
 Périphériques technologiques
IA
Le chien robot de Tencent évolue : maîtriser les capacités de prise de décision autonome grâce au deep learning
Périphériques technologiques
IA
Le chien robot de Tencent évolue : maîtriser les capacités de prise de décision autonome grâce au deep learning
Le chien robot de Tencent évolue : maîtriser les capacités de prise de décision autonome grâce au deep learning

Le 14 juin, Tencent Robotics a été grandement amélioré.
Rendre les chiens robots aussi flexibles et stables que les humains et les animaux est un objectif à long terme dans le domaine de la recherche en robotique. Les progrès continus de la technologie d'apprentissage profond permettent aux machines de maîtriser des capacités pertinentes grâce à « l'apprentissage » et d'apprendre à faire face à des situations complexes et changeantes. environnements deviennent réalisables.
Présentation du pré-entraînement et de l'apprentissage par renforcement : rendre le chien robot plus agile
Tencent Robotics Il n'est pas nécessaire de réapprendre, mais vous pouvez réutiliser les connaissances à plusieurs niveaux de la posture, de la perception de l'environnement et de la planification stratégique que vous avez déjà apprises, et tirer des conclusions à partir d'un exemple pour faire face avec flexibilité à des environnements complexes


Cette série d'apprentissage est divisée en trois étapes :
Dans un premier temps, grâce au système de capture de mouvement souvent utilisé dans la technologie des jeux, le chercheur a collecté les données de posture de mouvement de vrais chiens, notamment la marche, la course, le saut, la position debout et d'autres actions, et a utilisé ces données pour construire une tâche d'apprentissage d'imitation. dans le simulateur, puis les informations contenues dans ces données sont extraites et compressées dans des modèles de réseaux neuronaux profonds. Ces modèles peuvent non seulement couvrir avec précision les informations collectées sur la posture des mouvements des animaux, mais également avoir une grande interprétabilité.
Tencent Robotique Ces technologies et données jouent un certain rôle auxiliaire dans la formation des agents basée sur la simulation physique et dans le déploiement de stratégies de robots dans le monde réel.
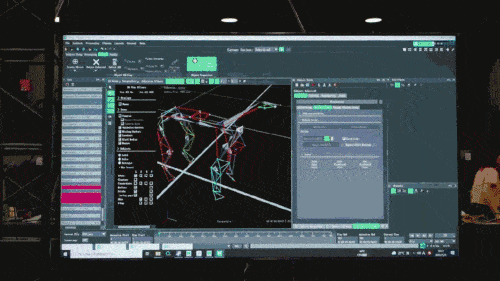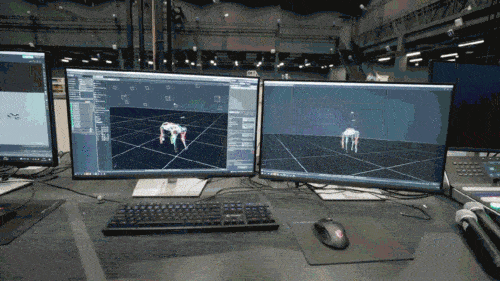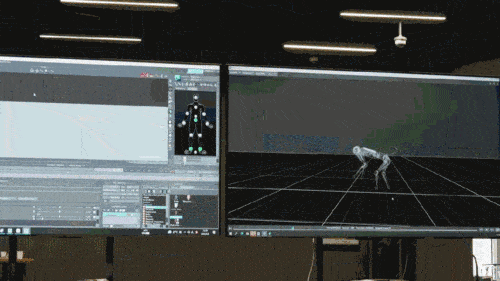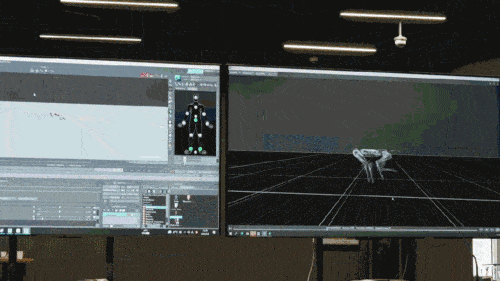
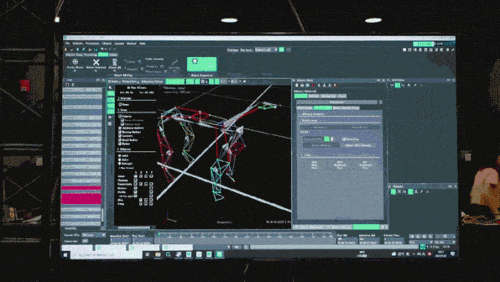

Le modèle de réseau neuronal n'accepte que les informations proprioceptives du chien robot (telles que l'état du moteur) en entrée et est entraîné selon une méthode d'apprentissage par imitation. Dans l'étape suivante, le modèle intègre des données sensorielles de l'environnement, par exemple en utilisant d'autres capteurs pour détecter les obstacles sous les pieds.
Dans la deuxième étape, des paramètres de réseau supplémentaires sont utilisés pour connecter la posture intelligente du chien robot maîtrisée dans la première étape avec la perception externe, afin que le chien robot puisse réagir à l'environnement externe grâce à la posture intelligente qu'il a apprise. Lorsque le chien robot s’adaptera à une variété d’environnements complexes, les connaissances qui relient les postures intelligentes à la perception externe seront également solidifiées et stockées dans la structure du réseau neuronal.



Dans la troisième étape, en utilisant le réseau neuronal obtenu au cours des deux étapes de pré-formation ci-dessus, le chien robot a la condition préalable et l'opportunité de se concentrer sur la résolution du problème d'apprentissage politique de haut niveau, et a enfin la capacité de résoudre des tâches complexes. -à la fin. Dans la troisième phase, des réseaux supplémentaires seront ajoutés pour collecter des données liées à des tâches complexes, telles que l'obtention d'informations sur les adversaires et les drapeaux du jeu. De plus, en analysant de manière exhaustive toutes les informations, le réseau neuronal responsable de l'apprentissage stratégique apprendra des stratégies de haut niveau pour la tâche, telles que la direction dans laquelle courir, prédire le comportement de l'adversaire pour décider de continuer à courir, etc.
Les connaissances acquises à chaque étape ci-dessus peuvent être élargies et ajustées sans réapprentissage, de sorte qu'elles puissent être continuellement accumulées et apprises en continu.
Concours de poursuite d'obstacles avec des chiens robots : possédant des capacités de prise de décision et de contrôle autonomes
Afin de tester ces nouvelles compétences maîtrisées par Max, le chercheur s'est inspiré du jeu de poursuite d'obstacles "World Chase Tag" et a conçu un jeu de poursuite d'obstacles à deux chiens. World Chase Tag est une organisation compétitive de chasse à obstacles fondée au Royaume-Uni en 2014. Elle est standardisée à partir des jeux de chasse folkloriques pour enfants. De manière générale, chaque tour de compétition de chasse à obstacles implique deux athlètes qui s'affrontent. L'un est le poursuivant (appelé l'attaquant) et l'autre est l'esquive (appelé le défenseur). Lorsqu'un athlète concourt tout au long de l'équipe, il recevra. un point lorsqu'ils réussissent à échapper à leur adversaire (c'est-à-dire qu'aucun contact ne se produit) pendant le tour de poursuite (c'est-à-dire 20 secondes). L'équipe qui marque le plus de points dans le nombre prédéterminé de tours de poursuite remporte la partie.
La taille du terrain de la compétition de chasse aux obstacles du chien robot est de 4,5 mètres x 4,5 mètres, avec quelques obstacles dispersés dessus. Au début du jeu, deux chiens robots MAX seront placés à des endroits aléatoires sur le terrain, et un chien robot se verra attribuer au hasard le rôle de poursuivant et l'autre d'évadé. En même temps, un drapeau sera placé. à un endroit aléatoire sur le terrain.
Le but du cagnard est de se rapprocher le plus possible du drapeau sans se faire rattraper par le poursuivant. La tâche du poursuivant est d'attraper l'évadé. Si l'esquive réussit à toucher le drapeau avant d'être attrapé, les rôles des deux chiens robots changeront instantanément et le drapeau réapparaîtra dans un autre endroit aléatoire. Le jeu se termine lorsque le esquive est rattrapé par le poursuivant actuel et que le chien robot jouant le rôle du poursuivant gagne. Dans tous les jeux, la vitesse d'avancement moyenne des deux chiens robots est limitée à 0,5 m/s.
Il ressort de ce jeu que, sur la base du modèle pré-entraîné, le chien robot possède déjà certaines capacités de raisonnement et de prise de décision grâce à un apprentissage par renforcement profond :
Par exemple, lorsque le poursuivant se rend compte qu'il ne peut plus rattraper le esquive avant qu'il ne touche le drapeau, il abandonnera la poursuite et s'éloignera du esquive afin d'attendre la prochaine réinitialisation. Le drapeau apparaît. .
De plus, lorsque le poursuivant est sur le point d'attraper le roublard au dernier moment, il aime sauter et faire une action de "bondir" vers le roublard, ce qui est très similaire au comportement des animaux lorsqu'ils attrapent une proie, ou lorsque le le Dodger est sur le point de toucher le drapeau aura le même comportement. Ce sont autant de mesures d’accélération proactives prises par le chien robot pour assurer sa victoire.
Selon les rapports, toutes les stratégies de contrôle des chiens robots du jeu sont des stratégies de réseau neuronal. Elles sont apprises par simulation et par transfert zéro-coup (transfert d'ajustement zéro), permettant au réseau neuronal de simuler les méthodes de raisonnement humain pour identifier. des choses qui n'ont jamais été vues auparavant et déployer ces connaissances sur de vrais chiens robots. Par exemple, comme le montre la figure ci-dessous, la connaissance de la manière d'éviter les obstacles que le chien robot a apprise dans le modèle de pré-entraînement est utilisée dans le jeu, même si les scènes avec des obstacles ne sont pas entraînées dans le monde virtuel de Chase Tag Game ( uniquement dans le monde virtuel Après s'être entraîné dans des scènes de jeu sur terrain plat), le chien robot peut également accomplir la tâche avec succès.
Tencent Robotics Son introduction dans le domaine des robots améliore les capacités de contrôle des robots et les rend plus flexibles. Cela jette également une base solide pour que les robots entrent dans la vie réelle et servent les êtres humains.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Comprendre en un seul article : les liens et les différences entre l'IA, le machine learning et le deep learning
Mar 02, 2024 am 11:19 AM
Dans la vague actuelle de changements technologiques rapides, l'intelligence artificielle (IA), l'apprentissage automatique (ML) et l'apprentissage profond (DL) sont comme des étoiles brillantes, à la tête de la nouvelle vague des technologies de l'information. Ces trois mots apparaissent fréquemment dans diverses discussions de pointe et applications pratiques, mais pour de nombreux explorateurs novices dans ce domaine, leurs significations spécifiques et leurs connexions internes peuvent encore être entourées de mystère. Alors regardons d'abord cette photo. On constate qu’il existe une corrélation étroite et une relation progressive entre l’apprentissage profond, l’apprentissage automatique et l’intelligence artificielle. Le deep learning est un domaine spécifique du machine learning, et le machine learning
 Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Super fort! Top 10 des algorithmes de deep learning !
Mar 15, 2024 pm 03:46 PM
Près de 20 ans se sont écoulés depuis que le concept d'apprentissage profond a été proposé en 2006. L'apprentissage profond, en tant que révolution dans le domaine de l'intelligence artificielle, a donné naissance à de nombreux algorithmes influents. Alors, selon vous, quels sont les 10 meilleurs algorithmes pour l’apprentissage profond ? Voici les meilleurs algorithmes d’apprentissage profond, à mon avis. Ils occupent tous une position importante en termes d’innovation, de valeur d’application et d’influence. 1. Contexte du réseau neuronal profond (DNN) : Le réseau neuronal profond (DNN), également appelé perceptron multicouche, est l'algorithme d'apprentissage profond le plus courant lorsqu'il a été inventé pour la première fois, jusqu'à récemment en raison du goulot d'étranglement de la puissance de calcul. années, puissance de calcul, La percée est venue avec l'explosion des données. DNN est un modèle de réseau neuronal qui contient plusieurs couches cachées. Dans ce modèle, chaque couche transmet l'entrée à la couche suivante et
 Annonce des progrès de l'optimisation de la mémoire de la version de l'architecture Tencent QQ NT, les scènes de discussion sont contrôlées dans un rayon de 300 M
Mar 05, 2024 pm 03:52 PM
Annonce des progrès de l'optimisation de la mémoire de la version de l'architecture Tencent QQ NT, les scènes de discussion sont contrôlées dans un rayon de 300 M
Mar 05, 2024 pm 03:52 PM
Il est entendu que le client de bureau Tencent QQ a subi une série de réformes drastiques. En réponse aux problèmes des utilisateurs tels qu'une utilisation élevée de la mémoire, des packages d'installation surdimensionnés et un démarrage lent, l'équipe technique de QQ a réalisé des optimisations spéciales sur la mémoire et a progressé progressivement. Récemment, l'équipe technique de QQ a publié un article d'introduction à la plateforme InfoQ, partageant ses progrès progressifs en matière d'optimisation spéciale de la mémoire. Selon les rapports, les défis de mémoire de la nouvelle version de QQ se reflètent principalement dans les quatre aspects suivants : Forme du produit : il se compose d'un grand panneau complexe (plus de 100 modules de complexité variable) et d'une série de fenêtres fonctionnelles indépendantes. Il existe une correspondance biunivoque entre les fenêtres et les processus de rendu. Le nombre de processus de fenêtre affecte grandement l'utilisation de la mémoire d'Electron. Pour ce grand panneau complexe, une fois qu'il n'y a plus
 Tencent Photon H Studio recrute à Hangzhou et prévoit de créer un RPG en monde ouvert 3A
Feb 05, 2024 pm 01:45 PM
Tencent Photon H Studio recrute à Hangzhou et prévoit de créer un RPG en monde ouvert 3A
Feb 05, 2024 pm 01:45 PM
Récemment, Tencent Interactive Entertainment Recruitment a publié des informations de recrutement, indiquant que Photon H Studio s'engage à développer un projet de RPG en monde ouvert riche en contenu et de niveau AAA. Les postes à recruter couvrent plusieurs domaines tels que les ingénieurs UE5, le backend, la conception de niveaux, la conception de scènes d'action, la modélisation de personnages, les effets spéciaux et la distribution, et le lieu de travail cible pour ces postes est Hangzhou, où se trouve le siège de NetEase.
 Les propriétaires d'Up ont déjà commencé à s'amuser avec « AniPortrait » open source de Tencent pour laisser les photos chanter et parler.
Apr 07, 2024 am 09:01 AM
Les propriétaires d'Up ont déjà commencé à s'amuser avec « AniPortrait » open source de Tencent pour laisser les photos chanter et parler.
Apr 07, 2024 am 09:01 AM
Les modèles AniPortrait sont open source et peuvent être utilisés librement. "Un nouvel outil de productivité pour Xiaopozhan Ghost Zone." Récemment, un nouveau projet publié par Tencent Open Source a reçu une telle évaluation sur Twitter. Ce projet est AniPortrait, qui génère des portraits animés de haute qualité basés sur l'audio et une image de référence. Sans plus tarder, jetons un coup d'œil à la démo qui peut être prévenue par une lettre d'avocat : Les images d'anime peuvent aussi parler facilement : Le projet a déjà reçu de nombreux éloges quelques jours seulement après son lancement : le nombre de GitHub Stars a dépassé 2 800. Jetons un coup d'œil aux innovations d'AniPortrait. Titre de l'article : AniPortrait : Audio-DrivenSynthesisof
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
