
 Périphériques technologiques
IA
Une IA capable d'imiter l'écriture manuscrite et de créer des polices exclusives pour vous
Périphériques technologiques
IA
Une IA capable d'imiter l'écriture manuscrite et de créer des polices exclusives pour vous
Une IA capable d'imiter l'écriture manuscrite et de créer des polices exclusives pour vous

Contexte de recherche sur l'IA d'imitation d'écriture manuscrite
Comme le dit le proverbe, les mots sont comme des visages et les mots sont comme des personnes. Par rapport aux polices imprimées rigides, l’écriture manuscrite peut mieux refléter les caractéristiques personnelles de l’écrivain. Je pense que beaucoup de gens ont imaginé avoir leur propre jeu de polices d'écriture manuscrite et les utiliser dans des logiciels sociaux pour mieux montrer leur style personnel.
Cependant, contrairement aux lettres anglaises, le nombre de caractères chinois est extrêmement important et il est très coûteux de créer votre propre police exclusive. Par exemple, le nouveau jeu de caractères chinois standard national GB18030-2022 contient plus de 80 000 caractères chinois. Il y a des rapports selon lesquels un blogueur sur un site Web de vidéos a passé 18 heures à écrire plus de 7 000 caractères chinois, en utilisant 13 stylos pendant le processus, et ses mains étaient engourdies à cause de l'écriture !
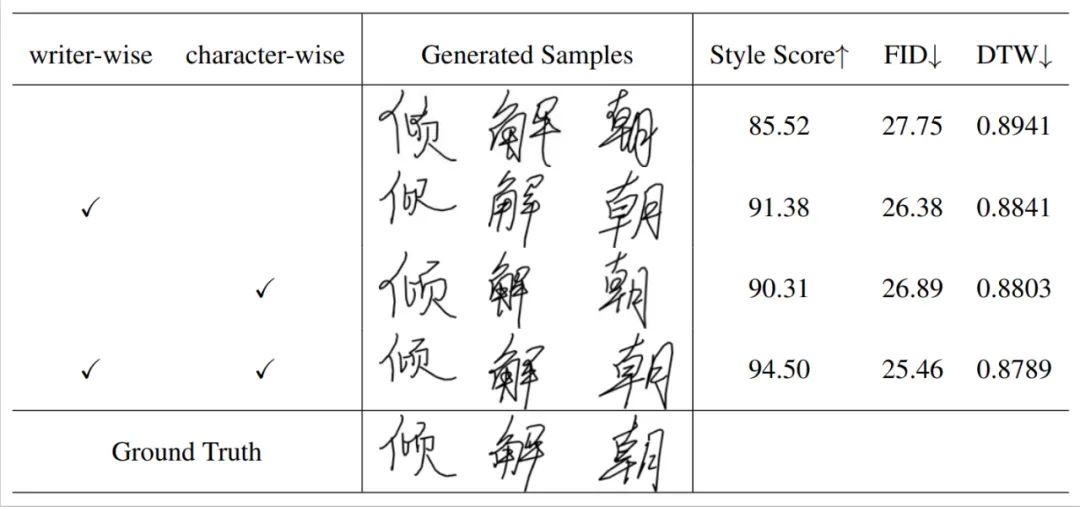
Les questions ci-dessus ont incité l'auteur de l'article à y réfléchir. Peut-il concevoir un modèle de génération automatique de texte pour aider à résoudre le problème du coût élevé de création de polices exclusives ? Afin de résoudre ce problème, les chercheurs ont imaginé une IA capable d'imiter l'écriture manuscrite. Seul l'utilisateur doit fournir un petit nombre d'échantillons d'écriture manuscrite (environ une douzaine) pour extraire le style d'écriture contenu dans l'écriture manuscrite (comme la taille de l'écriture manuscrite). caractères, le degré d'inclinaison, le degré d'inclinaison, etc.) Rapport d'aspect, longueur de trait et courbure, etc.), et copiez le style pour synthétiser plus de texte, synthétisant ainsi efficacement un ensemble complet de polices d'écriture manuscrite pour les utilisateurs.

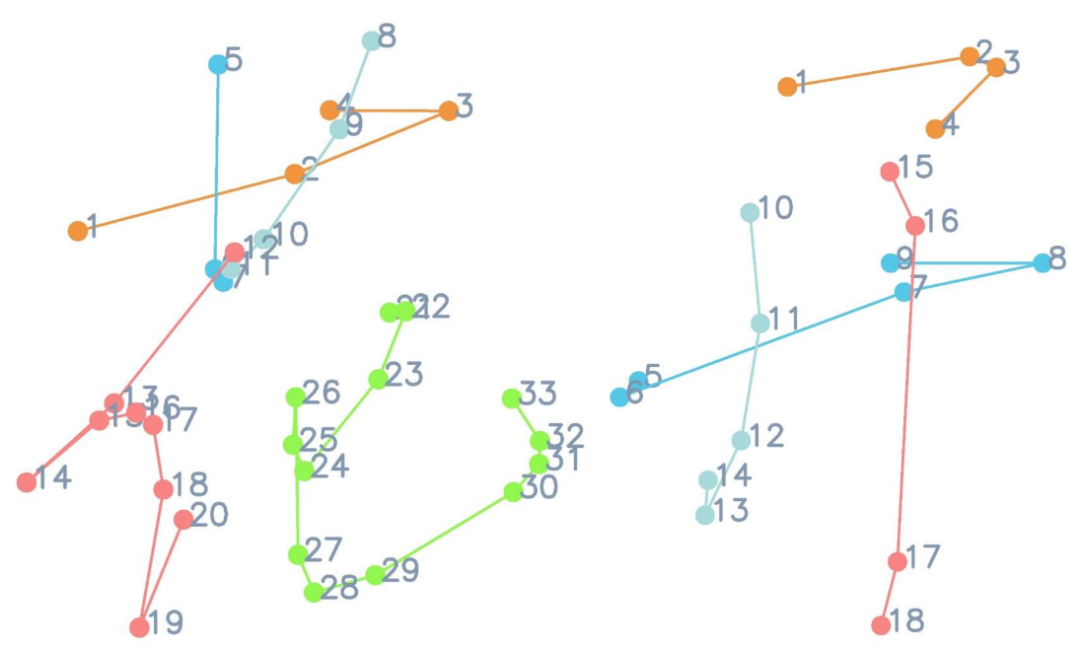
En outre, l'auteur de l'article a fait les réflexions suivantes sur les modalités d'entrée et de sortie du modèle du point de vue de la valeur de l'application et de l'expérience utilisateur : 1. Prise en compte de la police en ligne du La modalité de séquence (écritures manuscrites en ligne) contient des informations plus riches que les écritures manuscrites hors ligne en mode image (positions détaillées et ordre d'écriture des points de suivi, comme le montre la figure ci-dessous). Le réglage du mode de sortie du modèle sur texte en ligne aura une gamme d'applications plus large). perspectives, telles que l’écriture robotisée et l’enseignement de la calligraphie. 2. Dans la vie quotidienne, il est plus pratique pour les gens d'utiliser des téléphones portables pour prendre des photos afin d'obtenir du texte hors ligne que d'obtenir du texte en ligne via des appareils de collecte tels que des tablettes et des stylets tactiles. Par conséquent, définir le mode de saisie du modèle généré sur texte hors ligne le rendra plus pratique à utiliser pour les utilisateurs !
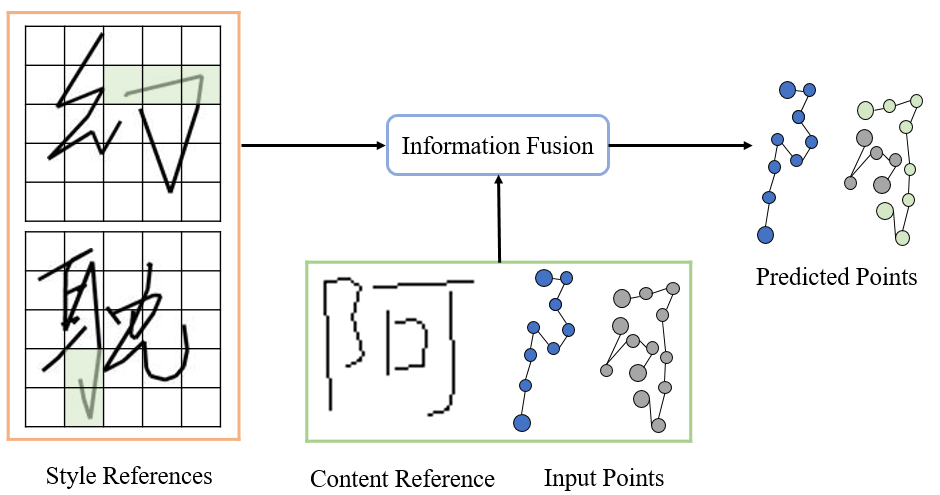
En résumé, l'objectif de recherche de cet article est de proposer une méthode de génération d'écriture manuscrite stylisée en ligne. Ce modèle peut non seulement copier le style d'écriture contenu dans le texte hors ligne fourni par l'utilisateur, mais également générer en ligne une écriture manuscrite dont le contenu est contrôlable en fonction des besoins de l'utilisateur.

- Adresse papier : https://arxiv.org/abs/2303.14736
- Code open source : https://github.com/dailenson/SDT
Principaux défis
Afin d'atteindre les objectifs ci-dessus, les chercheurs ont analysé deux questions clés : 1. Étant donné que les utilisateurs ne peuvent fournir qu'un petit nombre d'échantillons de caractères, le style d'écriture unique de l'utilisateur peut-il être appris uniquement à partir de ce petit nombre d'échantillons de référence. ? En d’autres termes, est-il possible de copier le style d’écriture d’un utilisateur sur la base d’un petit nombre d’échantillons de référence ? 2. L'objectif de recherche de cet article est non seulement de garantir que le style du texte généré est contrôlable, mais également que le contenu est également contrôlable. Par conséquent, après avoir appris le style d'écriture de l'utilisateur, comment combiner efficacement le style avec le contenu du texte pour générer une écriture manuscrite qui répond aux attentes de l'utilisateur ? Voyons ensuite comment la méthode SDT (style détangled Transformer) proposée dans ce CVPR 2023 résout ces deux problèmes.
Solution
Motivation de la recherche Les chercheurs ont découvert qu'il existe généralement deux styles d'écriture dans l'écriture personnelle : 1. Il existe un point commun stylistique global dans l'écriture manuscrite du même écrivain, et chaque caractère semble similaire. Le degré de l'inclinaison et le rapport hauteur/largeur sont différents et différents écrivains ont des points communs stylistiques différents. Parce que cette caractéristique peut être utilisée pour distinguer différents écrivains, les chercheurs l'appellent le style de l'écrivain. 2. En plus des points communs stylistiques globaux, il existe des incohérences stylistiques détaillées entre les différents personnages du même écrivain. Par exemple, pour les deux caractères « 黑 » et « 杰 », ils ont le même radical d'eau à quatre points dans la structure des caractères, mais il existe de légères différences d'écriture dans l'écriture de ce radical dans différents caractères, ce qui se reflète dans la longueur. des traits, de la position et de la courbure. Les chercheurs appellent ce motif de style subtil dans les glyphes le style des glyphes. Inspiré par les observations ci-dessus, SDT vise à dissocier le style d'écriture et de glyphe de l'écriture manuscrite personnelle, dans l'espoir d'améliorer la capacité à imiter le style d'écriture manuscrite de l'utilisateur.

Après avoir appris les informations de style, contrairement aux méthodes précédentes de génération de texte manuscrit qui fusionnent simplement les fonctionnalités de style et de contenu, SDT utilise les fonctionnalités de contenu comme vecteurs de requête pour capturer de manière adaptative les informations de style, réalisant ainsi une intégration efficace du style et du contenu pour générer de l'écriture manuscrite. qui répond aux attentes des utilisateurs.
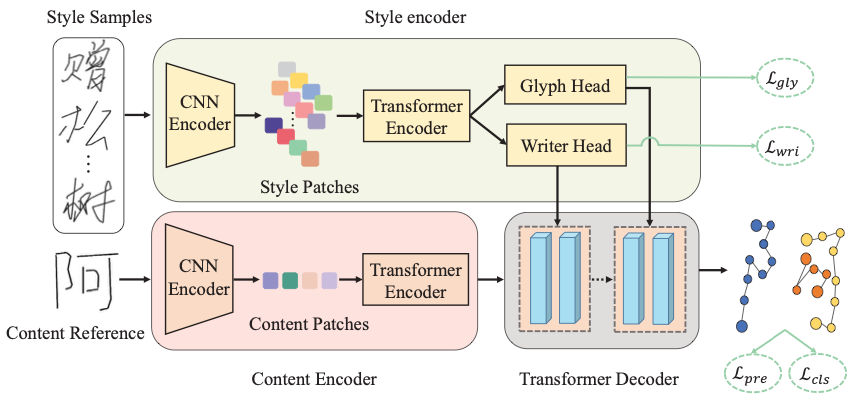
Cadre de méthode Le cadre global de SDT est présenté dans la figure ci-dessous, comprenant trois parties : un encodeur de style à double branche, un encodeur de contenu et un décodeur de transformateur. Tout d’abord, cet article propose deux objectifs d’apprentissage contrastifs complémentaires pour guider respectivement la branche écrivain et la branche glyphe de l’encodeur de style pour apprendre l’extraction de style correspondante. Ensuite, SDT utilise le mécanisme d'attention du transformateur (attention multi-têtes) pour fusionner dynamiquement les caractéristiques de style et les caractéristiques de contenu extraites par l'encodeur de contenu, et synthétiser progressivement le texte manuscrit en ligne.
(a) Apprentissage contrastif du style d'écrivain SDT propose un objectif d'apprentissage contrastif supervisé (WriterNCE) pour l'extraction du style d'écrivain, qui regroupe des échantillons de personnages appartenant au même écrivain. Ensemble, poussant transmettre des échantillons d’écriture manuscrite appartenant à différents écrivains amène explicitement les écrivains à se diversifier et à se concentrer sur les points communs stylistiques de l’écriture individuelle.
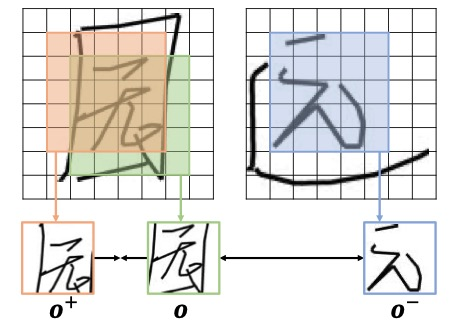
(b) Apprentissage contrastif des styles de glyphes Afin d'apprendre des styles de glyphes plus détaillés, SDT propose un objectif d'apprentissage contrastif non supervisé (GlyphNCE), qui est utilisé pour maximiser les informations mutuelles entre différentes vues du même caractère et encourager La branche glyphe se concentre sur l'apprentissage de modèles détaillés dans les caractères. Plus précisément, comme le montre la figure ci-dessous, effectuez d'abord deux échantillons indépendants du même caractère manuscrit pour obtenir une paire d'échantillons positifs
et
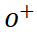
contenant des informations détaillées sur l'AVC, puis sélectionnez-les. à partir d'autres personnages L'échantillonnage donne des échantillons négatifs
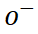
. Chaque fois qu'un échantillon est prélevé, un petit nombre de blocs d'échantillons sont sélectionnés au hasard comme une nouvelle perspective contenant les détails de l'échantillon d'origine. L'échantillonnage des blocs d'échantillon suit une distribution uniforme pour éviter le suréchantillonnage de certaines zones de caractères. Afin de mieux guider la branche de glyphe, le processus d'échantillonnage agit directement sur la séquence de caractéristiques sortie par la branche de glyphe.
(c) Stratégie de fusion du style et des informations de contenu Après avoir obtenu les deux fonctionnalités de style, comment les intégrer efficacement avec l'encodage de contenu appris par l'encodeur de contenu ? Afin de résoudre ce problème, à tout instant de décodage t, SDT considère les caractéristiques du contenu comme le point initial, puis combine les points de trajectoire générés avant les instants q et t pour former un nouveau contexte de contenu
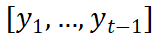
. Ensuite, le contexte de contenu est traité comme un vecteur de requête et les informations de style comme des vecteurs de clé et de valeur. Avec l'intégration du mécanisme d'attention croisée, le contexte du contenu et les deux informations de style sont tour à tour agrégés dynamiquement.
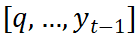 Expériences
Expériences
Évaluation quantitative
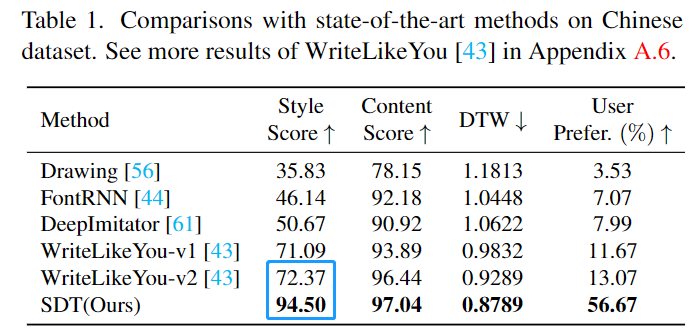
SDT a obtenu les meilleures performances sur les ensembles de données chinois, japonais, indiens et anglais, en particulier sur l'indice de score de style, par rapport à l'avant la méthode SOTA, SDT a fait de grandes percées.
Évaluation qualitative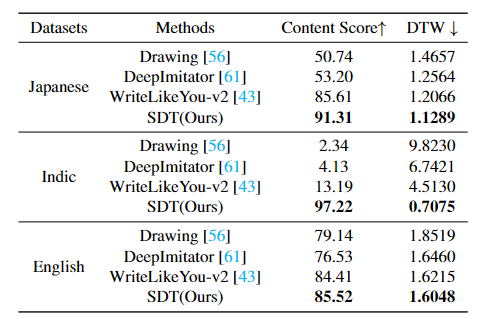
Par rapport aux méthodes précédentes, les caractères manuscrits générés par SDT peuvent éviter l'effondrement des caractères. Il peut également copier le le style d'écriture de l'utilisateur est très bon. Grâce à l'apprentissage du style de glyphe, SDT peut également faire du bon travail en générant des détails de trait de caractères.
SDT fonctionne également bien dans d'autres langues. Surtout en termes de génération de texte indien, les méthodes traditionnelles existantes peuvent facilement générer des caractères réduits, mais notre SDT peut toujours maintenir l'exactitude du contenu des caractères.
L'impact des différents modules sur les performances de l'algorithme
Analyse visuelle des deux styles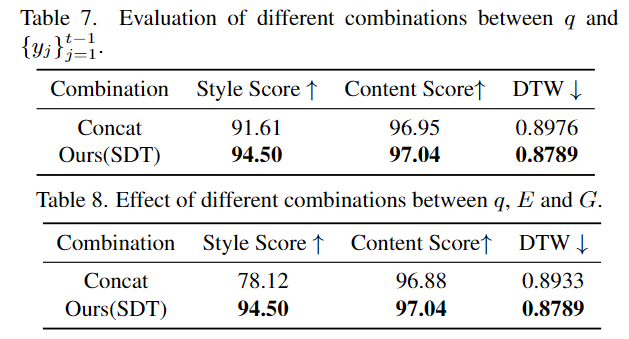
Tout le monde peut créer ses propres polices exclusives grâce à l'IA d'écriture manuscrite et mieux s'exprimer sur les plateformes sociales ! Pour l'avenir
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
