela offre également l'avantage supplémentaire que les solutions du modèle ne sont pas affectées par le biais des solutions des étudiants.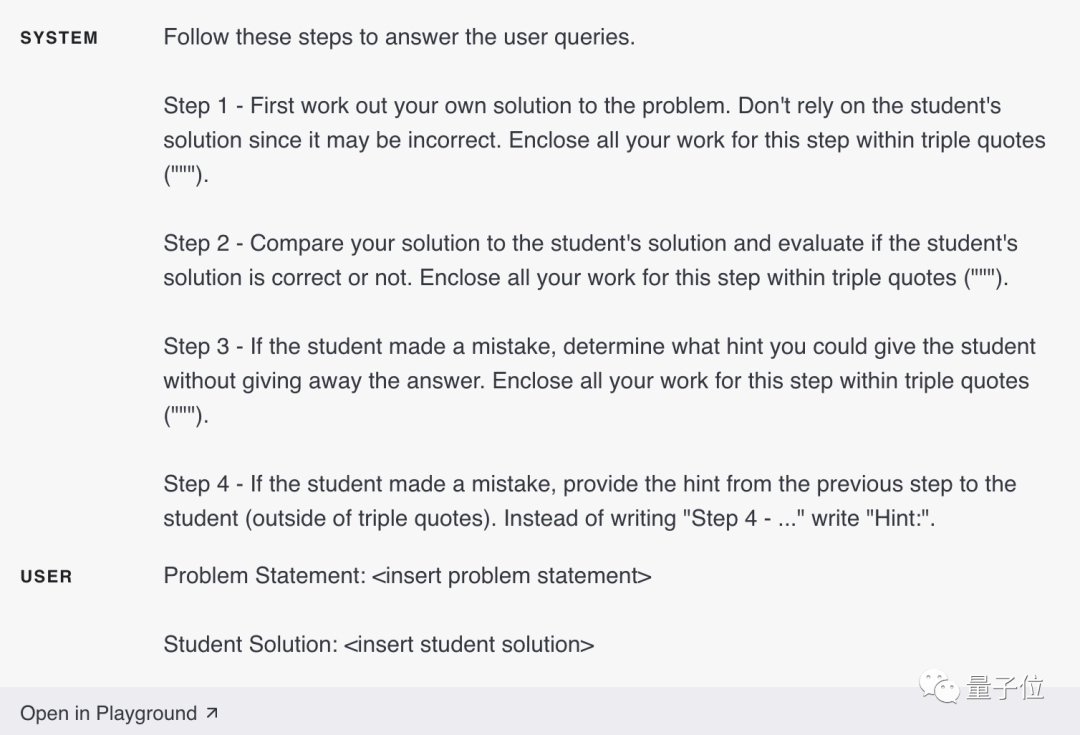
Vous êtes professeur de mathématiques. Si un élève répond incorrectement, incitez-le sans révéler la réponse. Si l’élève répond correctement, faites-lui simplement un commentaire encourageant.
3. Demandez au modèle s'il manque du contenu
Supposons que nous demandions à GPT-4 de répertorier un extrait de fichier source lié à un problème spécifique. Après avoir répertorié chaque extrait, le modèle doit déterminer s'il doit continuer à écrire. . Un extrait, ou un arrêt.
Si le fichier source est volumineux, le modèle s'arrêtera souvent prématurément, ne parvenant pas à répertorier tous les extraits pertinents.
Dans ce cas, il est souvent possible de demander au modèle d'effectuer des requêtes ultérieures pour retrouver les extraits qu'il a manqués lors du traitement précédent.
En d'autres termes, le texte généré par le modèle peut être très long et ne peut pas être généré en une seule fois, vous pouvez donc le laisser vérifier et remplir le contenu manquant.


GPT-4 est puissant, mais il n'est pas omnipotent.
Nous pouvons utiliser d'autres outils pour compléter les lacunes de GPT-4.
Par exemple, en combinaison avec un système de récupération de texte, ou en utilisant un moteur d'exécution de code.
Lorsque nous laissons GPT-4 répondre à une question, s'il existe des tâches qui peuvent être effectuées de manière plus fiable et plus efficace par d'autres outils, nous pouvons alors leur confier ces tâches. Cela peut non seulement tirer pleinement parti de leurs avantages respectifs, mais également permettre à GPT-4 de fonctionner au mieux.
Conseils pratiques :
1. Utilisez la recherche basée sur l'intégration pour obtenir une récupération efficace des connaissances
Cette astuce a été mentionnée ci-dessus.
Si des informations externes supplémentaires sont fournies dans l'entrée du modèle, cela aidera le modèle à générer de meilleures réponses.
Par exemple, si un utilisateur pose une question sur un film spécifique, il peut être utile d'ajouter des informations sur le film (comme les acteurs, le réalisateur, etc.) à l'entrée du modèle.
Les intégrations peuvent être utilisées pour permettre une récupération efficace des connaissances, où des informations pertinentes peuvent être ajoutées dynamiquement à l'entrée du modèle pendant l'exécution du modèle.
L'intégration de texte est un vecteur qui mesure la pertinence des chaînes de texte. Les chaînes similaires ou liées seront plus étroitement liées que les chaînes non liées. Ceci, associé à l’existence d’algorithmes de recherche vectorielle rapides, signifie que les intégrations peuvent être utilisées pour obtenir une récupération efficace des connaissances.
Spécialement, le corpus de texte peut être divisé en plusieurs parties, et chaque partie peut être intégrée et stockée. Ensuite, étant donné une requête, une recherche vectorielle peut être effectuée pour trouver les parties de texte incorporées dans le corpus les plus pertinentes pour la requête.
2. Utilisez l'exécution de code pour des calculs plus précis ou appelez des API externes
Vous ne pouvez pas compter uniquement sur le modèle lui-même pour des calculs précis.
Si vous le souhaitez, le modèle peut être invité à écrire et à exécuter du code au lieu d'effectuer des calculs autonomes.
Vous pouvez demander au modèle de mettre le code à exécuter dans un format spécifié. Une fois la sortie générée, le code peut être extrait et exécuté. Une fois la sortie générée, le code peut être extrait et exécuté. Enfin, la sortie du moteur d'exécution de code (c'est-à-dire l'interpréteur Python) peut être utilisée comme entrée suivante si nécessaire.

Un autre excellent scénario d'application pour l'exécution de code consiste à appeler des API externes.
Si l'utilisation correcte d'une API est communiquée au modèle, il peut écrire du code qui utilise cette API.
Les modèles peuvent apprendre à utiliser l'API en leur montrant de la documentation et/ou des exemples de code.
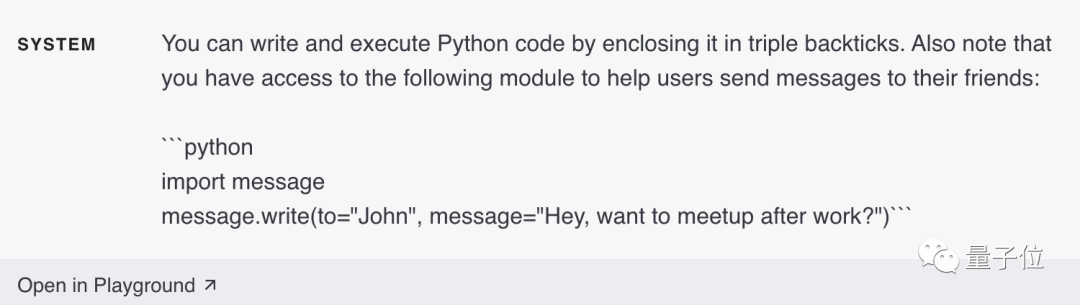
Ici, OpenAI émet un avertissement spécial⚠️ :
L'exécution de code généré par le modèle est intrinsèquement dangereuse et des précautions doivent être prises dans toute application qui tente de le faire. En particulier, un environnement d’exécution de code en bac à sable est nécessaire pour limiter les dommages que peut causer un code non fiable.

Parfois, il est difficile de déterminer si un changement rendra un système meilleur ou pire.
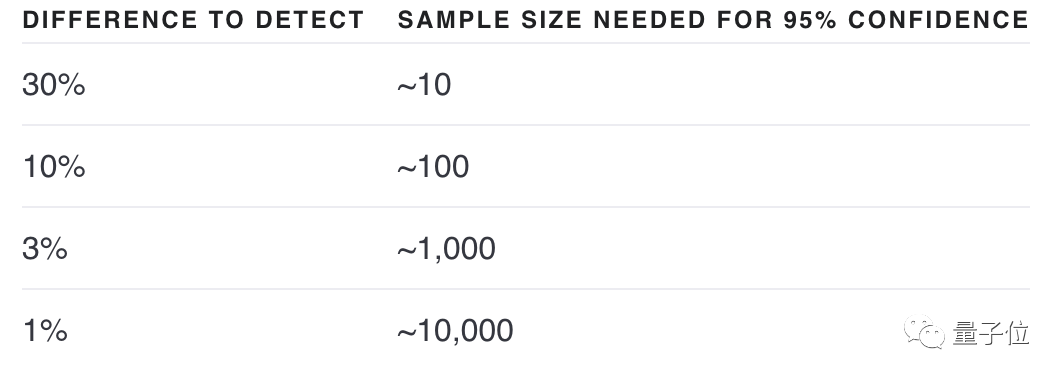
Il est possible de voir lequel est le meilleur en regardant quelques exemples, mais avec un petit échantillon, il est difficile de dire s'il y a une véritable amélioration ou simplement un hasard.
Peut-être que ce « changement » peut améliorer l'efficacité de certains intrants, mais réduire l'efficacité d'autres intrants.
Les procédures d'évaluation (ou « evals ») sont très utiles pour optimiser la conception du système. Une bonne évaluation présente les caractéristiques suivantes :
1) représente une utilisation réelle (ou au moins une variété d'utilisations)
2) contient de nombreux cas de test pour obtenir une plus grande puissance statistique (voir le tableau ci-dessous)
3 ) Facile à automatiser ou répéter
L'évaluation du résultat peut se faire par ordinateur, humainement ou une combinaison des deux. Les ordinateurs peuvent évaluer automatiquement à l'aide de critères objectifs, ou ils peuvent utiliser des critères subjectifs ou flous, comme l'utilisation de modèles pour évaluer des modèles.
OpenAI fournit un cadre logiciel open source - OpenAI Evals, qui fournit des outils pour créer des évaluations automatiques.
L'évaluation basée sur un modèle est utile lorsqu'il existe une série de résultats de qualité égale.
Conseils pratiques :
1. Évaluez les résultats du modèle en vous référant aux réponses de référence
Supposez que la réponse correcte à une question connue doit faire référence à un ensemble spécifique de faits connus.
Nous pouvons alors demander au modèle combien de faits requis sont inclus dans la réponse.
Par exemple, en utilisant le message système suivant,
donne les faits établis nécessaires :
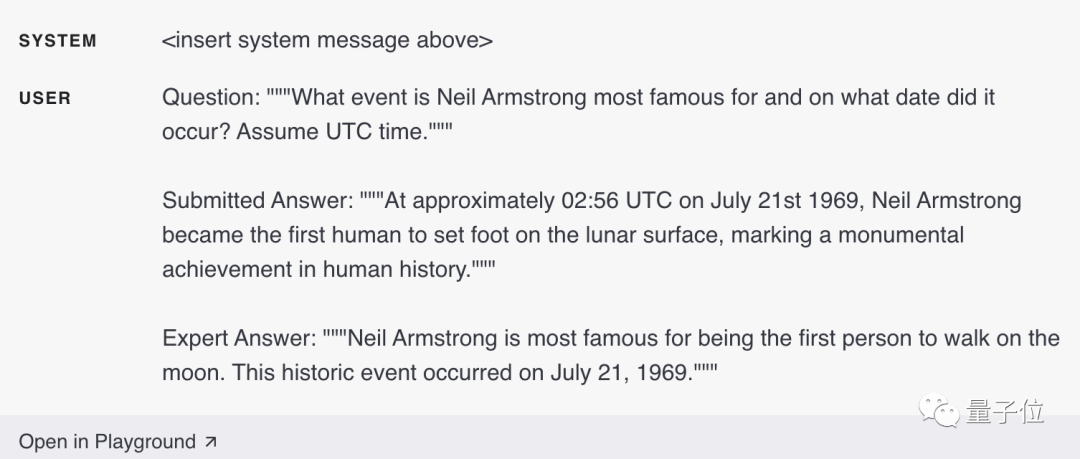
Neil Armstrong a été le premier homme à marcher sur la lune.
La date à laquelle Neil Armstrong a atterri pour la première fois sur la lune était le 21 juillet 1969.
Si la réponse contient les faits donnés, le modèle répondra « oui ». Sinon, le modèle répondra « non » et finalement le laissera compter le nombre de réponses « oui » :

Ce qui suit est un exemple d'entrée contenant deux faits établis (à la fois des événements et du temps) :
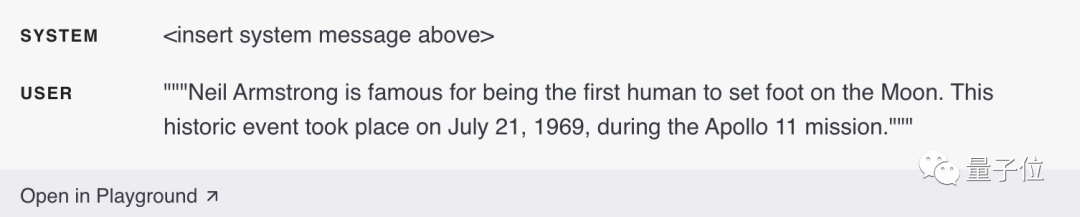
Un exemple d'entrée qui satisfait uniquement un fait établi (pas de temps) :
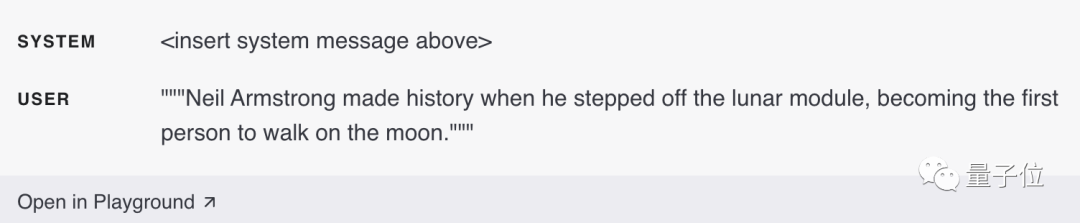
L'exemple d'entrée suivant ne contient aucun fait établi :
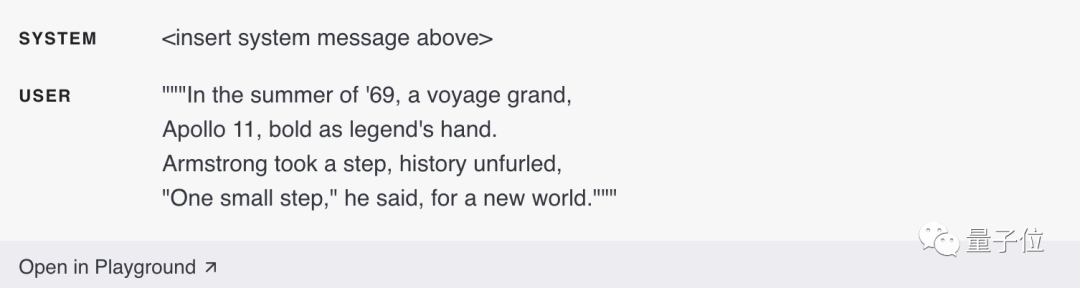
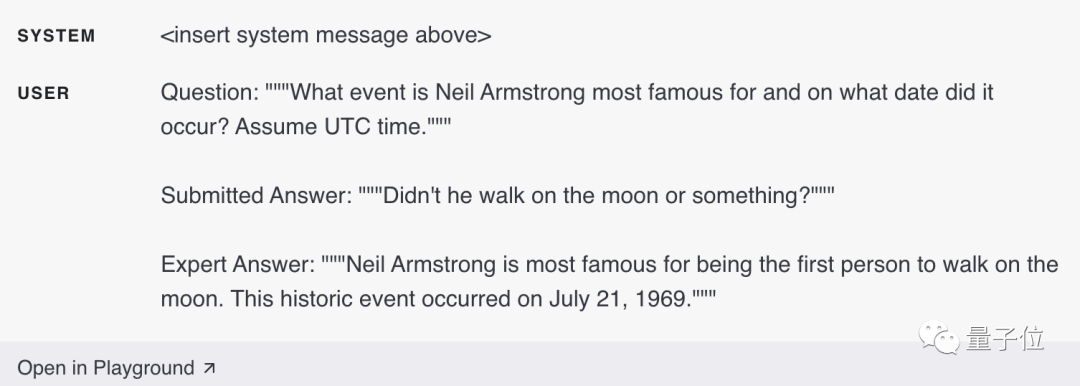
Il existe de nombreux variations possibles de la méthode d'évaluation, et il est nécessaire de suivre le degré de chevauchement entre la réponse du candidat et la réponse standard, et de déterminer si la réponse du candidat est en conflit avec la réponse standard.

Comme cet exemple d'entrée ci-dessous, qui contient des réponses de qualité inférieure, mais ne contredit pas la réponse de l'expert (réponse standard) :
Voici cet exemple d'entrée, dont la réponse est cohérente avec l'expert réponse La réponse est une contradiction directe (je pense que Neil Armstrong a été le deuxième homme à marcher sur la lune) :

Le dernier est un exemple de saisie avec la bonne réponse, qui fournit également plus de détails que nécessaire (l'heure est exactement 02h56 et souligne qu'il s'agit d'un événement monumental dans l'histoire de l'humanité).
(OpenAI Evals)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quels serveurs y a-t-il sur le Web ?
Quels serveurs y a-t-il sur le Web ?
 Introduction à la différence entre javascript et java
Introduction à la différence entre javascript et java
 Comment élever un petit pompier sur Douyin
Comment élever un petit pompier sur Douyin
 La différence entre maître et hôte
La différence entre maître et hôte
 drivermanager.getconnection
drivermanager.getconnection
 Enregistrez-vous dans un emplacement virtuel sur DingTalk
Enregistrez-vous dans un emplacement virtuel sur DingTalk
 bootsql.dat
bootsql.dat
 Graphique des prix historiques du Bitcoin
Graphique des prix historiques du Bitcoin








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



