
 Périphériques technologiques
IA
La génération de vidéos avec un temps et un espace contrôlables est devenue une réalité, et le nouveau modèle à grande échelle d'Alibaba, VideoComposer, est devenu populaire.
Périphériques technologiques
IA
La génération de vidéos avec un temps et un espace contrôlables est devenue une réalité, et le nouveau modèle à grande échelle d'Alibaba, VideoComposer, est devenu populaire.
La génération de vidéos avec un temps et un espace contrôlables est devenue une réalité, et le nouveau modèle à grande échelle d'Alibaba, VideoComposer, est devenu populaire.

Dans le domaine de la peinture IA, Composer proposé par Alibaba et ControlNet basé sur la diffusion stable proposée par Stanford ont dirigé le développement théorique de la génération d'images contrôlables. Cependant, l'exploration de la génération vidéo contrôlable par l'industrie est encore relativement vierge.
Par rapport à la génération d'images, la vidéo contrôlable est plus complexe, car en plus de la contrôlabilité de l'espace du contenu vidéo, elle doit également répondre à la contrôlabilité de la dimension temporelle. Sur cette base, les équipes de recherche d'Alibaba et d'Ant Group ont pris l'initiative de proposer VideoComposer, qui permet simultanément de contrôler la vidéo dans les dimensions temporelle et spatiale grâce à un paradigme de génération combinée.

- Adresse papier : https://arxiv.org/abs/2306.02018
- Page d'accueil du projet : https://videocomposer.github.io
Avant section À cette époque, Alibaba a publié en open source le modèle vidéo Vincent dans Magic Community et Hugging Face, qui a de manière inattendue attiré l'attention des développeurs nationaux et étrangers. Les vidéos générées par le modèle ont même reçu une réponse de Musk lui-même, et. le modèle a continué à être populaire sur la communauté Magic. Il a reçu des dizaines de milliers de visites internationales en une seule journée sur plusieurs jours.
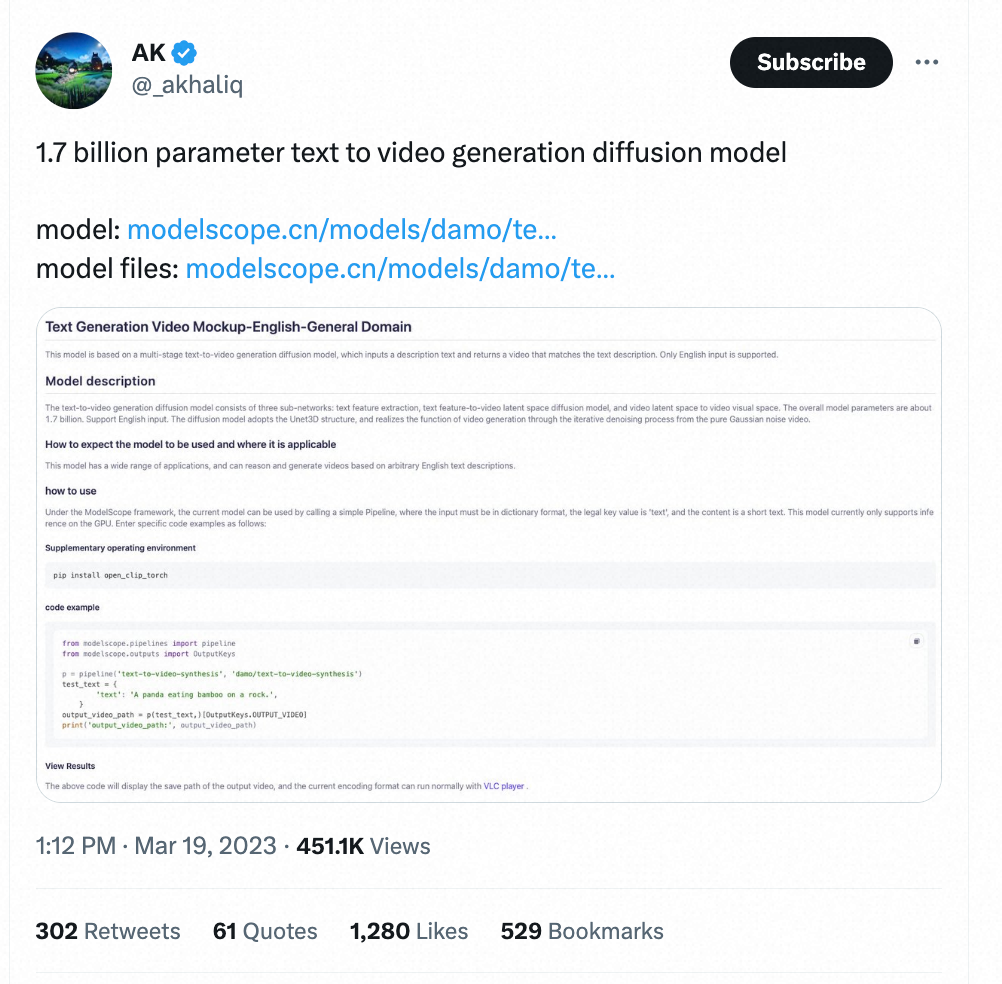
Text-to-Video sur Twitter
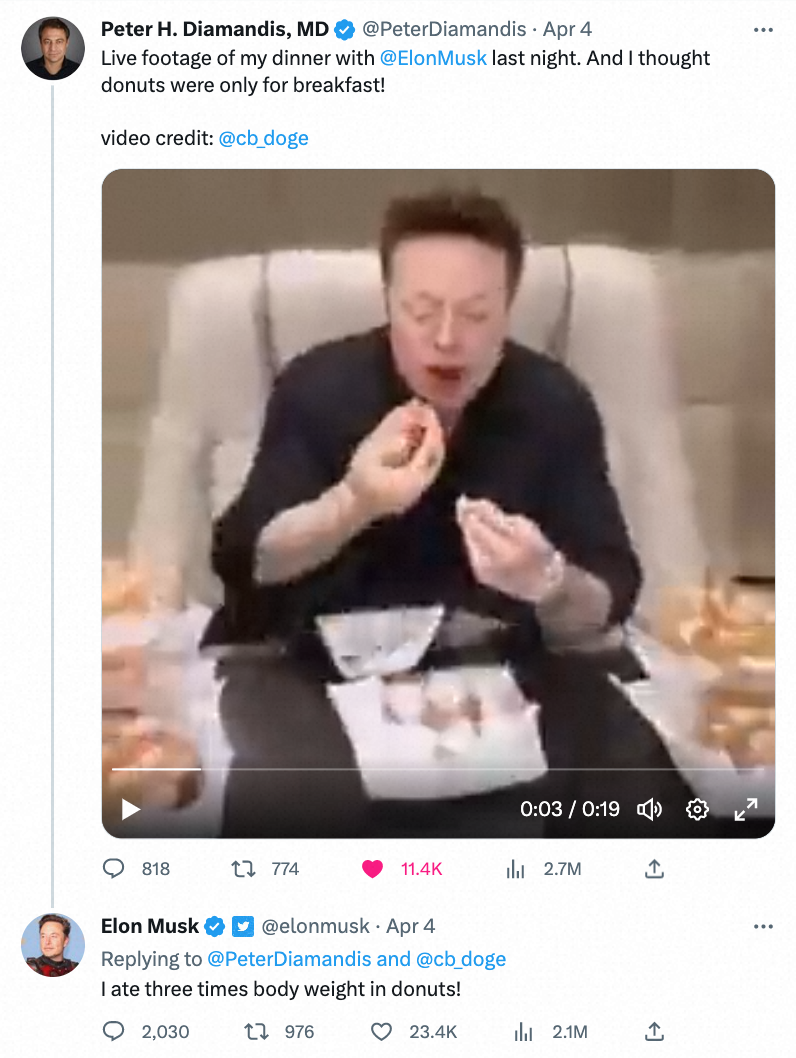
VideoComposer Les derniers résultats ont une fois de plus été largement accueilli par la communauté internationale se concentrer sur. V ideoComposer sur Twitter
En fait, la contrôlabilité est devenue un contenu visuel Une référence supérieure pour la création, qui a fait des progrès significatifs dans la génération d'images personnalisées, mais a encore trois défis majeurs dans le domaine de la génération vidéo :

- Structure de données complexe, la vidéo générée doit satisfaire à la fois la diversité des changements dynamiques dans la dimension temporelle et la cohérence du contenu dans la dimension spatio-temporelle
- Conditions de guidage complexes, la génération vidéo contrôlable existante doit être complexe. les conditions ne peuvent pas être construites manuellement. Par exemple, Gen-1/2 proposé par Runway doit s'appuyer sur des séquences de profondeur comme conditions, ce qui permet de mieux réaliser une migration structurelle entre les vidéos, mais ne peut pas bien résoudre le problème de contrôlabilité
- manque de contrôlabilité du mouvement, et le modèle de mouvement est un ; attribut complexe et abstrait de la vidéo, et la contrôlabilité du mouvement est une condition nécessaire pour résoudre la contrôlabilité de la génération vidéo.
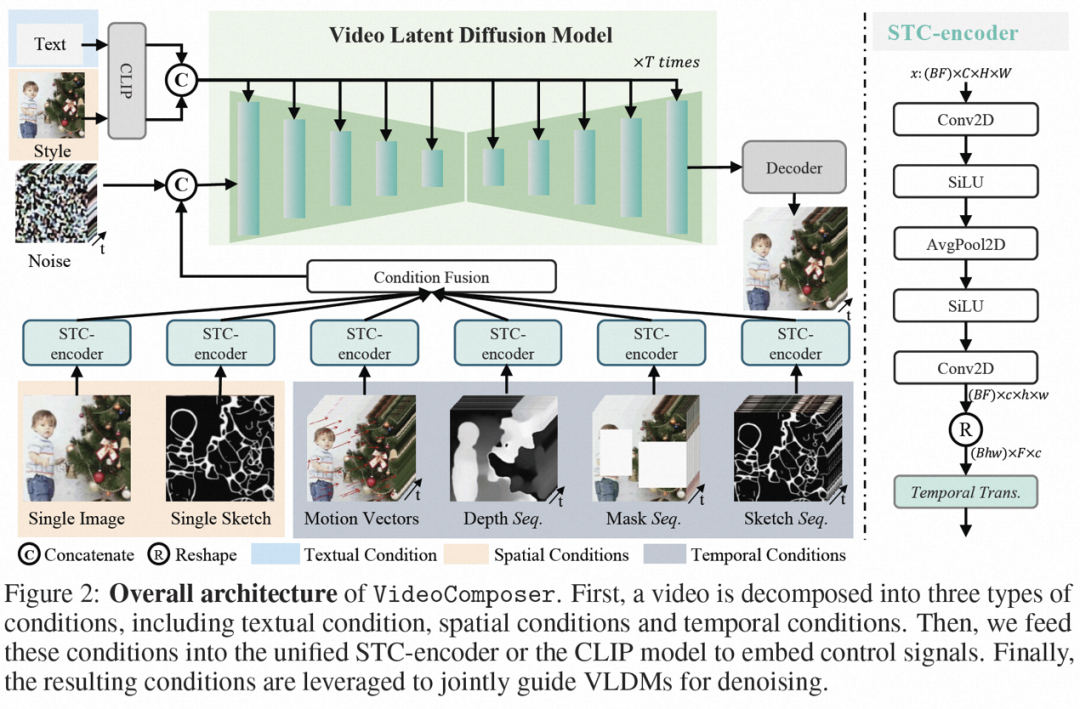
Avant cela, Composer proposé par Alibaba a prouvé que la compositionnalité est extrêmement utile pour améliorer la contrôlabilité de la génération d'images. VideoComposer est également basé sur le paradigme de génération de composition et résout les trois problèmes ci-dessus tout en améliorant la flexibilité de. génération vidéo. Plus précisément, la vidéo est décomposée en trois conditions directrices, à savoir les conditions de texte, les conditions spatiales et les conditions de synchronisation spécifiques à la vidéo, puis le LDM vidéo (modèle de diffusion latente vidéo) est formé sur cette base. En particulier, il utilise un vecteur de mouvement efficace comme condition de synchronisation explicite importante pour apprendre le modèle de mouvement des vidéos, et conçoit un encodeur de condition spatio-temporelle simple et efficace, un encodeur STC pour assurer la continuité spatio-temporelle des vidéos pilotées par la condition. Lors de l’étape d’inférence, différentes conditions peuvent être combinées de manière aléatoire pour contrôler le contenu vidéo.
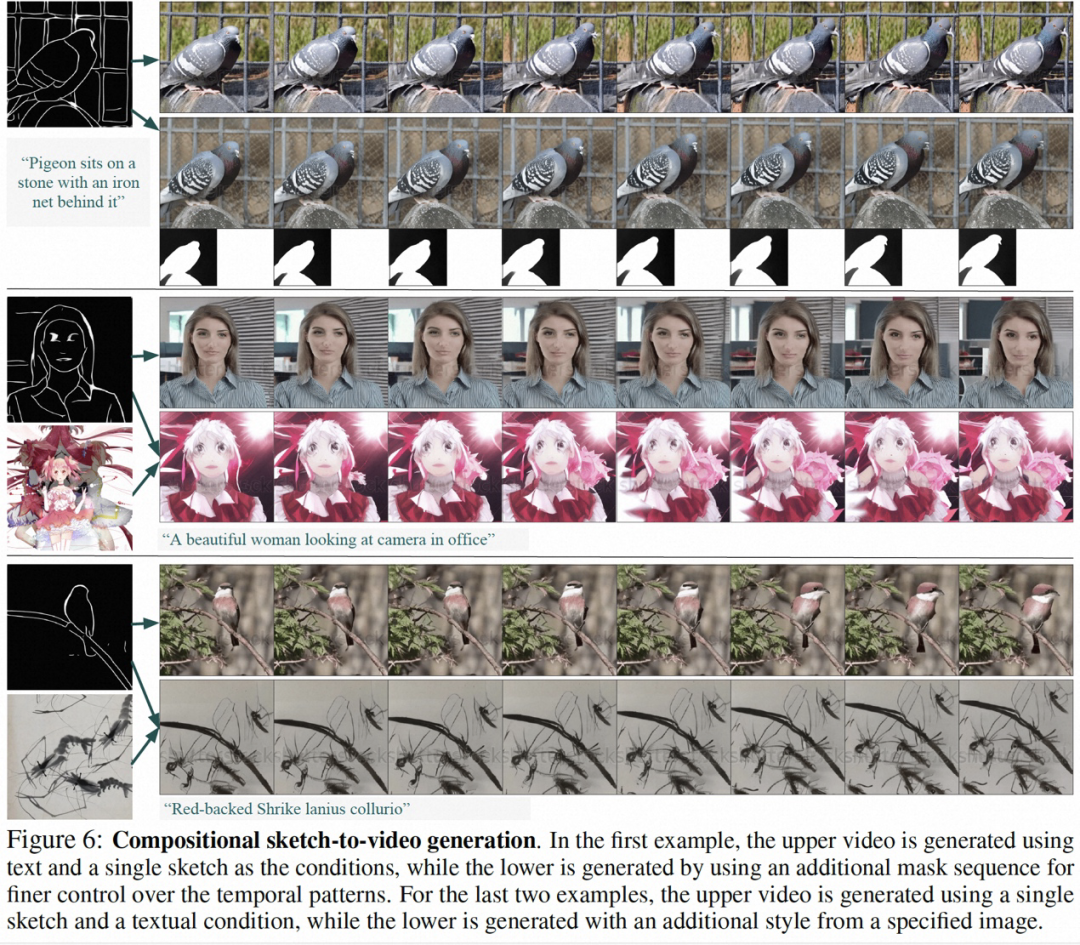
Les résultats expérimentaux montrent que VideoComposer peut contrôler de manière flexible les modèles temporels et spatiaux des vidéos, tels que la génération de vidéos spécifiques à travers des images uniques, des dessins dessinés à la main, etc., et peut même facilement contrôler le style de mouvement de la cible via de simples directions dessinées à la main. Cette étude a directement testé les performances de VideoComposer sur 9 tâches classiques différentes, et toutes ont obtenu des résultats satisfaisants, prouvant la polyvalence de VideoComposer.
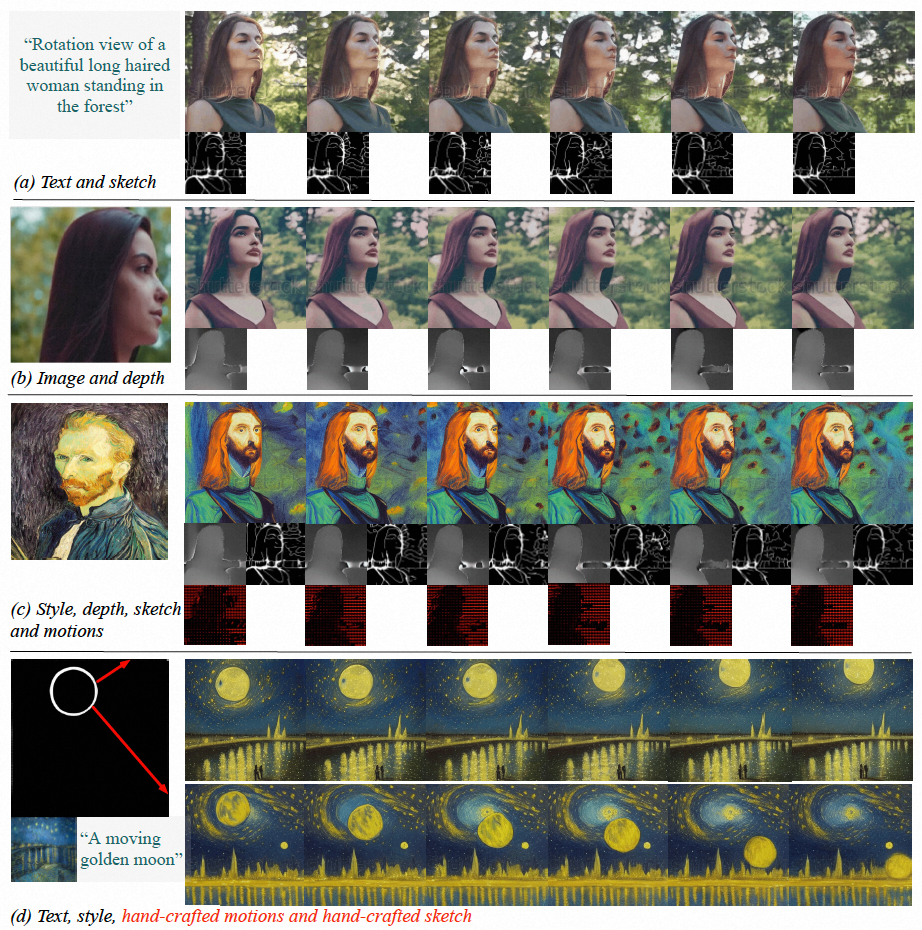
Figure (a-c) VideoComposer peut générer des vidéos qui répondent aux conditions de texte, d'espace et de temps ou un sous-ensemble de celles-ci (d) VideoComposer ne peut utiliser que deux traits pour générer des vidéos qui répondent au style Van Gogh ; satisfaisant Mode mouvement anticipé (traits rouges) et mode forme (traits blancs)
Espace caché.Video LDM introduit d'abord un encodeur pré-entraîné pour mapper la vidéo d'entrée à une représentation spatiale latente, où . Ensuite, le décodeur pré-entraîné D est utilisé pour mapper l'espace latent à l'espace des pixels. Dans VideoComposer, réglages des paramètres Pour apprendre la distribution réelle de contenu vidéo 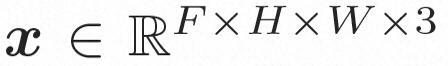 Modèle de diffusion.
Modèle de diffusion. 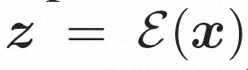
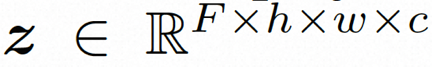
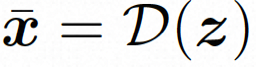
 , le modèle de diffusion apprend à débruiter progressivement le bruit de distribution normal pour restaurer le contenu visuel réel. Ce processus simule en fait une chaîne de Markov réversible d'une longueur de T = 1000. Afin d'effectuer un processus réversible dans l'espace latent, Video LDM injecte du bruit dans
, le modèle de diffusion apprend à débruiter progressivement le bruit de distribution normal pour restaurer le contenu visuel réel. Ce processus simule en fait une chaîne de Markov réversible d'une longueur de T = 1000. Afin d'effectuer un processus réversible dans l'espace latent, Video LDM injecte du bruit dans 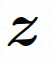
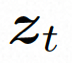
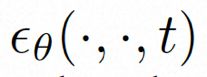
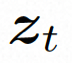
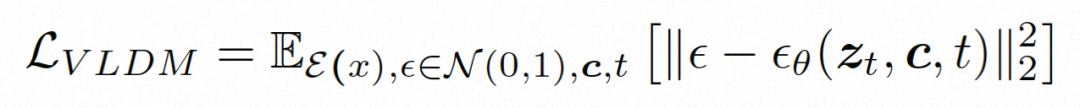
Afin d'explorer et d'utiliser pleinement l'espace local biais et séquence inductifs Pour le débruitage à l'aide du biais d'induction temporelle, VideoComposer instancie 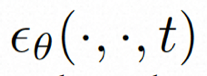
VideoComposer
Conditions combinées. VideoComposer décompose la vidéo en trois types différents de conditions, à savoir les conditions textuelles, les conditions spatiales et les conditions de synchronisation critiques, qui déterminent ensemble les modèles spatiaux et temporels dans la vidéo. VideoComposer est un cadre général de génération vidéo combinée, de sorte que des conditions plus personnalisées peuvent être incorporées dans VideoComposer en fonction de l'application en aval, sans se limiter aux conditions énumérées ci-dessous :
- Conditions de texte : la description du texte (texte) commence par le visuel approximatif les aspects du contenu et du mouvement fournissent une indication intuitive de la vidéo, ce qui est également une condition couramment utilisée pour T2V ; comme condition spatiale pour générer une image en vidéo pour exprimer le contenu et la structure de la vidéo ;
Single Sketch, utilisez PiDiNet pour extraire l'esquisse de la première image vidéo comme deuxième conditions spatiales ; ), afin de transférer davantage le style d'une seule image à la vidéo synthétisée, l'intégration d'images est sélectionnée comme guide de style
-
;
- Conditions de synchronisation :
- Motion Vector, le vecteur de mouvement est représenté comme un vecteur bidimensionnel en tant qu'élément unique de la vidéo, c'est-à-dire les directions horizontale et verticale. Il code explicitement le mouvement pixel par pixel entre deux images adjacentes. En raison des propriétés naturelles des vecteurs de mouvement, cette condition est traitée comme un signal de contrôle de mouvement synthétisé temporellement fluide, qui extrait les vecteurs de mouvement au format MPEG-4 standard à partir de la vidéo compressée #Depth Sequence (Depth Sequence), afin d'introduire la vidéo ; informations de profondeur de niveau, utilisez le modèle pré-entraîné dans PiDiNet pour extraire la carte de profondeur de l'image vidéo
- Séquence de masque (Séquence de masque), qui introduit un masque tubulaire ; pour masquer le contenu spatio-temporel local et force le modèle à prédire la zone masquée sur la base d'informations observables
- Sketch Sequence ), une séquence d'esquisse peut fournir plus de détails de contrôle qu'une seule ; croquis, permettant des compositions personnalisées précises.
- Encodeur conditionnel spatiotemporel.
Les conditions de séquence contiennent des dépendances spatio-temporelles riches et complexes, qui posent un plus grand défi aux instructions contrôlables. Pour améliorer la perception temporelle des conditions d'entrée, cette étude a conçu un encodeur de conditions spatio-temporelles (encodeur STC) pour intégrer les relations spatio-temporelles. Plus précisément, une structure spatiale légère est d'abord appliquée, comprenant deux convolutions 2D et un avgPooling, pour extraire des informations spatiales locales, puis la séquence de conditions résultante est entrée dans une couche de transformateur temporel pour une modélisation temporelle. De cette manière, l'encodeur STC peut faciliter l'intégration explicite d'indices temporels et fournir une entrée unifiée pour l'intégration conditionnelle de diverses entrées, améliorant ainsi la cohérence inter-trames. De plus, l'étude a répété les conditions spatiales d'une seule image et d'un seul croquis dans la dimension temporelle pour assurer leur cohérence avec les conditions temporelles, facilitant ainsi le processus d'intégration des conditions. Après avoir traité les conditions via l'encodeur STC, la séquence de conditions finale a la même forme spatiale que , et est ensuite fusionnée par addition élément par élément. Enfin, la séquence conditionnelle fusionnée est concaténée le long de la dimension du canal en tant que signal de contrôle. Pour les conditions de texte et de style, un mécanisme d’attention croisée est utilisé pour injecter des conseils de texte et de style.
Formation et inférence
#🎜 🎜 #Stratégie de formation en deux étapes.
Bien que VideoComposer puisse être initialisé via un pré-entraînement de l'image LDM, ce qui peut atténuer dans une certaine mesure la difficulté de l'entraînement, il est difficile pour le modèle d'avoir à la fois le capacité à détecter les dynamiques temporelles et multiples La capacité à générer de manière conditionnelle, cela augmentera la difficulté de la formation à la génération vidéo combinée. Par conséquent, cette étude a adopté une stratégie d'optimisation en deux étapes. Dans la première étape, le modèle a été initialement équipé de capacités de modélisation temporelle grâce à la formation T2V. Dans la deuxième étape, VideoComposer a été optimisé grâce à une formation combinée pour obtenir de meilleures performances. Raisonnement.
Pendant le processus d'inférence, DDIM est utilisé pour améliorer l'efficacité de l'inférence. Et adoptez des conseils sans classificateur pour garantir que les résultats générés répondent aux conditions spécifiées. Le processus de génération peut être formalisé comme suit :
où ω est le rapport guide et c2 sont deux ensembles ; de conditions. Ce mécanisme de guidage est jugé par un ensemble de deux conditions et peut donner au modèle un contrôle plus flexible grâce au contrôle de l'intensité.
Résultats expérimentaux
Dans l'exploration expérimentale, l'étude a prouvé que VideoComposer en tant que modèle unifié dispose d'un cadre génératif universel et fonctionne bien sur 9 tâches classiques Vérifier les capacités de VideoComposer.
Certains résultats de cette recherche sont les suivants, en génération d'image statique en vidéo (Figure 4), Inpainting vidéo (Figure 5), génération de croquis statiques en vidéo (Figure 6), la vidéo de contrôle de mouvement dessinée à la main (Figure 8) et le transfert de mouvement (Figure A12) peuvent tous refléter les avantages de la génération vidéo contrôlable.
# 🎜 🎜#
Présentation de l'équipeLes informations publiques montrent qu'Alibaba développe un visuel de base modèle Ses recherches se concentrent principalement sur les grands modèles de représentation visuelle, les grands modèles visuels génératifs et leurs applications en aval. Il a publié plus de 60 articles CCF-A dans des domaines connexes et a remporté plus de 10 championnats internationaux dans plusieurs compétitions industrielles. méthode de génération d'images Composer, méthodes de pré-formation d'images et de texte RA-CLIP et RLEG, apprentissage auto-supervisé de longues vidéos non recadrées HiCo/HiCo++ et méthode de génération de visage parlant LipFormer font tous partie de cette équipe.
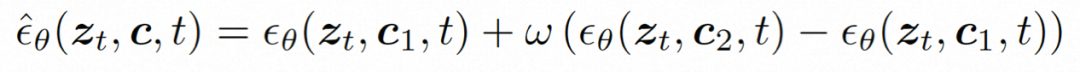


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Est-ce une infraction de publier des vidéos d'autres personnes sur Douyin ? Comment éditer des vidéos sans infraction ?
Mar 21, 2024 pm 05:57 PM
Avec l'essor des plateformes de vidéos courtes, Douyin est devenu un élément indispensable de la vie quotidienne de chacun. Sur TikTok, nous pouvons voir des vidéos intéressantes du monde entier. Certaines personnes aiment publier les vidéos d’autres personnes, ce qui soulève une question : Douyin enfreint-il la publication de vidéos d’autres personnes ? Cet article abordera ce problème et vous expliquera comment éditer des vidéos sans infraction et comment éviter les problèmes d'infraction. 1. Cela porte-t-il atteinte à la publication par Douyin de vidéos d'autres personnes ? Selon les dispositions de la loi sur le droit d'auteur de mon pays, l'utilisation non autorisée des œuvres du titulaire du droit d'auteur sans l'autorisation du titulaire du droit d'auteur constitue une infraction. Par conséquent, publier des vidéos d’autres personnes sur Douyin sans l’autorisation de l’auteur original ou du titulaire des droits d’auteur constitue une infraction. 2. Comment monter une vidéo sans contrefaçon ? 1. Utilisation de contenu du domaine public ou sous licence : Public
 Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Comment gagner de l'argent en publiant des vidéos sur Douyin ? Comment un débutant peut-il gagner de l'argent sur Douyin ?
Mar 21, 2024 pm 08:17 PM
Douyin, la plateforme nationale de courtes vidéos, nous permet non seulement de profiter d'une variété de courtes vidéos intéressantes et originales pendant notre temps libre, mais nous donne également une scène pour nous montrer et réaliser nos valeurs. Alors, comment gagner de l’argent en postant des vidéos sur Douyin ? Cet article répondra à cette question en détail et vous aidera à gagner plus d’argent sur TikTok. 1. Comment gagner de l’argent en publiant des vidéos sur Douyin ? Après avoir posté une vidéo et obtenu un certain nombre de vues sur Douyin, vous aurez la possibilité de participer au plan de partage publicitaire. Cette méthode de revenus est l’une des plus connues des utilisateurs de Douyin et constitue également la principale source de revenus pour de nombreux créateurs. Douyin décide d'offrir ou non des opportunités de partage de publicités en fonction de divers facteurs tels que le poids du compte, le contenu vidéo et les commentaires du public. La plateforme TikTok permet aux téléspectateurs de soutenir leurs créateurs préférés en envoyant des cadeaux,
 Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
Comment publier des vidéos sur Weibo sans compresser la qualité de l'image_Comment publier des vidéos sur Weibo sans compresser la qualité de l'image
Mar 30, 2024 pm 12:26 PM
1. Ouvrez d'abord Weibo sur votre téléphone mobile et cliquez sur [Moi] dans le coin inférieur droit (comme indiqué sur l'image). 2. Cliquez ensuite sur [Gear] dans le coin supérieur droit pour ouvrir les paramètres (comme indiqué sur l'image). 3. Ensuite, recherchez et ouvrez [Paramètres généraux] (comme indiqué sur l'image). 4. Entrez ensuite l'option [Video Follow] (comme indiqué sur l'image). 5. Ensuite, ouvrez le paramètre [Résolution de téléchargement vidéo] (comme indiqué sur l'image). 6. Enfin, sélectionnez [Qualité d'image originale] pour éviter la compression (comme indiqué sur l'image).
 2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
2 façons de supprimer le ralenti des vidéos sur iPhone
Mar 04, 2024 am 10:46 AM
Sur les appareils iOS, l'application Appareil photo vous permet de filmer des vidéos au ralenti, voire à 240 images par seconde si vous possédez le dernier iPhone. Cette capacité vous permet de capturer une action à grande vitesse avec des détails riches. Mais parfois, vous souhaiterez peut-être lire des vidéos au ralenti à vitesse normale afin de mieux apprécier les détails et l'action de la vidéo. Dans cet article, nous expliquerons toutes les méthodes pour supprimer le ralenti des vidéos existantes sur iPhone. Comment supprimer le ralenti des vidéos sur iPhone [2 méthodes] Vous pouvez utiliser l'application Photos ou l'application iMovie pour supprimer le ralenti des vidéos sur votre appareil. Méthode 1 : ouvrir sur iPhone à l’aide de l’application Photos
 Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Comment publier les œuvres vidéo de Xiaohongshu ? À quoi dois-je faire attention lorsque je publie des vidéos ?
Mar 23, 2024 pm 08:50 PM
Avec l'essor des plateformes de vidéos courtes, Xiaohongshu est devenue une plateforme permettant à de nombreuses personnes de partager leur vie, de s'exprimer et de gagner du trafic. Sur cette plateforme, la publication d’œuvres vidéo est un moyen d’interaction très prisé. Alors, comment publier les œuvres vidéo de Xiaohongshu ? 1. Comment publier les œuvres vidéo de Xiaohongshu ? Tout d’abord, assurez-vous d’avoir un contenu vidéo prêt à partager. Vous pouvez utiliser votre téléphone portable ou un autre équipement photo pour prendre des photos, mais vous devez faire attention à la qualité de l'image et à la clarté du son. 2. Editer la vidéo : Afin de rendre le travail plus attrayant, vous pouvez éditer la vidéo. Vous pouvez utiliser un logiciel de montage vidéo professionnel, tel que Douyin, Kuaishou, etc., pour ajouter des filtres, de la musique, des sous-titres et d'autres éléments. 3. Choisissez une couverture : La couverture est la clé pour inciter les utilisateurs à cliquer. Choisissez une image claire et intéressante comme couverture pour inciter les utilisateurs à cliquer dessus.
 Où puis-je trouver l'identifiant Alibaba ?
Mar 08, 2024 pm 09:49 PM
Où puis-je trouver l'identifiant Alibaba ?
Mar 08, 2024 pm 09:49 PM
Dans le logiciel Alibaba, une fois que vous avez enregistré un compte avec succès, le système vous attribuera un identifiant unique, qui servira d'identité sur la plateforme. Mais pour de nombreux utilisateurs, ils souhaitent interroger leur identifiant, mais ne savent pas comment le faire. Ensuite, l'éditeur de ce site Web vous présentera ci-dessous une introduction détaillée aux étapes de la stratégie, j'espère que cela pourra vous aider ! Où puis-je trouver la réponse à l'identifiant Alibaba : [Alibaba]-[Mon]. 1. Ouvrez d'abord le logiciel Alibaba. Après avoir accédé à la page d'accueil, nous devons cliquer sur [Mon] dans le coin inférieur droit. 2. Ensuite, après avoir accédé à la page Mon, nous pouvons voir [id] en haut de la page ; L'ID est-il le même que Taobao ID et Taobao ID sont différents, mais les deux
 Le siège mondial d'Alibaba à Hangzhou a été mis en service le 10 mai
May 07, 2024 pm 02:43 PM
Le siège mondial d'Alibaba à Hangzhou a été mis en service le 10 mai
May 07, 2024 pm 02:43 PM
Ce site Web a rapporté le 7 mai que le 10 mai, le siège mondial d'Alibaba (Xixi Area C) situé dans la future ville des sciences et technologies de Hangzhou sera officiellement mis en service et le parc scientifique et technologique d'Alibaba Beijing Chaoyang sera également ouvert. Cela représente le nombre d'immeubles de bureaux du siège d'Alibaba dans le monde, qui atteint quatre. ▲Siège mondial d'Alibaba (zone C, Xixi) Le 10 mai est également le 20e « Jour d'Alibaba » d'Alibaba. Ce jour-là chaque année, l'entreprise organisera des célébrations et deux nouveaux parcs seront ouverts aux parents, amis et anciens élèves d'Alibaba. Xixi Area C est actuellement le plus grand parc indépendant d’Alibaba et peut accueillir 30 000 personnes pour le travail de bureau. ▲Alibaba Beijing Chaoyang Science and Technology Park Le siège mondial d'Alibaba est situé dans la future ville scientifique et technologique de Hangzhou, au nord de Wenyi West Road et à l'est de Gaojiao Road, avec une superficie totale de construction de 984 500 mètres carrés, dont
 La DAMO Academy annonce les questions finales du test du concours mondial de mathématiques Alibaba 2024 : cinq pistes, résultats en août
Jun 23, 2024 pm 06:36 PM
La DAMO Academy annonce les questions finales du test du concours mondial de mathématiques Alibaba 2024 : cinq pistes, résultats en août
Jun 23, 2024 pm 06:36 PM
Selon les informations de ce site du 23 juin, ce site a appris du compte public DAMO WeChat qu'à minuit le 22 juin, heure de Pékin, la finale du concours mondial de mathématiques Alibaba 2024 s'est officiellement terminée. Plus de 800 candidats venus de 17 pays et régions du monde ont été présélectionnés pour la finale de cette année. Ensuite, il entrera dans la phase de notation indépendante du groupe d'experts. La notation comprend une évaluation préliminaire, un contre-interrogatoire, une vérification finale et d'autres processus. Dans les cinq filières finales, 1 médaille d'or, 2 médailles d'argent, 4 médailles de bronze et 10 prix d'excellence seront décernés en fonction des résultats. Au total, 85 gagnants seront annoncés en août. L'Alibaba Damo Academy a également annoncé les sujets de la finale de mathématiques. Les finales sont divisées en cinq domaines, à savoir : 1. Algèbre et théorie des nombres ; 2. Géométrie et topologie ; 3. Analyse et équations ; 4. Combinaison et probabilité ; et calcul.
