
 Périphériques technologiques
IA
L'IA remplacera-t-elle d'abord le travail humain dans le secteur de l'éducation ? La version américaine de 'Job Bang' déclenche des licenciements
Périphériques technologiques
IA
L'IA remplacera-t-elle d'abord le travail humain dans le secteur de l'éducation ? La version américaine de 'Job Bang' déclenche des licenciements
L'IA remplacera-t-elle d'abord le travail humain dans le secteur de l'éducation ? La version américaine de 'Job Bang' déclenche des licenciements

Les travailleurs du monde entier s'inquiètent du cauchemar du chômage en raison de la popularité de ChatGPT. C'est le résultat de « l'IA remplaçant le travail ». Aujourd’hui, les inquiétudes sont devenues réalité, et le secteur de l’éducation en fait les frais.
Lundi, heure locale, la version américaine de "Job Helper" Chegg a déclaré dans un dossier déposé auprès de la SEC qu'elle licencierait environ 4% de ses employés, soit environ 80 personnes, pour mieux exécuter sa stratégie d'intelligence artificielle. Devenue la première entreprise éducative à licencier des employés en raison de l'impact de l'IA.
L’activité principale de Chegg est le tutorat en ligne pour les devoirs. Pendant l'épidémie, alors que les étudiants suivaient généralement des cours en ligne, la demande pour les services de Chegg a considérablement augmenté.
Cependant, en mai, le PDG de Chegg, Dan Rosensweig, a déclaré lors d'une conférence téléphonique sur les résultats que ChatGPT avait affecté la croissance des performances de l'entreprise, ce qui a rapidement déclenché une réaction en chaîne. Le cours de l'action a chuté de 48 % en une journée. Cette année, le cours de l'action de la société a déjà chuté. .57%.
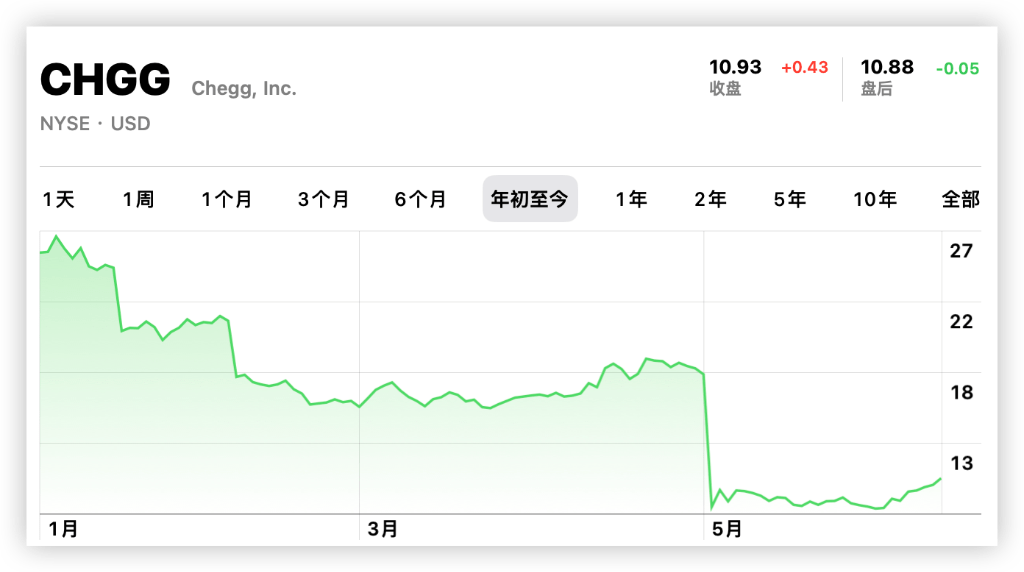
Alors que les chatbots IA comme ChatGPT continuent de gagner en popularité auprès des étudiants, Chegg améliore activement ses activités. Chegg a lancé en mai l'outil de tutorat en IA CheggMate, qui utilise l'API GPT-4 d'OpenAI.
Selon le plan, CheggMate utilisera la plateforme d'apprentissage personnalisé Chegg, les ensembles de données d'experts et les capacités de résolution de problèmes de GPT-4 pour créer un assistant d'apprentissage conversationnel IA, permettant aux étudiants d'apprendre en temps réel de manière plus efficace et plus précise qu'auparavant.
Au-delà du secteur de l’éducation, l’IA commence à avoir un impact de plus en plus répandu sur le marché du travail américain.
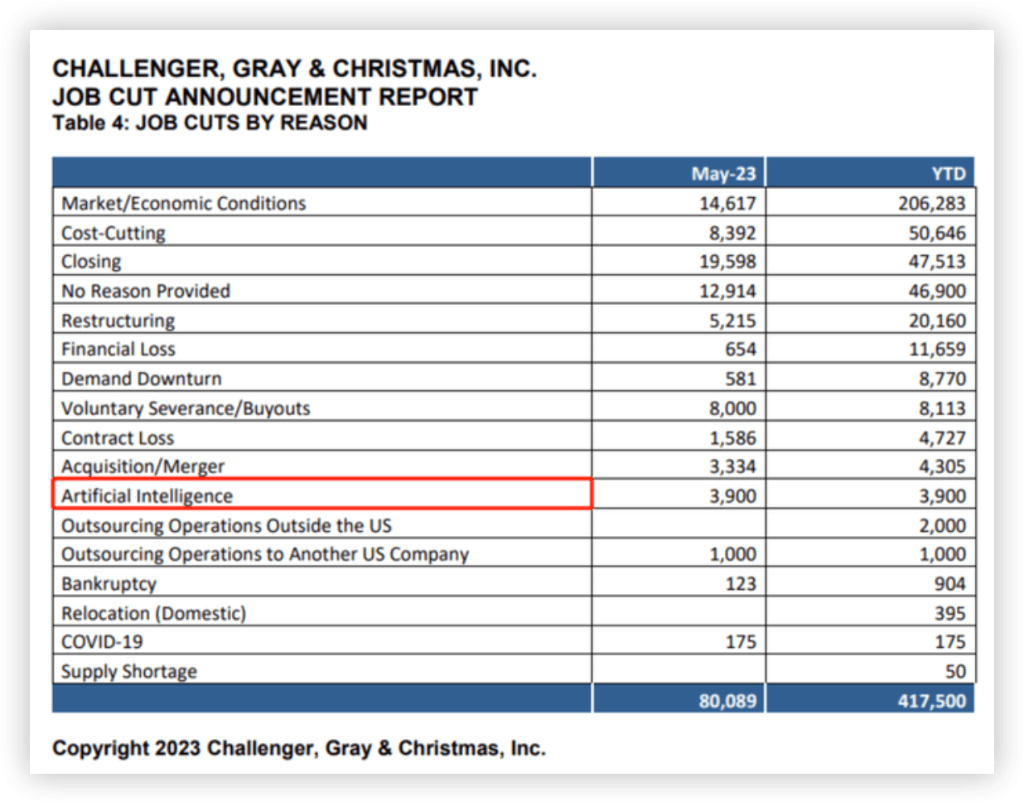
Début juin, Challenger, une société américaine de conseil en emploi, a cité « l'intelligence artificielle » comme l'une des raisons des licenciements dans les données sur les licenciements publiées par les entreprises américaines, et a déclaré qu'environ 3 900 emplois dans les entreprises américaines avaient été remplacés par cette technologie émergente. technologie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
